PostgreSQL10 incluye una gran cantidad de mejoras y novedades, como replicación lógica nativa, particionado de tablas declarativo y un paralelismo de consulta mejorada. Otro aspecto a tener en cuenta es el cambio de formato en la versiones, utilizando números con decimales para las versiones menores (por ejemplo, 10.1) y unidades enteras para las mayores (por ejemplo, 11).
De antemano os decimos que libre no quiere decir necesariamente que es gratis: una cosa es compartir y enseñar y otra muy distinta es que trabajemos gratis. Manejamos el Software Libre (así, con mayúsculas, porque es un ente) desde el punto de vista del servicio, de horas trabajadas, de que podemos automatizar las tareas, sí pero que la instalación, monitorización y mantenimiento (en ese orden) ocasiona «horas hombre» u «horas mujer» de trabajo duro y que conlleva una gran responsabilidad, éso es por lo que cobramos. Ahora bien, allá aquellos que piensan que trabajamos encerrados en «neveras» con nuestros ordenadores y que nos las pasamos «tuiteando», bueno tratamos siempre de convencer, que es más importante que vencer; tercer sábado de septiembre ¡FELIZ DÍA DEL SOFTWARE LIBRE!
Por supuesto que no estamos hablando del elemento químico cromo («chromium» en inglés) sino del popular navegador web de código abierto para todos. Lo que desarrollaremos es una «extensión», una herramienta integrada al navegador y que tiene muy diferentes propósitos. Con fines didácticos haremos una extensión muy sencilla que nos redirige hacia una página web que nos devuelve simplemente nuestra propia dirección IPv4, ¡manos al teclado!
El día de ayer por medio del perfil de línea de tiempo del Doctor Juan González observamos el interesante artículo tutorial sobre Python publicado por Juan J. Merelo Guervós el cual incluye retos de programación. Ni tardo ni perezoso, a pesar de llegar cansado a mi hogar, y tras una vigorizante taza de café negro con leche de avena sin azúcar nos dimos a la tarea de practicar algunas cositas para mantener el cerebro en forma y al día con las novedades en programación.
Nos empeñamos en realizar tutoriales pero en este caso vamos a realizar una simple revisión a un software novísimo: Marp. Esta entrada viene a colación por un «tuit» del sr. Aitor León desde Sevilla, España donde hace un autorecordatorio sobre un software del cual nosotros no habíamos escuchado antes y que nos llamó la atención porque le aplicó la etiqueta #MarkDown:
Nota mental: probar #Marp para presentaciones con #Markdown
Ni tardo ni perezosos indagamos y he aquí lo que pudimos aprender, lo cual humildemente compartimos con el mundo entero de habla castellana.
Inicio y desarrollo de Marp.
Un paso para comenzar.
Ya bien dice el refrán que todo viaje, por muy largo que sea, comienza con un solo paso: el 11 de febrero de 2016 (hace una gran cantidad de tiempo en términos de ordenador japonés) se escribió el comienzo de Marp, el cual originalmente se llamaba MDSlide en su versión 0.0.1.
En mayo de 2016, luego de duro trabajo, MDSlide se transforma en Marp y la numeración de versiones correlativo corresponde a V0.0.6; al cambiar de nombre nace un repositorio nuevo y de MDSlide no quedan rastros… dice uno porque bien sabemos que el protocolo Git es distribuido y por ahí en algún disco fijo debe haber una copia, je, je, je. El logotipo es el ahora conocido y la verdad ya estaba bastante maduro: soporte para emoji, ecuaciones matemáticas (eso nos impresiona) e imágenes (recordad que se basa en MarkDown: se trabaja con teclado).
Ruta de trabajo.
Para octubre de 2016 se retoma el desarrollo debido a que escuchando las sugerencias de los usuarios se replantea todo y liberan la versión 0.0.9 y se declara un plan de trabajo para liberar la tan ansiada versión 1.0 . También debemos tomar en cuenta que Electron, el entorno de programación utilizado, también ha sido actualizado y eso «empuja» a Marp en cierta medida y a pesar de suficientes «pull requests» (copias del código fuente modificado por terceros que lo devuelven mejorado y/o con sugencias) que recibe el sr. Hattori, él ratifica que sigue en las riendas del proyecto y espera mejorarlo mucho gracias a sus usuarios y colaboradores. Pero en este punto reconoce que el modo de presentación es la parte más difícil y es algo que aún no han logrado pulir, pues es esa la característica que estuvimos buscando nosotros y no vemos por ningún lado (más adelante mostraremos su uso con ejemplos en castellano). La «discusión» es viva y candente (en inglés) e incluso se le llega a comparar con software privativo que lleva décadas en el mercado.
Última versión a la fecha de escribir este artículo.
En noviembre de 2016 liberan la versión 0.0.1 que es la versión que descargamos y probamos pero al abrirlo nos encontramos con una versión compilada a lenguaje de máquina y con una extraña versión 1.3.8 ¿En qué momento nos perdimos… de algo? De todos modos no especulemos nada aún, en la parte del licenciamiento veremos bien si realmente es «software libre» o de «fuente abierta».
Autoría.
Así nació Marp de las manos del Ingeniero de Software Web Yuki Hattori, graduado en « 公立はこだて未来大学 » («Public Hakodate Future University») y quien actualmente trabaja en la empresa «Speee, Inc.» en Tokio, Japón.
Ingeniero Yuki Hattori
El Ingeniero Hattori maneja una gran cantidad de lenguajes de programación (vamos que desayuna PHP, merienda con CSS, almuerza con Ruby, la merienda de la tarde la pasa con Node y cena con Rails) y nosotros que pensábamos que algo programamos, pues nos quedamos cortos (44% en otros lenguajes de programación ¿cuáles serán? Acá hace algo con SVG dinámico y en este enlace lo podéis probar y modificar cortesía de Phil Maurer).
Yuki Hattori lenguajes de programación más utilizados
Licencia de uso.
El repositorio oficial de Marp lo podéis encontrar en este enlace, y de sus múltiples secciones hemos leído y analizado la información para el presente artículo, esparamos os sea útil en algún modo.
En junio de 2016 el proyecto tiene un mes con su nombre actual Marp y deciden colocar correctamente la licencia de uso que corresponde a la del Instituto Tecnológico de Massachusetts (MIT) la cual no puede ser un simple enlace web, se debe colocar el encabezado con el año y el nombre del autor para luego copiar fielmente la licencia de uso del MIT y luego, si se quiere, el enlace web correspondiente.
De hecho múltiples organismos conservan una copia de dicha licencia y la más socorrida es la de «The Open Source Initiative»; vale la pena recordar entonces que una cosa es software libre y otra cosa es código fuente abierto: para no ser puristas el software libre es más antiguo y solo tiene 4 reglas básicas (aunque ha evolucionado) y el código fuente abierto deriva su filosofía del software libre y tiene 10 reglas básicas.
En julio de 2016 se reconoce que el proyecto contiene un trabajo realizado con anterioridad y que también posee licencia de uso del MIT: Katex el cual está escrito en JavaScript y CSS para representar gráficamente las tediosas fórmulas matemáticas. Nosotros que estudiamos ingeniería mecánica y nos tocó estudiar matemáticas avanzadas damos fe del tremendo trabajo de presentar informes y no tener un software adecuado para ello. Da un poco de vergüenza decirlo pero era rapídisimo realizarlo de forma manuscrita y presentable en hojas blancas que lo horroroso que quedaban con las impresoras de matríz de punto y el software que disponíamos. Hemos progresado hasta el punto que hoy tenemos presentaciones en un lenguaje de marcación ligero y sencillo, que puede representar las matemáticas como son ¡y de paso se puede exportar a formato pdf, increíble!
En este mismo mes se decide retirar el anuncio de licencia de uso de underscore.js ya que no se sigue utilizando como componente.
Página web oficial de Marp.
En este enlace se tiene una presentación bien cuidada acerca del software y orientada a los usuarios normales, no programadores. Podemos ver su características, un enlace al repositorio, un enlace para descargarlo, una rápida introducción a su uso, una guía a ejemplos más avanzados y una declaratoria de licencia de uso. Lo que nos llama poderosamente nuestra atención es la inserción de dos objetos web que presentan por diapositivas a Marp, dichos objetos fueron hechos en Deckset -software hecho en Alemania-el cual está también basado en MarkDown… ¿casualidad? Bueno acá el software de fuente abierta supera al privativo, pues no exporta en formato pdf… y podremos agregarle funcionalidades que consideremos haciendole un «fork» y haciendo nuestro propio proyecto (conservando la licencia de uso del MIT, por supuesto).
«Instalando» Marp.
Pues que si llamamos «instalar» a descargar un archivo y descomprimirlo, vale, «cuela» como instalación. Esta entrada no es tan compleja como otras que hemos hecho que analizamos lo más a fondo que podemos su código fuente, pero no os preocupéis, no perderemos de vista a Marp en el futuro. Repetimos, el repositorio está en esta dirección.
Usando Marp.
Pilares fundamentales de Marp.
Escribimos en MarkDown las presentaciones (y también podemos ver el resultado del MarkDown).
Se pueden escoger temas y fondos de pantalla para las presentaciones.
Soporta caracteres UNICODE (mejor conocidos como emojis).
Se puden escribir ecuaciones matemáticas con hermoso estilo.
Se puede exportar a formato PDF.
Haciendo presentaciones en MarkDown.
Retrospectiva.
Admitámoslo: realizar presentaciones es tedioso para los que no tenemos el talento para los gráficos. Somos empedernidos usuarios de la ventana terminal y por eso nos agrada mucho el MarkDown y su simple sintaxis para obetener una apariencia básica del HTML… ¡Pero esperen, hay más!
Desde que Github popularizara el Git con su alojamiento gratuito para proyectos públicos (que de acuerdo a la licencia de uso que tengan tendrán diferentes clasificaciones) y agregaron el uso de MarkDown acompañando a los repositorios con su respectiva sección Wiki, que también utiliza cierto «sabor» de MarkDown, y ahora con una ligera variante podremos hacer presentaciones rápidamente sobre nuestro trabajo ya hecho pues… ¡BINGO! ??
Hala, manos a la obra.
Aunque entre las carpetas descomprimidas hay una llamada «locales» hay un archivo llamado es.pak cuyo contenido abrimos con gedit y está escrito en castellano, no hallamos opción para cambiar el idioma inglés. Revisando el código fuente no hallamos referencia a dichos archivos .pak (hay bastantes idiomas) lo que imaginamos es que son «paquetes» o plantillas que se utilizan masivamente para internacionalizar nuestras aplicaciones… o simplemente será nuestra imaginación.
Dicho todo esto, os escribiremos en inglés las referencias que hagamos al programa Marp.
No nos afanéis buscando teclas de acceso directo -para hacer cualquier cosa- excepto las siguientes:
Marp, como es de esperarse, utiliza la misma extensión de fichero de los documentos MarkDown: .md (tal vez presentemos algún vahído porque estamos bien acostumbrados a que las presentaciones tienen sus propias extensiones según el software que las manipule).
Lo primero es abrir un archivo nuevo, vamos al menú desplegable «File» -> «New file» (o pulsamos las teclas CTRL+N). Sin más preámbulo se abre un «lienzo» de trabajo presto a escribir en el. En este lienzo a la izquierda escribimos nuestro código y a la derecha veremos inmediatamente nuestro trabajo de tres maneras distintas:
En modo de presentación, diapositiva por diapositiva (modo por defecto).
En modo de presentación, diapositivas en hilo o «carrousel».
En modo MarkDown, tal como se vería al publicarla en la página web de GitHub, por ejemplo (¡interesante!).
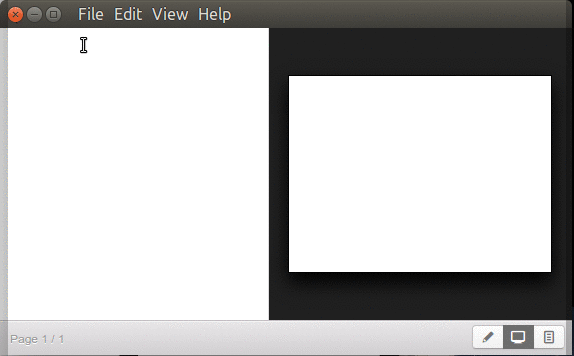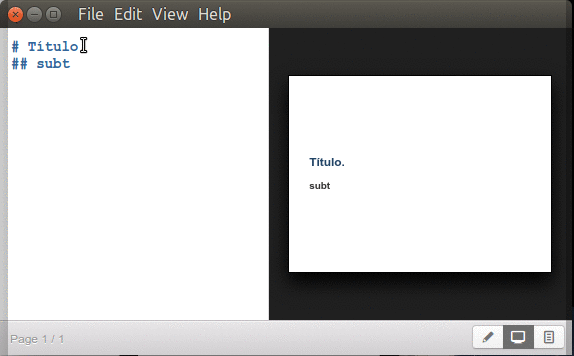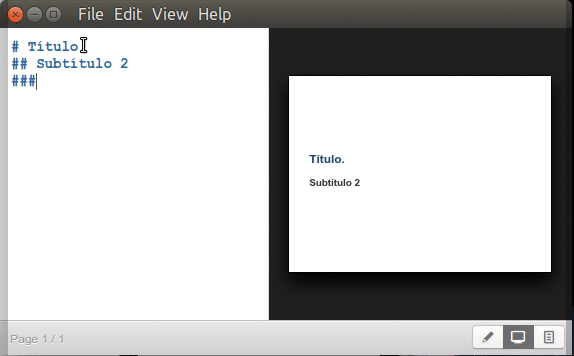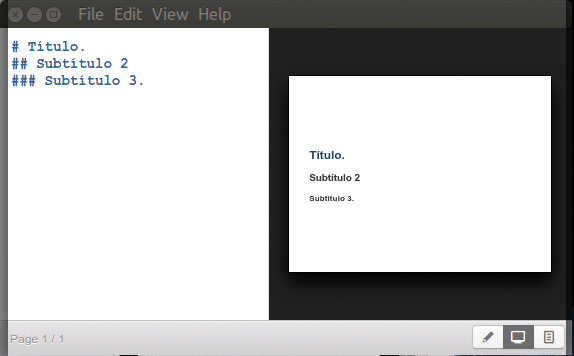
Títulos y subtítulos.
Inician con un símbolo numeral «#» seguido de un espacio y el texto para título principal y agregando dos o más numerales juntos -sin espacios- los subtítulos correspondientes (hasta un máximo de seis subniveles):
Marp títulos y subtítulos.
Nota 1: Marp como buen intérprete del MarkDown «original» soporta el uso de «=» y «-» (uno o más) en la línea inmediatamente inferior del texto para mostrar un encabezado de primer y segundo nivel. Pero si necesitamos de un tercer nivel necesitaremos tres numerales «###»… así que no vale la pena este método os aseguro.
Nota 2: Marp aplica a las imágenes un «realzamiento» su utilizamos numeral (es) delante de la declaración de imágenes, sin embargo «=» y «-» no funcionan en estos casos (no le busquen lógica a esto, por favor, no sabemos si es un «bug» o es algo hecho a propósito).
Realizando una segunda diapositiva.
Como véis el código MarkDown funciona y no es obejtivo de esta entrada mostraros su sintaxis por lo tanto vamos a enfocarnos en los comandos propios de Marp, que son apartes del MarkDown con el propósito de presentar nuestras diapositivas.
Tal como insertamos una línea horizontal en Markdown (tres guiones seguidos al principio de una línea) así agregaremos una segunda diapositiva, cuidando de dejar una línea en blanco antes y después:
Marp inserción de nueva diapositiva
Enumerando las diapositivas.
Para agregar el número de diapositiva en la esquina inferior derecha solo debemos agregar el siguiente código.
<!-- page_number: true -->
A partir de la diapositiva donde insertemos la orden serán numeradas hasta el final, si queremos que todas están numeradas la posicionaremos en la primera diapositiva; por el contrario, si queremos que una diapositiva en particular NO sea numerada modificaremos la directiva anterior agregandole un asterisco para indicar que se le aplique solo a esa diapositiva. Por supuesto, usaremos el valor verdadero o falso a nuestro gusto o necesidad.
Marp numeración de diapositivas
Directivas globales y directivas locales.
Lo que acabáis de ver «encerradas» entre comentarios tipo HTML «<!— comentario —>» por supuesto no se visualizan en nigún navegador o intérprete de MarkDown sin embargo Marp obtiene sus instrucciones de allí en el formato de una instrucción por línea separadas por dos puntos «:». Dichas instrucciones son llamadas directivas y como vimos serán globales -para todas las diapositivas, el documento completo- o solo para la diapositiva donde se encuentre la directiva que establezcamos siempre y cuando sean antecedidas por un asterisco.
Dado el caso que nos equivoquemos en la sintaxis pues simplemente Marp no las toma en cuenta ni ejecuta y no arroja ningún tipo de mensaje de excepción.
Directiva «$theme» y «template».
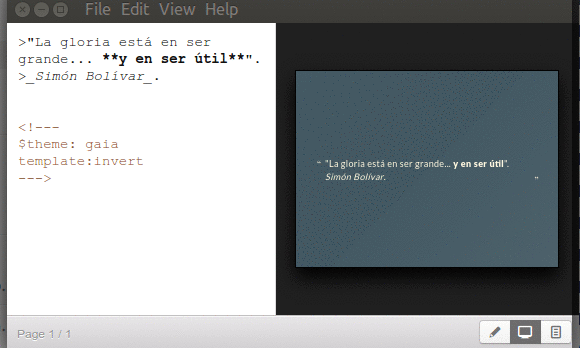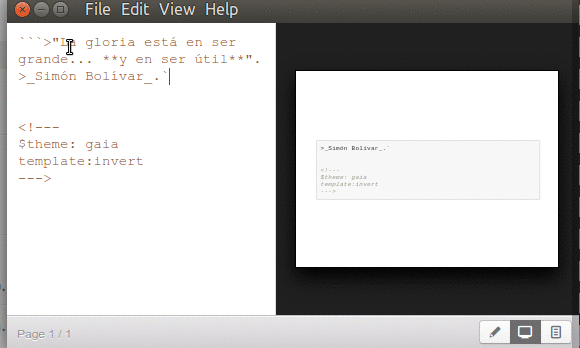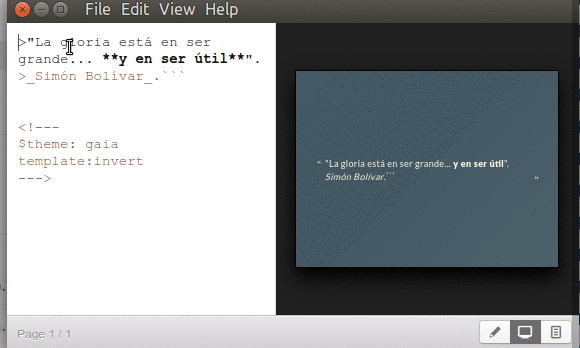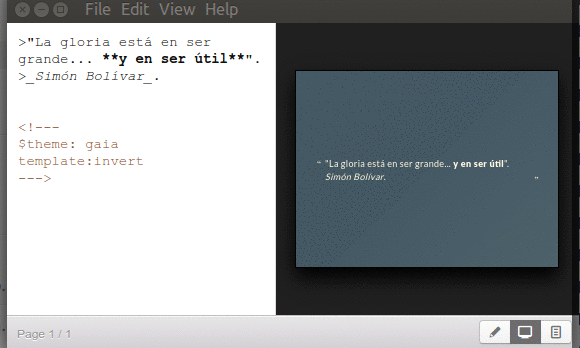
Marp soporta plantillas predeterminadas para nosotros dedicarnos a lo valioso de escribir los datos en las diapositivas, lo demás son «adornos de repostería». Al momento de escribir esto estaba disponible el tema gaia y de manera adicional con la directiva template:invert se tiene una inversión en los colores. Esto queda guardado en el documento de diapositivas para que Marp automáticamente la muestre al volver abrir el documento. Nota: si por el menú desplegable escogemos «View»->»Theme»->»default» -o cualquier otro tema que haya disponible- Marp obviará la directiva que hayamos establecida dentro de la diapositiva y mostrará la que le hayamos ordenado. Verbigracia:
Marp directiva theme y template
Marp directiva «footer».
Con esta directiva podremos establecer una frase en pie de página ya sea en todas las diapositivas o solo en la que le coloquemos la directiva, recordad el asterisco hace a la directiva local, mirad:
Marp directiva footer
Directiva $size
Esta directiva puede ser confusa porque se refiere a tamaño sin embargo presenta también unos valores que indican proporción pero si buscamos la lógica ambas son excluyentes mutuas y explicamos por qué: todo depende si nuestra presentación será por pantalla (primera opción para el 99% de los casos, vamos que hablamos de presentaciones por diapositivas). El otro asunto es si necesitamos imprimir dichas presentaciones.
Para la proporción tenemos «4:3» predeterminado para monitores normales y la mayoría de proyectores traen este valor por defecto y «16:9» para monitores «multimedia» -llamados así porque las películas son grabadas en esa proporción panorámica-.
Para el tamaño de papel tenemos desde A0 hasta A8 y B0 hasta B8, os adelantamos que el «tamaño carta» viene a ser A4 (mirad abajo en las fuentes consultadas el resto de los medidas de papel).
Por los dos puntos anteriores es que decimos que son mutuamente excluyentes.
Esta directiva solamente es global, recomendamos declararla al principio para un orden efectivo (hicimos pruebas y el asterisco lo que hace es inutlizarla).
Es indiferente que usemos mayúsculas o minúsculas en los tamaños de papel.
Marp lee de izquierda a derecha y el primer tamaño válido de papel o proporción lo aplica, el resto de los caracteres lo desecha (debería NO aplicar el formato o al menos indicar la excepción, pensamos).
No conseguimos hacer funcionar el prefijo documentado «-portrait», recordad que aún es un software en desarrollo y sus gazapos tendrá.
Marp directiva $size
Directivas $width y $height.
De necesitar un tamaño personalizado de papel, estas dos directivas son las adecuadas al caso y ambas heredan todo de la directiva $size por ello no os ponemos gif animado aunque si os podemos decir que si que funciona (¡vamos, animaros a descargar y probar Marp!) y las opciones disponibles son:
px: píxeles por defecto, no es necesario colocarle «px».
Por la razón anterior las siguientes unidades debéis colocarla juntitas sin espacio(o)s o si no lo interpretará como píxeles.
cm: centímetros.
mm: milímetros.
in: pulgadas «inches».
pt: puntos.
pc: picas.
En realidad dichas unidades son las utilizadas por CSSexcepto em (tamaño de fuente) y «%»; abajo en «Fuentes consultadas» (en idioma portugués) tenéis un enlace si queréis aprender más por vuestra cuenta.
Directiva «$prerender».
Antes de entrar de lleno con las imágenes os presentamos esta directiva especialmente hecha para indicarle a Marp que haga un preproceso de las imágenes de fondo en el caso de que éstas sean muy grandes, aligera el proceso con una carga previa de datos.
<!– prerender: true –>
Comando para mostrar imágenes.
Así como lo leeís, ya finalizamos las directivas y volvemos a los comandos de MarkDown en este caso os indicamos lo siguiente:
Para comenzar a insertar una imagen comenza por una línea en blanco donde colocareís  tal cual, incluyendo los paréntesis, son 8 caracteres en total.
Dentro de los corchetes rectos (paréntesis rectos) colocaréis el texto alterno si no se puede cargar la imagen, podéis dejarlo vacío pero el uso de los corchetes es obligatorio, de lo contrario no muestra imagen alguna.
Dentro de los paréntesis (curvos) pero fuera de las comillas dobles el nombre del fichero de la imagen (si reside en la misma carpeta de donde ejecutásteis Marp o una URL válida, local o internet).
La razón de utilizar una imagen desde internet es para mostrar los últimos valores o cifras relacionados con el tema de la presentación, de lo contrario llevad tus imágenes junto con el documento Marp
Entre la URL de la imagen y las comillas dobles debéis dejar un espacio -el mismo que consideramos al principio en el conjunto de 8 caracteres iniciales de declaración.
Dentro de las comillas dobles -que sí son opcionales- podemos colocar una breve descripción acerca de la imagen o una frase nemotécnica que podramos visualizar al pasar el puntero por encima de la imágen, tras lo cual al cabo de menos de un segundo se colocará una pequeña ventanita en blanco sobre negro con el texto que coloquemos.
Comando para mostrar imágenes de fondo.
Muchas personas querrán, en vez de utilizar o crear tema alguno, simplemente fijar una o más imágenes como fondo en las presentaciones. He aquí que Marp se toma la ligera licencia de tomar la sintaxis de las imágenes -en MarkDown– con la excepción que en los corchetes rectos colocamos el comando [bg] y por supuesto la URL local o remota de la imagen en sí. Dentro de los corchetes rectos acompañando a «bg» más un espacio podemos colocar un procentaje para redimensionar la imagen e incluso podemos colcoar varias imágenes siempre y cuando los porcentajes sumen 100% para garantizar visibilidad completa de cada imagen. El comando «bg» no soporta mayúsculas, disfrutad nuestras pruebas:
Marp fondo de diapositiva
Comandos para mostrar caracteres emoji.
Si se sorprenden por haber colocado los emoji como subsección de las imágenes preparaos a recibir una historia bien larga… vamos a tratar de resumirla lo mejor posible.
Por allá en los años ochenta cuando nosotros comenzamos a manipular computadoras y luego entramos a estudiar en la Universidad de Carabobo… ¡EA, ¿PARA DÓNDE VAÍS, QUEDAROS Y ESCUCHAD! ?
…? os contábamos que apenas teníamos computadoras de 16 bits XT y luego vinieron las de 32 bits -286, 386, etc- y en los años 90 se populariza -y hay hardware para manejarlo- el UNICODE que no es más que la representación codificada y gráfica -dibujada con papel y lápiz- de unos 65 mil y pico de caracteres- de la mayor parte de los alfabetos ideados por la humanidad. Allí se tuvo previsión de crear unos símbolos que representaban caras con diferentes estados de ánimo y objetos comunes, el gran problema era dibujarlos por pantalla Y ESO AÚN HOY EN DÍA ES DIFÍCIL DE HACERLO ¿por qué decimos esto?
Está bien, los sistemas operativos modernos manejan los códigos extendidos de UNICODE, con tan «poderosos» aparatos que tenemos faltaba más, faltaba menos. Pero a nivel de hardware, de tarjeta madre, aún no hemos visto que tengan dicho UNICODE grabado en firmware, los asiáticos han hecho hermosos BIOS gráficos pero que en realidad lo que hacen es cargar en memoria un mini sistema operativo con interfaz gráfica para su idiomas basados en ideogramas: AÚN NO SUCEDE QUE EL CPU ENVIE A UN MONITOR CUALQUIERA EL CÓDIGO BINARIO DE UN CARACTER UNICODE (EXTENDIDO) Y EL MONITOR TENGA «MEMORIA» PARA SABER COMO SE DIBUJA ¿Nos seguís el hilo? {Nota: todo monitor e impresora de matriz de puntos tiene en memoria cómo dibujar los 255 caracteres ASCII originales, pero hasta allí llegan, e incluso las impresoras a inyección de tinta y láser ¡perdieron esa capacidad!}.
Más aún, la genialidad de Steve Jobs, el fundador de Apple Computer -hoy la empresa más poderosa del mundo, incluso por encima de Microsoft e IBM juntas- fue el poner en práctica el trabajo desarrollado por Xerox Palo Alto (empresa aliada mutua con Apple) de fuentes tipográficas: pequeñísimas imágenes que computadoras con la suficiente potencia pueden dibujar rápidamente en pantalla imágenes que nosotros identificamos como «letras»… ¿y todo este discurso para qué? ?
Todo este discurso es para deciros que aún los sistemas operativos modernos NO POSEEN soporte nativo y por ende los navegadores web tienen que obtener de algún lado esas pequeñísimas imágenes que nosotros lamamos «letras» o, para este caso, emoticons.
Repetimos, lo simplificamos lo más que pudimos, en serio, no somos licenciados en computación pero como nos tocó vivir esa experiencia en carne propia, la evolución de los ordenadores (y escribimos, que algo queda para la posteridad de las generacioens futuras) pero a ese nivel da este tema.
Volviendo al tema de los emoticons o emoticones para castellanizar el término, revisamos el código fuente de Marp y observamos que utiliza dentro de sus dependencias (a esto nosotros lo llamamos librerías dinámicas) algo llamado «markdown-it-emoji» y a su vez buscamos en el código fuente de ese software unos «comandos» que permitan especificar los emoji en Marp.
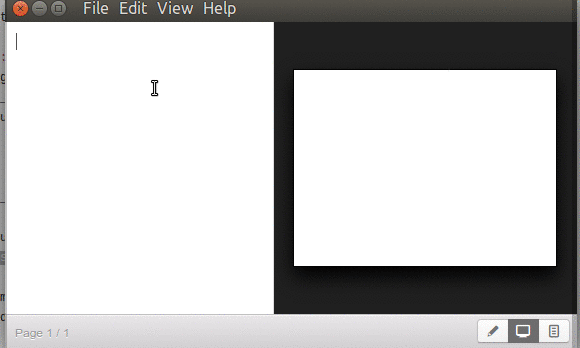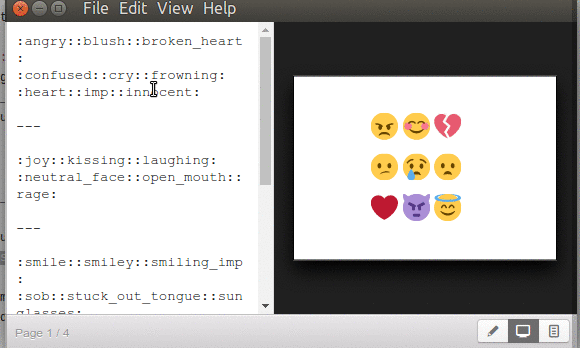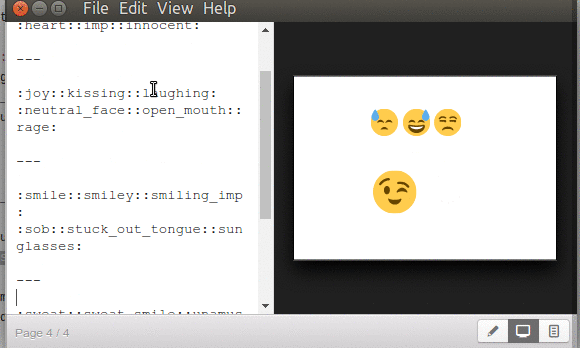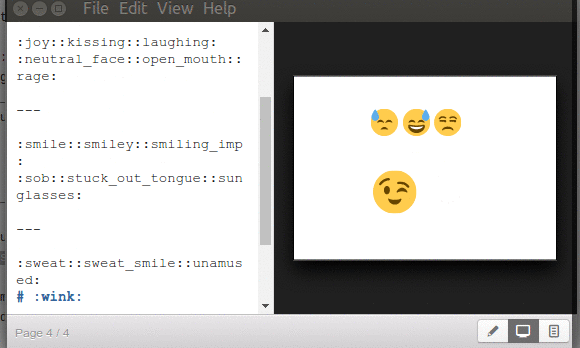
Para Marp un emoticon o emoji viene encerrado entre par de dos puntos «: :» y dentro, sin espacios viene la palabra clave con la cual se busca y se dibuja (imaginamos que al compilar Marp todas esas imágenes vienen a nuestro disco duro en el fichero ejecutable luego investigamos y nos dimos cuenta que a este proceso ELECTRON lo llama «Application Distribution«, con el archivo app.asar del cual podrán saber y entender su forma de almacenar la información en su propio repositorio).?
Ya para finalizar el tema de Marp y los emoticones, esos comandos o palabras claves (que no trae documentados cuántos ni cuales son) que os dijimos, los copiamos, encerramos entre «: :» y los pegamos en Marp para producir la siguiente captura (otra nota: los emoticones se ven afectados en tamaño si están precedidos como título «#», notad eso):
Podéis obtener una lista ampliada, nemotécnica, en este enlace cuyo encabezado anuncia las páginas web y/o aplicaciones que utilizan esos emoji. Por ejemplo :cat: es más fácil de memorizar que U1F408, caracter unicode, y que funciona sin problemas con Marp. En dicha página hacéis click en el emoji que os guste y es copaido la palabra clave con su par de dos puntos, y pegáis en MArp. Un código que no veréis es el de GitHub :octocat: (combinación de pulpo con gato) así que no es una lista definitiva, por ahora.
Ofrecemos disculpas por no haber investigado lo suficiente. Esa sí es una lista completa de los caracteres emoji y soportados por Marp porque forma parte de sus componentes y compilación.
Enlaces web.
Los enlaces web o hipervínculos en Marp los podemos declarar de forma implícita y explícita (forma recomendada):
De manera implícita: si escribís «http://» más un caracter cualquiera, Marp lo convierte de inmediato en un enlace a la derecha en la ventana de visualización. También cuela «www.» más al menos dos caracteres.
De forma explícita: como dicta el MarkDown: un par de corchetes rectos (opcionales) donde colocaremos el texto del enlace y un par de paréntesis (curvos) donde colocaremos el enlace web en sí mismo.
Marp enlaces web
Antes de hablar de las ecuaciones matemáticas…
…debemos indicaros que si necesitamos mostrar el código fuente en MarkDown a nuestra audiencia debemos encerrarlas entre triple comillas simples y Marp los interpretará como texto simple, es decir, no lo «ejecutará», no hará «parser».
Marp mostrar código MarkDown a la audiencia
Ecuaciones matemáticas.
Y acá lo que nos apasiona de tanto en tanto: las matemáticas, especialment el cálculo infinitesimal. Para ello Marp tiene un suplemento que debemos ingresar entre par de símbolos de pesos (o lo que sería con el paso del tiempo como símbolo de dólar). Cualquier texto que escribamos lo representa tal cual pero si lo antecedemos de cierta sintaxis comenzaremos a escribir nuestras fórmulas (no os preocupéis, no nos extenderemos mucho a favor de vuestra paciencia).
Fórmula de Euler.
Claro, cualquier texto lo representa tal cual…
… pero si lo antecedemos con un «_» tendremos un subíndice.
Con «^» lo convertiremos en superíndice.
Para agrupar estos subíndices o superíndices los encerramos entre llaves «{}»
Para multiplicar términos: «\cdot».
A «\cdot» le podemos agregar paréntesis para agrupar más términos.
Para mostrar tres puntos suspensivos: «\cdots».
¡También podemos combinar «\cdots()»!
Ya con esto podremos representar la famosa fórmula de Euler:
Marp formula de Euler
Nota: cada fórmula matemática debe ocupar una o más líneas completas, no podemos intercalar fórmulas en una línea, por ejemplo. Opinamos que debería hacerlo y hasta podemos clonar el repositorio y empezar a programar, para eso es el software libre.
Identidad de Euler.
Marp identidad de Euler
Símbolos y signos.
Es una lista larga, larguísima como la matemática misma pero los más comunes símbolos matemáticos tienen sus propios códigos:
Para representar ? usamos «\pi».
Para representar ?: «\phi»-
Para ?: «\theta»
Infinito: «\infty».
Operadores matemáticos simples y avanzados:
División: «\div».
Fracción: «\frac{}» -colocamos el numerador entre llaves y el denominador a continuación.
Sumatoria: «\sum» -la podemos combinar con superíndices y subíndices.
Raíz cuadrada: «\sqrt» más el número -o llaves, o paréntesis.
Paréntesis grandes, ideales para encerrar fracciones: «\Bigl(» y «\Bigl)».
Para representar integrales simples: «\int», dobles «\iint», triples «\iiint», integral de superficie «\oint».
Fórmula de cálculo de la constante e.
Marp cálculo de constante e
Exportar a formato PDF.
Probamos la exportación de archivos a formato PDF y no tuvimos ningún tipo de problema, si acaso un detalle que «no recuerda» los últimos archivos abiertos o guardados, «archivos recientes» les decimos. Incluso los emoticones fueron exportados y hermosamente dibujados -claro si originalmente fueron hechos en SVG nunca pierde calidad alguna al «pasar» de un lado a otro.
Conclusiones.
El software se ve realmente prometedor y aunque tiene la opción F11 pra verlo a pantalla completa no es lo mismo que un programa de presentación que se precie como tal: debe ser capaz no solo de usar las flechas de dirección del teclado para avanzar diapositivas sino que le falta aún programador de tiempo, música y lo más importante, ser capaz de detectar -y escoger- los múltiples monitores y/o proyectores que tengamos conectados a nuestro ordenador.
Esperamos os haya sido útil este vuestro -y nuestro- trabajo para la ampliación de conocimientos y saberes.
Cuando tuvimos que actualizar nuestros conocimientos sobre Diseño Asistido por Computadora (CAD) nuestra experiencia era limitada y amarrada al software privativo Autocad® y como estamos decididos a ser libres nos decantamos por Freecad para realizar nuestro trabajo. Comenzamos así nuestro aprendizaje, que sobre el tema abunda en internet pero quien de inmediato llamó nuestra atención por su trabajo estructurado y paciente fue «ObiJuan» González y su Escuela de Padawan’s «CloneWars». Por ello cuando tuvimos noticias de que se le había otorgado el premio de Google llamado O’Reilly Open Source Award en reconocimiento a su labor (aunque es tonto de nuestra parte) nos contentamos en sumo grado y de que no solamente el Software Libre esté en tan alto nivel en España sino que también el HARDWARE LIBRE está surgiendo en América tutelado por (a pocas personas llamamos por su título, y por sus títulos menos) el Ingeniero y Doctor Juan González Gómez.
El jueves 11 de mayo en Austin (Estados Unidos), durante la celebración del congreso mundial OSCON, fue entregado el premio O’Reilly 2017. Fueron creados en el año 2005 por Tim O’Reilly y hasta el 2009 llevaban el prefijo Google-O’Reilly pero hasta la fecha de hoy simplemente lleva el nombre O’Reilly Open Source Award: un reconocimiento a los individuos por su dedicación, innovación, liderazgo y destacada contribución al código abierto.
El premio, creado y organizado por Google en colaboración con la factoría de Tim O’Reilly, desde el 2005, se entregó este jueves 11 de mayo en Austin (Estados Unidos) durante la celebración del congreso mundial OSCON, evento que reúne a toda la comunidad de ingenieros y desarrolladores de software y hardware libre.
Es así que ObiJuán se ha ganado su hito en la muy famosa Wikipedia (hasta que Skynet? cobre conciencia de sí misma y borre nuestra adición de los ganadores del año 2017 en esa página, ja, ja, ja).
Ni os imagináis la ilusión que me hace aparecer en wikipedia?Este es el mayor de los premios¡Muchas gracias a todos!https://t.co/wgUTcNScTP
Eterno empedernido de la saga de películas «La Guerra de las Galaxias «Star Wars»» -¡ejem! nosotros también ?- se autodenomina por este juego de pronunciación en inglés y castellano del Maestro Jedi de los films Obi-Wan Kenobi como ObiJuán (nosotros castellanizamos aún más las cosas con la inclusión del acento) este madrileño ejemplar comenzó sus andanzas …
¡Este blog no va de ciencias sociales! No somos biógrafos de profesión, nuestra intención es dar justo reconocimiento al que «sabemos que sabe»; los lectores de este humilde portal y de nuestra cuenta Twitter pueden dar fe de que siempre reconocemos al que sabe más que nosotros y es así que aprendemos y luego difundimos el conocimiento adquirido. Sigamos pues, con nuestra entrada de hoy.
…comenzó sus andanzas en el servicio militar obligatorio («la mili») y es allí donde le «encasquetaron» el apodo por ser tan fanático de «Star Wars».
Ya desde el año 1996 «lidia» con Linux pero ya desde muy joven «lo que se le da» es lo de la informática. Sufrió lo mismo que Richard Stallman (y nosotros también desde los años 80): un mundo privativo donde te ofrecen «comprar, usar y desechar» * pero no preguntes cómo funciona*.
Uno de sus primeros cacharros fue ZX-Spectrum donde comenzó con el lenguaje BASIC (¿y quién no ha comenzado con ese lenguaje? ¡Ah, ahora los chavales estudian Python, menuda «paliza» para nosotros los vejetes!). Luego aprendió por su propia cuenta Pascal (¡ea, que yo tuve que pisar la universidad para poder aprender este lenguaje! ?) , C, Prolog, y ensamblador (eax, ebx, ebp y esp fueron sus grandes amigos). Luego al entrar en el mundo GNU/Linux reafirma C, y aprende C++ y Python.
Comenzó la universidad en 1991 y su primera obra fue el Sistema Tower Pro Tarjeta CT6811 para su sueño hecho realidad: el robot Tritt (que ya vendrá algún día el «Mazinger ?», porque ya el R2D2 lo tuvo… ¡como impresora 3D, con dinastía y todo!). De 1996 al 98 se dedica en cuerpo y alma -pesetas de por medio- al campo de los micro-robots y es cuando emprende su cruzada de hacer una España con un fuerte desarrollo endógeno para librarse de la dependencia tecnológica extranjera: producir y crear todo en su tierra natal (dichas batallas aún se libran fuertemente y se ganan poco a poco con muchísimo esfuerzo, solo que ahora no está solo, sus padawan‘s lo acompañan y apoyan).
En 2003 ya hablaba de los problemas del hardware libre mediante conferencia dictada en el VI Congreso de Hispalinux y llegó a la conclusión que son los planos de hardware son los que cumplen con las 4 premisas del software libre y por ende es así que debe ser considerado el hardware libre (ahora va de que preguntéis de dónde proviene el nombre GNU y obtendréis una respuesta enrevesada parecida).
En 2007-08 trabajó sobre un mando para wii y pudo lograr que controlara su robot Skybot, demostrando con ello que las empresas privativas tienen aún mucho más campo que cubrir si tan solo se dignaran a compartir el conocimiento.
Su «grito de guerra» es:
«Más vale proyecto publicado con licencia libre, que ciento en el cajón»
"Más vale proyecto publicado con licencia libre, que ciento en el cajón" #proverbioFriki
Patrimonio Tecnológico de la Humanidad: es que vamos a avanzar muchísimo más como Humanidad si compartimos el conocimiento! ¡Salimos ganando todos! La riqueza se va a distribuir muchísimo más… Esto se vio desde el principio en el mundo de la ciencia. Si tú no compartes lo que has descubierto, y te lo revisan otras personas, no avanzas, ya no es ciencia lo que haces.
Patrimonio Tecnológico de la Humanidad
Tuvo una fuerte influencia el trabajo del profesor Adrian Bowyer quien lanza al mundo la primera impresora para tercera dimensión «3D» a modo de hardware libre: fue desde entonces una revolución imparable en la cual ObiJuán se especializó y contribuyó -y seguirá aportando- en su conocimiento y masificación. Hasta ahora tiene construidas 270 impresoras 3D y podéis leer su trabajo enCloneWars en este enlace.
Así mismo lleva un canal en Youtube con multitud de tutoriales donde explica y comparte con suma paciencia su conocimiento y experiencia, añadiéndole como siempre su toque personal:
ObiJuán es apasionado de la tecnología y en 2016 comezó su proyecto épico: la reconstrucción del CPU del «Apolo 11», el proyecto espacial de la NASA que llevó a nuestra humanidad a la Luna; la «paleoarquitectura» de los ordenadores, sin duda una tarea ardua. Escuchemos en palabras del propio ObiJuán el proyecto de marras:
Para él fue una bendición la tecnología que aportó Arduino en los años 90, fue como la revista «Mecánica Popular» aplicado al mundo de la electrónica. Si Arduino abrió la posibilidad de combinar los componentes y ponerlos a funcionar con los FPGAs (Field Programmable Gate Array) tendremos la posibilidad de construir nuestros propios «chips» y eso ahora mismo es lo que mantiene más ocupado a ObiJuán. Esto es así porque a pesar de todos los títulos universitarios que ha logrado, lo que le apasiona es construir y verificar por sus propios medios (vamos que la ciencia se han de replicar los mismo resultados en las mismas condiciones): es de los que crea y observa, basado en la teoría, pero la destreza manual es bien sabido que abre nuestros cerebros a nuevas conexiones sinápticas y nuevas formas y maneras de ver las cosas, ¡es de los que dicen «no me fío de lo que me dices o alegas, dejadme probar y comprobar»!
A ObiJuán no le gustan los agradecimientos; nosotros por estos lares tampoco (de hecho, debido a la dura situación de nuestro país hasta ahora es que aceptamos donaciones) pero cuando la obra es grande ES IMPOSIBLE QUE PASE DESAPERCIBIDA. Desde 1989 que comenzamos a estudiar en la Facultad de Ingeniería de la Universidad de Carabobo nuestro punto de difusión de conocimiento era el boulevard al lado del cafetín principal, AHORA LO ES EL INTERNET POR EL MUNDO ENTEROy aunque en esa época ya sabíamos que difundir el conocimiento era la clave, no es sino hasta hace poco -en serio y en firme desde el año 2014- que entramos en el mundo del saber del software libre. Pero he aquí que ObiJuán no solo usa y difunde el software libre, ¡EL HARDWARE LIBRE TAMBIÉN! Nos aventaja por largo rato, y además se involucra en persona en causas sociales ¿Cómo no reconocer su labor? ¡Sería una injusticia!
Interesante es saber sobre cómo funciona el navegador web Mozilla Firefox (para nosotros, nuestro favorito) y vamos a diseccionar y explicar de manera sencilla, sin mayores pretensiones, sus diversos componentes. Para ello comenzaremos de atrás para adelante: el último Proyecto de Mozilla Firefox llamado «Quantum«, ¡Investiguemos juntos!
En el siglo IX los chinos inventaron la brújula (aguja imantada suspendida que siempre apunta al polo norte) y desde entonces le destinaron en cada barco un habitaculum (en latín, habitáculo en castellano) al cual los franceses le nombraron habitacle y que luego abreviaron como bitacle y que pasó a ser traducido al castellano como bitácora (a pesar de que ya teníamos la palabra traducida directamente del latín, habitáculo). Pues bien, se necesitaba llevar un registro de la posición del barco en los largos viajes por nuestro globo terráqueo (y junto al sextante para registrar los astros) todo se anotaba en un cuaderno de bitácora, o simplemente bitácora.
¿A donde nos lleva esta introducción que aparentemente no tiene nada que ver con computación? ¡Ya veremos!
Introducción.
Así como los gobiernos en tierra necesitaban conocer qué sucedió en un navío en altamar a su regreso, nosotros necesitamos saber qué sucedió en los programas que para bien desarrollemos para nuestros usuarios. Lo más básico es mostrar mensajes por pantalla a los usuarios y confiar en que ellos y ellas nos retribuyan debidamente la información… pero con muy contadas excepciones, podemos esperar sentados para no cansarnos porque eso será difícil que se haga realidad.
Es por ello que debemos guardar un registro metódico para que posteriormente podamos evaluar qué funcionó mal (por extraño que parezca, si funciona bien pues felices de la vida aunque no recibamos las felicitaciones de nuestros usuarios y usuarias de software). Otra razón de llevar un registro sería la de análisis de desempeño o incluso ejecutar un programa en modo de depuración.
La razón y la lógica indica que dichos registros que pensamos llevar deberían ser guardados en una base de datos pero en proyectos pequeños tal vez no necesitemos tal nivel de complejidad. Pongamos por caso el programa Filezilla que tiene ambas versiones tanto como servidor como cliente: por defecto no se registra mensaje alguno a menos que así lo deseemos y si decidimos guardarlo podemos especificar un archivo llevando la fecha de cada evento (opcional) e incluso podemos limitar a un tamaño específico tras lo cual al alcanzar dicho valor se procede a crear un archivo nuevo pero sin la extensión «.log» la cual es sustituida por una numeración consecutiva.
Por esta y muchas otras razones el lenguaje Python 3 tiene disponible una librería destinada para tal efecto, estudiemos pues.
Creando una aplicación modelo.
Antes de crear siquiera registro alguno debemos tener, claro está, un software al cual llevarle un registro. Para ello proponemos un programa que llamaremos calculadora1.py cuyo código es el siguiente (si queréis repasar vuestro conocimientos básicos sobre Python, revisad nuestro tutorial al respecto):
El código es bastante sencillo, solo las cuatro operaciones aritméticas básicas: suma, resta, multiplicación y división; reconocemos que el código es un tanto extraño pero recordad que tiene propósitos didácticos solamente. Creamos una clase con funciones que no emplean return sino que muestran por pantalla los resultados excepto en la inicialización que muestra un mensaje puramente informativo, emulando el «on» de una calculadora electrónica y anunciando el modelo virtual. Abstraigámonos entonces en el ejemplo para comenzar a modificarlo con el registro de eventos.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
La primera línea enlaza la librería y la segunda línea configuramos con una constante logging.DEBUG (que tiene un valor decimal de diez), osea, el nivel («level«) que vamos a usar: modo de depuración.
Notad todos y todas que en GNU/Linux son distintas las mayúsculas de las minúsculas, por lo tanto logging.DEBUG es una constante y logging.debug es un método, diferenciad bien esto en el siguiente código que modificamos a partir de la aplicación modelo.
Como vemos en la siguiente imagen la salida por pantalla ha sido modificada ya que le agrega «DEBUG:root» a todos los mensajes de resultado.
python3 calculadora2.py
La primera palabra indica que estamos en modo de registro a nivel de depuración «DEBUG» y la segunda palabra indica que estamos depurando el módulo principal aunque esto no es realmente cierto. Lo mejor sería indicar desde dónde estamos imprimiendo el mensaje de depuración, en nuestro caso cualquiera de las cuatro funciones. Para ello vamos a volver a modificar el programa -que ya hemos renombrado como calculadora2.py– especificando cada función por separado:
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Bien, pues ya estamos listos para comenzar a grabar en un archivo de texto plano nuestros eventos. Esto se logra configurando de nuevo el encabezado logging.basicConfig el cual ahora lo ocuparemos en varias líneas para buscar una mayor claridad para cada uno de sus parámetros:
Por supuesto el archivo será guardado en la misma carpeta donde se ejecuta la aplicación y para nuestra sorpresa al ejecutarla ya no muestra nada por pantalla… lo cual no es lo que realmente queremos hacer pero paciencia, primero analizemos el archivo resultante.
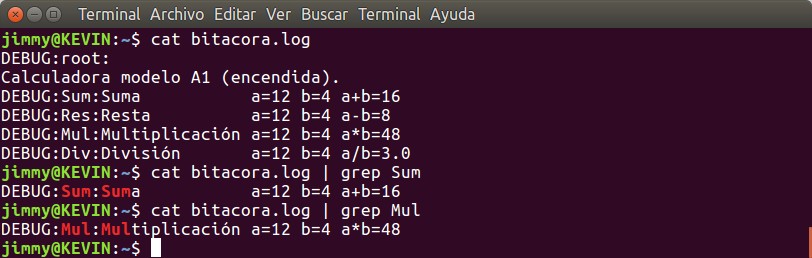
cat bitacora.log y combinado con el comando grep
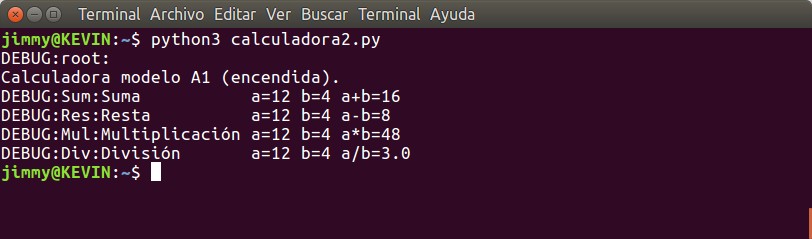
Al usar el comando cat podremos, entre otras cosas, listar el contenido de un archivo por pantalla y como probablemente la cantidad de mensajes generará gran cantidad de líneas podremos filtrar los resultados por palabra clave. ¿Recordáis que dimos nombres diferentes para la muestra de resultados a nivel de cada función? Pues con el comando grep que recibe el resultado del comando cat por medio del comando «tubería» «|» y la palabra clave «Sum» o «Mul» podremos ver lo que nos interese. Ya nuestra aplicación está entrando en modo pragmático, ¡lo realmente útil para nosotros!
Agregando más pragmatismo aún: claridad al registro.
Nosotros los seres humanos en nuestro cerebro siempre buscamos darle «orden» a nuestro mundo, así está torcido lo tratamos de ver derecho y esto en el registro de eventos no ha de ser la excepción. Ya le colocamos para saber cual función produce tal registro pero le agregaremos mayor claridad en el apartado de configuración al inicio de la aplicación:
Recordad siempre al final de cada línea colocar una coma para separar los parámetros, que como es multilínea tendemos a pensar que cada retorno de carro automáticamente separa cada parámeto pero no es así.En el tercer parámetro mandamos a separar con par de espacios y un guion las diferentes secciones de cada evento en cada línea:
Fecha y hora exacta hasta en milisegundos cuando ocurrió el evento.
Nombre del módulo donde se origina cada evento, en nuestro caso cada función.
Nivel del mensaje, clasificación (hasta ahora estamos en modo de depuración solamente DEBUG).
El mensaje en sí mismo.
cat bitacora.log
Formato de tiempo mejorado.
Al formato de estampado de fecha y hora lo podremos mejorar agregando otra línea más al encabezado de configuración con una máscara que también es utlizada por el comando time.strftime():
Dejamos para vosotros os ejercitéis y veáis cómo es distinto los nuevos registros que se siguen adicionando de manera automática al final de nuestro archivo destinado a tal efecto, bitacora.log
Nivel de registro de eventos.
Como hemos repetido varias veces, del modo de depuración DEBUG no nos hemos movido hasta ahora. Por ello debemos estudiar los diferentes niveles -y constantes- que utiliza la librería logging: ya sabemos que logging.DEBUG vale diez -y se van incrementando de diez en diez- pero he aquí la tabla completa de valores:
Nivel
Valor
numérico
Función
Uso
NOSET
0
no aplica
no aplica
DEBUG
10
logging.debug()
Diganóstico de problemas, muestra información bien detallada.
INFO
20
logging.info()
Confirma que todo está funcionando correctamente.
WARNING
30
logging.warning()
Indica que algo inesperado ha sucedido, o pudiera suceder.
ERROR
40
logging.error()
Indica un problema más serio.
CRITICAL
50
logging.critical()
Muestra un error muy serio, el programa tal vez no pueda continuar.
A nuestra aplicación vamos a agregarle un mensaje de error en la función de división, bien sabemos que cualquier número dividido entre cero tiende al infinito el cual es un concepto que entedemos los seres humanos pero los ordenadores no. La modificación es la siguiente (notad que b valdría uno si el valor no es pasado a la función para tratar de evitar este error):
def dividir(self, a=0, b=1):
if (b==0):
bita_div.error("Alerta: el divisor debe ser distinto a cero.")
else:
bita_div.debug("División a={} b={} a/b={}".format(a,b,a/b))
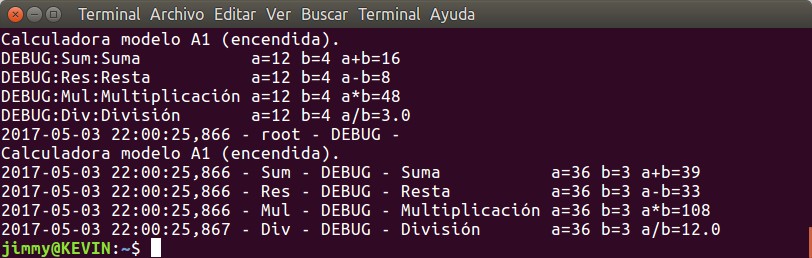
También modificamos el divisor en la función de división a calc.dividir(36,0) y el resultado en el registro de errores mostraría algo aprecido a esto:
Calculadora modelo A1 (encendida).
03/05/2017 11:03:07 PM - Sum - DEBUG - Suma a=36 b=3 a+b=39
03/05/2017 11:03:07 PM - Res - DEBUG - Resta a=36 b=3 a-b=33
03/05/2017 11:03:07 PM - Mul - DEBUG - Multiplicación a=36 b=3 a*b=108
03/05/2017 11:03:07 PM - Div - ERROR - Alerta: el divisor debe ser distinto a cero.
Lo próximo que haremos es modificar de manera completa nuestra aplicación con los diferentes «niveles» de mensajes.
Empleando diferentes niveles de registro.
Volvamos nuestros pasos sobre la sección logging.basicConfig donde contiene el nivel de registro de eventos para nuestra aplicación. Recordemos que la establecimos a nivel DEBUG y ahora la estableceremos a nivel INFO, guardaremos y ejecutaremos de nuevo la aplicación. Luego revisaremos el fichero bitacora.log y notaremos que no se registró el mensaje de inicialización pero si quedaron registrados los mensaje de información (y por supuesto el mensaje de error).
El siguiente paso es elevar al nivel de WARNING para obtener solamente el mensaje de error por la división entre cero y se repite el resultado si lo elevamos a nivel ERROR. No obtenderemos mensaje alguno si lo establecemos a nivel CRITICALya que la divisón entre cero no solamente ha sido debidamente advertida sino que también ha sido debidamente desviada.
Pro último, y más difícil de obtener (según la aplicación de modeo didáctico que de exprofeso escogimos) es el mensaje a nivel CRITICAL. Volvemos a repetir, este comportamiento es circunstrito estrictamente a nuestra aplicación modelo: la división está en el mensaje mismo a mostrar en bita_div.CRITICAL y nunca lograremos que se muestre ya que está debidamente desviado además, si no lo desviaramos al ejecutar el compilador Python3 inmediatamente nos mostraría el error si intentamos dividir entre cero y por ende no se ejecuta el programa.
Nosotros somos de experimentar al máximo, nos hacemos muchas, muchísimas preguntas: ¿Y si compilamos la aplicación, es decir la convertimos a lenguaje binario para ejecutar y lograr el mensaje a nivel CRITICAL?
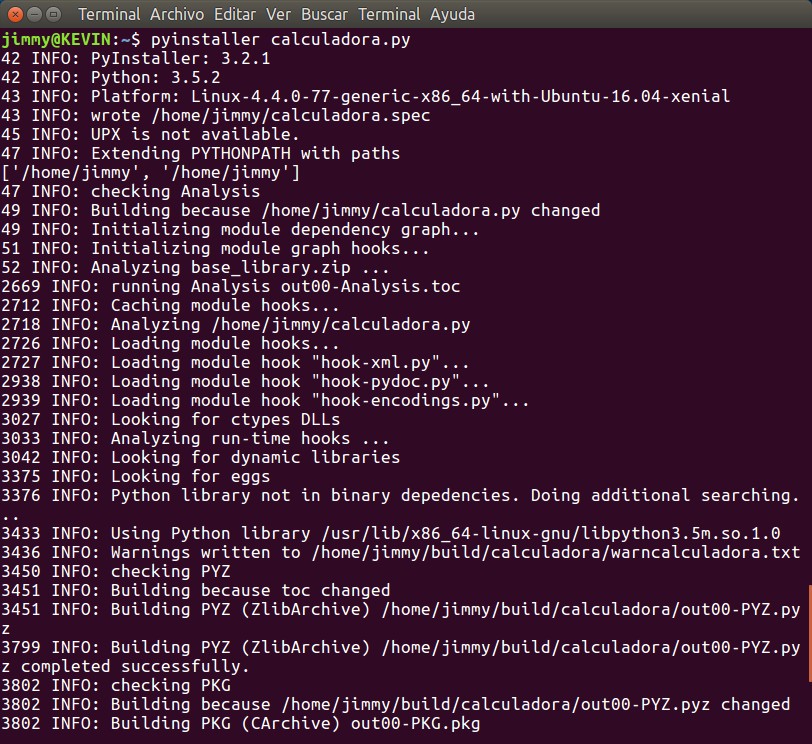
Para ello -brevemente- podemos instalar PyInstaller:
sudo pip3 pyinstaller
Luego simplemente vamos a la carpeta con nuestro fichero calculadora2.py (habiendo eliminado la desviación del error de división entre cero):
pyinstaller calculadora2.py
Y luego de cierto tiempo (¡oh, sorpresa, también utiliza logging para mostrar el progreso de la compilación pero con unos códigos no recomendables de niveles de registro -valores personalizados-) y en una carpeta dist encontraremos nuestro ejecutable listo para ser experimentado. Nosotros obtuvimos esto, si queréis practicad que algo parecido obtendréis:
pyinstaller calculadora.py
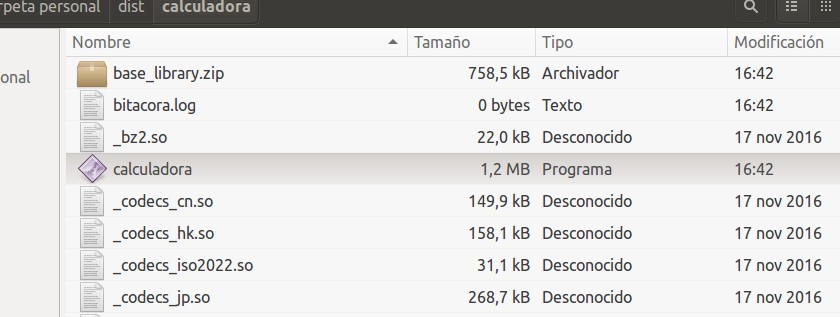
Entonces estaremos listo para ejecutar nuestro flamante binario, nos vamos con el explorador de ficheros Nautilus de Ubuntu a la carpeta dist le damos click derecho, ejecutar y ¡oh, sorpresa! el fichero bitacora.log se genera y aparece… pero con cero bytes, sin nada dentro, ¿qué ha sucedido aquí?
bitacora.log vacio cero bytes
Pues que simplemente la librería de registro abre el archivo bitacora.log (crea el archivo) pero la división entre cero no le permite llegar a ejecutar el grabado del mensaje, ya que las instrucciones son anidadas y primero trata de dividir y luego mostrar el mensaje, pero como se «cuelga» pues no registra nada de nada.
En este punto ya es bueno concluir algo muy cierto: el registro de errores incluso nos beneficiará al obligarnos a pensar dónde colocar los mensajes necesarios para futuras mejoras y en el caso del software libre donde TODOS podemos ser parte de un equipo de programadores esta ayuda es tremendamente bienvenida.
Otra pregunta que nos hacemos, ¿qué sucede si no establecemos un nivel de registro específico en logging.basicConfig? De manera predeterminada la utilería está en nivel WARNING y los mensajes que sean iguales o superiores a este nivel serán registrados (WARNING, ERROR y CRITICAL). No obstante vamos a dar un paso más allá en nuestros estudios y vamos a configurar para que sean nuestros propios usuarios quienes establezcan un nivel de registro lo cual consideramos útil para ellos que NO son programadores y que tal vez necesiten cierta orientación sin necesidad que ellos y/o ellas lleguen a tener que descargar el código fuente de la aplicación -que siempre estará al alcance por ser software libre-.
Que los usuarios y usuarias establezcan su nivel de registro.
Pasando parámetros a una aplicación desde la línea de comando.
En el mundo de Python hay varias librerías que nos permiten «pasar» parámetros hacia «lo interno» de nuestras aplicaciones, algunas de ellas son -pero no son todas-:
getoptes una librería la cual se deriva de una del lenguaje C llamada, claro, getopt().
optparseescrita para Python pero que actualemente está «descontinuada».
argparse la cual curiosamente deriva de optaprse pero ofrece total compatibilidad a la versión 3 -y a futuro-.
Por esa razón escogemos esta última para evitarnos dolores de cabeza a futuro.
argparse.
Introducción a argparse.
Debemos hacer una breve introducción al concepto de parámetros tanto opcionales como obligatorios. De manera general las aplicaciones corren sin ninguna isntrucción especial: escribimos el nombre del fichero, el sistema operativo revisa si es un ejecutable, o carga en memoria y ejecuta las instrucciones contenidas.
Un ejemplo sencillo es el comando para listar ficheros y directorios en una ventana terminal: ls. Sin más dicho comando nos muestra por pantalla los ficheros y directorios contenidos en la carpeta desde donde la ejecutamos. Si hubiera alguna carpeta y queremos saber su contenido debemos escribir ls nombre-de-la-carpeta y allí tenemos un parámetro opcional que le estamos pasando a la aplicación: le estamos ordenando listar el contenido de un directorio. Decimos que es opcional porque, como vimos, el comando no necesita nada para funcionar pero somos nosotros los que tenemos la necesidad de pedirle algo muy específico. Pero adicionalmente a la petición específica queremos que nos lo muestre de una manera específica y para poder diferenciar los nombres de las carpetas -o archivos- que pidamos de la forma como la va a presentar pues nació la idea de colocar palabras claves para diferenciar (recalcamos que estamos con el comando ls como ejemplo útil ya que es un comando extremadamente básico). Así podemos teclear ls nombre-de-carpeta -l para listar en modo columna o el también llmado modo largo (nombres de ficheros o directorios uno encima del otro con detalles de tamaños, fecha, atributos, etc.).
Es por esta razón que se estableció ciertas normas para pasar parámetros, en general podemos decir que:
Se utiliza un guion «-» como prefijo para indicar un parámetro y se acompaña generalmente con una sola letra que más que suficiente porque tenemos 54 opciones distintas (27 caracteres mayúsculas y minúsculas).
Como estrategia nemotécnica se utilizan dos guiones juntos «–» junto con palabras o incluso frases para que sea de manera explícita su recordación.
También se da el caso que a las dos opciones anteriores se le agregue sin dejar espacios un signo de igualdad y a continuación algún valor condicionante (que puede ser imprescindible o no).
Como para algunos el punto anterior no les parece elegante, también se estila colocar un espacio y a continuación algún valor condicionante.
Siguiendo con el ejemplo del comando ls:
Ejemplo del punto 1: comando «ls -r» (lista los archivos y carpetas en orden alfabético inverso, de la letra zeta hacia la letra a).
Ejemplo del punto 2: comando «ls –reverse» ídem al punto anterior pero más fácil de recordar y explícito para mostrar.
Ejemplo del punto 3: comando «ls –sort» ordena las lista de ficheros por orden de tamaño, del más grande hacia el más pequeño, pero sucede que hay muchas maneras de ordenar ese listado y si lo ejecutamos así sin más nos solicita un parámetro necesario. Podemos pedirlo por tamaño así que escribimos «ls –sort=size» y veremos el resultado con primero los más grandes yendo luego progresivamente hasta los más pequeños. Por cierto, este comando «largo» tiene un equivalente «corto»: ls -s.
Ejemplo del punto 4: comando «ls patron-a-buscar» como por ejemplo si queremos ver solamente los archivos que comienzen con la letra «a»: «ls a*«.
Primeros pasos con argparse.
Para comenzar a utilizar argparse en nuestro programa, simplemente hagamos un fichero nuevo y le colocamos los siguiente:
import argparse
analizador = argparse.ArgumentParser(description="Programa demostrativo de argparse")
analizador.parse_args()
Al salir lo nombramos como mi_programa.py y lo ejecutamos con python3 mi_programa.py y, por supuesto, no hace nada de nada ya que no le escribimos ningún código adicional. Pero ahora vamos a ejectuarlo acompañado de un parámetro como lo es el siguiente:python3 mi_programa.py -h y obtendremos la siguiente salida:
usage: mi_programa.py [-h]
Programa demostrativo de argparse.
optional arguments:
-h, --help show this help message and exit
Como vemos todo viene preconfigurado para utilizar el idioma inglés por defecto, pero pronto podremos darle un uso mejor para orientarlo hacia el idioma castellano en un tutorial dedicado al tema. Notad que especifica que el «parámetro largo» para ayuda es –help. Adicionalmente, cualquier otro parámetro que le pasemos manifestará desconocerlo -no hemos programado nada áun, por ahora-. Por lo pronto ya cumplimos con iniciar el uso práctico de argparser, continuemos aprendiendo.
Agregando otro argumento opcional.
Como vemos argparse tiene al menos un argumento establecido por defecto, el de ayuda [el cual es opcional, está mostrado entre corchetes], y ahora nosotros vamos a agregarle nuestro propio argumento para establecer el nivel de registro de eventos. Para ello especificaremos la palabra clave -log_lev acompañado del nivel que deseemos establecer, a continuación lo pasamos por una serie de tamices con la instrucción condicional if~elif~else y si coincide mostramos por pantalla la opción elegida:
import argparse
analizador = argparse.ArgumentParser("Programa demostrativo de argparse")
analizador.add_argument("-log_lev", help="Utilice DEBUG, INFO, WARNING, ERROR o$
analizador.parse_args()
argumentos = analizador.parse_args()
if argumentos.log_lev == 'DEBUG':
print("DEBUG")
elif argumentos.log_lev == 'INFO':
print("INFO")
elif argumentos.log_lev == 'WARNING':
print("WARNING")
elif argumentos.log_lev == 'ERROR':
print("ERROR")
elif argumentos.log_lev == 'CRITICAL':
print("CRITICAL")
else:
print("Opcion no válida de nivel de registro de eventos.")
Como vemos esto simplemente es el armazón para el manejo del pase de parámetros a nuestro programa didáctico para el registro de eventos con la utilería logging.
En este punto corred vuestro programa varias veces, experimentad con el pase de parámetros para que luego continuemos con el último paso de este tutorial: la fusión de logging con argparse.
Uniendo «logging» con «argparse».
Ya para finalizar unimos el código de ambos ejemplos y la idea es la siguiente: al utilizarse sin parámetros se establece el nivel de registro en WARNING que es el nivel predeterminado. Si se utiliza el parámetro -log_lev sin acompañarlo de valor alguno, la librería argparse se encargará debidamente de orientar al usuario sobre las opciones disponibles. Si el usuario usa alguna opción disponible válido pues se establece debidamente el nivel de registro correspondiente.
Queda para vuestra práctica el permitir que los usuarios especifiquen un nombre de archivo para el registro de eventos.
Acá tenemos el código final, espero os haya servido para aprender algo nuevo sobre el lenguaje Python.
Repetimos que esta página no va de ciencias sociales, sin embargo somos fanáticos de la ortografía y en esta oportunidad os presentamos una herramienta para corregir nuestros escritos, que ya son bastantes, por demás. Ahora es el punto donde nos diréis «ea, tío, ¿de qué vais si eso está integrado en ‘todos’ los programas?» Pues bueno preparaos a sorprenderos con los que os vamos a contar, ¡vamos a aprender a programar para corregir nuestra ortografía!













 (@ks7000)
(@ks7000) 

 by
by 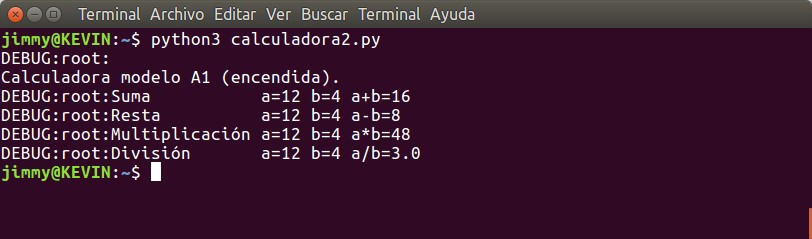

{kind=link}