A mi labor como programador de aplicaciones le agrego el de administrador de red de área local para varios de mis clientes que así lo soliciten -o que a mi juicio lo necesiten-, siempre basado en la vieja consigna de que “el trabajo es mejor que sobre y no que falte”.
Por supuesto que no estamos hablando del elemento químico cromo («chromium» en inglés) sino del popular navegador web de código abierto para todos. Lo que desarrollaremos es una «extensión», una herramienta integrada al navegador y que tiene muy diferentes propósitos. Con fines didácticos haremos una extensión muy sencilla que nos redirige hacia una página web que nos devuelve simplemente nuestra propia dirección IPv4, ¡manos al teclado!
«Content Delivery Network» (CDN) o Red de Entrega de Contenidos es la forma moderna de garantizar que nuestra página web pueda ser visitada por millones de usuarios y consiste, de manera muy simplificada, de repartir nuestro contenido estático a través de servidores ubicados físicamente en distintas partes del planeta, de tal manera que según sea la dirección IP del visitante se contacte con el servidor más cercano. Veamos ahora los detalles ¡vamos!
«Content Delivery Network» (CDN).
Content Delivery Network versus tradicional imagen de Wikipedia
Para poder entender hacia dónde vamos debemos ver de dónde venimos.
El primer servidor web.
Tim Berner-Lee, inventor del hiperenlace y del internet tal como lo conocemos, arrancó con un ordenador avanzado para la época fabricado por la compañía «NEXT Computers» la cual fue fundada por el legendario Steve Jobs luego de que lo despidieron de «Apple Computer», la empresa por él creada. En aquellos años 90 nosotros comprábamos la revista PCMagazine en castellano donde daban cuenta en un artículo que esas computadoras NEXT tenían la increíble cantidad de 1024 megabytes en RAM y costaba cada una más de 10 mil US$ ¡sorprendente!
Primer servidor web NEXT en el CERN
A dicho computador le pegaron un papelito indicando que era un servidor y que no debía ser apagado, estaba alojando la primera página web del mundo y pocos usuarios se conectaban a ella, específicamente los investigadores del CERN («European Organization for Nuclear Research» Organización Europea para la Investigación Nuclear).
Montando nuestra primera página web.
Pues hoy en día tenemos los mismos recursos -incluso rebasan- que contaban y disponían los investigadores europeos: ordenadores con más de 8 mil megabytes de RAM y 4 núcleos de 64 bits con conexiones fijas a internet con más de 1 mbps de velocidad y sin ningún límite de megabytes son comunes, ¿Qué nos impide montar en nuestro hogar u oficina nuestra página web? La limitación es que nuestro proveeedor de internet muy probablemente nos proporcionará una dirección IP dinámica: al apagar el modem y volverlo a encender tendremos una dirección IP diferente y a nuestros usuarios tendremos que volver a notificarles del cambio. Para evitar dicho inconveniente desde los albores del nacimiento del internet se utilizan los DNS «Domain Name Service» Servicio de Nombres de Dominios: son ordenadores que uno les pregunta por un dominio (dirección web) y nos devuelve la dirección IP para conectarnos al ordenador que contiene la página web deseada.
Lo anterior lo podemos simplificar con los teléfonos móviles celulares: cuando una amiga os da su número simplemente lo ingresamos al teléfono y le damos marcar y listo, la encontramos y conectamos. Pero luego recordar ese número es el problema, para ello nuestro celular tiene una agenda donde podemos colocar el nombre de la chica asociada a su número telefónico. En este ejemplo el DNS sería la agenda de contactos y el número de teléfono sería la dirección IP. Huelga decir que los DNS son más avanzados que la agenda de contactos: si un dominio cambia su dirección IP ésta es automáticamente actualizada, cosa que no hace el programita de agenda de contactos del celular (a menos que llamara todos los días a la chica confirmando el número telefónico ¡Qué locura!).
Tráfico hacia nuestra página web.
Con este escenario, un ordenador en nuestra casa u oficina, con un acceso a internet las 24 horas del día sin limites de megabytes y una dirección IP fija y un DNS configurado estamos prestos a difundir al mundo nuestro trabajo sobre el software libre. Pero para hacerle honor a la verdad, lo que distingue un servidor web de un ordenador normal es la redundancia de sus componentes, así que tienen al menos dos fuentes de poder (si una se «quema»queda la otra funcionando y se puede cambiar sin necesidad de apagar el servidor), tienen al menos dos discos duros en RAID (escriben y leen los mismos datos en ambos discos) y también se pueden reemplazar sin apagarlo (al conectar un disco nuevo automáticamente la tarjeta madre copiará los datos del disco viejo al nuevo y «emparejará» la información), memoria RAM de seguridad que -adivinen- internamente son dobles y almacenan y comparan ambas copias constantemente y también tienen dos o más tarjetas de red, generalmente ethernet con cables de cobre o fibra óptica, de igual manera si una falla queda la otra funcionando -y no se pueden reemplazar porque son integradas a la tarjeta madre pero se puede adicionar una(s) en una(s) ranura(s) PCI libre-.
En cuanto a qué podremos hacer con un ordenador con dos o más tarjetas de red (si tenéis un ordenador portátil con tarjeta de red inalámbrica y ethernet podéis hacer pruebas) varios usos le podemos dar:
Ambas tarjetas de red conectados a un concentrador/enrutador en una red de área local con diferentes direcciones IP (por supuesto de área local): podemos balancear la carga para enviar nuestra página web por ambas tarjetas, eso se configura facilmente con ifenslave para luego aplicar modprobe.
Una tarjeta de red conectada al modem y la otra al concentrador/enrutador para trabajarlo como «puente».
Una tarjeta de red conectada al enrutador/concentrador y la otra a otro ordenador con una base de datos para aislar y aumentar la seguridad de nuestra información (páginas web dinámicas).
Una tarjeta de red conectada a un concentrador y la otra a otro para crear dos segmentos de red.
Muchas otras combinaciones (aquí imaginen ustedes).
Esto que acabamos de explicar es para ir «abriendo la mente», para lo que luego queremos explicar acerca de los CDN’s.
Para continuar optaremos por configurar nuestro modem/concentrador/enrutador (hoy en día se puede dar los tres aparatos en uno, por eso decimos que tenemos más poder de hardware que los investigadores del CERN en los años 90). En todo caso explicamos que:
Un modem, generalmente ADSL, nos conecta a internet.
Un enrutador toma una dirección IP asignada a nuestro modem (que está en «modo puente») y traslada las peticiones (NAT) a nuestra red de área local (LAN).
Un concentrador amplía la cantidad de puertos necesarios para conectar hasta 255 ordenadores en un segmento de red (la mayoría de enrutadores tienen 4 puertos físico alámbricos, son pocos en realidad).
Así las cosas nuestro enrutador recibe las peticiones y las reenvía a nuestro servidor web: hasta allí todo va bien, pero ¿qué sucede si recibimos más visitas?
Ampliando la cantidad de ordenadores en una LAN.
Con 4 ordenadores podemos realizar el siguiente esquema para atender más visitantes:
Ordenador 1: recibe las peticiones y balancea la carga de trabajo hacia los ordenadores 2 y 3.
Ordenadores 2 y 3 son los servidores web como tal, reciben las cabeceras de peticiones de ordenador 1.
Ordenador 4: será donde guardemos nuestra página web y que los ordenadores 2 y 3 se encargarán de verificar constantemente si tienen la última versión de nuestra página web.
Este esquema tiene como ventaja, por supuesto, el poder atender más visitantes, manteniendo nuestro trabajo original en el ordenador 4 y teniendo respaldos en los ordenadores 2 y 3, el punto débil de la cadena sería el ordenador 1, que balancea la carga ya que si falla se cae por completo nuestro dominio, ojo con eso. Como desventaja podríamos mencionar, entre otras, el registro de los visitantes (quién ha sido atendido por ordenador 2 y quién por ordenador 3), problemas con las carpetas temporales en el caso que nuestros usuarios necesiten «subir» archivos a nuestra página web y con respecto al lenguaje PHP el almacenamiento de las variables de sesión que no serán iguales para todas las páginas (aquí debemos aclarar que nuestra página web es un sitio web conformado por varias páginas que pueden ser servidas tanto por ordenador 2 y ordenador 3: un visitante puede ver una hoja en ordenador 1 y al cabo del tiempo al volver a visitar el balanceo de carga lo envia a ordenador 3 por lo tanto las variables de sesión PHP serán con distintos valores, lo que pudiera ocasionar problemas de programación -«amnesia» de las aplicaciones-).
Añadiendo más «ancho de banda» a nuestra conexión a internet.
Pues que llega un momento que nuestro humilde modem ADSL no da para más velocidad, así que le pedimos a nuestro Proveedor de Servicio de Internet («Internet Service Provider» ISP) nos suba la velocidad pero va a ser que no, lo máximo ya lo tenemos, 10 mbps y ADSL2 que llega a 25 mbps no está disponible… Pues agregamos otra línea telefónica y otro modem y en teoría nuestro ISP debería colocarlos en modo vinculado «bonding»: con la misma dirección IP transmite por ambos modem entre nuestra casa u oficina hasta la central telefónica más cercana. ¿Recuerdan la redundancia de tarjetas de red en los servidores? Pues bueno, aquí es lo mismo, es una habilitación en una de las capas del modelo OSI, específicamente la capa física (de hecho cada modem en sí mismo cumple con esa capa y cada capa es independiente de las otras capas tanto por encima como por debajo).
Servidores espejos «mirrors».
Pues he aquí que nuestro negocio o portal educativo ha crecido y expandido en todo nuestro país, o incluso hacia el exterior , así que decidimos contratar alojamiento web en nuestro país y/o el exterior. En esos ordenadores contratados colocaremos una sincronización de archivos para que al modificar nuestros ficheros se copien, al cabo de cierto tiempo, a los servidores espejo.
Como ya tenemos configurado nuestro balanceo de carga lo único que tenemos que configurar es que se redirija hacia unas direcciones IP que no están en nuestra red de área local, sino en internet. El pequeño detalle de esta configuración estriba en que nuestro alojamiento debe ser dedicado, tal como tenemos montado en nuestra casa u oficina, si es alojamiento compartido deberemos comprar otro dominio web porque de esa manera es que sabe un servidor web compartido qué datos mostrar al visitante.
shared hosting
Si contratamos un servidor dedicado bien puede ser una máquina real o, lo que es más común hoy en día, una máquina virtual que igual compartiremos con otros sitios web un ordenador físico pero con varias máquinas virtuales que tendrán sus propias tarjetas de red virtuales con sus propios y únicos MAC por los cuales se podrán identificar y asignar sus propias direcciones IP fijas (esto es particularmente atractivo para cuando migremos, por fin, a las direcciones IPv6)
Inconvenientes de los servidores espejos.
Pues como ya se habrán percatado, nuestra debilidad sigue siendo el «balanceador de carga»: nuestro dominio y por medio de los DNS sigue devolviendo una única dirección IP, la de nuestro ordenador en nuestra casa u oficina, ¡pues he aquí la brillante solución de los CDN!
CDN «Content Delivery Network».
De nuevo simplificaremos al máximo para ilustrar de manera didáctica sobre el como funciona. A nivel mundial las direcciones IP están repartidas por grandes proveedores de acceso a internet o incluso por países enteros. Acá en Venezuela CANTV tiene su rango de direcciones IP asignadas, así que para los servidores web es «facil» determinar si nuestro visitante esta conectado por medio de ese proveedor de internet, simplemente comparando la dirección IP contra los rango registrados. Pueden incluso llegar a determinar desde cual ciudad se conectan. Basado en esto:
Una empresa decide montar un CDN a nivel mundial, así que va país por país donde montar una granja de servidores con acceso a internet por medio de algún proveedor que a su vez tiene su rango de direcciones IP asignadas. Aparte de la compra de conexión en sí como tal, también se incluye la compra de un rango de direcciones IP para asignarlas a los ordenadores de la nueva granja.
El siguiente paso es configurar con algunas de esas máquinas unos servidores DNS (generalmente uno principal y otro secundario). Dichos servidores DNS estarán a la orden de los servidores DNS del proveedor de internet y llevarán registro de los dominios web que van a alojar.
Este procedimiento se repite país por páis, o región por región.
Una vez tengan «armada» la red es hora de ofrecer el servicio, no sin antes «unificar» todos sus servidores DNS para que operen como un conjunto armónico.
¿Cómo funciona el CDN?
Al comprar nosotros un alojamiento en CDN lo primero que tenemos que hacer es configurar ante quien nos vendió el nombre o dominio web y establecer los DNS de la empresa que ofrece el servicio CDN. Nuestro trabajo es seguir manteniendo nuestro «balanceador de carga» como siempre lo hemos hecho pero con privilegios especiales para que los ordenadores del CDN tengan acceso y copien nuestra página web y la distribuyan por cada una de las granjas de servidores que nombramos anteriormente.
Lo brillante de la idea de los CDN es analizar la dirección IP de un visitante de nuestra página web RECORDAD que primero tiene que pasar por los DNS del CDN para saber la dirección IP de nuestro balanceador de carga… PUES VA A SER QUE NO porque si nuestro visitante está más cerca de una granja de servidores del CDN pues le pasa esa dirección IP al visitante de una manera totalmente transparente, al fin y al cabo es una copia exacta de nuestra web lo que le va a ser retribuida al internauta.
Un asunto importante para un CDN es el poder identificar según la dirección IP recibida del webnauta de dónde viene para redirigirlo a la granja de servidores más cercana -y que contiene copia de nuestra página(s) web-. Es por ello que muchas empresas ofrecen para descargar sus bases de datos, con su respectivo «manual de uso», por ejemplo, desde MaxMind podeis visitar su página designada al respecto en este enlace. Esencialmente se resume en este comando, siempre respetando y considerando de no abusar del servicio:
Dicha base de datos es utilizada por aplicaciones de seguridad para proteger servidores web de ataques maliciosos. Dado el caso que suframos un ataque masivo de denegación de servicio (millones de dispositivos al mismo tiempo visitan nuestra página web con la intención de saturarla y colapsarla) pues simplemente será repartida a lo largo y ancho del planeta. Puede darse el caso que el ataque provenga, por ejemplo, de millones de dispositivos infectados que están localizados fisicamente en Europa: pues bien las granjas de servidores ubicadas en Europa (digamos que hayan tres, una en Francia, otra en Inglaterra y otra en Italia) solo esas tres granjas de servidores serán colapsados, si es que pueden, mientras que las demás granjas en el resto del mundo mantendrán nuestra página web incólume.
Conclusión.
Si queremos simplificar a tope podríamos decir, en una gran perspectiva, que los CDN actúan como unos «balanceadores de carga» pero a una gran medida, no sin antes realizar un arduo rabajo de sincronización de DNS y contenidos web. Esperamos les haya sido útil la información.
El aumento del sueldo mínimo en sí es el Decreto Presidencial N° 2.966 «mediante el cual se aumenta en un cincuenta por ciento (50%) el Salario Mínimo Nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela, para los trabajadores y las trabajadoras que presten servicios en los sectores público y privado, a partir del 1° de julio de 2017, estableciéndose la cantidad que en él se menciona.»
Es una sola hojita en formato PDF que no tuvimos que hacerle procedimiento alguno ya que lo descargamos de la Imprenta Nacional (institución al cual nos hemos referido en anteriores oportunidades) que ahora permite escoger una sola hoja o sino el documento completo con 16 hojas debido a que no fue posible descargarla del Tribunal Supremo de Justicia (que de todas maneras les dejamos el enlace para ver si ustedes tienen suerte por esta vía).
Desde esta vuestra humilde página web lo pueden descargar del siguiente enlace:
Asimismo se aumenta la Cestaticket socialista a 17 Unidades Tributarias por día, tanto para el sector privado como el sector público, y con dos decretos más adicionales para este último sector que por estar regidos por contrataciones colectivas las benditas burocracias no permiten el aumento de sueldo automático y para no tener que llamar a los sindicalistas y explicarles que todo aumento es bueno y no perder tiempo, pues de una se aumenta por decreto, de hecho las leyes rezan que todo lo que sea beneficioso al trabajador, aplíquese y después veremos las formas correspondiente(s), si es que hubiera(n).
Sumario
Decreto Presidencial N° 2.966
Decreto N° 2.966 mediante el cual se aumenta en un cincuenta por ciento (50%) el Salario Mínimo Nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela, para los trabajadores y las trabajadoras que presten servicios en los sectores público y privado, a partir del 1° de julio de 2017, estableciéndose la cantidad que en él se menciona.
Decreto Presidencial N° 2.967
Decreto N° 2.967, mediante el cual se ajusta la base de cálculo para el pago del Cestaticket Socialista para los trabajadores y las trabajadoras que presten servicios en los sectores público y privado, a diecisiete Unidades Tributarias (17 U.T.) por día, a razón de treinta (30) días por mes.
Decreto Presidencial N° 2.968
Decreto N° 2.968, mediante el cual se establece la Escala General de Sueldos para Funcionarias y Funcionarios Públicos de Carrera de la Administración Pública Nacional.
Decreto Presidencial N° 2.969
Decreto N° 2.969, mediante el cual se establece el Tabulador General Salarial para las Obreras y los Obreros que participan en el proceso social de trabajo en la Administración Pública Nacional.
Transcripciones
Decreto 2.966
Decreto 2.966
02 de julio de 2017
Nicolás Maduro Moros
Presidente de la República
Con el supremo compromiso y voluntad de lograr la mayor eficacia política y calidad revolucionaria en la construcción del Socialismo, la refundación de la patria venezolana, basado en principios humanistas, sustentado en condiciones morales y éticas que persiguen el progreso del país y del colectivo, por mandato del pueblo, de conformidad con lo establecido en los artículos 80 y 91 de la Constitución de la República Bolivariana de Venezuela; concatenado con el artículo 226 ejusdem, en ejercicio de las atribuciones que me confiere el numeral 11 del artículo 236 ibídem, en concordancia con el artículo 46 del Decreto con Rango, Valor y Fuerza de Ley Orgánica de la Administración Publica, y de acuerdo a lo preceptuado en los artículos 10, 98, 111 y 129 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, en Consejo de Ministros,
CONSIDERANDO
Que es una función fundamental del gobierno revolucionario la protección social, de la economía del Pueblo y de la guerra económica desarrollada por el imperialismo y sectores apátridas nacionales, que impulsan procesos inflacionarios y desestabilizacién económica como instrumentos de acumulación de capital y perturbación económica, política y social,
CONSIDERANDO
Que es función constitucional del Estado defender principios democráticos de equidad, así como una política de recuperación sostenida del poder adquisitivo de la población venezolana, así como la dignificación de la remuneración del trabajo y el desarrollo de un modelo productivo soberano, basado en la justa distribución de la riqueza, capaz de generar trabajo estable y de calidad, garantizando que las y los trabajadores disfruten de un salario mínimo igual para todas y todos,
CONSIDERANDO
Que el Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, promulgado por el Comandante Supremo de la Revolución Bolivariana, Hugo Rafael Chávez Frías, el 30 de abril de 2012 y publicado en la Gaceta Oficial de la República Bolivariana de Venezuela de fecha 07 de mayo de 2012, establece que el Estado fijará el salario mínimo, el cual deberá ser igual para todos las trabajadoras y los trabajadores en el territorio nacional y pagarse en moneda de curso legal.
DICTO
El siguiente,
DECRETO N0. 37 EN EL MARCO DEL ESTADO DE EXCEPCIÓN Y DE EMERGENCIA ECONÓMICA, MEDIANTE EL CUAL SE AUMENTA EL SALARIO MÍNIMO MENSUAL OBLIGATORIO Y SE AJUSTA EL BONO ESPECIAL COMPENSATORIO DE GUERRA ECONÓMICA A LAS PENSIONADAS Y PENSIONADOS
Artículo 1.
Se incrementa en un cincuenta por ciento (50%) el salario mínimo nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela, para las trabajadoras y los trabajadores que presten servicios en los sectores públicos y privados, sin perjuicio de lo dispuesto en el artículo 2° de este Decreto, a partir del 1° de julio de 2017, estableciéndose la cantidad de NOVENTA Y SIETE MIL QUINIENTOS TREINTA Y UN BOLÍVARES CON CINCUENTA Y SEIS CÉNTIMOS (Bs. 97.531,56) mensuales.
El monto de salario diurno por jornada, sera cancelado con base al salario mínimo mensual a que se refiere este artículo,
dividido entre treinta (30) días.
Artículo 2°.
Se fija un incremento del salario mínimo nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela para las y los adolescentes aprendices, de conformidad con los previsto en el Capítulo II del Título V, del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, a partir del 1° de julio de 2017, por la cantidad SETENTA Y DOS MIL QUINIENTOS TREINTA Y DOS BOLÍVARES CON CUARENTA Y CUATRO CÉNTIMOS (Bs. 72.532,44) mensuales.
El monto del salario por jornada diurna, aplicable a las y los adolescentes aprendices, sera cancelado con base a| salario
mínimo mensual a que se refiere este artículo, dividido entre treinta (30) días.
Cuando la labor realizada por las y los adolescentes aprendices, sea efectuada en condiciones iguales a la de las demás trabajadoras y trabajadores, su salario mínimo será el establecido en el artículo 1° de este Decreto, de conformidad con el artículo 303 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras.
Artículo 3.
Los salarios mínimos establecidos en este Decreto, deberán ser pagados en dinero en efectivo y no comprenderán, como parte de los mismos, ningún tipo de contraprestación en especie.
Artículo 4°.
Se fija como monto de |as pensiones de las jubiladas y los jubiladas, las pensionadas y los pensionados de la Administración Pública, el salario mínimo nacional obligatorio establecido en el artículo 1° de este Decreto.
Artículo 5°.
Se fija como monto de Ias pensiones otorgadas a las jubiladas y los jubilados, las pensionadas y los pensionados, por el Instituto Venezolano de los Seguros Sociales (I.V.S.S.), el salario mínimo nacional obligatorio establecido en el artículo 1° de este Decreto.
Artículo 6.
Adicionalmente, a lo establecido en el artículo 1° de este Decreto se otorga a las pensionadas y los pensionados por el Instituto Venezolano de los Seguros Sociales (I.V.S.S.), que perciban el equivalente a un salario mínimo un Bono Especial de Guerra Económica del treinta por ciento (30%), equivalente a la cantidad de VEINTINUEVE MIL DOSCIENTOS CINCUENTA Y NUEVE BOLiVARES CON CUARENTA Y SIETE CéNTIMOS (Bs.29.259,47) mensuales.
Quienes fueren beneficiarios de más de una pensión en el marco del ordenamiento jurídico aplicable, recibirán el beneficio solo con respecto a una de ellas.
Artículo 7.
Cuando la participación en el proceso social de trabajo se hubiere convenido a tiempo parcial, el salario estipulado como mínimo, podrá someterse a lo dispuesto en el artículo 172 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, en cuanto fuere pertinente.
Artículo 8.
El pago de un salario inferior a los estipulados como mínimos en este Decreto, obligara al patrono o patrona a su pago de conformidad con el artículo 130 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras y dará lugar a la sanción indicada en su artículo 533.
Artículo 9.
Se mantendrán inalterables las condiciones de trabajo no modificadas en este Decreto, salvo las que se adopten o acuerden en beneficio de la trabajadora y el trabajador.
Artículo 10.
Queda encargado de la ejecución de este Decreto, el Ministro del Poder Popular para el Proceso Social de Trabajo.
Artículo 11.
Este Decreto entrara en vigencia a partir del 1° de julio de 2017.
Dado en Caracas, a los dos días del mas de julio de dos mil diecisiete. Años 207° de la Independencia, 158° de la Federación y 18° de la Revolución Bolivariana.
Ejecútese,
(Ls.)
Decreto N° 2.967
Decreto N° 2.967
02 de julio de 2017
NICOLÁS MADURO MOROS
Presidente de la República
Con el supremo compromiso y voluntad de lograr la mayor eficacia política y calidad revolucionaria en la construcción del Socialismo, la refundación de la patria venezolana, basado en principios humanistas, sustentado en condiciones morales y éticas que persiguen el progreso del país y del colectivo, por mandato del pueblo, de conformidad con lo establecido en el artículo 226 de la Constitución de la República Bolivariana de Venezuela; en ejercicio de las atribuciones que me confiere el numeral 11 del artículo 236 ejusdem, en concordancia con lo dispuesto en el artículo 46 del Decreto con Rango, Valor y Fuerza de Ley Orgánica de la Administración Publica, concatenado con el articularlo 7° del Decreto con Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras, en Consejo de Ministros,
CONSIDERANDO
Que el Estado debe promover el desarrollo económico, con el generar fuentes de trabajo, con alto valor agregado nacional y elevar el nivel de vida de la población para garantizar la seguridad jurídica y la equidad en el crecimiento de la
economía, a objeto de lograr una justa distribución de la riqueza, mediante una planificación estratégica, democrática y participativa,
CONSIDERANDO
Que es obligación del Estado, proteger al pueblo venezolano de los embates de la guerra económica propiciada por factores tanto internos como externos; razón por la cual, considera necesario equilibrar los diferentes eslabones del proceso productivo y garantizar el acceso de la población a los productos de primera necesidad ante las circunstancias que vive la economía venezolana,
CONSIDERANDO
Que es interés del Ejecutivo Nacional, asegurar los niveles de bienestar y prosperidad de las trabajadoras y los trabajadores y de su núcleo familiar.
DICTO
El siguiente,
DECRETO N0. 38 EN EL MARCO DEL ESTADO DE EXCEPCIÓN Y DE EMERGENCIA ECONÓMICA, MEDIANTE EL CUAL SE INCREMENTA LA BASE DE CALCULO PARA EL PAGO DEL BENEFICIO DEL CESTATICKET SOCIALISTA.
Articulo 1°.
Se ajusta la base de calculo para el pago del Cestaticket Socialista para Ias trabajadoras y los trabajadores que presten servicios en los sectores público y privado, a Diecisiete Unidades Tributarias (17 U.T.) por día, a razón de treinta (30) días por mes, pudiendo percibir hasta un maximo del equivalente a Quinientas Diez Unidades Tributarias (510 U.T.) a| mes, sin perjuicio de lo dispuesto en el articulo 7° del Decreto con Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras.
Articulo 2°.
Las entidades de trabajo de los sectores público y privado, ajustaran de conformidad con Io establecido en el artículo 1° de este Decreto, el beneficio de alimentación denominado “Cestaticket Socialista” a todos las trabajadoras y Ios trabajadores a su servicio.
Articulo 3°.
Las empleadoras y empleadores tanto del sector público como del privado, pagaran a cada trabajadora y trabajador en efectivo 0 mediante abono en su cuenta nómina el monto por concepto de Cestaticket Socialista a que se refiere e| artículo 1° de este Decreto, expresando en el recibo de pago separado el monto que resulte por los días laborados, así como indicando que el mismo no genera incidencia salarial alguna, y en consecuencia no podrán efectuarse deducciones sobre éste, salvo las que expresamente autorice el trabajador para la adquisición de bienes y servicios en el marco de los programas y misiones sociales para la satisfacción de sus necesidades.
Articulo 4°.
El ajuste mencionado en el articulo 1° de este Decreto, es de obligatorio cumplimiento por parte de las empleadoras y los empleadores en todo el territorio de la República Bolivariana de Venezuela.
Articulo 5°.
Las entidades de trabajo de los sectores público y privado, que mantienen en funcionamiento el beneficio establecido en el artículo 4°, numerales 1 al 4 del Decreto con Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras, adicionalmente y en forma temporal, deberán otorgar dicho beneficio en efectivo 0 mediante depósito en la cuenta nómina de acuerdo con la establecido en el artículo 3° de este Decreto.
Articulo 6°.
Queda encargado de la ejecución de este Decreto, el Ministro del Poder Popular para el Proceso Social de Trabajo.
Articulo 7°.
Este Decreto entrará en vigencia a partir del 1° de julio de 2017.
Dado en Caracas, a los dos días del mes de julio de dos mil diecisiete. Años 207° de la Independencia, 158° de la Federacion y 18° de la Revolucion Bolivariana.
El día de ayer por medio del perfil de línea de tiempo del Doctor Juan González observamos el interesante artículo tutorial sobre Python publicado por Juan J. Merelo Guervós el cual incluye retos de programación. Ni tardo ni perezoso, a pesar de llegar cansado a mi hogar, y tras una vigorizante taza de café negro con leche de avena sin azúcar nos dimos a la tarea de practicar algunas cositas para mantener el cerebro en forma y al día con las novedades en programación.
Abrimos el mes de julio con mucho trabajo y hemos estado lentos en la publicación por este vuestro humilde «web log» pero hicimos un paréntesis con la simple traducción de un artículo duro y contundente a propósito de un trabajo de investigación que venimos desarrollando. Estos conceptos -expuestos de una manera muy práctica y orientados sobre lenguaje Java- los consideramos fundamentales (a pesar que algunos programadores han anunciado este modelo como en decadencia) por ello los traducimos tal cual y además les agregamos unos enlaces para que veaís cuán profundo es el tema y como de maravilloso lo simplificaron en el artículo que citamos en idioma castellano a continuación.
En la Programación Orientada a Objeto frecuentemente escuchamos términos como «Clase», «Objeto» e «Instancia» pero ¿qué es una Clase / Objeto / Instancia en realidad?
En resumen, un objeto es un paquete de software de estado y comportamiento relacionados. Una Clase es un modelo o prototipo del que se crean los Objetos. Una Instancia es una sencilla y singular unidad de una clase.
Por ejemplo, tenemos un proyecto (Clase) que representa al «Estudiante» (Objeto) con campos como nombre, edad, curso (miembro de la Clase). Y tenemos dos estudiantes aquí, José y María. Así, José y María son dos Instancias diferentes de la clase «Estudiante» que representan el Objeto (personas Estudiantes). Veamos mayores detalles.
Objeto.
Los objetos del mundo real comparten 2 características principales, estado y comportamiento. Los humanos tienen estado (nombre, edad) y comportamiento (correr, dormir). Los objetos de software son conceptualmente similares a los objetos del mundo real: ellos también consisten en el estado y el comportamiento relacionado. Un Objeto almacena su estado en campos y expone su comportamiento a través de métodos.
Clase.
La clase es una «plantilla» o «modelo» que se utiliza para crear objetos. Básicamente, una clase consistirá en campo, campo estático, método, método estático y constructor. Campo se utiliza para mantener el estado de la clase (por ejemplo: nombre del objeto Estudiante). El método se utiliza para representar el comportamiento de la clase (por ejemplo: cómo un objeto Estudiante va a ponerse de pie). Constructor se utiliza para crear una nueva instancia de la clase.
Instancia.
Una Instancia es una copia única de una clase que representa un Objeto. Cuando se crea una nueva Instancia de una Clase, el ordenador asignará un espacio de memoria para esa Instancia de Clase (en nuestro ejemplo, José y María tendrán su espacio aparte e independientes en memoria).
Nota: aunque no está en el artículo original, quisieramos agregar algo adicional con respecto a las Instancias, y es que pudiera darse el caso que se pudieran compartir los valores de campo fácilmente entre dos o más Instancias y precisamente eso es lo que facilita la programación. Si la Clase Estudiante tiene un campo llamado «residencia» (la cual tiene subcampos que contienen la dirección de habitación – estado, ciudad, barrio, calle, casa, etc.- de José y María) y ellos son parejas y viven en la misma casa pues con solo rellenar los campos de María al finalizar los «igualamos» -copiamos- en un solo paso a la Instancia Pedro ¡fácil!.
El pasado 12 de mayo se cumplieron 20 años del Decreto Presidencial 1.808 el cual dicta las normas y procedimientos para las retenciones del Impuesto Sobre La Renta (ISLR). En todo ese tiempo hemos tenido dos Constituciones (enmienda incluida), varios Presidentes de la República, Congreso de Diputados y Senadores y luego una Asamblea Nacional Legislativa e infinidad de Ministros y Ministras ¿Cómo es posible que este decreto haya sobrevivido tanto tiempo?
Advertencia.
Por supuesto que este artículo está dirigido a los venezolanos y venezolanas que hace muchísimos años nos retienen el Impuesto Sobre La Renta «ISLR» en nuestro trabajo intelectual de servicios a las empresas privadas (nunca hemos laborado ni contratado con el sector público). No somos licenciados, ni contadores, mucho menos abogados, pero ya saben como reza el dicho «se puede desconocer la Ley pero la Ley no lo desconoce a usted» Y POR ESO ES MEJOR ESTUDIAR LA LEGISLACIÓN AL RESPECTO ya que estamos directamente involucrados. Vamos pues a este proceso de aprendizaje (o redescubrimiento, en realidad) de las Ciencias Sociales, rama Tributaria.
Nos empeñamos en realizar tutoriales pero en este caso vamos a realizar una simple revisión a un software novísimo: Marp. Esta entrada viene a colación por un «tuit» del sr. Aitor León desde Sevilla, España donde hace un autorecordatorio sobre un software del cual nosotros no habíamos escuchado antes y que nos llamó la atención porque le aplicó la etiqueta #MarkDown:
Nota mental: probar #Marp para presentaciones con #Markdown
Ni tardo ni perezosos indagamos y he aquí lo que pudimos aprender, lo cual humildemente compartimos con el mundo entero de habla castellana.
Inicio y desarrollo de Marp.
Un paso para comenzar.
Ya bien dice el refrán que todo viaje, por muy largo que sea, comienza con un solo paso: el 11 de febrero de 2016 (hace una gran cantidad de tiempo en términos de ordenador japonés) se escribió el comienzo de Marp, el cual originalmente se llamaba MDSlide en su versión 0.0.1.
En mayo de 2016, luego de duro trabajo, MDSlide se transforma en Marp y la numeración de versiones correlativo corresponde a V0.0.6; al cambiar de nombre nace un repositorio nuevo y de MDSlide no quedan rastros… dice uno porque bien sabemos que el protocolo Git es distribuido y por ahí en algún disco fijo debe haber una copia, je, je, je. El logotipo es el ahora conocido y la verdad ya estaba bastante maduro: soporte para emoji, ecuaciones matemáticas (eso nos impresiona) e imágenes (recordad que se basa en MarkDown: se trabaja con teclado).
Ruta de trabajo.
Para octubre de 2016 se retoma el desarrollo debido a que escuchando las sugerencias de los usuarios se replantea todo y liberan la versión 0.0.9 y se declara un plan de trabajo para liberar la tan ansiada versión 1.0 . También debemos tomar en cuenta que Electron, el entorno de programación utilizado, también ha sido actualizado y eso «empuja» a Marp en cierta medida y a pesar de suficientes «pull requests» (copias del código fuente modificado por terceros que lo devuelven mejorado y/o con sugencias) que recibe el sr. Hattori, él ratifica que sigue en las riendas del proyecto y espera mejorarlo mucho gracias a sus usuarios y colaboradores. Pero en este punto reconoce que el modo de presentación es la parte más difícil y es algo que aún no han logrado pulir, pues es esa la característica que estuvimos buscando nosotros y no vemos por ningún lado (más adelante mostraremos su uso con ejemplos en castellano). La «discusión» es viva y candente (en inglés) e incluso se le llega a comparar con software privativo que lleva décadas en el mercado.
Última versión a la fecha de escribir este artículo.
En noviembre de 2016 liberan la versión 0.0.1 que es la versión que descargamos y probamos pero al abrirlo nos encontramos con una versión compilada a lenguaje de máquina y con una extraña versión 1.3.8 ¿En qué momento nos perdimos… de algo? De todos modos no especulemos nada aún, en la parte del licenciamiento veremos bien si realmente es «software libre» o de «fuente abierta».
Autoría.
Así nació Marp de las manos del Ingeniero de Software Web Yuki Hattori, graduado en « 公立はこだて未来大学 » («Public Hakodate Future University») y quien actualmente trabaja en la empresa «Speee, Inc.» en Tokio, Japón.
Ingeniero Yuki Hattori
El Ingeniero Hattori maneja una gran cantidad de lenguajes de programación (vamos que desayuna PHP, merienda con CSS, almuerza con Ruby, la merienda de la tarde la pasa con Node y cena con Rails) y nosotros que pensábamos que algo programamos, pues nos quedamos cortos (44% en otros lenguajes de programación ¿cuáles serán? Acá hace algo con SVG dinámico y en este enlace lo podéis probar y modificar cortesía de Phil Maurer).
Yuki Hattori lenguajes de programación más utilizados
Licencia de uso.
El repositorio oficial de Marp lo podéis encontrar en este enlace, y de sus múltiples secciones hemos leído y analizado la información para el presente artículo, esparamos os sea útil en algún modo.
En junio de 2016 el proyecto tiene un mes con su nombre actual Marp y deciden colocar correctamente la licencia de uso que corresponde a la del Instituto Tecnológico de Massachusetts (MIT) la cual no puede ser un simple enlace web, se debe colocar el encabezado con el año y el nombre del autor para luego copiar fielmente la licencia de uso del MIT y luego, si se quiere, el enlace web correspondiente.
De hecho múltiples organismos conservan una copia de dicha licencia y la más socorrida es la de «The Open Source Initiative»; vale la pena recordar entonces que una cosa es software libre y otra cosa es código fuente abierto: para no ser puristas el software libre es más antiguo y solo tiene 4 reglas básicas (aunque ha evolucionado) y el código fuente abierto deriva su filosofía del software libre y tiene 10 reglas básicas.
En julio de 2016 se reconoce que el proyecto contiene un trabajo realizado con anterioridad y que también posee licencia de uso del MIT: Katex el cual está escrito en JavaScript y CSS para representar gráficamente las tediosas fórmulas matemáticas. Nosotros que estudiamos ingeniería mecánica y nos tocó estudiar matemáticas avanzadas damos fe del tremendo trabajo de presentar informes y no tener un software adecuado para ello. Da un poco de vergüenza decirlo pero era rapídisimo realizarlo de forma manuscrita y presentable en hojas blancas que lo horroroso que quedaban con las impresoras de matríz de punto y el software que disponíamos. Hemos progresado hasta el punto que hoy tenemos presentaciones en un lenguaje de marcación ligero y sencillo, que puede representar las matemáticas como son ¡y de paso se puede exportar a formato pdf, increíble!
En este mismo mes se decide retirar el anuncio de licencia de uso de underscore.js ya que no se sigue utilizando como componente.
Página web oficial de Marp.
En este enlace se tiene una presentación bien cuidada acerca del software y orientada a los usuarios normales, no programadores. Podemos ver su características, un enlace al repositorio, un enlace para descargarlo, una rápida introducción a su uso, una guía a ejemplos más avanzados y una declaratoria de licencia de uso. Lo que nos llama poderosamente nuestra atención es la inserción de dos objetos web que presentan por diapositivas a Marp, dichos objetos fueron hechos en Deckset -software hecho en Alemania-el cual está también basado en MarkDown… ¿casualidad? Bueno acá el software de fuente abierta supera al privativo, pues no exporta en formato pdf… y podremos agregarle funcionalidades que consideremos haciendole un «fork» y haciendo nuestro propio proyecto (conservando la licencia de uso del MIT, por supuesto).
«Instalando» Marp.
Pues que si llamamos «instalar» a descargar un archivo y descomprimirlo, vale, «cuela» como instalación. Esta entrada no es tan compleja como otras que hemos hecho que analizamos lo más a fondo que podemos su código fuente, pero no os preocupéis, no perderemos de vista a Marp en el futuro. Repetimos, el repositorio está en esta dirección.
Usando Marp.
Pilares fundamentales de Marp.
Escribimos en MarkDown las presentaciones (y también podemos ver el resultado del MarkDown).
Se pueden escoger temas y fondos de pantalla para las presentaciones.
Soporta caracteres UNICODE (mejor conocidos como emojis).
Se puden escribir ecuaciones matemáticas con hermoso estilo.
Se puede exportar a formato PDF.
Haciendo presentaciones en MarkDown.
Retrospectiva.
Admitámoslo: realizar presentaciones es tedioso para los que no tenemos el talento para los gráficos. Somos empedernidos usuarios de la ventana terminal y por eso nos agrada mucho el MarkDown y su simple sintaxis para obetener una apariencia básica del HTML… ¡Pero esperen, hay más!
Desde que Github popularizara el Git con su alojamiento gratuito para proyectos públicos (que de acuerdo a la licencia de uso que tengan tendrán diferentes clasificaciones) y agregaron el uso de MarkDown acompañando a los repositorios con su respectiva sección Wiki, que también utiliza cierto «sabor» de MarkDown, y ahora con una ligera variante podremos hacer presentaciones rápidamente sobre nuestro trabajo ya hecho pues… ¡BINGO! ??
Hala, manos a la obra.
Aunque entre las carpetas descomprimidas hay una llamada «locales» hay un archivo llamado es.pak cuyo contenido abrimos con gedit y está escrito en castellano, no hallamos opción para cambiar el idioma inglés. Revisando el código fuente no hallamos referencia a dichos archivos .pak (hay bastantes idiomas) lo que imaginamos es que son «paquetes» o plantillas que se utilizan masivamente para internacionalizar nuestras aplicaciones… o simplemente será nuestra imaginación.
Dicho todo esto, os escribiremos en inglés las referencias que hagamos al programa Marp.
No nos afanéis buscando teclas de acceso directo -para hacer cualquier cosa- excepto las siguientes:
CTRL+N
New file
Fichero nuevo
CTRL+O
Open...
Abrir un fichero
CTRL+S
Save
Guardar fichero
Mayús+CTRL+E
Export slides as PDF
Exportar presentaciones a formato PDF
CTRL+W
Close
Cerrar programa
CTRL+Z
Undo
Deshacer acción
Mayús+CTRL+Z
Redo
Rehacer acción
CTRL+X
Cut
Cortar selección
CTRL+C
Copy
Copiar selección
CTRL+V
Paste
Pegar selección
CTRL+A
Select all
Seleccionar todo
F11
Toggle full screen
Cambiar a pantalla completa
Marp, como es de esperarse, utiliza la misma extensión de fichero de los documentos MarkDown: .md (tal vez presentemos algún vahído porque estamos bien acostumbrados a que las presentaciones tienen sus propias extensiones según el software que las manipule).
Lo primero es abrir un archivo nuevo, vamos al menú desplegable «File» -> «New file» (o pulsamos las teclas CTRL+N). Sin más preámbulo se abre un «lienzo» de trabajo presto a escribir en el. En este lienzo a la izquierda escribimos nuestro código y a la derecha veremos inmediatamente nuestro trabajo de tres maneras distintas:
En modo de presentación, diapositiva por diapositiva (modo por defecto).
En modo de presentación, diapositivas en hilo o «carrousel».
En modo MarkDown, tal como se vería al publicarla en la página web de GitHub, por ejemplo (¡interesante!).
Títulos y subtítulos.
Inician con un símbolo numeral «#» seguido de un espacio y el texto para título principal y agregando dos o más numerales juntos -sin espacios- los subtítulos correspondientes (hasta un máximo de seis subniveles):
Marp títulos y subtítulos.
Nota 1: Marp como buen intérprete del MarkDown «original» soporta el uso de «=» y «-» (uno o más) en la línea inmediatamente inferior del texto para mostrar un encabezado de primer y segundo nivel. Pero si necesitamos de un tercer nivel necesitaremos tres numerales «###»… así que no vale la pena este método os aseguro.
Nota 2: Marp aplica a las imágenes un «realzamiento» su utilizamos numeral (es) delante de la declaración de imágenes, sin embargo «=» y «-» no funcionan en estos casos (no le busquen lógica a esto, por favor, no sabemos si es un «bug» o es algo hecho a propósito).
Realizando una segunda diapositiva.
Como véis el código MarkDown funciona y no es obejtivo de esta entrada mostraros su sintaxis por lo tanto vamos a enfocarnos en los comandos propios de Marp, que son apartes del MarkDown con el propósito de presentar nuestras diapositivas.
Tal como insertamos una línea horizontal en Markdown (tres guiones seguidos al principio de una línea) así agregaremos una segunda diapositiva, cuidando de dejar una línea en blanco antes y después:
Marp inserción de nueva diapositiva
Enumerando las diapositivas.
Para agregar el número de diapositiva en la esquina inferior derecha solo debemos agregar el siguiente código.
<!-- page_number: true -->
A partir de la diapositiva donde insertemos la orden serán numeradas hasta el final, si queremos que todas están numeradas la posicionaremos en la primera diapositiva; por el contrario, si queremos que una diapositiva en particular NO sea numerada modificaremos la directiva anterior agregandole un asterisco para indicar que se le aplique solo a esa diapositiva. Por supuesto, usaremos el valor verdadero o falso a nuestro gusto o necesidad.
Marp numeración de diapositivas
Directivas globales y directivas locales.
Lo que acabáis de ver «encerradas» entre comentarios tipo HTML «<!— comentario —>» por supuesto no se visualizan en nigún navegador o intérprete de MarkDown sin embargo Marp obtiene sus instrucciones de allí en el formato de una instrucción por línea separadas por dos puntos «:». Dichas instrucciones son llamadas directivas y como vimos serán globales -para todas las diapositivas, el documento completo- o solo para la diapositiva donde se encuentre la directiva que establezcamos siempre y cuando sean antecedidas por un asterisco.
Dado el caso que nos equivoquemos en la sintaxis pues simplemente Marp no las toma en cuenta ni ejecuta y no arroja ningún tipo de mensaje de excepción.
Directiva «$theme» y «template».
Marp soporta plantillas predeterminadas para nosotros dedicarnos a lo valioso de escribir los datos en las diapositivas, lo demás son «adornos de repostería». Al momento de escribir esto estaba disponible el tema gaia y de manera adicional con la directiva template:invert se tiene una inversión en los colores. Esto queda guardado en el documento de diapositivas para que Marp automáticamente la muestre al volver abrir el documento. Nota: si por el menú desplegable escogemos «View»->»Theme»->»default» -o cualquier otro tema que haya disponible- Marp obviará la directiva que hayamos establecida dentro de la diapositiva y mostrará la que le hayamos ordenado. Verbigracia:
Marp directiva theme y template
Marp directiva «footer».
Con esta directiva podremos establecer una frase en pie de página ya sea en todas las diapositivas o solo en la que le coloquemos la directiva, recordad el asterisco hace a la directiva local, mirad:
Marp directiva footer
Directiva $size
Esta directiva puede ser confusa porque se refiere a tamaño sin embargo presenta también unos valores que indican proporción pero si buscamos la lógica ambas son excluyentes mutuas y explicamos por qué: todo depende si nuestra presentación será por pantalla (primera opción para el 99% de los casos, vamos que hablamos de presentaciones por diapositivas). El otro asunto es si necesitamos imprimir dichas presentaciones.
Para la proporción tenemos «4:3» predeterminado para monitores normales y la mayoría de proyectores traen este valor por defecto y «16:9» para monitores «multimedia» -llamados así porque las películas son grabadas en esa proporción panorámica-.
Para el tamaño de papel tenemos desde A0 hasta A8 y B0 hasta B8, os adelantamos que el «tamaño carta» viene a ser A4 (mirad abajo en las fuentes consultadas el resto de los medidas de papel).
Por los dos puntos anteriores es que decimos que son mutuamente excluyentes.
Esta directiva solamente es global, recomendamos declararla al principio para un orden efectivo (hicimos pruebas y el asterisco lo que hace es inutlizarla).
Es indiferente que usemos mayúsculas o minúsculas en los tamaños de papel.
Marp lee de izquierda a derecha y el primer tamaño válido de papel o proporción lo aplica, el resto de los caracteres lo desecha (debería NO aplicar el formato o al menos indicar la excepción, pensamos).
No conseguimos hacer funcionar el prefijo documentado «-portrait», recordad que aún es un software en desarrollo y sus gazapos tendrá.
Marp directiva $size
Directivas $width y $height.
De necesitar un tamaño personalizado de papel, estas dos directivas son las adecuadas al caso y ambas heredan todo de la directiva $size por ello no os ponemos gif animado aunque si os podemos decir que si que funciona (¡vamos, animaros a descargar y probar Marp!) y las opciones disponibles son:
px: píxeles por defecto, no es necesario colocarle «px».
Por la razón anterior las siguientes unidades debéis colocarla juntitas sin espacio(o)s o si no lo interpretará como píxeles.
cm: centímetros.
mm: milímetros.
in: pulgadas «inches».
pt: puntos.
pc: picas.
En realidad dichas unidades son las utilizadas por CSSexcepto em (tamaño de fuente) y «%»; abajo en «Fuentes consultadas» (en idioma portugués) tenéis un enlace si queréis aprender más por vuestra cuenta.
Directiva «$prerender».
Antes de entrar de lleno con las imágenes os presentamos esta directiva especialmente hecha para indicarle a Marp que haga un preproceso de las imágenes de fondo en el caso de que éstas sean muy grandes, aligera el proceso con una carga previa de datos.
<!– prerender: true –>
Comando para mostrar imágenes.
Así como lo leeís, ya finalizamos las directivas y volvemos a los comandos de MarkDown en este caso os indicamos lo siguiente:
Para comenzar a insertar una imagen comenza por una línea en blanco donde colocareís  tal cual, incluyendo los paréntesis, son 8 caracteres en total.
Dentro de los corchetes rectos (paréntesis rectos) colocaréis el texto alterno si no se puede cargar la imagen, podéis dejarlo vacío pero el uso de los corchetes es obligatorio, de lo contrario no muestra imagen alguna.
Dentro de los paréntesis (curvos) pero fuera de las comillas dobles el nombre del fichero de la imagen (si reside en la misma carpeta de donde ejecutásteis Marp o una URL válida, local o internet).
La razón de utilizar una imagen desde internet es para mostrar los últimos valores o cifras relacionados con el tema de la presentación, de lo contrario llevad tus imágenes junto con el documento Marp
Entre la URL de la imagen y las comillas dobles debéis dejar un espacio -el mismo que consideramos al principio en el conjunto de 8 caracteres iniciales de declaración.
Dentro de las comillas dobles -que sí son opcionales- podemos colocar una breve descripción acerca de la imagen o una frase nemotécnica que podramos visualizar al pasar el puntero por encima de la imágen, tras lo cual al cabo de menos de un segundo se colocará una pequeña ventanita en blanco sobre negro con el texto que coloquemos.
Comando para mostrar imágenes de fondo.
Muchas personas querrán, en vez de utilizar o crear tema alguno, simplemente fijar una o más imágenes como fondo en las presentaciones. He aquí que Marp se toma la ligera licencia de tomar la sintaxis de las imágenes -en MarkDown– con la excepción que en los corchetes rectos colocamos el comando [bg] y por supuesto la URL local o remota de la imagen en sí. Dentro de los corchetes rectos acompañando a «bg» más un espacio podemos colocar un procentaje para redimensionar la imagen e incluso podemos colcoar varias imágenes siempre y cuando los porcentajes sumen 100% para garantizar visibilidad completa de cada imagen. El comando «bg» no soporta mayúsculas, disfrutad nuestras pruebas:
Marp fondo de diapositiva
Comandos para mostrar caracteres emoji.
Si se sorprenden por haber colocado los emoji como subsección de las imágenes preparaos a recibir una historia bien larga… vamos a tratar de resumirla lo mejor posible.
Por allá en los años ochenta cuando nosotros comenzamos a manipular computadoras y luego entramos a estudiar en la Universidad de Carabobo… ¡EA, ¿PARA DÓNDE VAÍS, QUEDAROS Y ESCUCHAD! ?
…? os contábamos que apenas teníamos computadoras de 16 bits XT y luego vinieron las de 32 bits -286, 386, etc- y en los años 90 se populariza -y hay hardware para manejarlo- el UNICODE que no es más que la representación codificada y gráfica -dibujada con papel y lápiz- de unos 65 mil y pico de caracteres- de la mayor parte de los alfabetos ideados por la humanidad. Allí se tuvo previsión de crear unos símbolos que representaban caras con diferentes estados de ánimo y objetos comunes, el gran problema era dibujarlos por pantalla Y ESO AÚN HOY EN DÍA ES DIFÍCIL DE HACERLO ¿por qué decimos esto?
Está bien, los sistemas operativos modernos manejan los códigos extendidos de UNICODE, con tan «poderosos» aparatos que tenemos faltaba más, faltaba menos. Pero a nivel de hardware, de tarjeta madre, aún no hemos visto que tengan dicho UNICODE grabado en firmware, los asiáticos han hecho hermosos BIOS gráficos pero que en realidad lo que hacen es cargar en memoria un mini sistema operativo con interfaz gráfica para su idiomas basados en ideogramas: AÚN NO SUCEDE QUE EL CPU ENVIE A UN MONITOR CUALQUIERA EL CÓDIGO BINARIO DE UN CARACTER UNICODE (EXTENDIDO) Y EL MONITOR TENGA «MEMORIA» PARA SABER COMO SE DIBUJA ¿Nos seguís el hilo? {Nota: todo monitor e impresora de matriz de puntos tiene en memoria cómo dibujar los 255 caracteres ASCII originales, pero hasta allí llegan, e incluso las impresoras a inyección de tinta y láser ¡perdieron esa capacidad!}.
Más aún, la genialidad de Steve Jobs, el fundador de Apple Computer -hoy la empresa más poderosa del mundo, incluso por encima de Microsoft e IBM juntas- fue el poner en práctica el trabajo desarrollado por Xerox Palo Alto (empresa aliada mutua con Apple) de fuentes tipográficas: pequeñísimas imágenes que computadoras con la suficiente potencia pueden dibujar rápidamente en pantalla imágenes que nosotros identificamos como «letras»… ¿y todo este discurso para qué? ?
Todo este discurso es para deciros que aún los sistemas operativos modernos NO POSEEN soporte nativo y por ende los navegadores web tienen que obtener de algún lado esas pequeñísimas imágenes que nosotros lamamos «letras» o, para este caso, emoticons.
Repetimos, lo simplificamos lo más que pudimos, en serio, no somos licenciados en computación pero como nos tocó vivir esa experiencia en carne propia, la evolución de los ordenadores (y escribimos, que algo queda para la posteridad de las generacioens futuras) pero a ese nivel da este tema.
Volviendo al tema de los emoticons o emoticones para castellanizar el término, revisamos el código fuente de Marp y observamos que utiliza dentro de sus dependencias (a esto nosotros lo llamamos librerías dinámicas) algo llamado «markdown-it-emoji» y a su vez buscamos en el código fuente de ese software unos «comandos» que permitan especificar los emoji en Marp.
Para Marp un emoticon o emoji viene encerrado entre par de dos puntos «: :» y dentro, sin espacios viene la palabra clave con la cual se busca y se dibuja (imaginamos que al compilar Marp todas esas imágenes vienen a nuestro disco duro en el fichero ejecutable luego investigamos y nos dimos cuenta que a este proceso ELECTRON lo llama «Application Distribution«, con el archivo app.asar del cual podrán saber y entender su forma de almacenar la información en su propio repositorio).?
Ya para finalizar el tema de Marp y los emoticones, esos comandos o palabras claves (que no trae documentados cuántos ni cuales son) que os dijimos, los copiamos, encerramos entre «: :» y los pegamos en Marp para producir la siguiente captura (otra nota: los emoticones se ven afectados en tamaño si están precedidos como título «#», notad eso):
Podéis obtener una lista ampliada, nemotécnica, en este enlace cuyo encabezado anuncia las páginas web y/o aplicaciones que utilizan esos emoji. Por ejemplo :cat: es más fácil de memorizar que U1F408, caracter unicode, y que funciona sin problemas con Marp. En dicha página hacéis click en el emoji que os guste y es copaido la palabra clave con su par de dos puntos, y pegáis en MArp. Un código que no veréis es el de GitHub :octocat: (combinación de pulpo con gato) así que no es una lista definitiva, por ahora.
Ofrecemos disculpas por no haber investigado lo suficiente. Esa sí es una lista completa de los caracteres emoji y soportados por Marp porque forma parte de sus componentes y compilación.
Enlaces web.
Los enlaces web o hipervínculos en Marp los podemos declarar de forma implícita y explícita (forma recomendada):
De manera implícita: si escribís «http://» más un caracter cualquiera, Marp lo convierte de inmediato en un enlace a la derecha en la ventana de visualización. También cuela «www.» más al menos dos caracteres.
De forma explícita: como dicta el MarkDown: un par de corchetes rectos (opcionales) donde colocaremos el texto del enlace y un par de paréntesis (curvos) donde colocaremos el enlace web en sí mismo.
Marp enlaces web
Antes de hablar de las ecuaciones matemáticas…
…debemos indicaros que si necesitamos mostrar el código fuente en MarkDown a nuestra audiencia debemos encerrarlas entre triple comillas simples y Marp los interpretará como texto simple, es decir, no lo «ejecutará», no hará «parser».
Marp mostrar código MarkDown a la audiencia
Ecuaciones matemáticas.
Y acá lo que nos apasiona de tanto en tanto: las matemáticas, especialment el cálculo infinitesimal. Para ello Marp tiene un suplemento que debemos ingresar entre par de símbolos de pesos (o lo que sería con el paso del tiempo como símbolo de dólar). Cualquier texto que escribamos lo representa tal cual pero si lo antecedemos de cierta sintaxis comenzaremos a escribir nuestras fórmulas (no os preocupéis, no nos extenderemos mucho a favor de vuestra paciencia).
Fórmula de Euler.
Claro, cualquier texto lo representa tal cual…
… pero si lo antecedemos con un «_» tendremos un subíndice.
Con «^» lo convertiremos en superíndice.
Para agrupar estos subíndices o superíndices los encerramos entre llaves «{}»
Para multiplicar términos: «\cdot».
A «\cdot» le podemos agregar paréntesis para agrupar más términos.
Para mostrar tres puntos suspensivos: «\cdots».
¡También podemos combinar «\cdots()»!
Ya con esto podremos representar la famosa fórmula de Euler:
Marp formula de Euler
Nota: cada fórmula matemática debe ocupar una o más líneas completas, no podemos intercalar fórmulas en una línea, por ejemplo. Opinamos que debería hacerlo y hasta podemos clonar el repositorio y empezar a programar, para eso es el software libre.
Identidad de Euler.
Marp identidad de Euler
Símbolos y signos.
Es una lista larga, larguísima como la matemática misma pero los más comunes símbolos matemáticos tienen sus propios códigos:
Para representar ? usamos «\pi».
Para representar ?: «\phi»-
Para ?: «\theta»
Infinito: «\infty».
Operadores matemáticos simples y avanzados:
División: «\div».
Fracción: «\frac{}» -colocamos el numerador entre llaves y el denominador a continuación.
Sumatoria: «\sum» -la podemos combinar con superíndices y subíndices.
Raíz cuadrada: «\sqrt» más el número -o llaves, o paréntesis.
Paréntesis grandes, ideales para encerrar fracciones: «\Bigl(» y «\Bigl)».
Para representar integrales simples: «\int», dobles «\iint», triples «\iiint», integral de superficie «\oint».
Fórmula de cálculo de la constante e.
Marp cálculo de constante e
Exportar a formato PDF.
Probamos la exportación de archivos a formato PDF y no tuvimos ningún tipo de problema, si acaso un detalle que «no recuerda» los últimos archivos abiertos o guardados, «archivos recientes» les decimos. Incluso los emoticones fueron exportados y hermosamente dibujados -claro si originalmente fueron hechos en SVG nunca pierde calidad alguna al «pasar» de un lado a otro.
Conclusiones.
El software se ve realmente prometedor y aunque tiene la opción F11 pra verlo a pantalla completa no es lo mismo que un programa de presentación que se precie como tal: debe ser capaz no solo de usar las flechas de dirección del teclado para avanzar diapositivas sino que le falta aún programador de tiempo, música y lo más importante, ser capaz de detectar -y escoger- los múltiples monitores y/o proyectores que tengamos conectados a nuestro ordenador.
Esperamos os haya sido útil este vuestro -y nuestro- trabajo para la ampliación de conocimientos y saberes. 😉
Para abrir el mes de junio seguimos el hilo en nuestros artículos que buscan difundir el conocimiento libre del Patrimonio Tecnológico de la Humanidad. En anterior oportunidad estudiamosPHP curl, una herramienta basada en cURL y por ende en libcurl (¡ea, esto último no lo mencionamos allá!). Como en ese caso obtuvimos un método para descargar páginas web enteras, incluso si hay que pasarle datos con el método POST y/o hay que introducir usuario y contraseña. Esta entrada busca extraer, analizar e incluso modificar dichos datos ¡vente con nosotros!
Suena incoherente: usamos curl en nuestra línea de comandos frecuentemente para diversidad de tareas pero no sabíamos que el lenguaje PHP tiene su propia versión llamada, cómo no, curl. El asunto es cómo se implementa y qué podemos hacer, nosotros en la línea de comandos lo acompañamos en el trabajo con grep pero en PHP la cosa es un poco diferente, ¡vamos a averiguar cómo!
Introducción.
Exactamente cómo implementaron cURL en PHP no lo sabemos, tal vez PHP haga llamado directo al curl y recoja sus resultados, sirviendo entonces como intermediario solamente… No tiene sentido pero si analizamos que muchos sitios web compartidos con otros dominios tienen PHP pero a uno no lo dejan ingresar por la línea de comandos entonces ¡vaya que si vale la pena el trabajo intermedio!
Por otra parte puede ser que especulamos demasiado y los buenos desarrolladores de PHP tienen su propia versión… ¡pero recordad que trabajamos con Software Libre que permite la modificación y reutilización del código! Pero echemos una leve ojeada al comando curl.
Comando curl.
Ya sabemos como va es esto del software libre: hay más de 1400 colaboradores en curl y el proyecto está alojado en GitHub desde el año 2010; aceptan contribuciones bajo la forma de «pull requests»: en resumen uno copia y trabaja con esa copia privada modificandola -y mejorandola, por supuesto- y devolviendo el trabajo al original para su aprobación. No se garantiza que se acepte toda la propuesta, e incluso ellos podrán tomar ciertas cosas propuestas y otras no, o en el mejor de los casos todo vaya bien y nos convirtamos en el colaborador 1401… y así haremos nuestra contribución al Patrimonio Tecnológico de la Humanidad.
Pero ¿quiénes desarrollan curl? Daniel Stenberg -sueco, habitante de Estocolmo- es el principal desarrollador y comenzó el proyecto por allá en 1996 basado en el trabajo de un programador brasileño llamado Rafael Sagula. Esta sencilla herramienta herramienta carioca fue bautizada como httpget con unas cuantas centenares de líneas y Stenberg las amplió para liberarla en 1997 con el nuevo nombre de «HTTP proxy support». Pero con el advenimiento de «nuevos» protocolos al proyecto tales como GOPHER y FTP pronto dejó de tomar sentido llamarlo solamente «HTTP»… así que ese mismo año vio la luz la versión número dos.
Para 1998 más protocolos y capacidades fueron agregados así que volvió a cambiar de nombre para la versión 4.0 -manteniendo la numeración de versiones- así que el 20 de marzo de ese año marca el nacimiento formal de curl. El nuevo nombre hace alusión al programa del lado del cliente, de allí la letra «c» inicial. Las otras tres letras os lo podéis imaginar ya: Uniform Resource Locator -URL- o Localizador de Recursos Normalizados.
El mismo Stenberg reconoce que hay muchos proyectos con el mismo nombre curl pero para la época que ellos lanzaron la versión cuatro no había (o conocían) de otros proyectos con el mismo nombre. Es por ello que nosotros al principio especulamos del origen de curl en el lenguaje PHP, pero es que ¡Incluso existe un curl desarrollado en software privativo! (no le haremos publicidad pues no nos pagan por ello, buscadlo vosotros mismos con DuckDuckGo). Tan famoso es que ya se considera como verbo en idioma inglés y muchos creen que es un protocolo pues lo tratan como tal pero ya sabemos que en realidad es una navaja suiza con muchísimas funciones.
curl para la línea de comandos.
En principio el comando curl fue desarrollado para scripts ya que sus entradas y salidas utilizan las ya famosas stdin y stdout. No ampliaremos más porque en este blog hallaréis información sobre su uso con la línea de comandos. El artículo que motivó la publicación de esta entrada está en el siguiente «tuit» y precisamente es para la línea de comandos -y pretendemos que corra en PHP curl-:
A partir del año 2000 fueron desarrolladas, o mejor dicho, el código existente fue migrado completamente como librerías y a partir de allí se le hizo una interfaz de usuario para la línea de comandos. Está escrito en lenguaje C y aún hoy en día dichas bases siguen sustentando el proyecto con la ventaja que se puede reutilizar en otros proyectos y compilarlos todos juntos. Seguimos sospechando que precisamente eso hicieron en PHP pero esa es nuestra humilde opinión que como reafirmamos: en software libre este comportamiento es un honor a su filosofía de desarrollo: ejecutar, estudiar, distribuir, mejorar y redistribuir.
Versiones actuales y desarrolladores estrellas.
Nosotros en nuestro GNU/Linux Ubuntu 16 tenemos instalada la versión 7.40.00 pero en realidad la última versión estable es la 7.54.0.
Si bien son muchísimos los colaboradores, es justo mencionar los que más han contribuido en los últimos años de una manera marcada y constante:
Daniel Stenberg.
Steve Holme.
Jay Satiro.
Dan Fandrich.
Marc Hörsken.
Kamil Dudka.
Alessandro Ghedini.
Yang Tse.
Günter Knauf.
Tatsuhiro Tsujikawa.
Patrick Monnerat.
Nick Zitzmann.
Disipación de toda duda.
En este punto de nuestra investigación nuestras sospechas se hacen realidad: uno de los primero lenguajes en adoptar la librería curl es precisamente PHP el cual motoriza un 25% de las páginas web a nivel mundial. El extracto , en inglés, reposa en el libro electrónico -liberado con licencia «Creative Commons»- «Everything about curl«:
The libcurl binding for PHP was one of, if not the, first bindings for libcurl to really catch on and get used widely. It quickly got adopted as a default way for PHP users to transfer data and as it has now been in that position for over a decade and PHP has turned out to be a fairly popular technology on the Internet (recent numbers indicated that something like a quarter of all sites on the Internet uses PHP).
A few really high-demand sites are using PHP and are using libcurl in the backend. Facebook and Yahoo are two such sites.
La traducción hecha por nosotros al idioma castellano:
El software de enlace (librerías) de curl para PHP fue uno, cuidado sino, el primero de los enlaces que realmente captura y lo usa ampliamente. Rápidamente fue adoptado como una manera por defecto para transferir datos y se ha mantenido en esa posición por más de una década mientras tque PHP se ha convertido en una tecnología bastante popular en internet (cifras recientes indican que algo asó como una cuarta parte de todos los sitios web en internet utilizan PHP).
Realmente unos pocos sitios web de alta demanda están usando PHP acompañado de las librerías de enlace de curl corriendo entre bamabalinas. Facebook y Yahoo son dos de tales sitios.
Protocolos soportados por curl.
HTTP, HTTPS, FTP, FTPS, GOPHER, TFTP, SCP, SFTP, SMB, TELNET, DICT, LDAP, LDAPS, FILE, IMAP, SMTP, POP3, RTSP y RTMP (esos son todos, por ahora -y vienen más, no se detiene el proyecto-).
PHP curl.
Ahora si que pasamos a hablar del software que nos ocupa en este vuestro sitio web de compartición del conocimiento. Como ya hemos hablado bastante de historia y teoría pasamos directamente a describir cómo trabajar con PHP curl:
Inicializar curl con curl_init().
Pasarle los parámetros – esencial es la URL – con curl_setopt().
Retribuir y mostrar -o guardar- con curl_exec().
Cerrar y liberar recursos con curl_close().
Nuestro primer ejemplo práctico.
Lo siguiente que haremos es abrir una ventana terminal, tomar nuestro editor de texto favorito y escribir el siguiente código para ser guardado en un archivo que llamaremos php_curl.php:
[cc lang=»php» tab_size=»2″ lines=»80
[/cc]
Por supuesto, llamad vuestro archivo como queráis, guardadlo en vuestra carpeta donde ejecute vuestro servidor PHP y dadle los permisos de lectura y ejecución necesarios. En la primera línea inicializamos, en la segunda línea le pasamos la dirección web deseada -un dominio que devuelve nuestra dirección IP asignada por nuestro ISP-, en la tercera línea lo ejecutamos y en la cuarta línea cerramos y liberamos recursos. Una explicación más detallada a continuación.
Inicialización.
Debemos crear una instancia y guardarla para futuras referencias, este objeto basado en curl nosotros lo llamamos $objCurl y este nombre es el que debemos pasar a los otros comandos. El comando curl_init() solamente acepta un parámetro, la URL que es un dato imprescindible, tal vez debido a ser tan importante fue el único que establecieron en este comando. Aunque en el ejemplo no lo colocamos por razones didácticas, de ahora en adelante «para que no se nos olvide» lo estableceremos siempre en la primera línea del script o guion del programa.
Configuración.
Este es el comando más denso, notad que le damos el nombre de configuración porque su nombre así lo sugiere: curl_setopt(), osea «setopt» -> «set options». Acepta tres parámetros, separados por comas:
Primero debemos indicarle el objeto que contiene la inicialización de curl, en nuestro caso la variable $objCurl.
Segundo le pasaremos el tipo de valor que le pasaremos en el tercer parámetro, en nuestro caso la URL y la constante que lo define -nombrada de manera nemotécnica- es CURLOPT_URL.
El tercer parámetro es el valor en sí mismo de lo que indicamos en el segundo parámetro.
Debemos indicaros que usamos una sola línea para configurar, pero pronto veremos que esta parte es la más abultada por la infinidad de datos y tipos de datos que podemos pasar. Es mejor que vayaís preparando para aprender que esta sección siempre será multilínea y que debemos indentarla y escribirla lo más explícito posible para corregir a futuro de forma fácil nuestro código.
Ejecución.
Simplemente le decimos a PHP que hemos terminado de establecer lo que queremos obtener –o lo que queremos enviar, ya veremos más adelante- y acepta un parámetro que sigue siendo el objeto que hemos creado y configurado. En este punto ya os recordaremos que estamos trabajando con funciones y este comando devuelve verdadero o falso para indicar si tuvo éxito (para comparar la respuesta usaremos siempre «==» para estar seguros del tipo de variable y el resultado obtenido). En el ejemplo no colocamos ninguna variable que reciba el resultado del que hablamos como función ¿dónde está lo que nos interesa? En realidad el valor numérico (verdadero o falso) es lo que podemos guardar en una variable, el resto del resultados se va al stdout y eso será lo que enviaremos al navegador web que solicitó nuestro primer guión PHP sobre curl. Debido a esto recibiremos el mismo código HTML de la página que estamos solicitando (pero con los enlaces web absolutos cambiados).
Si probáis con descargar diferentes páginas, unas funcionarán, otras no, todo depende de si la página es estática, dinámica, si tiene JavaScript, en fin, cantidad de cosas que pueden NO ser compatibles con PHP curl: por eso debemos aprender las muchísimas opciones de configuración que nos sean útil en cada trabajo que se nos presente para ganarnos así el pan nuestro de cada día como Dios manda.
Liberación de recursos.
Os podrá sonar que nos contradecimos con lo siguiente: la función curl_close() se encarga de cerrar, como su nombre indica pero no devuelve resultado acerca del trabajo que le mandamos a realizar. Consideramos que esto es un «bug» porque a la hora de detectar dónde fugan recursos en nuestro servidor deberemos recurrir a otras herramientas apartes de PHP, pudiendo ser evitado esto con una sencilla rutina de nuestra parte e indicar que está sucediendo y qué está mal. Ah, perdón, casi lo olvidamos: el parámetro único que acepta es el objeto que creamos -y queremos destruir- con curl_init().
Nuestro primer ejemplo práctico pero mejorado.
Un sencillísima rutina de control de errores nos puede ahorrar muchísimos dolores de cabeza.
Nota: hay mejores métodos para el manejo de excepciones, pero aprendamos poco a poco. Ah, y nosotros lo llamamos «control de errores» y eso tampoco es el nombre correcto (excepciones) pero así nos abstraemos.
Por ello reescribiremos nuestro ejemplo pero con condicionales if~else:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]
$objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == true) {
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl);
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Notad que pasamos de una buena vez el URL en en el inicio con curl_init(). Además guardamos el valor del resultado en una variable, evaluamos el valor que tiene y ejecutamos o mostramos un mensaje apropiado según la respuesta obtenida. Muchos programadores y programadoras piensan que hacer nuestro software de esta manera, aparte de ayudarnos a nosotros mismo, abre las puertas a los hackers cuando se presentan excepciones -o errores, como les llamamos- porque «develan mucho». Ese razonamiento es válido en el software privativo pero en el software libre no tiene asidero alguno porque cualquier hacker tiene acceso al código fuente, así que hagamos la depuración fácil para nosotros mismos.
Guardando el resultado en una «variable aparte».
Como explicamos PHP curl envía al stdout la respuesta y asu vez eso lo pasamos al navegador, ¿qué tal si analizamos primero lo que recibimos y luego lo reenviamos? Por ejemplo, podríamos «acomodar» los enlaces absolutos de las imágenes que contiene la página web que llamamos (URL). Para ello vamos a emplear culr_setopt() con CURLOPT_RETURNTRANSFER establecido en el valor 1, mirad:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com»);
if ($objCurl == true) {
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl); print «Nuestra direccion IP es: «; print $resul;
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Y así «manipulamos» el resultado con el texto que coloreamos en verde; ahora vamos un paso más allá. 😎
Guardando el resultado en un archivo.
Aunque ya tengamos el resultado deseado en una «variable» supongamos que estamos creando un robot (o bot como los mientan ahora en este siglo) y queremos guardar el resultado en un archivo ¿qué tiene que ver PHP curl con esto si ya sabemos el lenguaje PHP y sabemos como hacerlo aparte?
Pues resulta que con CURLOPT_FILE en curl_setopt() permite guardarlo en un archivo, pero antes tenemos que abrir el archivo y pasarle la «referencia» a PHP curl:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == false) {
print «No se pudo inicializar PHP curl.
«;
} else {
$nom_arch = ‘PHP_curl.html’; $arch = fopen( $nom_arch , «w»);
if ($arch == false ) {
print «No se pudo abrir el archivo ‘».$nom_arch.»‘
«;
curl_close ($objCurl);
} else { $resp = curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_RETURNTRANSFER.
«;
curl_close ($objCurl);
} else { $resp = curl_setopt ($objCurl, CURLOPT_FILE, $arch);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_FILE.
«;
curl_close ($objCurl);
} else { $resul = curl_exec ($objCurl);
if ($resul == false) {
echo «No se pudo ejecutar PHP curl.
«;
} else { print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado:
curl_close ($objCurl);
}
}
}
}
}
?>[/cc]
Así de sencillo, con las correspondientes rutinas de depuración para nosotros. Como tal vez se vea un poco largo hemos coloreado las partes importantes para que sigáis el hilo. ¿Que por qué nos hemos ido por la negación siempre de primero? Pues revisando la función fopen() verificamos que si es exitosa devuelve una referencia al archivo más no un valor de tipo booleno -verdadero-. En cambio si falla la función siempre devuelve un valor boleano falso. Lo de seguir usando la negación por defecto es para llevar el mismo estilo parejo al resto del código.
Mejorando la claridad de la sintaxis con ayuda de exit().
Una función «vieja» en PHP es la función die() que es totalmente equivalente a exit() que es más «elegante». El chiste del asunto es emplear la conjunción or (operador lógico «o») para unir la acción que queremos realizar con la función exit(). Dicha función permite como parámetro una cadena de texto o un entero entre cero y 254 (el 255 está reservado para uso exclusivo de PHP). Nos gusta mejor la opción de pasarle una cadena de texto con el mensaje que queremos presentar al usuario ¡o a nosotros mismos!
Otro punto importante es que la función exit() aparte de mostrar mensaje y cerrar adecuadamente los objetos en memoria es que sale inmediatamente y no ejecuta el resto de las líneas que quedan a partir de su llamada.
Veamos entonces cómo emplearlo en nuestra labor que hoy nos ocupa (para no alargar tanto cada línea fijaos el uso del punto y coma para separar bloques de código multilíneas):
$objCurl = curl_init("http://www.soporteweb.com/")
or exit("No se pudo inicializar PHP curl.
");
$nom_arch = ‘PHP_curl.html’; $arch = fopen( $nom_arch , «w»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado: curl_close ($objCurl);
?>[/cc]
¡Qué gran mejora en la legibilidad! Debemos aclarar que exit() de manera implícita llama a los procedimientos de cierre y liberación de recursos de memoria (destructor lo nombran en lenguaje C++) así que como ven es una vía muy pragmática para nuestros propósitos.
Si queréis probar como funciona la rutina con control de excepciones, colocad una dirección web que no exista y mirad que sucede, ¡experimentad! También os recomendamos probar otros protocolos, por ejemplo FTP en un servidor público como por ejemplo «ftp://ftp.cesca.es/» donde veremos un listado de archivos disponibles para ser descargados.
Probando otros protocolos: FTP.
En el párrafo anterior os sugerimos probar el protocolo FTP y no hubo nada que cambiar en el código que teníamos -aparte de la URL, por supuesto-. Pero PHP curl tiene sus opciones y a continuación pasamos a revisar alguna de ellas. La primera que revisaremos limita el listado obtenido de archivos y directorios, osea, no muestra los permisos de cada uno de ellos. La sintaxis en el comando curl_setopt() -y todas las opciones utilizan esta función- es la siguiente:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]curl_setopt($objCurl, CURLOPT_FTPLISTONLY, 1)
or exit("No se pudo establecer CURLOPT_FTPLISTONLY"); [/cc]
Si el servidor FTP no fuera público o exigiera una conexión tipo anónimo usaremos esto:
curl_setopt($objCurl, CURLOPT_USERPWD, "anonimo:su@correo-e.com")
or exit("No se pudo establecer CURLOPT_USERPWD");[/cc]
Con esta novedad de introducir credenciales de conexión nos encontramos con otro tipo de manejo de excepciones: dado el caso las credenciales no funcionen (mala escritura, contraseña vencida, usuario inexistente, etc) dentro del obejto PHP curl se guardará en una instancia aparte el resultado del intento de conexión, para ellos contamos con:
[cc lang="php" tab_size="2" lines="80" widht="10%"] echo curl_error($objCurl);[/cc]
https://twitter.com/souzace/status/868869012414840832
Pasando valores por medio del método POST.
Finalmente llegamos al meollo del asunto: poder pasar a un servidor web una o más variables por medio del método POST a un servidor web. Para propósitos de aprendizaje diremos que es uno de los métodos más populares debido a su cierta privacidad ya que el usuario no puede ver el enlace como en el método GET y tampoco es «cacheable» por los navegadores web.
Primero haremos una rchivo que nos muestre todas las variables que reciba y las liste por pantalla, de manera increíble solo necesita una sola líneas de código (guardar con el nombre de «curl_post.php«):
var_dump($_POST);
?>[/cc]
Una vez tengamos este archivo ya sea en nuestro servidor local o en nuestro servidor remoto podremos comenzar a escribir el siguiente script:
$objCurl = curl_init("http://localhost/curl_post.php")
or exit("No se pudo inicializar PHP curl
");
curl_setopt($objCurl, CURLOPT_POST, 1)
or exit(«No se pudo establecer CURLOPT_POST»);
//Pasamos las variables que nos interesan al servidor curl_setopt($objCurl, CURLOPT_POSTFIELDS, «var1=uno&var2=dos&var3=tres»)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.»);
curl_close ($curl);
?>[/cc]
Debido a los mensaje que incluimos en cada exit() y con el coloreado del código no hay nada que explicar… excepto unas cuantas acotaciones:
Las variables que pasamos en el método POST deben estar por pares unidas con el ampersand y separadas por medio de un signo de igualdad.
Los espacios no se permiten, debemos pasar «%20» o mejor dicho debemos darle un formato especial antes de enviarlo. El comando que nos ayudará será urlencode() y para nosotros castellanohablantes es importante representar bien los acentos, etc.
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] //Pasamos las variables que nos interesan al servidor
$var_post = urlencode(«var1=Venezuela&var2=América del Sur&var3=Güigüe»); curl_setopt($objCurl, CURLOPT_POSTFIELDS, $var_post)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);[/cc]
Fuera de tema: «Tamper data for Mozilla Firefox».
Adam Judson es un desarrollador que tiene -nos tiene- como usuarios a más de 80 mil personas en su trabajo de programación desde el año 2007. Él desarrolló «Tamper Data» para este popular navegador, una herramienta para, según sus propias palabras «pruebas de seguridad en aplicaciones web por medio de la modificación de los parámetros POST».
Dicha herramienta la podemos instalar en nuestro navegador (requiere reinicio del navegador y no es compatible con «Google Web Accelerator») y con ella podremos visitar cualquier sitio web que utilize envio de datos POST y al activarlo en una ventana aparte mostrará sin molestar ni influir en nada el tráfico saliente de nuestro ordenador por medio de nuestro navegador web Firefox. ¿Por qué anuncia pruebas de seguridad? Porque nosotros muy bien sabemos como programadores que el código fuente de nuestras aplicaciones web están a la vista de los usuarios ¿pero que tal lo que no se ve? Pues acá entra «Tamper Data»: por más que coloquemos validación HTML5 y JavaScript del lado del cliente, si no utilizamos HTTPS el tráfico entre el usuario y nuestro servidor puede ser modificado por terceros. Y aunque si usaramos HTTPS tampoco podemos confiarnos de nuestros usuarios, verbigracia la misma herramienta que estamos recomendando puede modificar los datos si en la venta que se nos abre hacemos click en «modificar». Al activar este botón, cuando sale algo de nuestro ordenador nos pregunta si deseamos modificar algún dato, ¡y allí podremos echar por tierra toda la hermosa programación hecha en HTML5 y javaScript!
Este comentario es «fuera de tema»: para combatir esto último lo que debemos hacer es, en lenguaje PHP -o vuestro lenguaje utilizado- volver a validar los datos recibidos desde el usuario, ¡PERO HAY MÁS! Es obligatorio agregar «disparadores» y «restricciones» incrustados en nuestra base de datos (recomendamos PostgreSQL por su capacidad de incluso aceptar guiones en lenguaje Python) para volver a validar datos al agregar los datos a nuestro motor informático. Más detalles escapan de esta entrada, pero este resumen es el mejor que podemos expresar al respecto.
Ejecutando PHP curl en modo de depuración.
«Verbose» en idioma inglés describe un modo de hablar más de lo necesario. Pero en nuestro mundo del software libre nuestra búsqueda del conocimiento es insaciable, «solo sabemos que no sabemos nada» por ello le dedicamos esta sección empinada a ahondar en PHP curl. Aparte de aprender más y mantener nuestro cerebro haciendo ejercicios, debido a la gran cantidad de protocolos y opciones es sumamente fácil para nosotros el cometer errores solicitando opciones inexistentes o incompatibles entre ellas, si son varios los parámetros que les pasemos.
Para activar el modo de depuración -vamos que la traducción al castellano de «verboso» no cuela- en PHP curl echamos mano de la alternativa CURLOPT_VERBOSE en la ya consabida función curl_opt() ¡pero esperen -como dice el «infomercial» de T.V.- hay más! PHP curl, dijimos, lo tenemos claro, emplea stdin y stdout que son los más conocidos pero también utiliza stderr ¡para algo que no es error, sino DEPURACIÓN! Teoricamente no debería ser pero en la práctica, el mundo real esto es de facto que lo hacen -y haremos-: capturar el stderr para llevar los mensajes de depuración hacia un archivo de escritura y de adición. Este archivo si no está creado, lo hace, y lo abre para agregar dichos datos y si existe le adiciona al final, de tal manera que llevamos una especie de bitácora para nuestro estudio y control.
$ObjCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt ($ObjCurl, CURLOPT_URL, «http://www.soporteweb.com»)
or exit(«No se pudo establecer la URL.
«);
curl_setopt($ObjCurl, CURLOPT_VERBOSE, 1)
or exit(«No se pudo establecer el modo de depuración.
«);
$verbose_arch = fopen(‘verbose.txt’, ‘a’); curl_setopt($ObjCurl, CURLOPT_STDERR, $verbose_arch)
or exit(«No se pudo establecer CURLOPT_STDERR
.»);
curl_exec ($ObjCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($ObjCurl);
?>[/cc]
Y veremos algo parecido a esto:
CURLOPT_VERBOSE
Explicamos que:
Las líneas que comienza con un asterisco son mensajes informativos de PHP curl.
Las líneas que comienzan con «>» es información que se le envia al servidor web, ftp, etc.
Las líneas que comienzan con «<» es la información que recibimos de tal servidor.
Los servidores web basados en ASP.NET devolverán un error «HTTP/1.1 500 Internal Server Error» y no podremos hacer nada ya que no se rigen por las normas comunes basadas en RFC y recomendaciones de WWW.
Otros usos para PHP curl.
Por nuestros experimentos vimos que PHP curl permite grabar en archivos «flujos de datos» de una manera básica, sin estar amarrado a protocolos (si lo usamos con FTP veremos que nos hacen falta los comandos populares y que solo podremos usar si tenemos un cliente FTP como tal). Eso deja abierta la posiblidad a darle infinidad de usos sin siquiera saber -ni preocuparnos- «con quien estamos hablando». Un ejemplo de ello es con el acceso a servidores con tecnología ASP.NET o la mismisa consulta de nuestra dirección IP que devuelve un resultado no normalizado ni con metadato alguno (solo nosotros, seres humanos, estamos con la plena certeza que es una dirección IPv4).
Por ejemplo, si en vez de usar soporteweb.com para retribuir nuestra dirección IPv4 usamos el servicio que presta icanhazip.com en el modo de depuración veremos algo como esto:
icanhazip.com Get the facts
Y al seguir el enlace indicado abrimos el blog de Major Hayden (sí, ese es el nombre, no no es mayor de ningún ejército ni alcalde de ninguna ciudad) un administrador de sistemas GNU/Linux con 6 años de experiencia quien ha tenido excelentes maestros y está dispuesto siempre aprender… como nosotros mismos, quienes escribimos y quienes leemos este humilde sitio web.
Auguramos que curl y PH curl seguirá creciendo y mejorando para nuestro beneplácito y que nosotros, a la larga, algún día aportaremos nuestro granito de arena a la causa del software libre, de una u otra manera, de manera inexorable.
curl_setopt(): parámetros mas socorridos.
La lista es larga en verdad pero mencionaremos, al menos, los que avizoramos de alguna utilidad dada la experiencia que hemos logrado a lo largo de los años:
CURLOPT_USERAGENT
Con esta opción podremos indicarle al servidor con el cual le estamos requiriendo información acerca de nuestra identidad. Curiosamente PHP curl por defecto no envía indentificación alguna acerca del nombre del software pero es que también el servidor que atiende la consulta tampoco la requiere como obligatoria. En la práctica les mostramos (las direcciones IP las ocultamos -junto con otros detalles- de las visitas a esta vuestra página web):
PHP curl no se identifica -por defecto-
Así que le aplicamos código y así quedaría la visita de nuestro bot en cierne:
Usando PHP curl CURLOPT_USERAGENT
CURLOPT_CONNECTTIMEOUT
A veces estimamos en cuánto tiempo debería responder determinado proceso y si no se realiza pues no está bien afinado nuestro servidor no sin antes descartar fallas de internet, etc. Para ello CURLOPT_CONNECTTIMEOUT es el idóneo para que nuestro script no se cuelgue indefinidamente, al cabo de cierto tiempo que le establezcamos y si no logra conectar con el servidor la tarea finalizará. El tercer parámetro que pasaríamos a continuación es el número de segundos, lo cual es una eternidad en tiempo de computadores, por ello también contamos con CURLOPT_CONNECTIONTIMEOUT_MS que viene expresado en milisegundos si estamos realmente apurados.
Es una excelente opción para desarrollar herramientas de diagnóstico a equipos remotos y podremos llevar un ergistro de eventos en nuestra base de datos (sí, que ya hay mucho software para eso pero también hay tareas tan pequeñas que no necesitamos «una mandarria sino un simple martillito»)
CURLOPT_COOKIE y CURLOPT_COOKIEFILE
Una «cookie» en inglés o galletita en castellano, es una pieza de información que plantan los servidores web en nuestros navegadores para identificarnos de manera absoluta. Al igual que el método POST debemos saber el nombre de la galletita y por ende su contenido, así que no la generamos nosotros -obvio- pero si debemos tener una para poder obtener respuesta de algunos servidores, quienes comparan si tienen la galletita en su lista de memoria (las galletitas tienen vencimiento o validez en el tiempo) y así podrán:
bien sea aceptar nuestra petición ó
incluso devolvernos unos valores personalizados.
De allí viene el gran temor a la violación de nuestra privacidad, una delgada línea demarca las buenas de las malas intenciones.
De esto último viene la necesidad de CURLOPT_COOKIEFILE, muchas veces son tantas las galletitas usadas por nosotros los programadores que mejor es enviar un archivo completo con ellas incluídas. Aquí debemos colocar el nombre del archivo en la opción anterior debemos enviar los valores en sí.
Otra manera de pasar una gran cantidad de galletitas es pasar el jarrón completo, un fichero, y para que no se nos olvide la sintaxis le pusieron el curioso nombre CURLOPT_COOKIEJAR. Un ejemplo sería:
Con esta opción podemos deshabilitar que verifique certificados en una conexión https (o mejor dicho TLS). Esto normalmente está habilitado pero uno a veces necesita, por economía, un certificado autofirmado el cual no está validado ante ningún tercer ente. Con esta opción cambiada a false en el tercer parámetro evitaremos este problemita.
CURLOPT_FOLLOWLOCATION
Actualmente las redirecciones de página se ha vuelto el pan nuestro de cada día motivado a la popularidad de las páginas web. Una página de cualquier gobierno del mundo de muy seguro que tendrá miles y hasta millones de visitantes y como comprenderán un solo servidor web jamás ni nunca se daría abasto. Lo que se ha inventado es poner granjas de servidores en distintas partes del mundo con copias constantes de los dominios deseados y redireccionado el tráfico con ayuda de potentes DNS: todo esto se conoce como CDN o «Content Delivery Network».
La idea del asunto es que cuando uno solicita una página web los DNS encargados redireccionan nuestra solicitud a la granja de servidores más cerca a nosotros de manera geográfica donde habrá una copia de la web que queremos. ¿A qué viene todo este cuento con PHP curl? Que es muy probable que la respuesta que obtengamos será una cabecera tipo 300 indicandonos que la direcciíon adecuadad para nosotros y entonces volvemos a hacer la petición -la misma petición- pero a otro servidor más cercano (o mas desocupado, o que tenga nuestra idioma, etc. -el que nos convenga-).
PHP curl ya está preparado en ese escenario y estableceremos CURLOPT_FOLLOWLOCATION a verdadero y por defecto PHP curl redireccionará hasta un máximo de 5 oportunidades nuestra solicitud (más adelante veremos otra función que nos dirá cuántas redirecciones siguió con la variable CURLINFO_REDIRECT_COUNT establecida).
Un problema se presenta al hacer una consulta POST: después del primer redireccionamiento PHP curl NO HACE una consulta POST sino una consulta GET (por razones históricas y de costumbres en los navegadores) y esto es un problema porque son métodos distintos y no obtendremos respuesta (aparte de que nos volveremos «locos» buscando dónde está el error). Para prevenir este inconveniente en vez de fijar CURLOPT_POST a «true» tomaremos otra opción, CURLOPT_CUSTOMREQUEST fijado a «POST»:
Otra advertencia más: cuando uno sube archivos por medio de CURLOPT_POSTFIELDS en la segunda redirección no será enviado dicho fichero. También para prevenir esto urge emplear CURLOPT_POSTREDIR fijado el valor a 3 para que maneje los redireccionamientos 301 y 302 reenviando el archivo en cada oportunidad (es más tráfico de datos pero ¿cómo hacemos con los CDN’s que llegaron para quedarse?).
Panorama general del resto de las opciones de curl_setopt()
Ya en este punto os habreis dado cuenta de la importancia de esta función, recordad que solo hemos visto apenas cuatro que van en este orden: curl_init(), curl_setopt(), curl_exec() y curl_close(); pues bien hay 23 funciones más de las cuales más adelante estudiaremos una de ellas (por ahora).
He aquí un listado clasificado por el tipo de contenido que hay que pasar en el tercer parámetro de curl_setopt(), de un vistazo (en marrón las que hemos visto y analizado):
Aquellas cuyo valor debe ser booleano (verdadero<>0 ó falso=0):
Aquellas cuyo valor debe ser un recurso de flujo de datos:
CURLOPT_FILE
CURLOPT_INFILE
CURLOPT_STDERR
CURLOPT_WRITEHEADER
Aquellas cuyo valor debe ser una función o una función de cierre:
CURLOPT_HEADERFUNCTION
CURLOPT_PASSWDFUNCTION
CURLOPT_PROGRESSFUNCTION
CURLOPT_READFUNCTION
CURLOPT_WRITEFUNCTION
Aquellas cuyo valor debe ser una muy específica:
CURLOPT_SHARE
Función curl_setopt_array.
Nos dimos cuenta como la función exit() mejoró muy bien la legilibilidad de nuestro código y además proporciona información a nuestros usuarios en caso de tratamiento de excepciones. Pero hay una manera aún mejor de configurar las opciones justo antes de ejecutar curl_exec() con el detalle que es como la famosa película de vaqueros: tiene lo bueno, lo malo y lo feo pero sin lo feo. Lo bueno -y muy bueno- es que como dijimos mejora la apariencia de nuestro código y abre nuevas posibilidades con el uso de una matriz: podemos realizar una función que consulte una base de datos y llene dicha matriz. Lo malo es que al pasar todo de un solo golpe a la unficón ésta acepta todo o no acepta nada y tendremos nuestra bella salida diciendo «no se pudo establecer culr_setopt_array» pero no nos indicará dónde, cuál es el elemento que falla.
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«); $opciones = array(
CURLOPT_URL => ‘https://icanhazip.com’,
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose );
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Percataos que colocamos el URL en la matriz para abultar y activamos el modo de depuración de resto todo lo demás es el mismo ejemplo que colocamos anteriormente. Lo curioso del asunto es que curl_setopt() y curl_setopt_array() pueden trabajar juntos perfectamente, lo anterior lo podemos reescribir como lo próximo y funciona plenamente:
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt($objCurl, CURLOPT_URL ,’https://icanhazip.com’)
or exit(«No se pudo establecer el CULROPT_URL»);
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«); $opciones = array(
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose );
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Analizando los resultados de la última conexión.
Comentamos que PHP curl puede utilizarse para fabricar una sencilla herramienta de monitoreo de servidores. Pensando en esto indagamos en ciertas opciones que trae la librería y de la cual podemos obtener gran cantidad de información, siempre pensando en guardarlo en una base de datos para su posterior análisis de manera masiva. Pero debemos comenzar por lo básico y no irnos precipitadamente.
Aparte de las opciones de depuración, que ya logramos vertirlas en un archivo que llamamos simplemente «verbose.txt» (y cuyo nombre podemos cambiar a la fecha y hora actual para que siempre sea un archivo distinto y almacenar -o borrar, o procesar, etc.- cuando queramos) podemos echar mano de otra función para obtener los datos de la conexión. Tal función es denominada curl_getinfo() a la que introducimos nuestro manejador creado por curl_init().
Esta función devuelve falso si no tiene información o una matriz con elementos predefinidos -no todos-. Para poder escribir esta matriz en un archivo agarramos a la función serialize() para convertirla en una cadena de texto antes de guardarla.
De una vez vamos a la práctica con el primer ejemplo que presentamos, el más «refinado» con las llamadas exit() ¿lo recordais? Pero vamos un paso adelante y lo modificamos, primero para que tome la URL por el método GET: escribimos en la barra de direcciones la ubicación de nuestro guion y al final agregamos un signo de cierre de interrogante con la palabra «url», luego un signo de igualdad y a continuación el dominio o página que queremos descargar y guardar -para luego analizar según el propósito que tengamos, que para cada persona es muy variopinto. Supongamos que nuestro guion está en nuestro servidor local y se llama «curl.php», el llamado sería el siguiente (obvien el prefijo «http://» porque lo agregamos en el script):
También agregaremos dos mensajes adicionales: si no se pasa una URL entonces alerta que debe pasar una y otro mensaje para indicar que ha sido guardada en un archivo (recordad que usamos la opcion CURLOPT_RETURNTRANSFER al valor de 1). Coloreamos el código para su mayor comprensión:
if ($_GET["url"]){ $objCurl = curl_init("http://".$_GET["url"])
or exit("No se pudo inicializar PHP curl.
");
$nom_arch = ‘servidor.html’; $arch = fopen( $nom_arch , «a»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_setopt ($objCurl, CURLOPT_CONNECTTIMEOUT, 7)
or exit(«No se pudo establecer CURLOPT_CONNECTTIMEOUT.
«); curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
$nom_arch = «servidor_respuesta.txt»; $archivo = fopen($nom_arch, «a»)
or exit(«No se pudo abrir el archivo'».$nom_arch.»‘
«);
$resp = curl_getinfo($objCurl)
or exit(«No se pudo obtener información de la ultima conexion.
«);
fwrite($archivo, serialize($resp))
or exit(«No se pudo escribir en el archivo ‘».$nom_arch.»‘
«);
fclose($archivo)
or exit(«No se pudo cerrar el archivo ‘».$nom_arch.»‘
«);
// curl_close NO devuelve resultado: curl_close ($objCurl);
echo «URL descargada y guardada.
«; } else {
echo «Debe pasar una URL para ser descargada y analizada.
«; }
?>
[/cc]
Es crucial llamar esta función ANTES de llamar la función curl_close() que es cuando aún existe el objeto en memoria.
Matrix con campos predefinidos.
Esos datos que guardamos en el anterior software que inventamos ya están seleccionados por los desarrolladores de PHP curl y son los siguientes (repetimos, NO son todos los disponibles):
«url»
«content_type»
«http_code»
«header_size»
«request_size»
«filetime»
«ssl_verify_result»
«redirect_count»
«total_time»
«namelookup_time»
«connect_time»
«pretransfer_time»
«size_upload»
«size_download»
«speed_download»
«speed_upload»
«download_content_length»
«upload_content_length»
«starttransfer_time»
«redirect_time»
«certinfo»
«primary_ip»
«primary_port»
«local_ip»
«local_port»
«redirect_url»
«request_header» (solamente está definido si CURLINFO_HEADER_OUT está establecido por una llamada previa a curl_setopt())
Totalidad de los campos de get_info()
Podemos solicitar cualquiera de estos campos pasando como parámetro los siguientes valores a la función curl_getinfo() -con una breve descripción y ordenados alfabéticamente-:
CURLINFO_APPCONNECT_TIME – Tiempo, en segundos, desde el inicio hasta la conexión/apretón de manos SSL/SSH del host remoto.
CURLINFO_CERTINFO – Serie de certificados TLS.
CURLINFO_CONDITION_UNMET – Información del condicional de timepo unmet.
CURLINFO_CONNECT_TIME – Tiempo, en segundos, que tomó el establecimiento de la conexión.
CURLINFO_CONTENT_LENGTH_DOWNLOAD – Logitud del contenido de la descarga, leída desde el campo “Content-Length:”.
CURLINFO_CONTENT_LENGTH_UPLOAD – Tamaño especificado de subida .
CURLINFO_CONTENT_TYPE – “Content-Type:” del documento solicitado. NULL indica que el servidor no envío un encabezado “Content-Type:” válido.
CURLINFO_COOKIELIST – Todas las cookies conocidas.
CURLINFO_EFFECTIVE_URL – Último URL efectivo.
CURLINFO_FILETIME – Hora del documento remoto obtenido; si devuelve -1, la hora del documento es desconocida.
CURLINFO_FTP_ENTRY_PATH – Ruta de entrada en el servidor FTP.
CURLINFO_HEADER_OUT – El string de la petición enviada. Para que funcione, se ha de añadir la opción CURLINFO_HEADER_OUT al manejador, llamando a curl_setopt()
CURLINFO_HEADER_SIZE – Tamaño total de los encabezados recibidos.
CURLINFO_HTTP_CODE – Último código HTTP recibido.
CURLINFO_HTTP_CONNECTCODE – El código de respuesta de CONNECT.
CURLINFO_HTTPAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticación disponible/s de acuerdo a la respuesta anterior.
CURLINFO_LOCAL_IP – Dirección IP local (fuente) de la conexión más reciente.
CURLINFO_LOCAL_PORT – Puerto local (fuente) de la conexión más reciente.
CURLINFO_NAMELOOKUP_TIME – Tiempo, en segundos, en resolver el nombre.
CURLINFO_NUM_CONNECTS – Número de conexiones que curl ha tenido que crear para lograr la transferencia anterior.
CURLINFO_OS_ERRNO – Número de error (errno) de un fallo de conexion. Es número es específico de cada SO y sistema.
CURLINFO_PRETRANSFER_TIME – Tiempo, en segundos, desde el inicio hasta justo antes de que comience la transferencia del fichero.
CURLINFO_PRIMARY_IP – Dirección IP de la conexión más reciente.
CURLINFO_PRIMARY_PORT – Puerto de destino de la conexión más reciente.
CURLINFO_PRIVATE – Datos privados asociados a este manejador de cURL, previamente establecidos con la opción CURLOPT_PRIVATE de curl_setopt()
CURLINFO_PROXYAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticaición proxy disponible/s de acuerdo a la respuesta anterior.
CURLINFO_REDIRECT_COUNT – Número de redireccionamientos, con la opción CURLOPT_FOLLOWLOCATION habilitada.
CURLINFO_REDIRECT_TIME – Tiempo, en segundos, de todos los pasos de redireción antes de que la última transación haya empezado, con la opción CURLOPT_FOLLOWLOCATION habilitada.
CURLINFO_REDIRECT_URL – Con la opción CURLOPT_FOLLOWLOCATION inhabilitada: URL de redirección encontrado en la última transacción, que debería ser solicitado manualmente luego. Con la opción CURLOPT_FOLLOWLOCATION habilitada: está vacío. El URL de redirección en este caso está disponible en CURLINFO_EFFECTIVE_URL
CURLINFO_REQUEST_SIZE – Tamaño total de las peticiones realizadas, actualmente solo para peticiones HTTP.
CURLINFO_RESPONSE_CODE – El último código de respuesta.
CURLINFO_RTSP_CLIENT_CSEQ – Siguiente CSeq cliente de RTSP.
CURLINFO_SSL_VERIFYRESULT – Resultado de la verificación del certificado SSL solicitado por la opción CURLOPT_SSL_VERIFYPEER.
CURLINFO_STARTTRANSFER_TIME – Tiempo, en sengudos, hasta que el primer byte está a punto de transferirse.
CURLINFO_TOTAL_TIME – Duración total, en segundos, de última transferencia.
Futuro de cURL.
Como bien es sabido por todos nosotros, Internet como tal está basado en las siete capas de red según el modelo de interconexión de sistemas abiertos (ISO/IEC 7498-1), más conocido como “modelo OSI”, (en inglés, Open System Interconnection) y cURL hace uso de la séptima capa para las transferencias por internet orientadas a ficheros. Por ello su autor Daniel Stenberg deja bien claro que eso es lo que seguirá haciendo cURL ahora y durante mucho tiempo. A continuación una traducción automatizada de su entrada en el blog al respecto:
No soy de los que pasan el tiempo mirando hacia el horizonte soñando con la grandeza futura y haciendo planes sobre cómo ir allí. Trabajo en cosas ahora mismo para trabajar mañana. No tengo idea de lo que haremos y trabajaremos en un año a partir de ahora. Conozco un montón de cosas en las que quiero trabajar a continuación, pero no estoy seguro de si alguna vez llegaré a ellas o si realmente enviarán o si tal vez serán reemplazadas por otras cosas en esa lista antes de que llegue a ellas.
El mundo, Internet y las transferencias cambian constantemente y nos estamos adaptando. No hay sueños a largo plazo más que apegarse al plan simple y único: hacemos transferencias de Internet orientadas a archivos utilizando protocolos de capa de aplicación.
Las estimaciones aproximadas dicen que ya podemos tener mil millones de usuarios. Lo más probable es que si las cosas no cambian demasiado drásticamente sin que podamos mantener el ritmo, tendremos incluso más en el futuro.
Resumen.
Recuerden lo que siempre dijo en vida nuestro Gran Maestro: «un punto, un punto y una línea recta«; aprovechen estos conocimientos para desarrollar programas y utilidades para fortalecer el Patrimonio Tecnológico de nuestra Humanidad no para escribir virus y gusanos que marguen las vidas de los demás.
<Esto es todo, pora ahora>.
Actualizado el sábado 27 de enero de 2018.
Recientemente, pocos días atrás, el creador de cURL, Daniel Stenberg, publicó la versión 7.58 la cual contiene una curiosa correción al proceso de agregar un «espacio en blanco» (sí, un simple y vulgar espacio en blanco) en el «pase» de las cabeceras URL (ver en GitHub el causante de este desaguisado) lo cual nos parece muy significativo, pues somos de los que insistimos y somos fastidiosos en corregir hasta el último caracter al programar (si véis algún error por estos lares hacednos un comentario abajo). Pero no somos los únicos, mirad el siguiente «tuit»:
Se acaba de parchear cURL para #Debian 9. Un "espacio en blanco" que lo machaba solo: https://t.co/LSr1zr5NNU Sí, un espacio en blanco (para los que me llaman "rompe pe…" cuando les corrijo los putos espacios :'D).


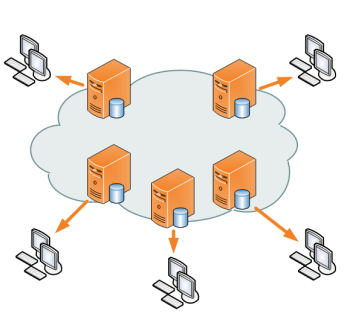
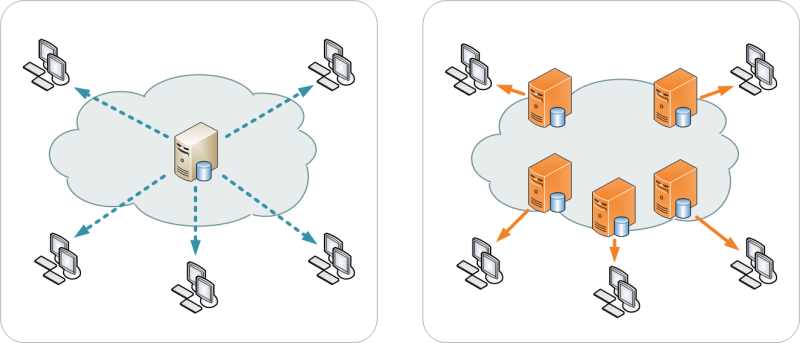









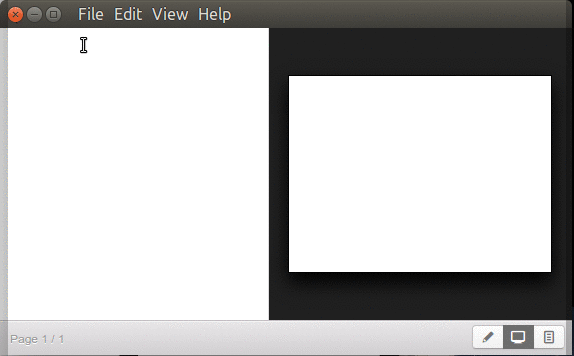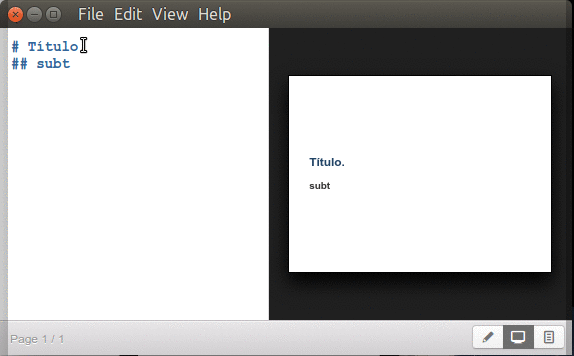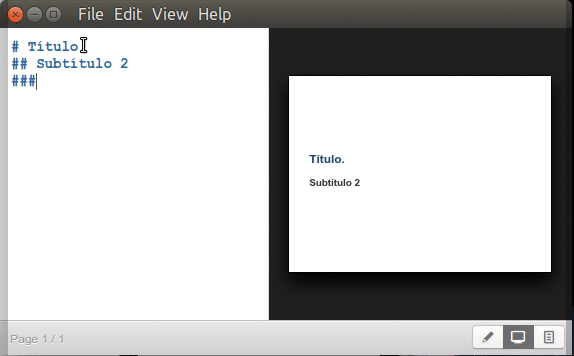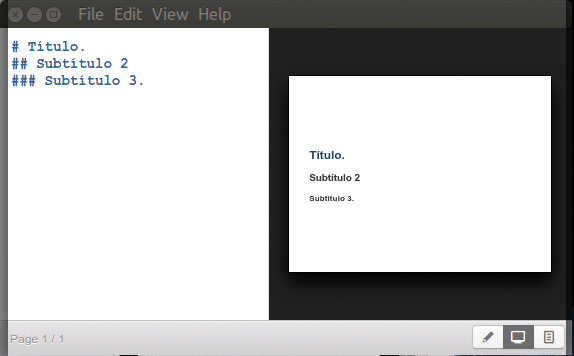
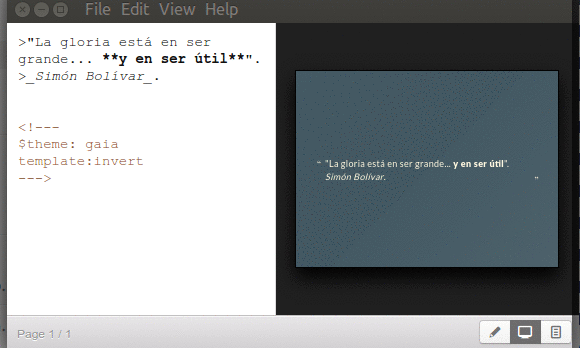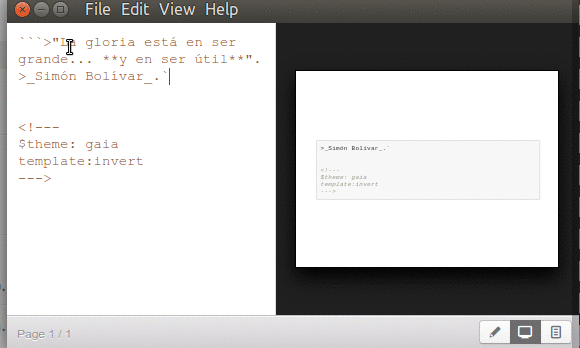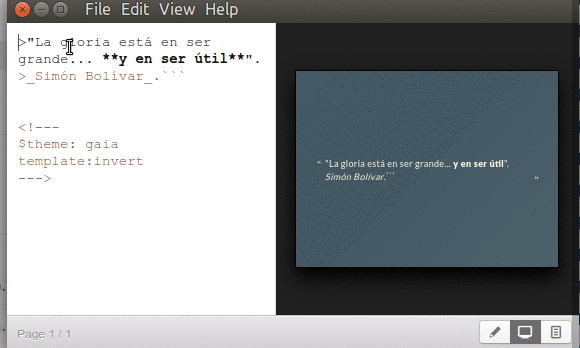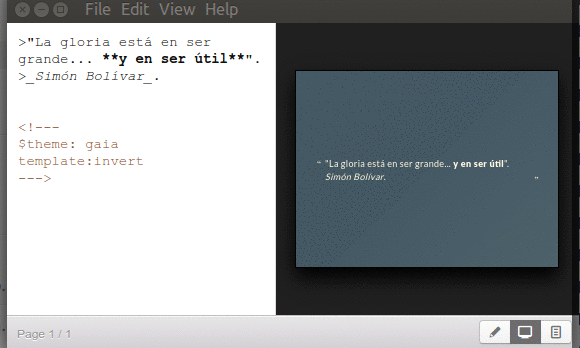
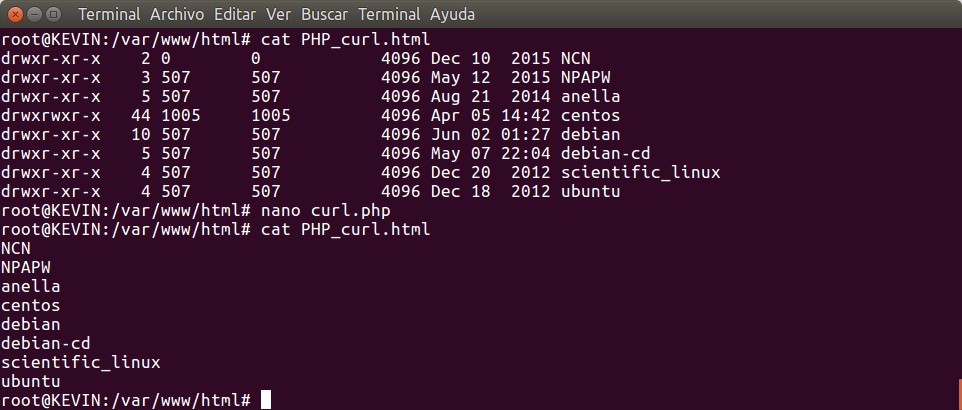
{kind=link}
{kind=link}