En nuestra entrega anterior -y con la ayuda del Doctor Jason Brownlee- instalamos Fedora 25 como máquina virtual para tener un entorno de desarrollo específico para Python3: pues bien, el fin último es tener una base para poder desarrollar el «machine learning» a un nivel intermedio, veamos.
¿Qué es el «machine learning»?
Es una ciencia aplicada con ayuda de los ordenadores: de una serie gigantesca de datos obtenidos de nuestro mundo analógico regido por la mecánica cuántica podemos obtener patrones, precisamente lo que hacemos nosotros los seres humanos, como por ejemplo cuando miramos una noche estrellada y percibimos constelaciones que solo están en nuestro cerebro. Muchas universidades en el mundo están abocadas a este estudio y promete ser el futuro en el cual debemos estar preparados para cuando lleguen los ordenadores cuánticos.
Un dato que nos llama la atención es que ya hoy en día tiene una aplicación práctica, para mal, denunciada por Edward Snowden en su cuenta en Twitter:
¿Qué tiene que ver esto con el «machine learning»? Pues que el dispositivo que es utilizado para detectar los patrones de atención de los televidentes durante los comerciales es grabado con un dispositivo originalmente diseñado para juegos denominado Kinetic. En realidad es un dispositivo biométrico que en el año 2011 incluso ganó un premio de 50 mil libras esterlinas por desarrollo innovador al reconocer los movimientos de nuestro cuerpo, interpretarlos y trasladarlo como acciones en los juegos de vídeo. Es así que en solo seis años se le ha conseguido un uso importante en la vida real, acercándonos cada vez más a las historias contadas en las saga de películas «Terminator».
Instalando un entorno basado en Python para el aprendizaje de las máquinas.
Instalando el entorno Python.
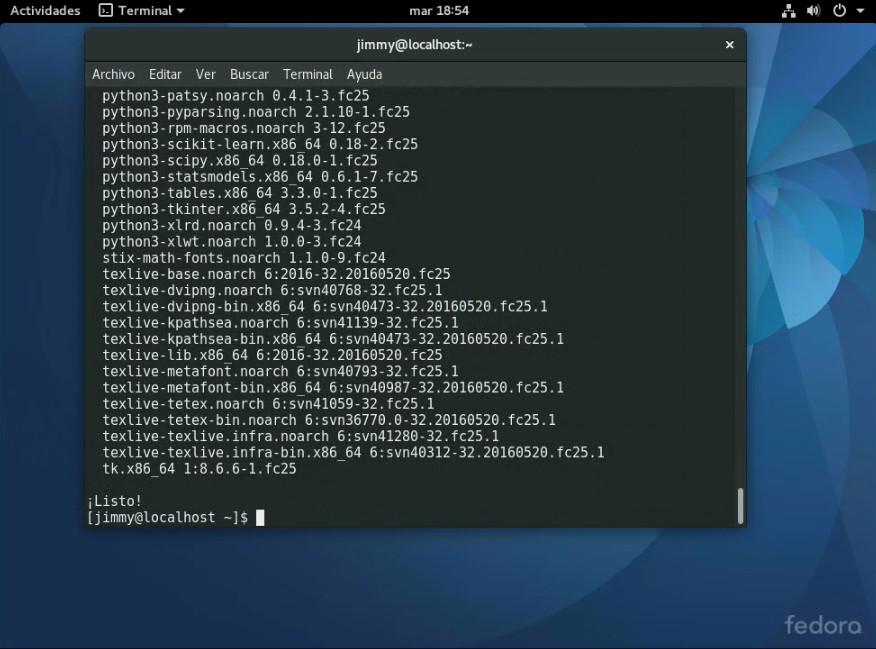
Como ya bien sabéis, ya sea por este vuestro humilde portal o por internet -que abunda información- el lenguaje de programación Python viene instalado por defecto en la mayoría de las distribuciones GNU/Linux y Fedora no es la excepción. Para saber cual versión tenemos instalada, ejecutamos nuestra máquina virtual e introducimos nuestras credenciales de usuario. Acto seguido pulsamos ALT+F2 e introducimos la orden «gnome-terminal» para ejecutar una ventana de comandos para lanzar la siguiente línea:
python3 --version
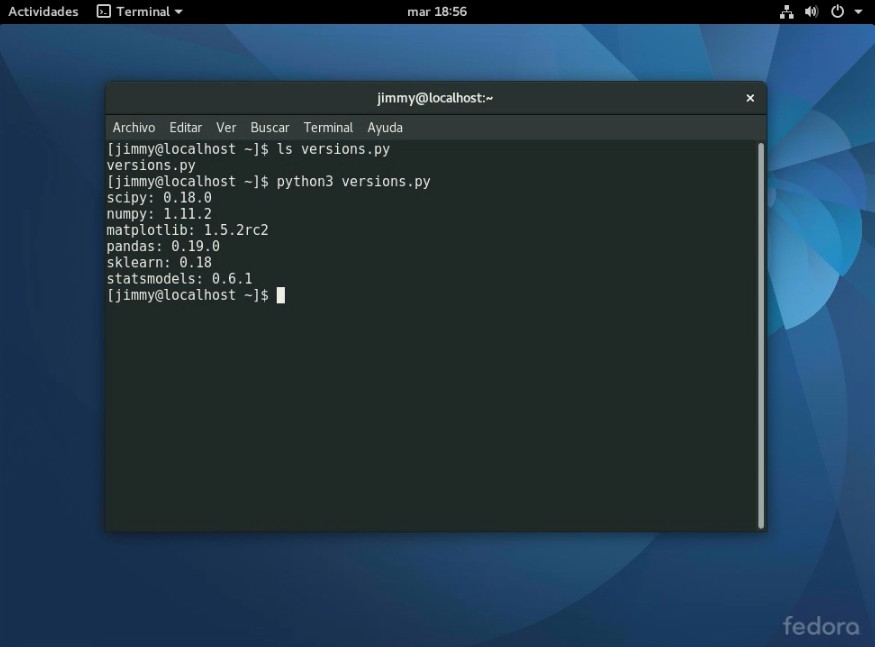
En la figura podemos observar que ya tenemos instalada la versión 3.5.2:
python3 –version
Instalando el conjunto de utilidades para Python3.
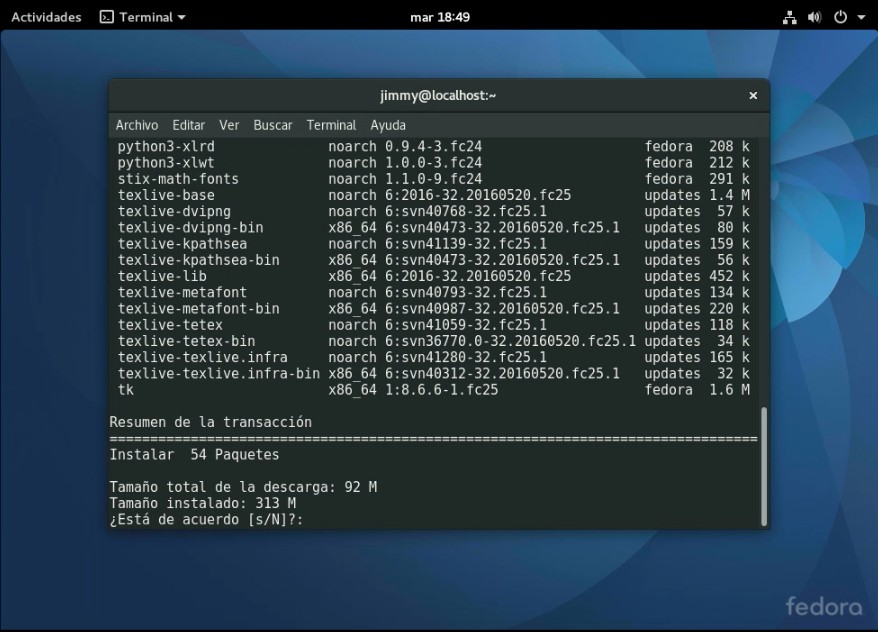
Los paquetes que necesitaremos son seis en total:
SciPy, conjunto de herramientas que integra los siguientes paquetes:
NumPy: herramienta para álgebra lineal, transformadas de Fourier y generación de números aleatorios.
Todas ellas las podemos bien instalar en una sola línea, bien una por una, depende de nuestra paciencia. Por rapidez escogeremos la primera y en la misma ventana terminal que tenemos abierta colocamos:
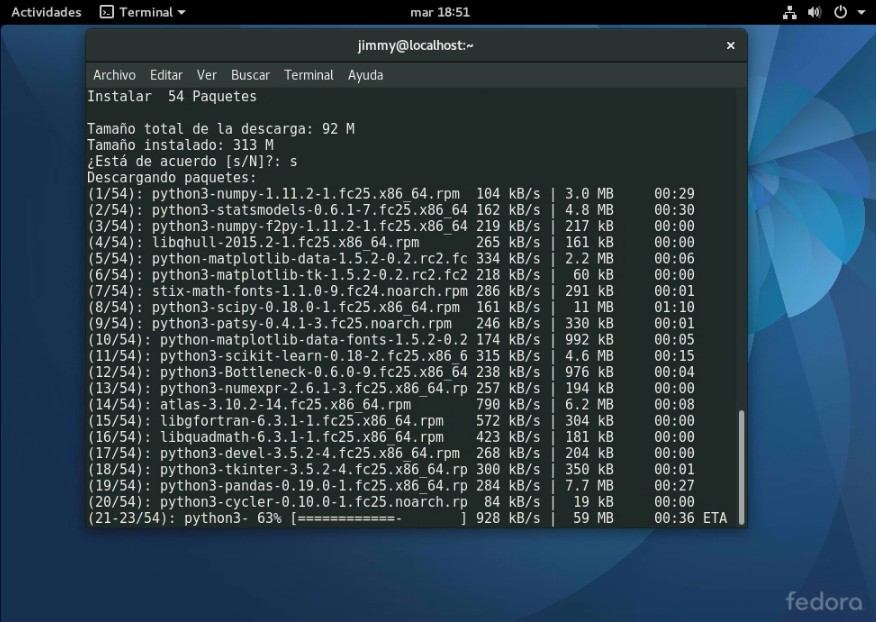
El comando DNF es la abreviatura para Dandified Yum, que tal como explicamos, es el equivalente al comando apt-get utilizado en las distribuciones GNU/Linux basadas en Debian. Así que autorizamos la descarga, que son más o menos 92 megabytes:
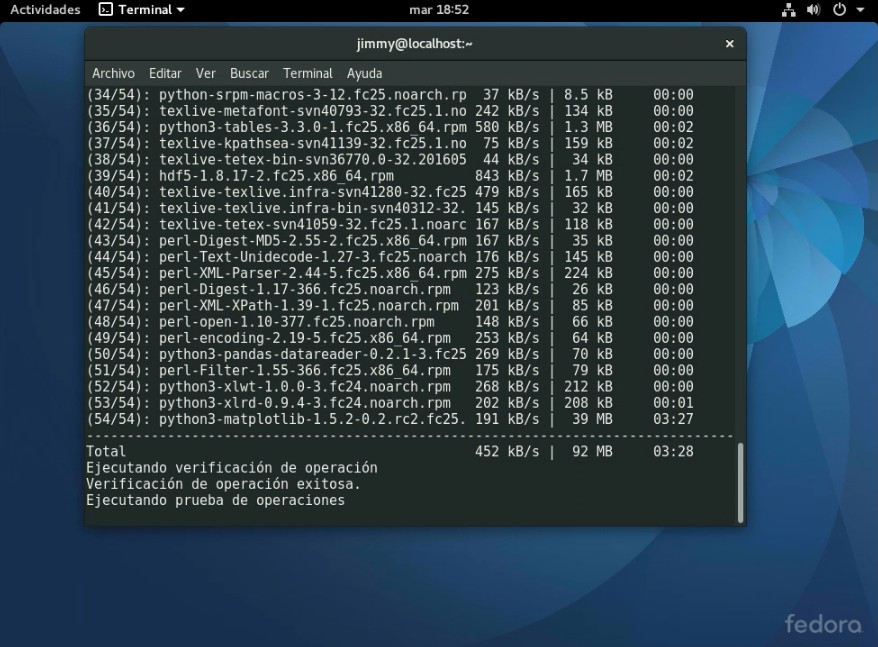
Una vez se han descargado a nuestro ordenador virtual, se hace la verificación de contenido y se procede a descomprimir e instalar; allí van 200 megabytes adicionales:
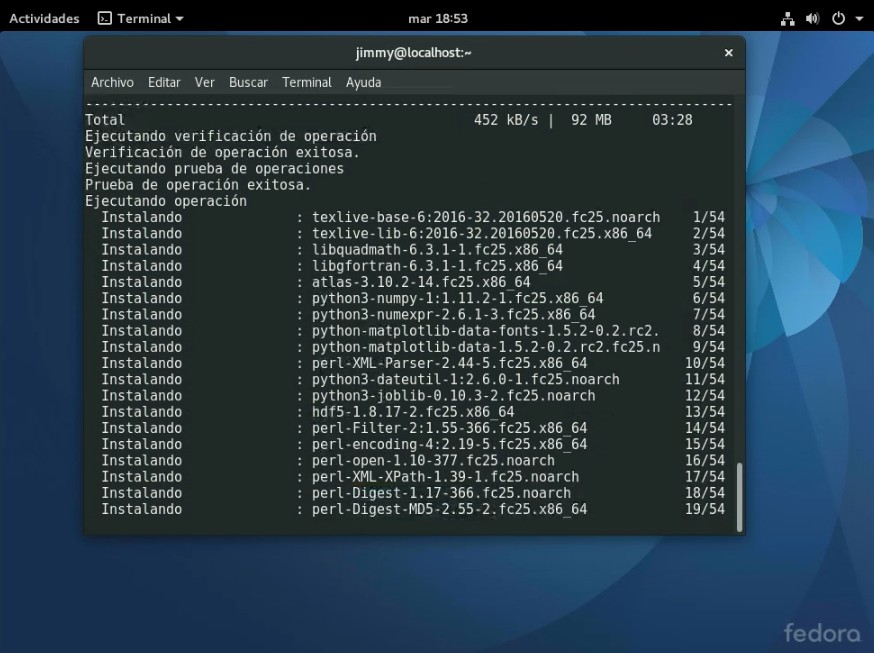
Instalando entorno Python3 para «machine learning» 3Instalando entorno Python3 para «machine learning» 4
Confirmación del entorno instalado.
Una vez finalizado procedemos a «crear» un guión en bash para averiguar rápidamente las versiones instaladas. Aquí viene la utilidad de haber instalado las utilerías de «VirtualBox Guest Additions» en nuestra entrada anterior: podremos «copiar y pegar» texto entre nuestro ordenador anfitrión y el ordenador virtual.
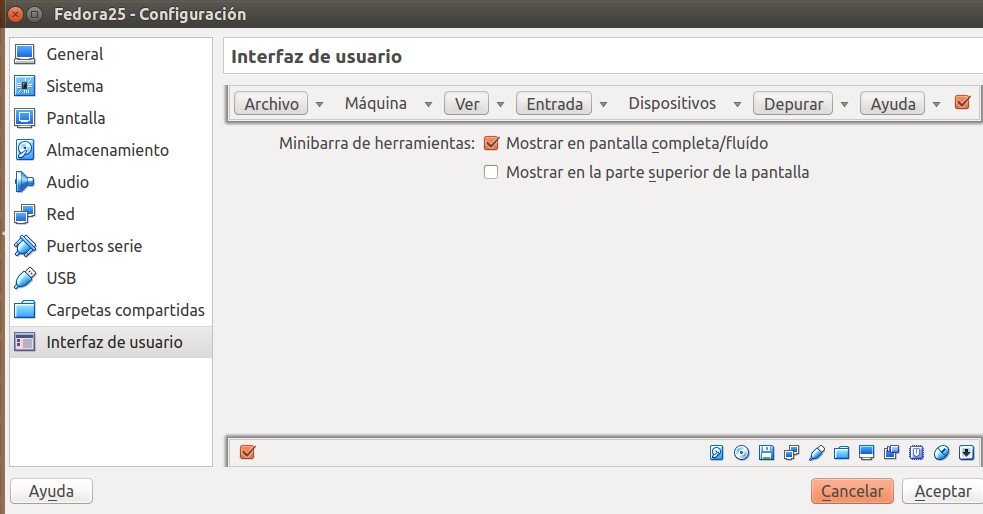
Habilitar el portapapeles entre VirtualBox y las máquinas virtuales.
Antes de poder «copia y pegar» texto debemos primero habilitar su paso por medio de VirtualBox: seleccionamos la máquina virtual Fedora y presionamos CONTROL+S para entrar a la configuración y vamos a la sección «Interfaz de usuario» -> «Dispositivos»:
VirtualBox portapapeles entre ordenador anfitrión y ordenador virtual
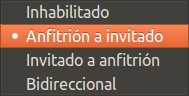
Descolgamos la lista y seleccionamos «Anfitrión a invitado» y damos «Aceptar».
VirtualBox portapapeles ordenador anfitrión a invitado
Archivo de comando «versions.py».
Ahora que podemos pasar el portapapeles a la máquina virtual (tedioso procedimiento para poder habilitarlo), seleccionamos, copiamos y pegamos lo siguiente:
En las siguientes imágenes utilizamos el editor de textos gedit, pero sentiros libres de utilizar vuestro preferido (de hecho nosotros más adelante instalamos nano):
Guión para detectar los componentes instalados de Python3 unoGuión para detectar los componentes instalados de Python3 dosGuión para detectar los componentes instalados de Python3 tresGuión para detectar los componentes instalados de Python3 cuatroGuión para detectar los componentes instalados de Python3 cinco
Hemos escrito y referenciado -bastante- sobre cómo trabajar bajo la linea de comandos en GNU/Linux y para trabajar con Python de esta manera muchas veces debemos presentar los datos y resultados de una manera agradable a la vista. Para ello echaremos mano de unos comando que vienen por defecto en Python 3.5.2 , la versión que usamos a la fecha. Hagamos pues, ¡manos a la obra!
Introducción.
En el lenguaje de programación Python (y esto es un brevísimo repaso) las cadenas de texto deben ser contenidas o encerradas entre comillas simples o comillas dobles, con apertura y cierre correspondiente y por pares, y dichas comillas no serán mostradas por pantalla al ordenar imprimirlas, veamos el ejemplo:
Hasta aquí no necesita mayor explicación, ustedes decidirán cuáles pares de comillas utilizar, a su gusto y elección pero eso sí, tratemos de ser constantes en su uso, si son simples o dobles. Para este tutorial utilizaremos comillas simples y nuestra balanza se inclina hacia allá porque al uno introducir una cadena de texto entrecomillada doble y presionar intro en el shell de Python por pantalla nos mostrará la misma cadena pero con comilla simples, un detalle a observar. Pero para poder mostrar estas cadenas de caracteres en un guión o script debemos utilizar el comando print() y dentro del par de paréntesis introduciremos dichas cadenas de texto:
Y el resultado por pantalla será la cadena de texto sin comilla alguna.
Concatenado de cadenas de texto.
Si queremos imprimir en una sola línea de texto dos cadenas, debemos usar el símbolo de suma «+» pero en este caso simplemente nos muestra la primera cadena y luego la segunda (podemos incluir en las mismas espacios para separar las palabras):
print('Simón ' + 'José ' + 'Antonio ' + 'de la Santísima Trinidad ' + 'Bolívar y Palacios')
Ahora analizamos que aunque usemos el símbolo de la suma no quiere decir que podemos pasar cualquier número para que sea interpretado como texto, el siguiente comando producirá un error y el segundo es el que debemos utilizar:
print('Simón Bolívar nació en el año ' + 1783)
print('Simón Bolívar nació en el año ' + '1783')
Nótese que hemos encerrado el número entre comillas para que sea considerado una cadena de texto, en el lenguaje Python nos atreveríamos a decir que los datos deber ser explícitos, el lenguaje es estricto en su manipulación (si son caracteres, caracteres serán siempre, si son números igualmente, más adelante profundizaremos en esto).
Repetición de cadenas de texto.
Muchas veces necesitamos repetir uno o más caracteres varias veces, especialmente con propósitos decorativos. Esto es importante en el caso de las licencias de software donde se muchas veces se utiliza el signo de igualdad ‘=’ para encerrar los títulos de la misma. Así como usamos el símbolo de suma ahora utilizaremos el signo de multiplición en programación que es el asteristo ‘*’ (la equis la utilizamos para los humanos, como por ejemplo para representar las tablas de multiplicación). Para ello encerramos entre comillas el texto deseado y seguido de un asterisco y luego un número que representa las veces que repetiremos el caracter o caracteres:
print('='*40)
print('+-'*40)
Almacenando cadenas de texto en variables.
Pues bien, si en nuestro programa vamos a repetir muchas veces una frase pues lo mejor es almacenarla en una variable para mostrarla donde la necesitemos y escribirla una sola vez al principio del software que desarrollemos:
gracias = '¡Muchas gracias por su colaboración!'
Y una vez la tengamos declarada podemos imprimirla con el famoso comando print() -en Python 3 los paréntesis son obligatorios-:
print(gracias)
Reutilizando el último resultado.
Gracias al sr. Juan J. Merelo Guervós quien amablemente publica por Twitter una presentación sobre Python, nos enteramos del uso de el guion bajo «_» para utilizar el último valor que hayamos presentado por la consola interactiva de Python teneindo cuidado de darle el tratamiento adecuado al valor: si es texto, número, etcétera y valga para que aplique a las combinaciones posibles, echad un ojo al siguiente ejemplo:
Uso del guion bajo como almacen del último resultado en consola Python
Comillas y apóstrofos.
Sí, así como lo leen APÓSTROFOS y no , es común caer en este error, pero ese es el nombre correcto: apóstrofos (tal vez influye en errar el como se escribe en inglés: «apostrophes»). Lo cierto del caso es que en castellano no tenemos mayor problema en la escritura, más en el habla coloquial vaya sí que usamos la «contractura» de la palabra (elisión le dice la Real Academia Española), un caso muy común: «para allá» lo pronunciamos «pa’llá». Como véis igual hacemos en Python, solo que esta vez rompemos la regla de utilizar comillas simples porque de lo contrario se produce un error si escribimos ‘pa’llá’ pues la comilla simple en el medio de la frase indica que allí termina la cadena de texto (si queréis ver algo más avanzado, por favor leed nuestro otro tutorial sobre el tema). Algunos nombres que vienen del idioma portugués también utilizan el apóstrofo, como por ejemplo el apellido «D’acosta», y si lidiamos con eso debemos usar distintos tipos de comillas, tengamos precaución con esto al momento de programar.
Si necesitamos mostrar las comillas en sí mismas pues las encerramos debidamente de forma anidada, ejemplo:
print('Sí, eso fue lo que ella dijo:"Hacia el sur"')
Líneas múltiples.
Si pretendemos mostrar varias líneas podemos almacenar dichas líneas encerrandolas entre comillas triples (sencillas o dobles, según necesitemos o queramos):
agua = '''El agua está compuesta de:
-Oxígeno
-Hidrógeno'''
print(agua)
Caracteres de escape.
Con el caracter de escape barra invertida «\» podemos escribir nuestro apóstrofo encerrado entre comillas simples de la siguiente manera:
print('El ciudadano Pedro D\'acosta.')
Como pueden observar le indicamos a Python que tome el caracter que está a la derecha de la barra invertida como caracter en sí mismo y que no lo tome como un caracter especial para el lenguaje (en este caso como delimitador de cadena de texto).
También podemos usar dicho caracter de escape con la comilla doble:
print("Vendedme un tubo de 2\" de diámetro.")
# El siguiente comando también hará el mismo trabajo:
print('Vendedme un tubo de 2" de diámetro.')
En Python si una línea comienza con el símbolo numeral «#», todo lo que esté hacia la derecha hasta el retorno de carro será considerado comentario -sirve para documentar nuestro código para futuras generaciones-.
Además, si el caracter que le agregamos a la derecha NO es un caracter especial (por ejemplo, la letra «n») nos permitirá «quebrar» o insertar un retorno de carro en una sola línea:
print('Línea 1\nLínea 2')
Y con la barra invertida y la letra «t» podremos presentar por pantalla la composición química del agua del ejemplo anterior pero numerada y tabulada:
agua = 'El agua está compuesta de:\n1\tátomo de Oxígeno\n2\tátomos de Hidrógeno'
print(agua)
Y para imprimir la barra invertida…
Y si necesitamos imprimir la barra invertida por pantalla con el comando print() debemos anteceder la letra «r» justo antes de la cadena de texto:
print(r'El agua está compuesta de:\n1\tátomo de Oxígeno\n2\tátomos de Hidrógeno')
Formateando cadenas de texto con marcadores de posición.
Así como utilizamos el comando print() en este caso utilizaremos otro comando intrínseco en Python: format(). En lenguaje Python podemos «heredar» o «unir» a una variable una función -es por ello que dicen y comentan que es un lenguaje de programación avanzado-: por medio del punto «.» unimos primero la variable y luego la función format() auxilíandonos con un par de corchetes «{}» -marcador de posición- que le indicará a dicha función dónde colocar el valor que necesitemos. Vayamos de la teoría a la práctica:
print('Venezuela tiene {} estados.'.format(24))
Y veremos por pantalla lo siguiente:
Venezuela tiene 24 estados.
Tal como lo presentamos es poco útil en verdad, pero vayamos un poco más allá: en Venezuela el ahora estado Amazonas antes era un territorio federal, así que el número de estados a lo largo del tiempo será algo que puede variar. Asimismo muchos países están divididos por estados (otros por comunas como Chile, otros por cantones como Suiza, etcétera). Veamos el siguiente código:
pais = "Venezuela"
estados = 24
print(pais + ' tiene {} estados.'.format(estados))
Ahora tiene más sentido ya que dichas variables ‘pais’ -sin acento, así se acostumbra escribir los nombres de variables- y ‘estados’ podrían ser llenados, por ejemplo, desde los valores almacenados en una base de datos con varios países y sus respectivas cantidades de estados y podremos hacer un ciclo para mostrarlos a todos. Lo que incluiremos entre corchetes no necesariamente debe ser un número, también puede ser otra cadena de texto como veremos a continuación.
Formateando cadenas de texto con varios marcadores de posición.
Continuando con el ejemplo anterior, es posible reescribirlo de la siguiente manera:
pais = "Venezuela"
estados = 24
print('{} tiene {} estados.'.format(pais, estados))
Siempre hay que tener en cuenta el colocar las variables a insertar en el mismo orden que van de izquierda a derecha según los marcadores de posición, esto es así porque dentro de los corchetes no hemos insertado aún órdenes especiales; por lo tanto lo siguiente NO mostrará correctamente la información:
pais = ''Venezuela'
estados = 24
print('{} tiene {} estados.'.format(estados, pais))
Para corregir lo anterior debemos colocar el número correspondiente (comenzando desde cero) a la enumeración de elementos -valga la redundancia-. Es decir que lo que insertemos dentro de los paréntesis del comando format -separados por comas- automáticamente tomará el primer elemento el índice cero, el segundo, uno y así sucesivamente:
pais = "Venezuela"
estados = 24
print('{1} tiene {0} estados.'.format(estados, pais))
Podremos escribir muchos más elementos que la cantidad de marcadores de posición -corchetes {}- pero no menos, porque produce un error; veamos el próximo modelo:
pais = "Venezuela"
print('{} tiene {} estados.'.format(pais))
Allí tenemos dos marcadores de posición pero una sola variable (podemos complicar el ejercicio con muchos más elementos, pero trabajar con 2 ó 3 elementos ilustra bien lo que queremos enseñar). Igualmente, si a los marcadores de posición le insertamos índices que no existen, pues también nos arroja error:
pais = "Venezuela"
estados = 24
print('{1} tiene {2} estados.'.format(estados, pais))
Tal como les indicamos, se debe enumerar desde cero, es así que el elemento 2 no existe ni está declarada dicha variable (está fuera de rango, produce error).
Si se nos hace difícil el trabajar con base cero, también Python nos permite colocarles nombres clave a las variables abramos nuestra mente a los llamados alias:
pais = "Venezuela"
estados = 24
print('{uno} tiene {dos} estados.'.format(uno = estados, dos = pais))
Si analizamos bien, en realidad estamos llamando a la variable «pais» con el alias «uno» y «estados» con el alias «dos», lo cual nos muestra lo poderoso que es el lenguaje Python.
Pasando los formatos específicos.
Hasta ahora hemos utilizado los marcadores de posición vacios o con un índice o alias pero podemos ir más allá. Por medio de los dos puntos «:» nos permite separar el índice o alias del formato con que queramos presentar las variables. Para ilustrar imaginemos que tenemos una lista de países pero sus nombres, desde luego, no tienen el mismo número de caracteres. Si queremos mostrarlos de una manera muy ordenada nos fijaremos cual tiene la cifra más larga y asi dejaremos sufiente espacio para los otros más cortos. Hagamos un sencillo listado de 3 países hartos conocidos por nosotros los venezolanos:
pais = ("Colombia", "Chile", "Venezuela")
division = ("departamentos", "comunas", "estados")
Con estas declaraciones le estamos indicando a Python que nos haga una matriz (ellos lo llaman «tupla», una palabra no reconocida por la RAE) de 1 fila y 3 columnas para la variable «pais» e igualmente para la variable «division». Fijaos que el más largo es Venezuela con 9 letras y le sumaremos uno más para separar del resto de la oración con un espacio; haremos uso de un ciclo for:
for k in range(0,3):
print("{0:10} está dividido políticamente en {1}.".format(pais[k], division[k]))
Ya os dijimos que las numeraciones arrancan desde cero, pero es conveniente aclarar que la variable «k» es evaluada por Python al inicio del ciclo, por eso debemos agregarle uno más a nuestros índices de matriz. Veremos la siguiente salida por pantalla:
Colombia está dividido políticamente en departamentos.
Chile está dividido políticamente en comunas.
Venezuela está dividido políticamente en estados.
¡Qué práctico! Lo más interesante es que podemos alinear las variables al centro o a la derecha (por defecto alinea a la izquierda) si le colocamos el signo «^» o «<» para la alineación a la izquierda o «>» para alinear a la derecha:
for k in range(0,3):
print("{0:10} está dividido políticamente en {1}.".format(pais[k], division[k]))
Colombia está dividido políticamente en departamentos.
Chile está dividido políticamente en comunas.
Venezuela está dividido políticamente en estados.
Incluso podemos presentar los nombres de los países de la misma manera que uno hace al escribir los nombres de los beneficiarios en un cheque bancario: agregando asteriscos (o cualquier otro caracter) a la izquierda y derecha y centrando el nombre y agregaremos 12 «espacios» en vez de 10, probad en vuestra terminal lo siguiente (no publicamos imágenes del resultado para «forzaros» a practicar en vuestro ordenador):
for k in range(0,3):
print("{0:*^12} está dividido políticamente en {1}.".format(pais[k], division[k]))
Tal vez con los números hallaremos la máxima utilidad al formateo de cadenas con marcadores de posición, veamos algunos de ellos.
Pasando los formatos numéricos específicos.
Muchas veces necesitamos en nuestros programas las tasas de los impuestos que recauda el Estado para el buen funcionamiento de la República. En Venezuela el ente encargado es el Servicio Nacional Integrado de Administración Tributaria y Aduanera (SENIAT por sus siglas) quien legalmente está facultado a publicar y hacer cumplir las variaciones en los porcentajes. El Impuesto al Valor Agregado (IVA por sus siglas) recordamos que comenzó con un 10% en 1994 (año en que fue creado el SENIAT de la mano de la Guardia Nacional quienes nos visitaron para cumplir y hacer cumplir el impuesto) y ha sufrido subidas y bajadas estando hoy en 12% -en España tenemos entendido que está en 25% al momento de escribir estas líneas-. Imaginemos que queremos informar esto a nuestros usuarios:
iva1994 = 10
iva2016 = 12
print('La tasa de impuesto del IVA en 1994 era de {:f}%'.format(iva1994))
print('Hoy en día, año 2016:{:f}%'.format(iva2016))
Como recordaremos, en el marcador de posición debemos colocar los dos puntos para separar el índice (por defecto cero porque es un solo elemento y se puede omitir) del formato numérico que deseamos presentar. En nuestra vida común los números del 0 al 100 toman especial importancia y tanto nuestra moneda y tasas se representa hasta con dos decimales a la derecha de la coma -mejor dicho, empleamos hasta la centésima parte de la unidad-. Es por esto que, si habéis practicado los comandos de arriba, notaréis que se «imprime» con seis decimales porque utilizamos el parámetro «f» -número con separador decimal flotante- y para limitar la salida a dos decimales debemos agregar «.2» al formato:
print('La tasa de impuesto del IVA en 1994 era de {:.2f}%'.format(iva1994))
print('Hoy en día, año 2016:{:.2f}%'.format(iva2016))
Ahora se ve un poco mejor, pero con el inconveniente de que nuestro separador decimal es la coma y para el mundo anglosajón es el punto (los sistemas operativos modernos lidian con esto muy bien todo el tiempo simplemente asignandole un identificador especial que tal vez sea el Unicode 2396 «⎖» y mostrando al usuario de cada región su símbolo particular en cada salida por pantalla y/o impresora). Nota: los parámetros en la función format() deben ser en estricto orden: «{0:.2f}» es lo correcto -índice, separador, número de decimales y tipo de número, «f» para flotante-; mientras que «{0:f.2}» no funcionará.
Usando formatos de texto para presentar datos.
Una aplicación práctica de la vida real es mostrar a nuestros párvulos las tablas de multiplicar, escojamos -¡ejem!- el número 7, nuestro número de la suerte, y hagamos un programita:
for k in range(1,10):
print('{} x {} = {}'.format(7, k, 7*k))
Como véis no representa mayor problema la salida pues el único elemento díscolo es el resultado de «7 x 1», vamos a ampliar la tabla hasta 30 (recordad sumar uno más) y mostramos su respuesta a continuación:
for k in range(1,31):
print('{} x {} = {}'.format(7, k, 7*k))
7 x 1 = 7
7 x 2 = 14
7 x 3 = 21
7 x 4 = 28
7 x 5 = 35
7 x 6 = 42
7 x 7 = 49
7 x 8 = 56
7 x 9 = 63
7 x 10 = 70
7 x 11 = 77
7 x 12 = 84
7 x 13 = 91
7 x 14 = 98
7 x 15 = 105
7 x 16 = 112
7 x 17 = 119
7 x 18 = 126
7 x 19 = 133
7 x 20 = 140
7 x 21 = 147
7 x 22 = 154
7 x 23 = 161
7 x 24 = 168
7 x 25 = 175
7 x 26 = 182
7 x 27 = 189
7 x 28 = 196
7 x 29 = 203
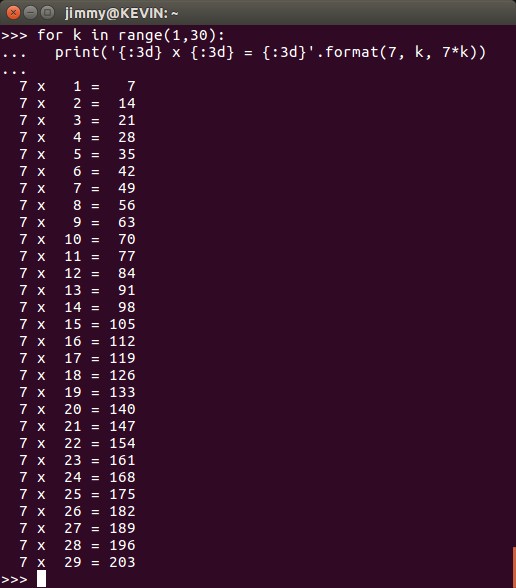
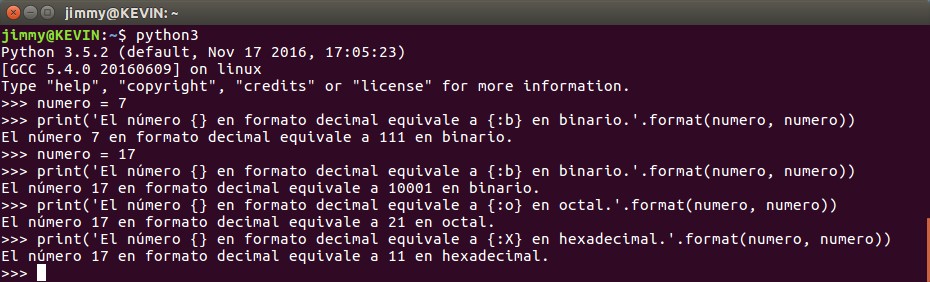
Aquí está el meollo del asunto, a medida que los números «engordan» nuestras columnas no se presentan de manera tabulada. Para observarlo más a nuestro gusto, el de los seres humanos (imagino que las computadoras cuando gobiernen al mundo obviarán el arte por completo, privando la funcionalidad por encima de todo, pero hasta que esos días lleguen no nos preocuparemos por #Skynet) necesitamos que cada número, sin importar su valor, ocupe máximo 3 espacios o casillas, si lo queremos ver de esa manera. Para ello agregamos «{:3d]» en cada marcador de posición y listamos el resultado (en este ejemplo colocamos lo que se ve en la línea de comandos de Phyton):
Python ciclo for con marcadores de posicion para una tabla de multiplicar.
¡Mucho mejor para nosotros los obsesivos por el orden!
Formatos soportados por Python.
Como era de esperarse, hay una gran cantidad de parámetros en el comando format() y acá explicamos los hasta ahora conocidos teniendo en cuenta que hay que respetar el orden en que pasamos los parámetros, a saber son los siguientes:
El índice o alias de la variable que queremos formatear, generalmente se omite ya que acostumbramos a colocarlas en el orden correspondiente, cosas de nosotros los seres humanos.
Caracter separador, los dos puntos «:».
Caracter de relleno, cualquiera que se necesite (hicimos un ejemplo con un asterisco, el ejemplo de los cheques bancarios ¿lo recordáis?).
Alineación (recordad el ejemplo de los países), abajo especificamos más.
Signo positivo, negativo o cero (abajo aclaramos).
En el caso de números en otros sistemas de numeración podemos usar «#» o «0», de nuevo abajo explicamos mejor el asunto.
Opción de agrupamiento: aquí si que hay mucha tela que cortar, mirad el punto 8 que lo hacemos muy detalladamente.
Precisión: en el caso de las tasas de impuesto usamos 2 decimales, pero podemos usar los que necesitemos, lo único que no explicamos es que esta función redondea hacia arriba (si es mayor o igual a 5) o hacia abajo según el primer decimal fuera del alcance de precisión.
Tipo de dato: lo más importante queda de último, ya que podemos indicarle explícitamente qué tipo de datos pasamos e incluso que conversión hacemos, leed el punto 10 en detalle.
Los puntos 1 y 2 ya los hemos explicado muy bien, veamos los siguientes.
3.-Caracter de relleno.
Cualquier caracter INCLUSO los caracteres especiales no presentan ningún problema, recordad que lo TODO lo que está en el marcador de posición «{}» Python los considera parámetros, no comandos especiales; haced la prueba colocando comillas simples, dobles, barra y barra invertida y os lo mostrará sin problema alguno.
4.-Alineación de caracteres.
«<«: alinea a la izquierda, generalmente se omite ya que es la opción por defecto en la mayoría de los objetos.
«^»: alinea al centro del espacio disponible.
«>»: alinea a la derecha.
«=»: solamente para formatos numéricos que presentan signo, por ejemplo «+000000120», rara vez se utiliza.
5.-Signo numérico.
«+», «-» y » «: si necesitamos colocarle signo a nuestro resultado usamos el signo de suma o de resta, o simplemente dejamos un solo espacio en blanco reservado para el signo, si es negativo se muestra sino coloca un espacio en blanco.
6.-Forma alterna para la conversión.
El utilizar «#» o «0» nos hes tremendamente útil si hacemos conversiones a otros sistemas de numeración (binarios, por ejemplo), mirad el punto 10.
7.-Anchura del campo.
Ya dijimos que está limitado por nuestra noció de estética pero en realidad si le pasamos un valor muy alto pues simplemente Python lo mostrará en tantas líneas como necesite, una abajo de la otra, dando al traste cualquier tipo de formato que deseemos, cuidadito con esta cifra.
8.-Opción de agrupamiento.
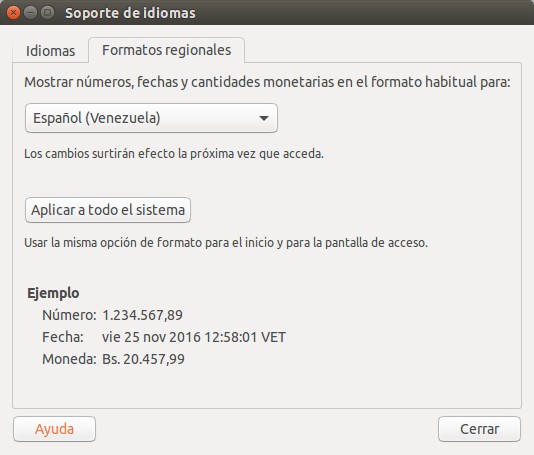
¿Recuerdan que hablamos del separador decimal y que en nuestro país es la coma? De hecho nosotros usamos el punto como separador de miles y esto trae muchas veces un dolor de cabeza para el mundo de la banca y negocios. Acá os mostramos cómo lo maneja Ubuntu 16.04:
Formato regional en Ubuntu 16.04
Pues acá va que Python se empeña en utilizar el punto como separador decimal y la coma como separador de miles a pesar de nosotros tener nuestra configuración regional como corresponde. Es por ello que en la PEP378 le buscan una solución al asunto haciendo uso de un comando y un artilugio: cambiamos las comas «,» que separan los miles en formato anglosajón por guiones bajos «_», luego cambiamos el punto «.» que es separador decimal en formato anglosajón por una coma «,» y finalmente cambiamos los guiones bajos «_» por puntos «.» ¿complicado en idioma castellano? Veamos como se escribe en lenguaje Python:
monto = 1234567.89
print('Su saldo bancario es Bs.' + '{:,}'.format(monto).replace(",","_").replace(".", ",").replace("_","."))
El comando clave es replace(,) y nótese que hemos dejado el símbolo de «Bs.» fuera del valor numérico para que ese punto no sea sustituido por una coma y nuestro trabajo se ve plasmado así:
Representación correcta de Python de los formatos numéricos para Venezuela.
¿Complicado? Pues aún no hemos comenzado a programar de verdad, ja ja ja 😉
En realidad nuestros amigos que desarrollan Python de manera desinteresada (monetariamente hablando) se han compadecido de nuestro predicamento porque, al menos nos han permitido el parámetro de la coma «,» como separador de miles, de parte de nosotros está comenzar a programar nuestras propias utilerías y «subirlas» a GitHub para que estén disponibles de manera pública por medio del Software Libre. Como ustedes ya imaginarán ya otros colegas habrán pasado por esto y en la internet habrá una solución ya realizada, lo que hay es que buscarla o sino hacerla nosotros mismos.
10.-Tipos de datos (y conversiones).
Pues ya va finalizando nuestra clase del día, lo último y tal vez más importante es que le podemos decir a Python el tipo de dato que le vamos a pasar para que nos lo represente adecuadamente e incluso podemos hacer conversiones a otros sistemas de numeración, miremos:
«s»: formato de cadena de texto, es el valor por omisión, eso quiere decir que es tácito y sobre entendido que lo que le pasamos al comando format() es una cadena de texto sin más; se puede omitir.
«b»: nos representará un número en de numeración formato binario, si le pasamos la coma como separador de agrupamiento lo hará de 4 en 4 caracteres.
«c»: un número entero que corresponde a un caracter ASCII, así la letra «A» es el número 34, le pasamos ese número y nos dibujará una letra «A».
«d»: sistema de base decimal, si se lo pasamos en binario hace la conversión correspondiente.
«o»: sistema de numeración de base 8.
«x» y «X»: sistema de numeración de base 16 con los caracteres en mayúsculas o minúsculas para los valores por encima de nueve.
«n»: supuestamente para indicar que se utilize los separadores decimales y sepradores de miles segúna la configuración regional del sistema operativo del usuario (lo probamos y no funciona para nada bajo Python 3.5.2, no señor, la teoría es hermosa pero la práctica que hace nuestra experiencia ES MARAVILLOSA).
Esta es la segunda parte de nuestro tutorial sobre Python, específicamente la versión 3.5.2, para ser exactos. Para mayores detalles de compatibilidad, historia y, en fin, lo básico sobre este lenguaje, debéis leer primero nuestra entrega anterior. Pero si ya tenéis alguna experiencia, podéis comenzar aquí con funciones. Y si soís un profesional en esto, gracias por vuestra visita, vuestras correcciones las podéis hacer llegar vía Twitter a @ks7000 o realizar un comentario acá abajo al finalizar esta entrada. Pues bien, ¡manos a la obra!
Funciones en Python.
Clasificación de las funciones.
En la primera parte de nuestro tutorial hicimos una sencilla función, demasiado simple, para nuestro programa que_hubo_mundo.py, y ahora es bueno que veaíś el panorama completo de las funciones desde nuestro punto de vista.
Advertencia.
Lo aquí expresado por nosotros es nuestra opinión, la forma y manera en que enfocamos el aprendizaje del lenguaje Pyhton. En la página web oficial podréis ver el tutorial completo -en inglés- y con todo detalle. Nuestra idea es que aprendáis lo básico y una vez estéis diestro o diestra en la materia, repaséis en Python.org y contrásteis la información. ¿Queréis continuar? ¡Vamos!
Las funciones en Python las consideramos en el siguiente orden:
Funciones nativas o integradas: no se necesita acción alguna fuera de llamarlas y pasarles los argumentos, si es que exige alguno. Ejemplo fácil: la función print() la cual podemos llamarla y simplemente nos «devuelve» un retorno de carro por cónsola en pantalla. Y decimos que nos «devuelve» porque eso es lo que vemos que hace la función, porque en realidad no nos devuelve valor alguno, ni numérico ni de texto. ¿Recordáis la palabra clave «end» para print()? Ingresad en vuestra cónsola lo siguiente (le «pasamos» un argumento a print() especificamente un argumento con palabra clave): print(end=»») ¿Qué os parece?
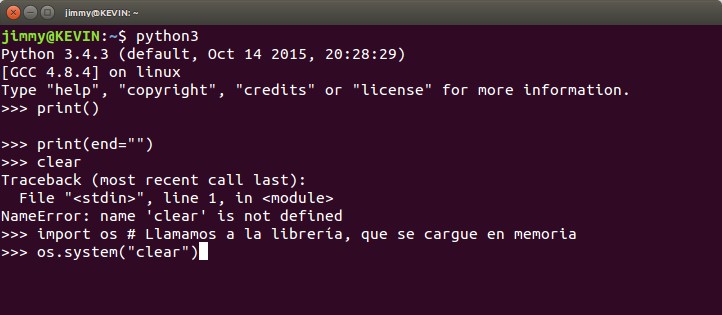
Funciones que vienen con Python pero hay que declararlas primero para luego llamarlas: pues eso, vamos a traer un ejemplo práctico, cuando vosotros estáis trabajando en modo interactivo tal vez os gustaría poder «limpiar» la cónsola de todo lo que hayáis practicado. Pues bien, esta tarea descansa con el sistema operativo de vuestro ordenador, y en el caso de GNU/Linux se hace con el comando «clear» pero antes que intentéis probarla revisad primero el siguiente código, observad la palabra clave o comando import:
>>> import os
>>> os.system(«clear»)
0
>>>
Eso es lo que veréis, más o menos. La pantalla se «limpiará» pero obervareís que aparece un cero y luego el prompt de Python interactivo. Por eso es que es una función, devuelve un valor, que en este caso es cero. Si queremos que ese cero no aparezca y veamos una prístina cónsola (solo el prompt, por su puesto) deberemos teclear algo como esto: k = os.system(«clear»). Al finalizar estos párrafos os colocamos una captura de pantalla para que veaís más detalles.
Funciones para Python que hay que descargarlas e importarlas: nosotros podemos publicar (como de hecho lo hicimos) nuestro archivo que_hubo_mundo.py el cual contiene la función hola() la cual solamente imprime el mensaje «¡Qué hubo mundo!». Abrid una ventana terminal, listad los ficheros con el comando ls y si tenéis el archivo en cuestión en esa carpeta entonces abrid la terminal interactiva e ingresad lo siguiente: from que_hubo_mundo import hola y observad lo que pasa. ¡Genial! ¿o no? Pues bueno así podéis crear tus «librerías» e incluir el trabajo de otros, así, sin mayor parsimonia ni protocolo (punto 3 PEP20). El problema de esto es que si traemos el trabajo de otras personas hasta nuestro disco duro y dichos programadores publican una nueva versión (para mejor, se supone) deberemos descargar manualmente y verificar si funciona con nuestro programa -dos trabajos en uno-. Para evitar esto pasemos al siguiente punto.
Funciones para Python que hay que instalarlos por un procedimiento especial: Python.org mantiene siempre sus puertas abiertas a contribuciones, tanto monetarias como de programas y para ello mantiene en línea «the Python Package Index» (El Índice de Paquetes de Python) con el cual podemos instalar el trabajo de los demás y mantenernos actualizados si surgen nuevas versiones. El «procedimiento especial» consiste en instalar el programa pip el cual será el que haga el trabajo por nosotros (aunque probablemente ya lo tenéis instalado). A su vez, para instalar pip debemos descargar un archivo llamado get-pip.pydesde un servidor seguro (HTTPS, «candado verde») y ejecutarlo. Luego podremos usar directamente desde Python.org cualquier trabajo publicado. Aquí es importante acotar que se deben seguir normas y reglas para publicar y son de obligatorio cumplimiento si queremos llegar lejos en esto. Sabemos que si seguimos estudiando y trabajando duro algún día publicaremos algo allí pero si queréis probar cómo funciona (declarar, subir y luego bajar nuestra programación) Python ofrece un ambiente de prueba (le dicen «sandbox» en inglés ya que allá se acostumbra poner en los parques cajones de madera llenos de arena para que los niños y niñas desarrollen sus habilidades motoras sin dañar nada ni herirse): he aquí el enlace y «happy hacking!» como dicen allá 😉 .
os.system(«clear»)
Creación de una función con el comando pass.
La manera intencional de declarar una función que no haga nada pues tiene que darse con un comando que tampoco haga nada. Os presentamos el comando pass. Y eso es lo que hace, nada de nada. Mirad este código:
Como veís, al invocar la función no realiza «nada». Aquí vamos a explicar línea por línea:
Línea 1: definimos la función con la palabra reservada def seguido de un espacio y el nombre que hayamos escogido para la función. Luego colocamos par de paréntesis, uno que abre y otro que cierra, allí luego colocaremos los argumentos o datos que le queremos pasar a la función. Los dos puntos «:» indican que la línea no acaba allí, que hay más en líneas siguientes y al presionar intro observaréis que el prompt pasa a ser «…» y nos invita a escribir la segunda línea.
Línea 2: en la primera parte de este tutorial hablamos de configurar nuestro editor de textos para que al presionar la tecla TAB nos inserte espacios en vez del caracter tabulador. Ahora os rogamos, para cumplir con las normas de Python.org que lo configuréis exactamente a 4 espacios o que pulséis 4 espacios la primera vez y luego vuestro procesador indentará automáticamente cada vez que presionéis intro. Así que colocamos el comando pass (que no hace nada sino gastar 4 bytes en nuestro disco duro al estar guardado en un archivo). Luego colocamos un comentario sobre lo que pensamos hacer a futuro con dicha función.
Línea 3: una línea en blanco para poder presionar intro y volver al prompt interactivo. También debemos dejar una línea en blanco si estuvieramos escribiendo en un archivo, por razones de legibilidad y claridad en nuestro código.
Creación de una función útil en la vida real.
Muy bonito estudiar la teoría pero debemos de ser pragmáticos y ponerla a trabajar en nuestras vidas. Para ello vamos a realizar una función que dado un monto nos calcule el impuesto a las ventas que debemos pagar (Impuesto al Valor Agregado, I.V.A. o IVA). En nuestro país, Venezuela, todo eso está normado por la ley y si queréis revisarlo nosotros hemos publicado una entrada al respecto.
El cálculo es el siguiente: al monto (que llamaremos base gravada o base) le multiplicamos por la tasa de impuesto y la dividimos entre cien. A la fecha la tasa es de un 12% pero puede aumentar o disminuir con el paso del tiempo, pero en general dura meses y hasta años en un mismo valor. Asumiremos entonces que es 12% y pasamos a escribir la función:
>>> def impuesto(base):
... print('Impuesto a pagar:', round(base*12/100,2))
...
>>> impuesto(100)
Impuesto a pagar: 12
>>>
Rápidamente observamos, en la única linea de la función, como hemos utilizado la función print() , hemos separados con comas los argumentos para nos imprima un espacio en blanco entre ellos, y uno de los argumentos le hemos pasado una funcion round() a su vez con dos argumentos: el cálculo del impuesto en sí y el número 2 para indicarle que redondee el impuesto a dos decimales ya que así lo exige la ley (hay ciertos casos como el manejo de moneda extranjera o divisa -por ej.: €- y venta de hidrocarburos que, debidos a los altos montos, al multiplicar con solo 2 decimales trae mucha diferencia: solo en esos casos se exigen 4 decimales ¿por qué demonios explicamos esto? Más adelante veréis ).
Por supuesto, el comando pass lo eliminamos y el comentario también, pero no debemos dejarlo así, siempre debemos agregarle un texto explicativo, no solo para nosotros a futuro, que se nos pueden olvidar las cosas (¡vamos , a menos que seas Rainman!) sino para enriquecer a la comunidad de software libre, debemos compartir nuestras creaciones (y cobrar por el servicio, claro está, el que trabaja se gana su pan diario). Si con esos argumentos no os hemos convencido aquí va un tercero que es necesario: Python.org tiene algo llamado docustring que fue diseñado para que se puedan construir manuales a partir de un formato especial que nosotros agreguemos a nuestras funciones. ¿Cómo funciona esto? Solamente os decimos que debemos seguir estudiando cómo escribir funciones y en su oportunidad volveremos a tocar el tema.
Baste entonces con escribir nuestro comentario encerrado en un entrecomillado triple para cumplir con Python.org y sus normas, veamos
>>> def impuesto(base):
... ''' Cálculo del IVA a un monto dado '''
... print('Impuesto a pagar:',round(base*12/100,2))
...
>>>
¿A que es más lúcida nuestra función? Pero ojo, ahora vamos a llamar la función impuesto() tal cual, sin ningún monto y veremos un hermoso error, al traste con nuestra emoción, pero la computadora está en lo correcto, y si nosotros hemos fallado ¿qué esperamos entonces de nuestros futuros usuarios de nuestros programas?
Pues he aquí que vamos a mejorar nuestra función, la versión 0.1, de esta manera:
>>> def impuesto(base=0):
... ''' Cálculo del IVA a un monto dado V. 0.1 '''
... if base==0:
... print('Introduzca un monto mayor que cero.')
... else:
... print('Impuesto a pagar:', round(base*12/100,2))
>>>
Agregamos un valor por defecto así que si al llamar a la función no le pasamos argumento entonces toma un valor de cero y si el valor es cero imprime un mensaje invitando a hacerlo. Hemos convertido una función con argumento obligatorio en una que no lo es. Esto tiene ventajas y desventajas: si no le ponemos valor por defecto nos obligamos nosotros mismos a ser mejores programadores. Pero como le pusimos valor por defecto es recomendable que el programa avise que se le está pasando, así sea verdad o no, un valor cero, por lo tanto el impuesto sería cero y la función no tendría razón de ser. Si nos equivocaramos programando y en algún punto llamamos a la función sin argumento con el tiempo recibiremos una hermosa llamada telefónica de nuestros clientes diciendo algo como «metemos el monto de la base y el programa dice que introduzcamos un valor mayor que cero«.
Así nuestra función sigue evolucionando: volvemos a colocarla para que sea obligatoria la base como argumento PERO dejamos el mensaje y lo mejoramos para manejar valores negativos, la versión 0.2 quedaría así:
>>> def impuesto(base):
... ''' Cálculo del IVA a un monto dado Ver. 0.2 '''
... if base<=0:
... print('Introduzca un monto mayor que cero.')
... else:
... print('Impuesto a pagar:', round(base*12/100,2))
>>>
Funciones con argumentos con palabras clave.
Os dijimos que el monto de la tasa de impuesto dura meses y hasta años con el mismo valor, pero eventualmente cambia. Por ello vamos a pensar en el futuro y modifiquemos otra vez, sería la versión 0.3:
>>> def impuesto(base, tasa=12):
... ''' Cálculo del IVA a un monto dado Ver. 0.3 '''
... if base<=0:
... print('Introduzca un monto mayor que cero.')
... else:
... n_tasa = input('Introduzca tasa (12%)')
... if len(n_tasa) > 0:
... tasa=float(n_tasa)
... print('Impuesto a pagar: Bs.', round(base*tasa/100,2))
...
>>>
Aquí le damos la oportunidad al usuario de modificar la tasa si ha cambiado, de lo contrario pulsa intro y la tasa seguirá con su valor por defecto de un 12% que le colocamos al declarar la función. La función input() devuelve una cadena de texto: si el usuario escribió algo la longitud de la cadena es mayor a cero y la función len() nos lo dirá así, por otra parte la función float() convertirá la cadena de texto a un número de doble precisión, capaz de manejar decimales.
Pasaremos por alto que el usuario introduzca un valor no numérico, ya llegará el momento de mejorar nuestro código. Por ahora nos interesa seguir aprendiendo. Así como modificamos nuestra función nos permite para la tasa desde la llamada a la función, por ello es lo correcto mostrar dicho monto para que la función input() enseñe la tasa que va a aplicar, podemos modificar la línea de la siguiente manera:
Para llamar a la función escribiremos impuesto(100 , 15) para indicarle a la función, por lógica, que a un monto de Bs. 100 le calcule el 15% de impuesto. Pero con Python tenemos varias maneras de llamar a la función y todas producirán el mismo resultado: Bs. 15 -si simplemente presionamos intro cuando verifica la tasa-, probadlo en vuestras cónsolas por favor:
>>> impuesto(100 , 15 )
Impuesto a pagar: Bs. 15.0
>>> impuesto(base=100 , tasa=15)
Impuesto a pagar: Bs. 15.0
>>> impuesto(tasa=15, base=100)
Impuesto a pagar: Bs. 15.0
>>> impuesto(tasa=15, 100)
impuesto(tasa=15 , 100)
^
SyntaxError: non-keyword arg after keyword arg
En la última entrada nos arroja error porque no estamos pasando el valor con su palabra clave, Python espera que el primer argumento sea obligatorio y no importa si solo tiene 2 argumentos (con una palabra clave pues por descarte el otro argumento es el «restante»), es decir, si vamos a cambiar el orden de los argumentos siempre debemos pasarle la palabra clave para indicarle a donde va cada valor. De otra manera, pues nos aprendemos de memoria el orden exacto de los argumentos de cada función. Si tenemos un editor que nos ayude a escribir las funciones, bien, por medio de tooltips nos dirán el nombre y tipo de variable que espera cada función mientras estamos escribiendo un comando al programar. Pero en GNU/Linux se necesitan programas pequeños que hagan cosas pequeñas y las hagan bien. Previendo la programación a futuro, rumbo a la inteligencia artificial, Python nos ofrece algo muy interesante. Empecemos por docustring ¿lo recordáis?
Anotaciones en funciones.
Podemos ‘preguntarle’ a la función para qué sirve por medio de su docustring simplemente ingresando lo siguiente:
>>> print(impuesto.__doc__)
Cálculo del IVA a un monto dado V. 0.3
Ya vamos viendo la utilidad de documentar a medida que programamos; también tenemos la posibilidad de «saber» cuántos argumentos recibe la función sin haberle pasado un solo dato, lo que nos prepara para el poder usarla (si es que otra persona la escribió o es lo que nosotros escribimos para otras personas). Para ello debemos agregar a nuestra función la siguiente notación « -> float: » ya que así definimos qué tipo de dato espera entregar y recibir la función (eso disciplina nuestras tácticas de programación, pasandole a la función el tipo correcto de dato):
>>> def impuesto(base: float, tasa: float =12) -> float:
... ''' Cálculo del IVA a un monto dado Ver. 0.3 '''
... if base<=0:
... print('Introduzca un monto mayor que cero.')
... else:
... n_tasa = input('Introduzca tasa (12%)')
... if len(n_tasa) > 0:
... tasa=float(n_tasa)
... print('Impuesto a pagar: Bs.', round(base*tasa/100,2))
...
>>>print(impuesto.__annotations__)
{'base': <class 'float'>, 'return': <class 'float'>, 'tasa': <class 'float'>}
¿Observáis el formato como devuelve las definiciones de los argumentos? Vamos a analizarlos y para ello lo colocaremos en varias líneas de manera indentada:
La primera y última línea encierra la definición por medio de corchetes de apertura y cierra. La segunda línea indica que un argumento tiene como nombre clave la palabra ‘base’ y debe ser un número flotante. La tercera línea «return’ indica lo que devuelve la función, una variable numérica flotante (la cual habremos redondeado a dos decimales, como explicamos). No especifica nombre pues ya sabemos cómo se llama la función. La cuarta línea también indica que debe recibir un argumento llamado ‘tasa’ y debe ser númerica de tipo flotante. Notarán que las nombran entre corchetes angulares como «class» o clase en castellano: si nosotros hiciéramos nuestras propias clases podremos referirnos a ellas en cualquier momento. Hay clases definidas de antamano en Python: ‘float’ es una variables numérica que admite hasta 16 decimales (en su momento veremos los tipos de datos disponibles en Python).
Las anotaciones de funciones son totalmente opcionales y están definidas en PEP 484 y son de reciente adaptación, año 2015, aunque tienen su base en otras PEP, aparte de ser compatibles, en cierta forma.
Palabra clave «return«.
Lo próximo que vamos a realizar es transformar completamente nuestro código a una verdadera función con el comando return, veamos:
>>> def impuesto(base: float, tasa: float =12, decimales: int =2) -> float:
... ''' Cálculo del IVA a un monto dado Ver. 0.4'''
... monto=round(base*tasa/100, decimales)
... return monto
...
>>> valor_impuesto=impuesto(100)
>>> print(valor_impuesto)
12.0
Lo que hicimos fue agregarle un argumento adicional, opcional, con la palabra clave «decimales» y que por defecto es 2 (por ley de nuestra República) y la «tasa» de impuesto que por ahora es 12 pero que le podemos pasar a la función un valor diferente sea el caso. También utilizamos una variable llamada «valor_impuesto» donde guardamos el valor devuetlo para la función y a continuación lo imprimimos por pantalla; pero esta variable la podemos usar donde y como la necesitemos. Así podemos practicar de varias maneras el por palabras claves, veamos, que la práctica hace al maestro (recordemos que estamos en modo interactivo y simplemente al llamar la función se imprime automáticamente por pantalla, pero si la guardamos en un archivo .py debemos guardar en una variable para luego imprimirla, tal como codificamos, de lo contrario no tendremos salida por pantalla):
Lo que siempre debemos hacer es «pasarle» la base, y luego por medio de palabras claves, sin importar el orden, los otros dos argumentos, de lo contrario arroja error (o excepción que es el nombre correcto). Si queremos pasarle argumentos, sin importar el orden, debemos colocarle palabras claves a todos los argumentos, de la siguiente manera:
>>> impuesto(decimales=2, tasa=10, base = 1500)
150.0
>>> impuesto(decimales=2, tasa=10)
Traceback (most recent call last):
File "/usr/lib/x86_64-linux-gnu/gedit/plugins/pythonconsole/console.py", line 378, in __run
r = eval(command, self.namespace, self.namespace)
File "<string>", line 1, in <module>
TypeError: impuesto() missing 1 required positional argument: 'base'
Sin embargo, si le pasamos solamente los decimales y la tasa y no le pasamos la base, arroja error, porque ese debe ser un argumento obligatorio , ya que tasa y decimales le colocamos valores por defecto y así los convertimos en argumentos opcionales.
Uso de variables para pasarlas a las funciones.
Veremos algo que es facilmente deducible, pero lo complicaremos un poco con los valores por defecto en los argumentos opcionales de una función. Nos explicamos: podemos guardar en variables los valores y luego pasarlos a la función:
Esto no necesita mayor explicación: es simplemente pasarle los valores por medio de variables. Lo que es más avanzado es pasarle los valores por defecto a la función por medio de variables declaradas antes de definir la función y dichas variables luego pueden cambiar su valor pero la función quedará definida con los valores dados exactamente antes de haber definido la función. Podemos así redefenir la función y luego explicaremos su utilidad:
valor_tasa=15
def impuesto(base: float, tasa: float =valor_tasa, decimales: int =2) -> float:
''' Cálculo del IVA a un monto dado Ver. 0.4'''
monto=round(base*tasa/100,decimales)
return monto
valor_tasa=16
Aunque luego cambiemos la variable valor_tasa a 16, la función impuesto() quedará en un valor de por defecto de 15 en la tasa a lo largo de todo el programa.
¿Recordáis que os dijimos que la tasa de impuesto puede variar, según las necesidades fiscales del país? Pues bueno, nuestra función se puede preparar a futuro (por ejemplo, realizamos una sencilla aplicación de facturación y manejo de inventario) si escribimos nuestras funciones de esta manera, las podemos a volver a recompilar rápidamente si al módulo principal le cambiamos el valor.
Funciones con argumentos arbitrarios.
Podemos definir una función que acepte cualquier argumento, habiendo ya estudiado anteriormente la flexibilidad que denota Python. Son pocos caracteres que la componen, pero no se dejen engañar: es una función compleja y difícil de asimilar, muy genérica, y es difícil darle un uso práctico:
Funciones con argumentos arbitrarios pero con palabras claves.
Para «declarar» argumentos arbitrarios en una función solamente tenemos que precederla con un asterisco y así Python «sabrá» agruparlas en un «diccionario» lo cual nos permite listarlas (y trabajar) dichos argumentos (que serán una simple variable más dentro de la función). Pero como mejor es explícito que implícito, Python nos permite pasar argumentos con palabras claves (y todas deben llevar su palabra clave o producirá una «errror» o excepción). Tomemos de nuevo nuestra función de cálculo de IVA con una base dada
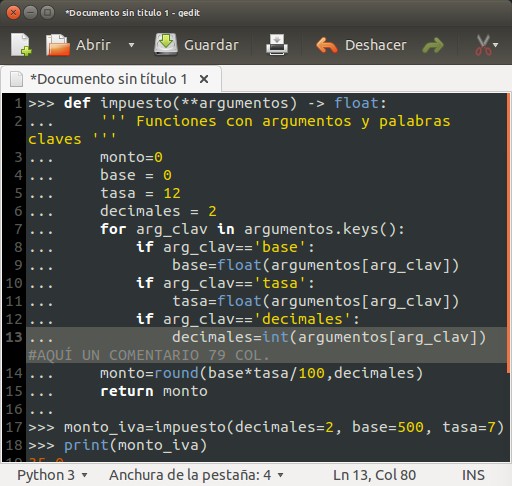
>>> def impuesto(**argumentos) -> float:
... ''' Funciones con argumentos y palabras claves '''
... monto=0
... base = 0
... tasa = 12
... decimales = 2
... for arg_clav in argumentos.keys():
... if arg_clav=='base':
... base=float(argumentos[arg_clav])
... if arg_clav=='tasa':
... tasa=float(argumentos[arg_clav])
... if arg_clav=='decimales':
... decimales=int(argumentos[arg_clav])
... monto=round(base*tasa/100,decimales)
... return monto
...
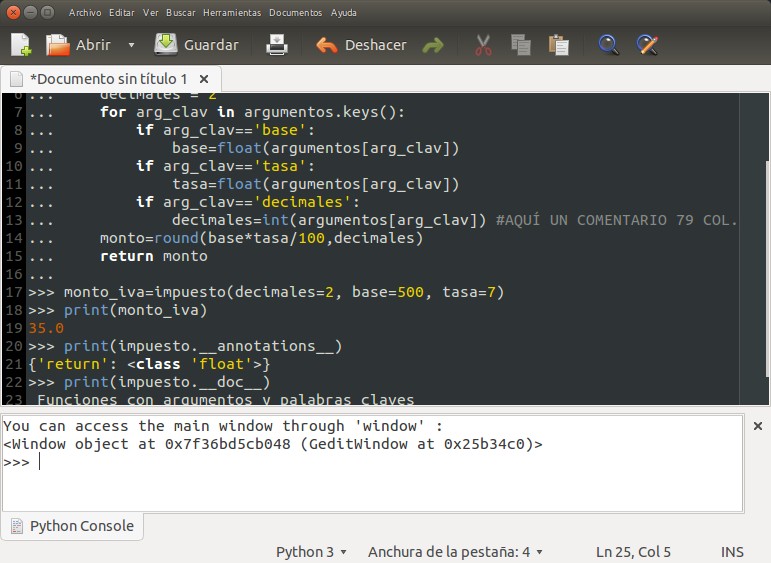
>>> monto_iva=impuesto(decimales=2, base=500, tasa=7)
>>> print(monto_iva)
35.0
>>> print(impuesto.__annotations__)
{'return': <class 'float'>}
>>> print(impuesto.__doc__)
Funciones con argumentos y palabras claves
>>>
Ya nuestras funciones van ganando complejidad y cada vez es más difícil escribirlas en modo interactivo, creemos que ya vale la pena escribirlas en un archivo por medio de nuestro editor de texto favorito, pronto daremos unas recomendaciones al respecto y unas normativas de Python. Mientras, veámos que sucede en este último ejemplo:
Línea 1: declaramos la función en sí con metadatos incluídos.
Línea 2: le establecemos su docustring.
Líneas 3 a 6: incializamos las variables con su valor pro defecto, si lo tuviera.
Línea 7: llamamos a un ciclo for para enumerar todos los argumentos con palabra claves «pasadas» a la función.
Líneas 8 a 13: por medio de sentencias condicionales verificamos si todos los elementos de la fórmula del cálculo del impuesto están presentes, si faltare alguno pues tomaría su valor por defecto.
Línea 14: realiza el cálculo en sí.
Línea 15: devuelve el resultado hacia fuera de la función.
Demás líneas: anotaciones de la función y su docustring. Obsérvese que en las anotaciones solo nos indica que es una función que solo devuelve un valor numérico flotante, sin ninguna información de los argumentos necesarios para que «haga su trabajo»
¿Qué utilidad tiene esto, declarar una función tan extraña que acepte cualquier cantidad de argumentos con palabras clave? Cuando veamos los diccionarios en mayor detalle se nos ocurrirán unos cuantos usos útiles, en este punto vamos a probar algo muy sencillo:
Fíjense que las palabras claves deben estar encerradas entre comillas, y que debemos colocarle dos asteriscos al llamar a la función, así estemos declarando la función con **argumentos, esto es lo más curioso del asunto y nos devuelve al principio: cualquier función acepta los argumentos con palabras claves si le colocamos ** al llamar la función con un diccionario ¿complejo, cierto? Y apenas estamos comenzando 😉 .
Funciones «clonadas».
Python nos permite tomar las funciones que importemos y «cambiarles» el nombre. Así nuestra función impuesto() que escribimos, tal vez sea para nosotros memorizarla de otra manera, por ejemplo impt(), pues solo debemos escribir impt = impuesto y pasarle los valores con el diccionario que hicimos anteriormente, he aquí:
A veces necesitamos usar una función una sola vez (cosa rara) y codificarlo en 3 líneas como mínimo (aparte de ir en una sección aparte de nuestro proyecto dedicada a las funciones) pues que nos lleva tiempo y espacio. Para ello echamos mano de la ¿función de funciones? el comando lambda. Este comando nos permite aplicar, por ejemplo, un cálculo como el nuestro, que es sumamente sencillo, practiquemos:
>>> (lambda base : round(base*12/100,2))(100)
12.0
Como vemos no le colocamos nombre a la función, solo le indicamos que devuelva la misma base con el cálculo del impuesto (es todo lo que encierra el primer par de paréntesis de izquierda a derecha) y en el segundo par de paréntesis le pasamos el argumento con la base a calcular. Tal vez sea complicado de entender así que pasamos a definir la función y «clonarla» con un nombre:
Acá vemos que es una manera de definir rápidamente una función. Si queremos colocarle los argumentos completos la podemos definir de la siguiente manera:
Evidentemente que los argumentos son posicionales, si queremos agregarles palabras claves… pues para eso definimos la función completa como ya lo hemos hecho. Consideramos útil a este comando/función dentro de otra función declarada para que se circunscriba dentro de esa función solamente, pero vosotros juzgad y dadle algún otro uso novedoso, ¡a practicar!
Estilo al codificar.
En PEP 8 se especifica cómo codificar nuestras funciones y para que queden correctas deben cumplir con las suguientes especificaciones:
Se deben indentar con 4 espacios y sin tabuladores (ver al final nuestras recomendaciones).
Las líneas no deben superar los 79 caracteres.
Se deben usar líneas en blanco entre funciones y clases.
Cuando sea posible, coloque los comentarios en la misma línea que describe.
Se debe usar docustring (¿deberíamos traducirlo como ‘docutexto‘?).
Se deben usar espacios entre los operadores y después de las comas pero no dentro de los paréntesis, ejemplo: a = f(1,2) + g(3,4) .
En el caso de las funciones y métodos se deben separar las palabras con guión bajo, por ejemplo impuesto_iva() , impuesto_sobre_renta() ; las clases se deben nombrar en estilo jorobas de camello: TasaDeImpuesto.
En el caso de que nuestro código sea para uso internacional, deberemos usar solamente caracteres básicos. Evidentemente que nuestro idioma utiliza muchos caracteres extendidos en UTF-8, así que todo dependen hacia adonde va dirigido.
Uso de gedit con python.
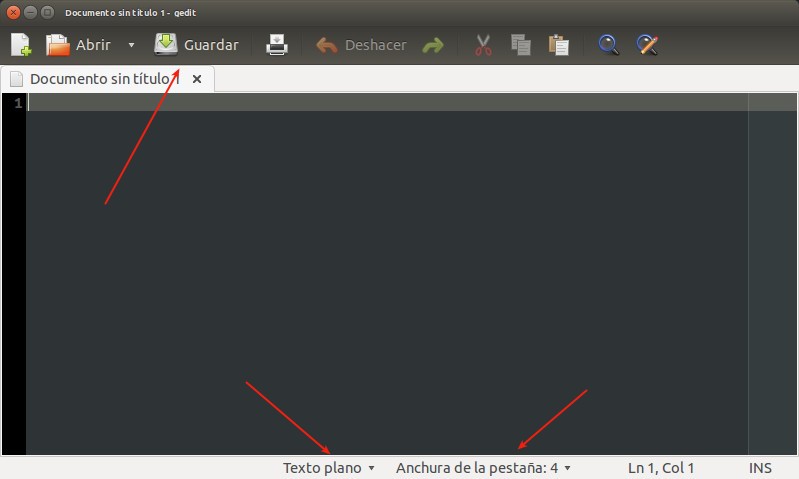
Por mucho nuestro editor de texto favorito es gedit debido a que tiene ciertas características deseables para programar pequeños proyectos de código.
Las capturas de pantalla aquí mostradas corresponde a gedit 3.10.4:
gedit version 3.10.4
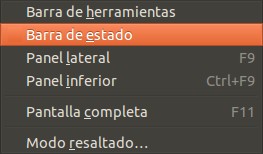
Al ejecutarlo lo primero que debemos activar es la barra de herramientas y la barra de estado en el menú desplegable «Ver»:
gedit barra de herramientas y barra de estado
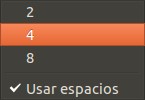
Al marcar estas dos opciones podremos ver en la aprte superios los comandos más usados como: documento nuevo, abrir documento, guardar, imprimir, etcétera. A pesar que todos estos comandos tiene sus atajos de teclados, los íconos de los botones tienen un efecto muy intuitivo. La parte más importante es la parte inferior la cual permite escoger qué lenguaje estamos programando y justo al lado la cantidad de espacios a insertar en el indentado automático y al presionar la tecla tabulador inserte espacios en vez de la caracter tabulador en sí, veamos:
gedit ventana principalgedit lenguajes soportadosgedit cantidad de espacios a usar con la tecla TAB
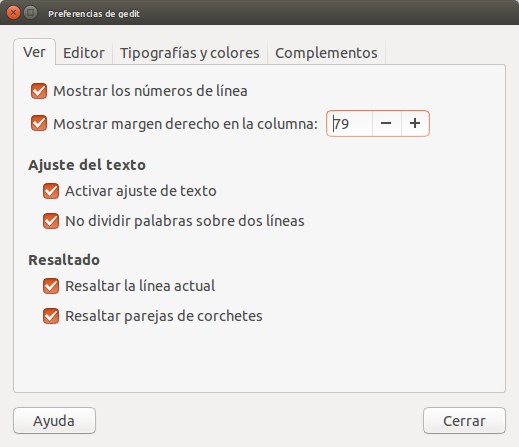
También podemos guardar nuestras perferencias para la próxima vez que ejecutemos gedit, para hacerlo vamos al menu desplegable «Editar» -> «Preferencias» y marcamos las siguientes opciones, todo según las normas de estilo de Python:
Preferencias de gedit
Mostrar los números de línea nos sirve para hallar rápidamente dónde debemos corregir cuando el depurador Python nos indica algún fallo de sintaxis.
Al mostrar el margen derecho con una pequeña marca de agua nos ayuda a no sobrepasar los 79 caracteres.
Si activamos el ajuste de texto, así no sobrepasamos los 79 caracteres por línea pero cambiamos el tamaño de nuestra ventana, gedit nos colocará las líneas que no quepan en la ventan en múltiples líneas pero respetando la numeración para indicarnos que es una sola línea sobre la que estamos trabajando. La opción de no dividir palabras nos permite los comandos completos, sin divisiones.
La opción de resaltar la línea actual nos permite enfocarnos en la linea sobre la cual estamos editando y si es multilínea (ve punto anterior) nos ofrece un mejor panorama.
Por último resaltar parejas de corchetes nos permite anidar funciones y sus argumentos son más fáciles de visualizar.
gedit activar ajuste de texto
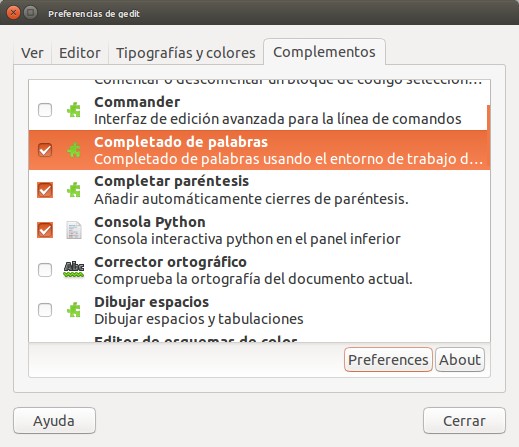
Una vez hayamos fijado nuestras preferencias (la cuales se aplican en tiempo real, así que muestran como se ve nuestro archivo de una vez) también podemos activar los complementos que nos serán muy útiles:
gedit complementos: completado de palabras, completar paréntesis y cónsola python.
El completado de palabras «memoriza» los comandos que hayamos escrito y al nosotros volver a escribirlos el complemento lo sugiere por medio de un pequeño menú emergente. Recomendamos hacer click en «preferences» y marcar interactivo y un mínimo de 3 letras por palabra.
Completar paréntesis, corchetes rectos y llaves evita el error común de no hacerles el cierre. No funciona con los corchetes angulares «<» y «>».
Por último la cónsola python: al activarla podemos pulsar CTRL+F9 y una subventana en la parte inferior nos abre una cónsolar interactiva con práticamente las mismas características de la cónsola python. Podemos volver a la edición del documento con la tecla ESC y volver a abrir la cónsola python con CONTROL+F9.
En una publicación anterior tratamos el tema de generar códigos QR con lenguaje Python y hasta escribimos un sencillo cliente FTP para sincronizar los archivos de una carpeta local versus una carpeta remota. He aquí que entonces que necesitamos un tutorial sobre cómo funciona el lenguaje Python, un lenguaje versátil multiplataforma. Específicamente estaremos tratando la versión 3.5.2 porque consideramos que es el futuro y tiene varios años ya de existencia entre nosotros, dado el caso que valga la pena referirnos a alguna versión 2.X lo especificaremos pero la idea es ser lo más sencillo posible con abundancia de ejemplos y la menor teoría posible.
El objetivo de escribir python-easy-ftp-sync persigue como fin último la creación de un programa por línea de comandos escrito en lenguaje Python versión 3.4.3 para sincronizar dos carpetas (y sus subcarpetas) por medio de FTP (File Transfer Protocol), así de sencillo, por ello lo de parte del nombre «easy» (fácil -o tranquilo- en idioma inglés). Por supuesto que no vamos a descubrir el agua tibia, antes que nosotros muchos autores han escrito sobre el tema, y lo grandioso del software libre -y la ciencia moderna en sí misma- es que no tenemos que partir desde cero (aunque sería un muy buen ejercicio) sino que podemos estudiar esos trabajos anteriores y sobre ellos construir nuestra herramienta.
En el día de hoy aprendimos que se pueden generar «QR codes» (la cual es la abreviatura, en inglés, de «Quick Response Code«) con un paquete para el lenguaje Python. Fueron creados en Japón para el manejo de piezas y manufactura de vehículos de la marca Toyota, a fin de agilizar grandemente los inventarios. Explicar cómo funcionan merece su entrada completa y aparte, aquí vamos a explicar brevemente cómo instalarlo y usarlo con Python.
Agradecimiento.
Agradecemos de antemano a los programadores de software libre de «Industrias Diana» cuya exposición fue brillante en el «Décimo Primer Congreso de Software Libre». Dicha exposición abarcó varios temas acerca del proceso y manejo de la información, entre otros la comunicación con impresoras fiscales y la generación de códigos QR, caso que nos ocupa hoy. Muchas gracias por compartir el conocimiento, cumplimos con seguir difundiendolo.

 Esta entrada no pretende ser una guía exhaustiva de Python ni tampoco algo avanzado en el campo de la inteligencia artificial, apenas es la presentación de todo aquello, un abrebocas: primero estableceremos un entorno de programación y luego ejecutaremos un mini curso de 14 lecciones sobre «machine learning» cuyo material es proporcionado al mundo entero por el Dr. Jason Brownlee en su página web (en idioma inglés).
Esta entrada no pretende ser una guía exhaustiva de Python ni tampoco algo avanzado en el campo de la inteligencia artificial, apenas es la presentación de todo aquello, un abrebocas: primero estableceremos un entorno de programación y luego ejecutaremos un mini curso de 14 lecciones sobre «machine learning» cuyo material es proporcionado al mundo entero por el Dr. Jason Brownlee en su página web (en idioma inglés).