En la entrada anterior explicamos cómo instalar y configurar el phpPgAdmin y creamos nuestra primera base de datos (basados en el usuario «adminsql» de la primera entrada de esta mini serie de artículos), y esta entrada estará dedicada a la poderosa herramienta Visual Paradigm (que puede descargar para GNU/Linux en este enlace ) con la cual podremos crear tablas y sus relaciones de una manera gráfica y hasta amena (si se quiere) en comparación a los comandos por cónsola. Para mí es una novedad esta herramienta, y creo que es representativa del nivel de calidad de software que contamos hoy en día no obstante dedicaremos una entrada a las órdenes por cónsola, por aquello de la nostalgia. 😉
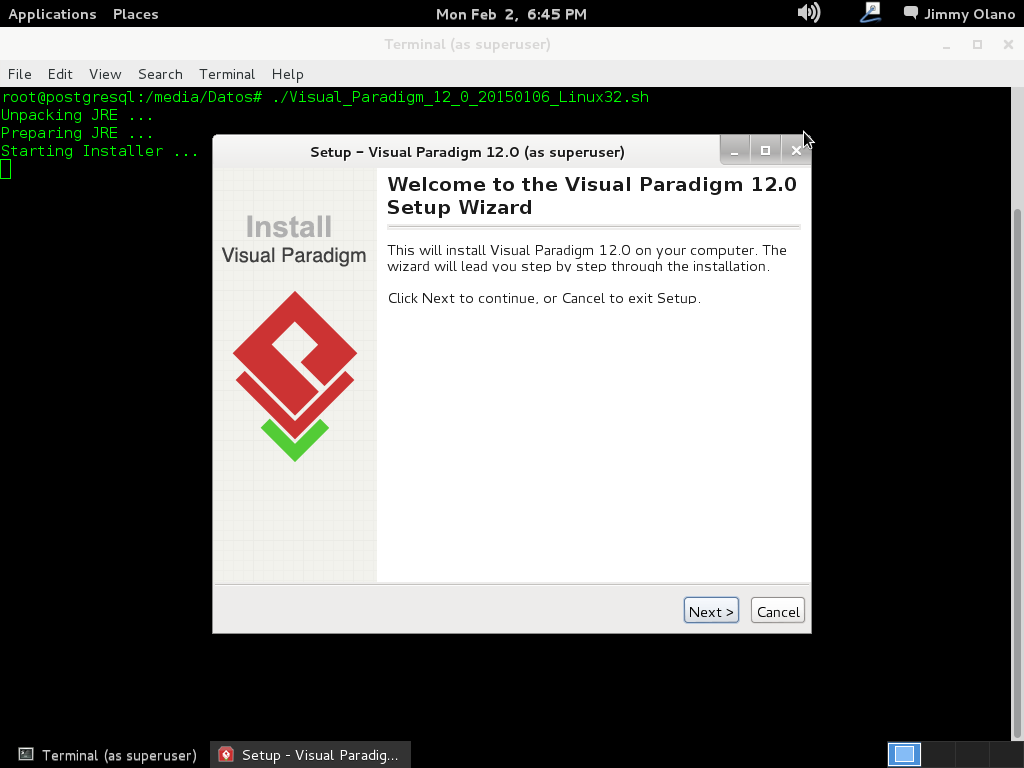
Pues bien, empecemos: de primero ya descargamos el archivo llamado Visual_Paradigm_12_0_20150106_Linux32.sh que no es más que un archivo de procesamiento por lotes (o shell script en idioma inglés) en este caso MUY GRANDE que ocupa 253,3 megabytes y al cual hay que dedicarle al menos mil megabytes de espacio en disco para ser instalado. Es grande.
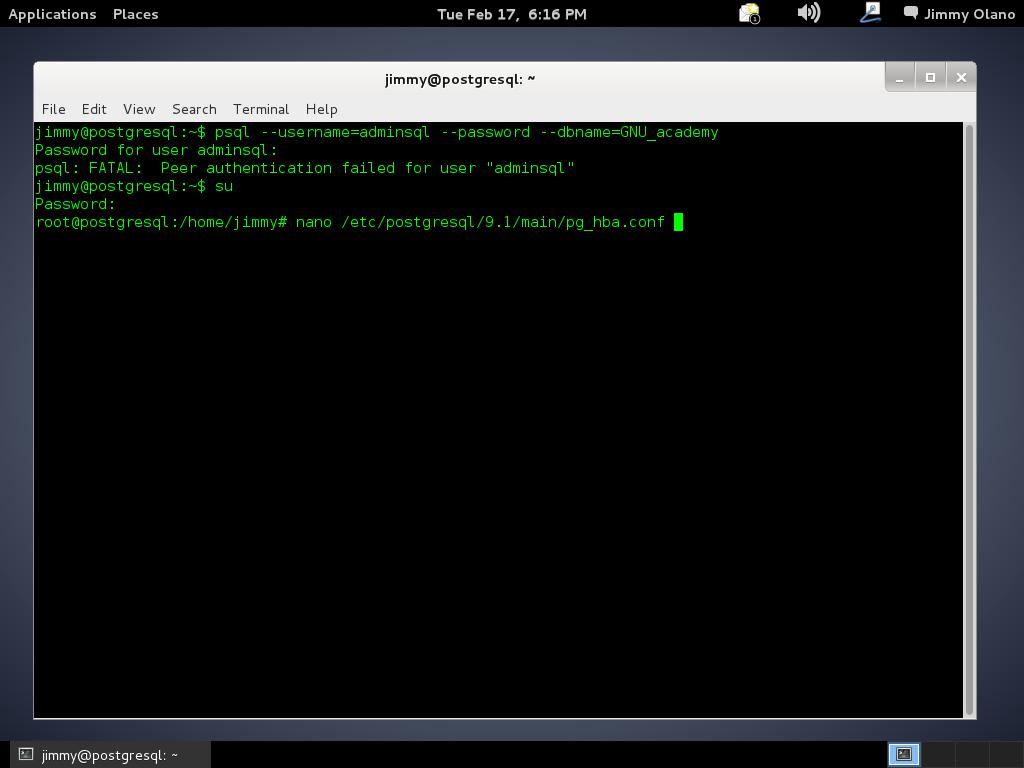
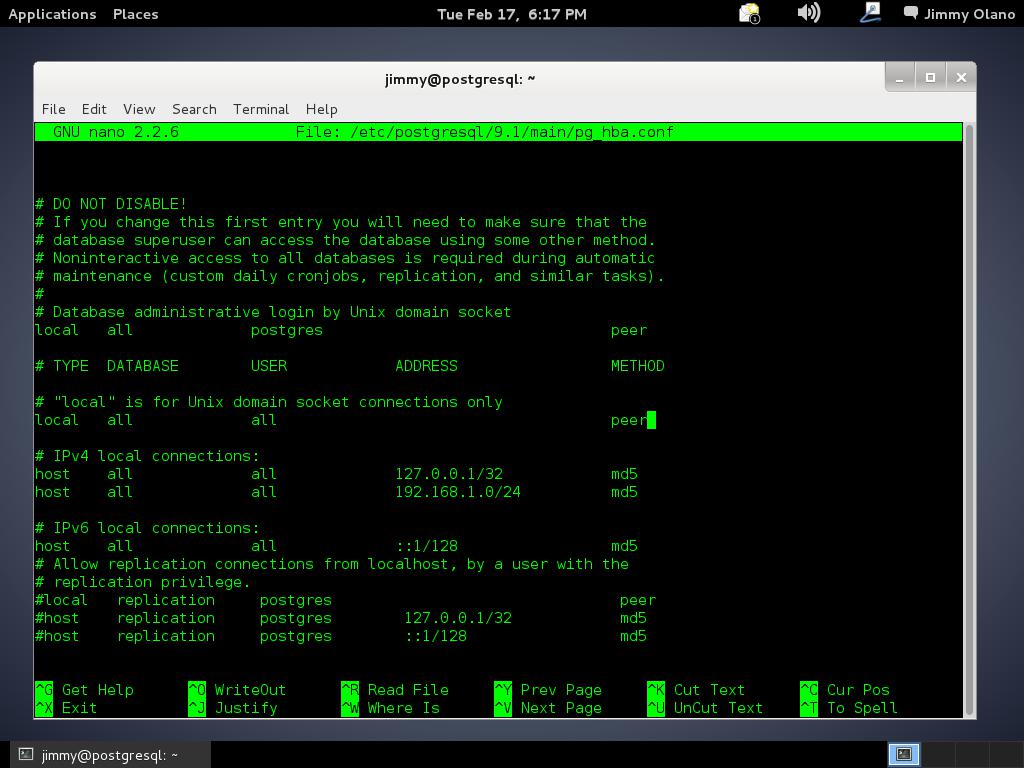
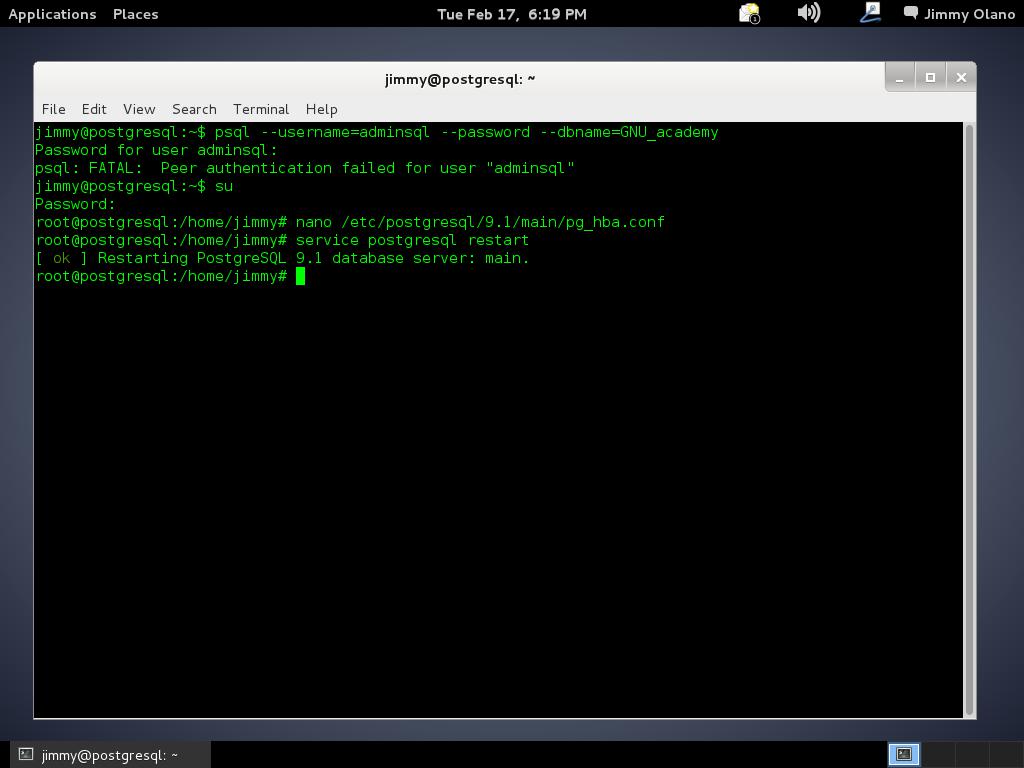
Abrimos una terminal con derechos de usuario root y nos vamos a la carpeta de descargas de nuestro navegador web (o a la carpeta donde realmente los guardamos) y ejecutamos:
./Visual_Paradigm_12_0_20150106_Linux32.sh
 Hacemos click en «next» y veremos lo siguiente:
Hacemos click en «next» y veremos lo siguiente:
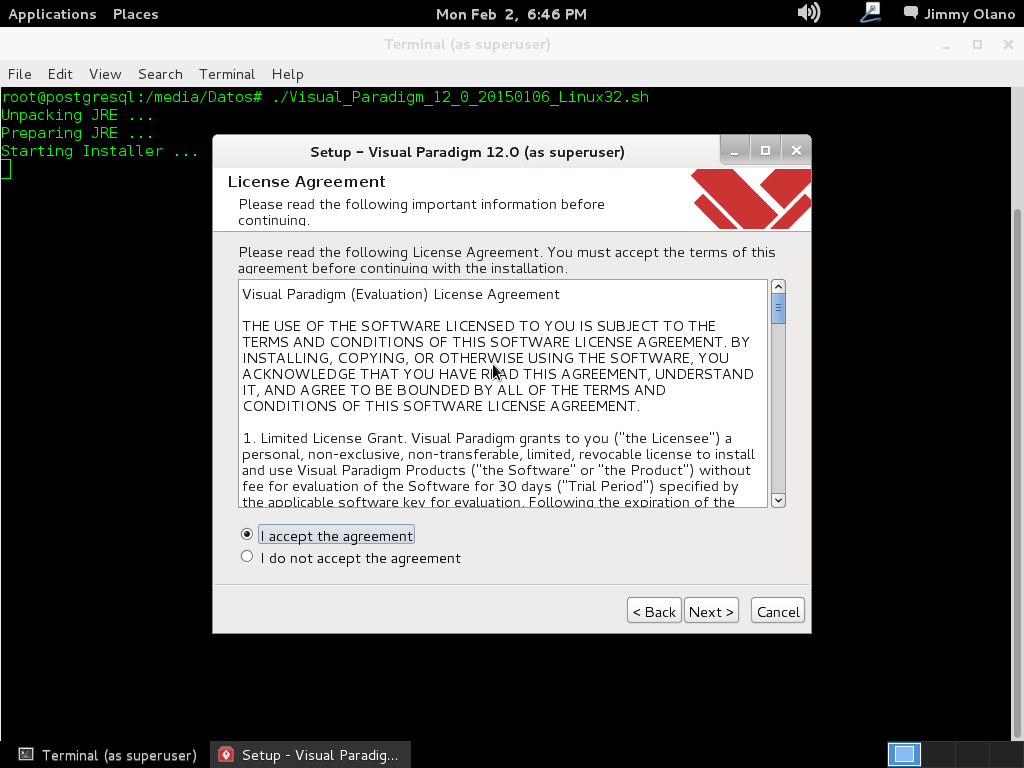
 Pueden leer completo (en inglés) la el acuerdo de licencia completo haciendo click aquí. Seleccionamos «I accept the agreement» y hacemos click en «next»:
Pueden leer completo (en inglés) la el acuerdo de licencia completo haciendo click aquí. Seleccionamos «I accept the agreement» y hacemos click en «next»:
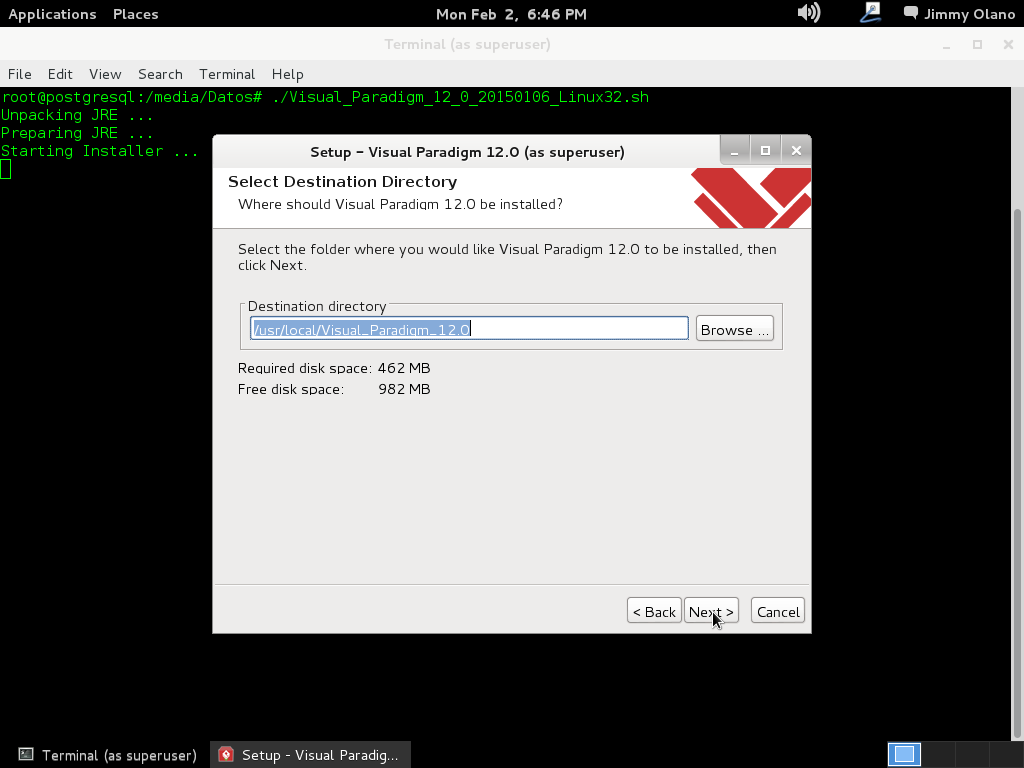
 En nuestro caso dejamos el directorio por defecto (si hacen click en «browse» pueden seleccionar otra ubicación) y hacemos click en «next»:
En nuestro caso dejamos el directorio por defecto (si hacen click en «browse» pueden seleccionar otra ubicación) y hacemos click en «next»:
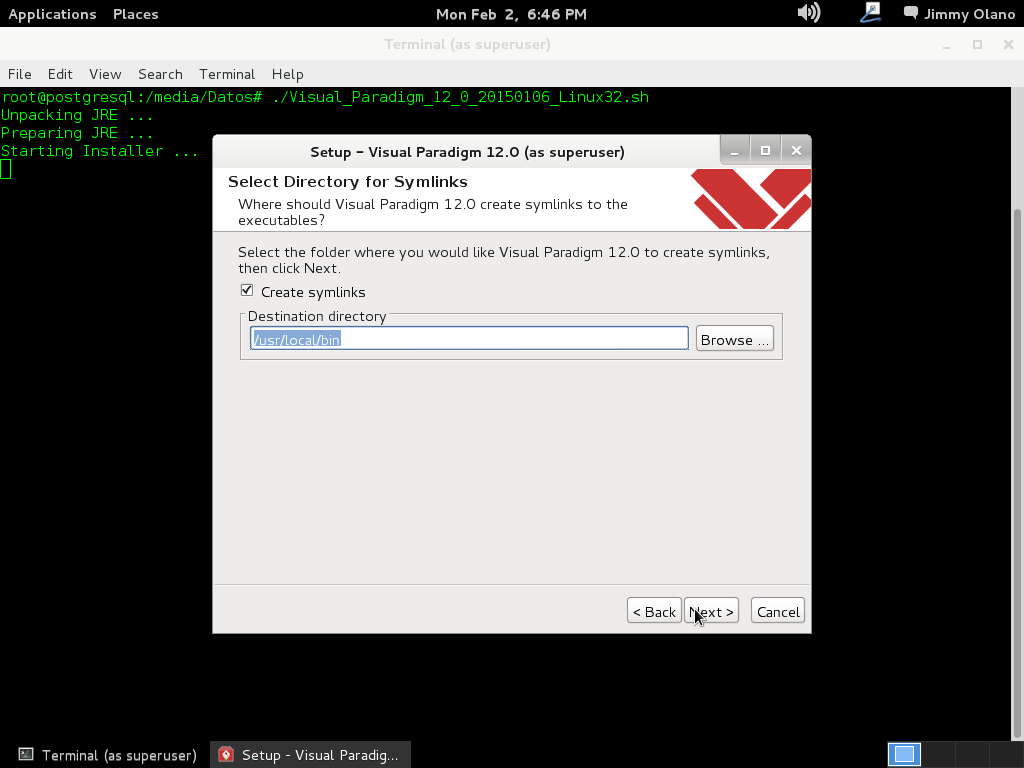
 Dejamos los «symlinks» o «symbolic link» (o «enlace simbólico«) en su directorio por defecto (dichos enlaces simbólicos son archivos que apunta hacia la ubicación real de los archivos y ayudan, por ejemplo, dar nombres cortos a los programas que nos ahorran trabajo cuando escribimos por cónsola). Hacemos click en «next» y comienza realmente la instalación en sí:
Dejamos los «symlinks» o «symbolic link» (o «enlace simbólico«) en su directorio por defecto (dichos enlaces simbólicos son archivos que apunta hacia la ubicación real de los archivos y ayudan, por ejemplo, dar nombres cortos a los programas que nos ahorran trabajo cuando escribimos por cónsola). Hacemos click en «next» y comienza realmente la instalación en sí:

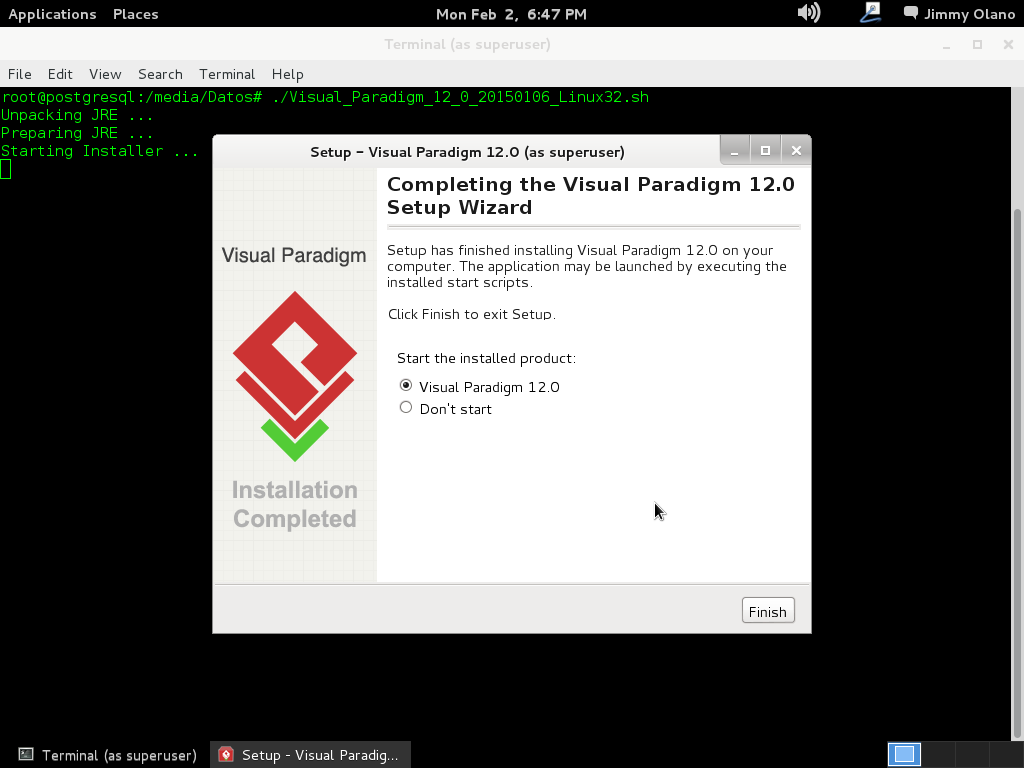
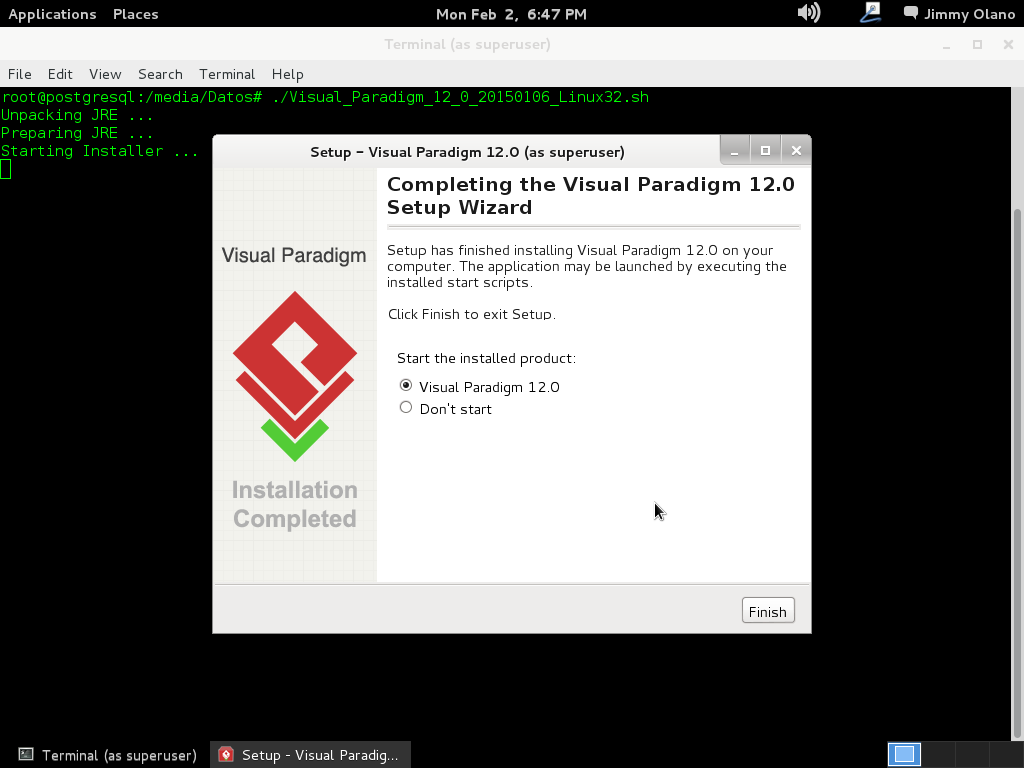 Como queda seleccionada por defecto la opción de ejecutar (o «correr») el programa hacemos click en «next» para seleccionar la opción de uso, en nuestro caso seleccionamos los 30 días de prueba:
Como queda seleccionada por defecto la opción de ejecutar (o «correr») el programa hacemos click en «next» para seleccionar la opción de uso, en nuestro caso seleccionamos los 30 días de prueba:
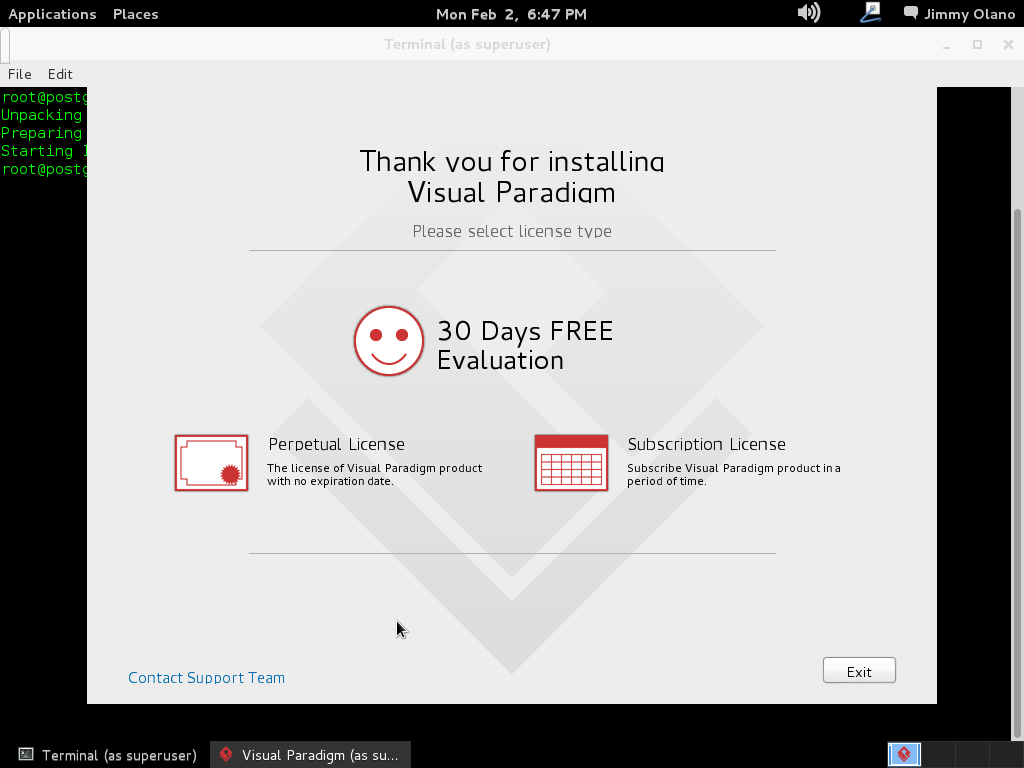
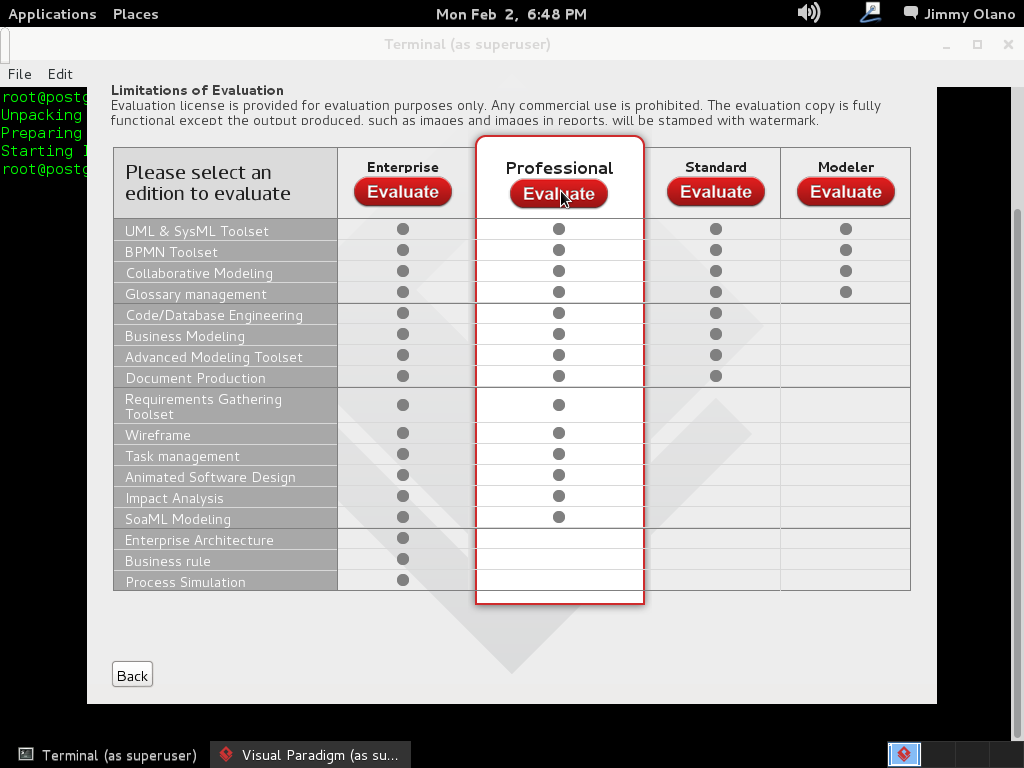
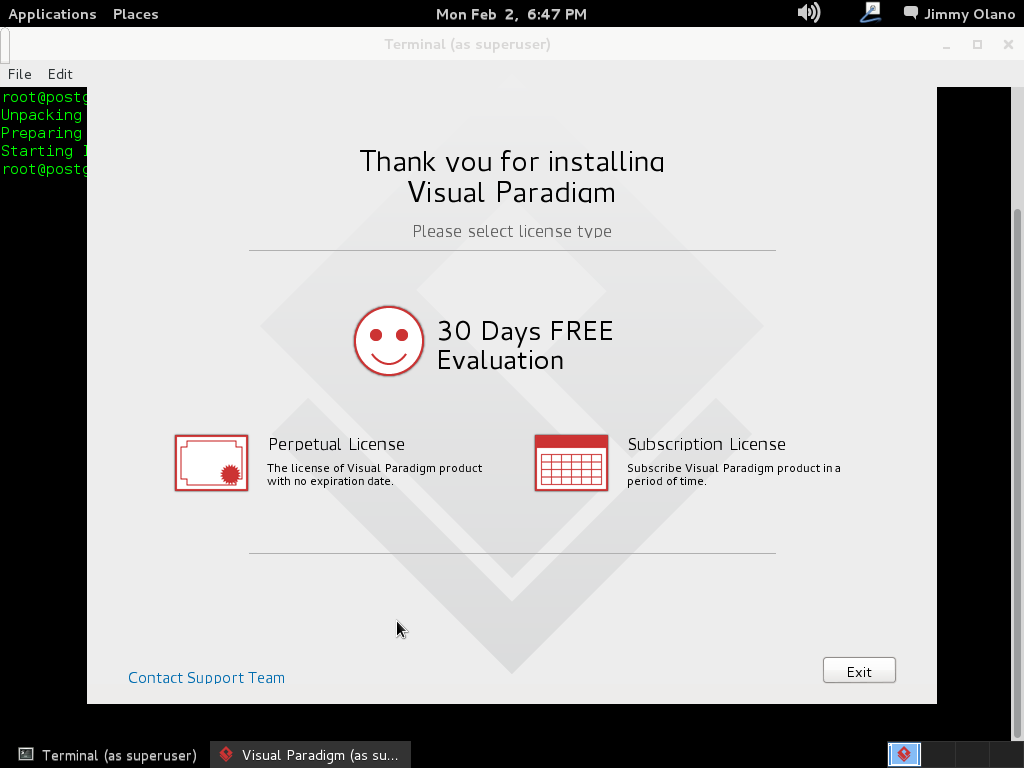 Recuerden que «Thus, ‘free software’ is a matter of liberty, not price.» («software libre es cuestión de libertad, no de precio») para nuestros propósitos didácticos la versiónde prueba es más que suficiente:
Recuerden que «Thus, ‘free software’ is a matter of liberty, not price.» («software libre es cuestión de libertad, no de precio») para nuestros propósitos didácticos la versiónde prueba es más que suficiente:
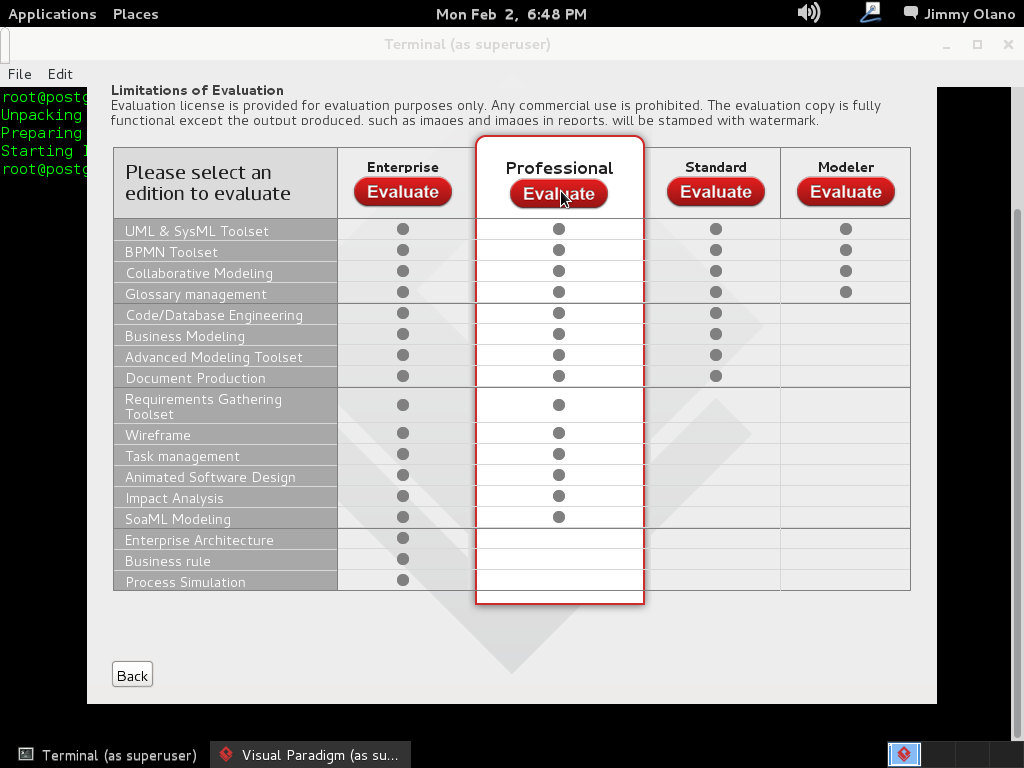
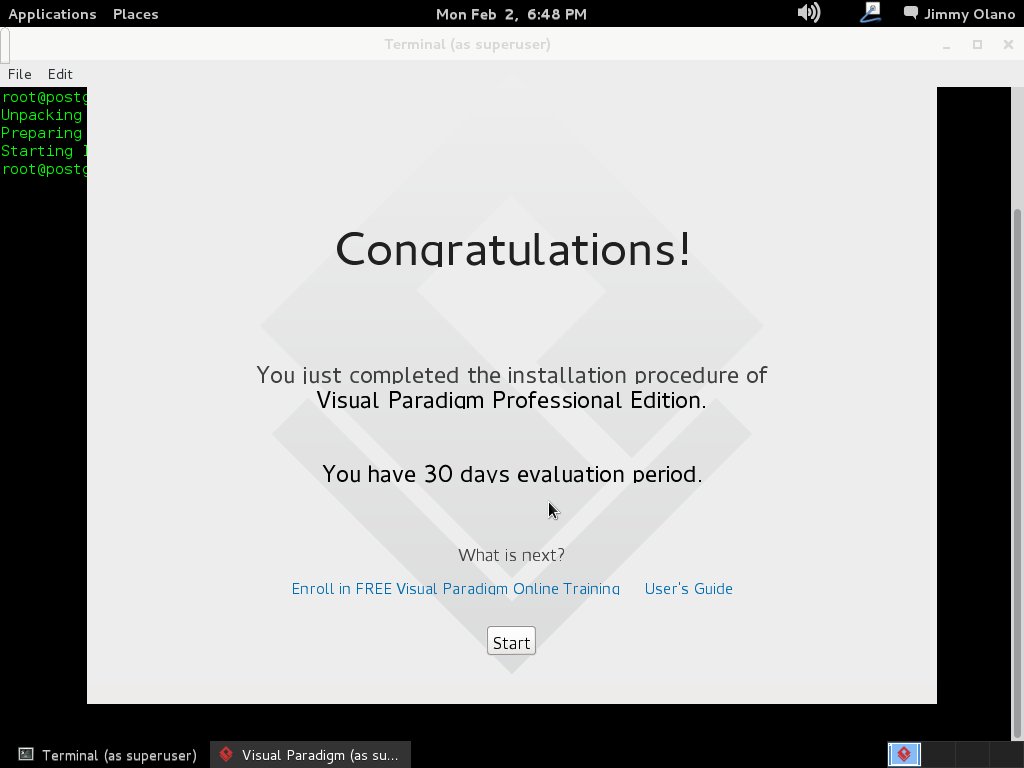
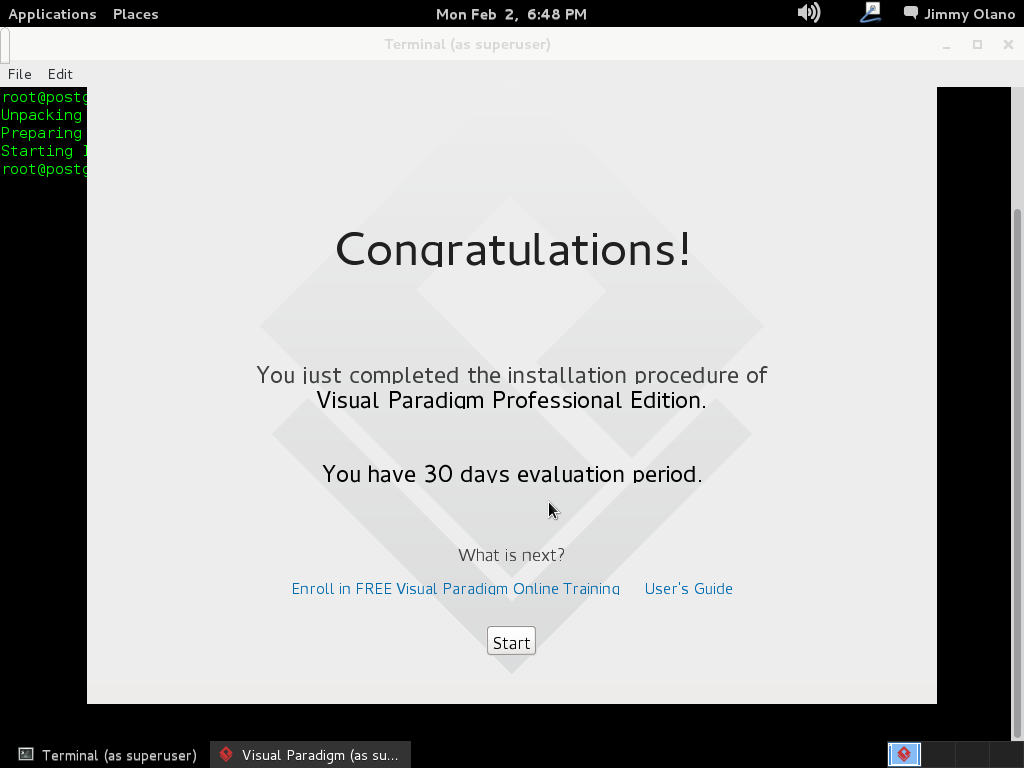 Hasta acá queda instalado la herramienta de software, ahora a trabajar en la creación de las tablas y sus relaciones.
Hasta acá queda instalado la herramienta de software, ahora a trabajar en la creación de las tablas y sus relaciones.
Creación de tablas y relaciones.
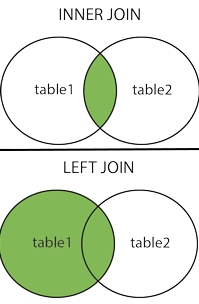
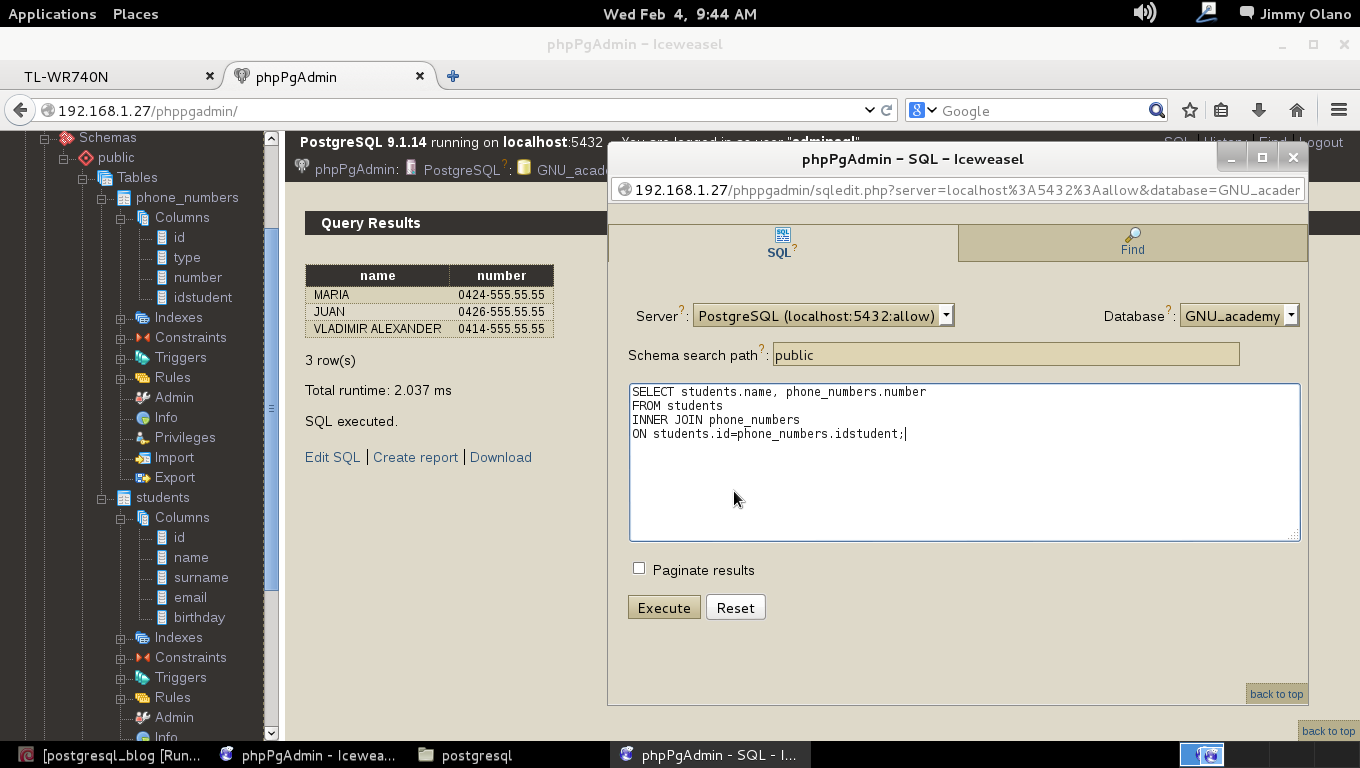
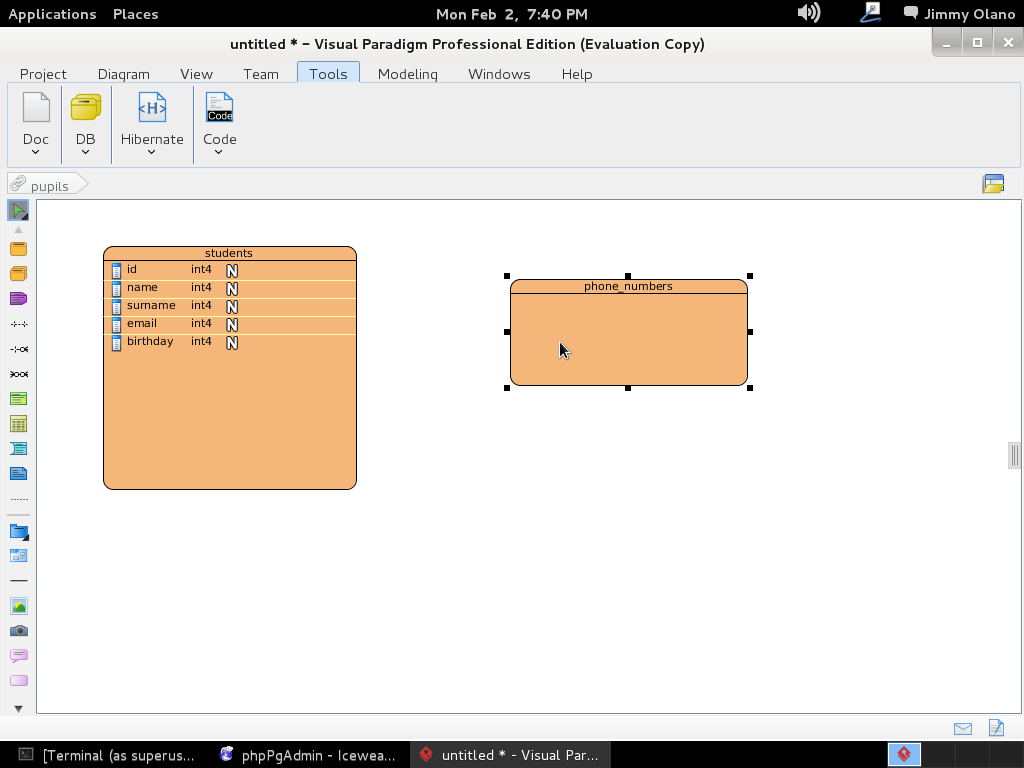
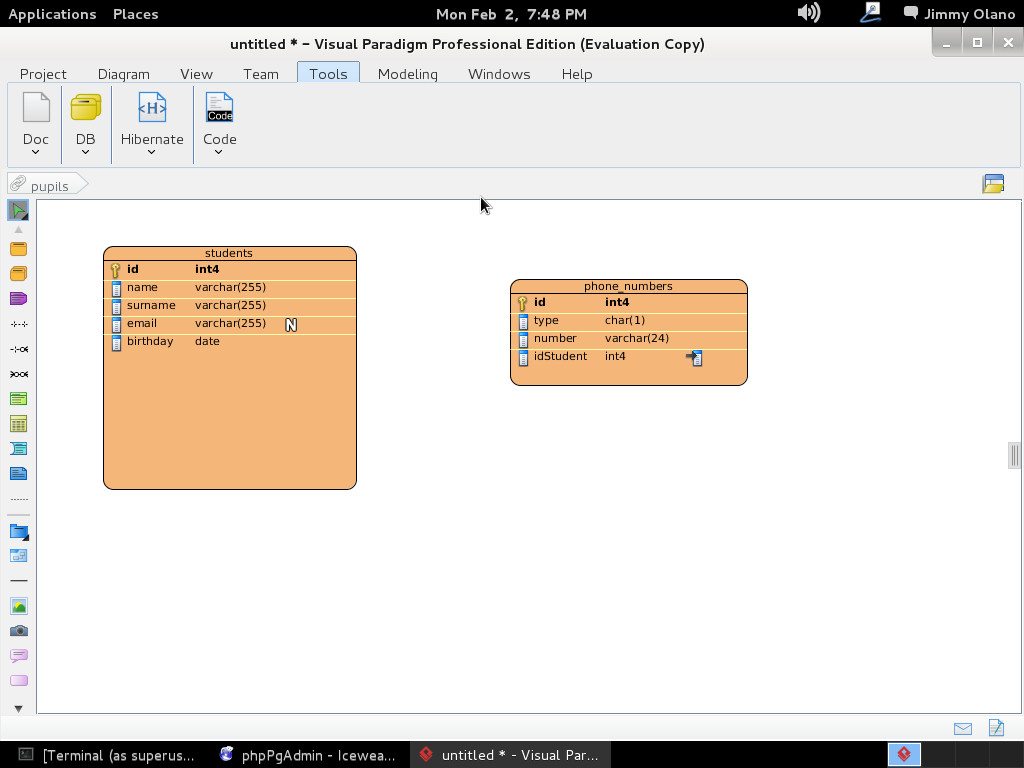
Nos proponemos crear dos tablas sencillas, una para contener los datos básicos de los estudiantes y otra con los números de teléfonos (teniendo en cuenta que cada persona puede tener un celular o móvil, el teléfono de casa, el de oficina u otro(s) números) relacionados por una «foreign key» que apunta a una «primary key» y en su debida oportunidad veremos las ventajas (y desventajas) de dicha forma de trabajar, todo bajo la «Normalización de base de datos«; por ahora basta con saber que ésos son los conceptos que nos basaremos para modelar.
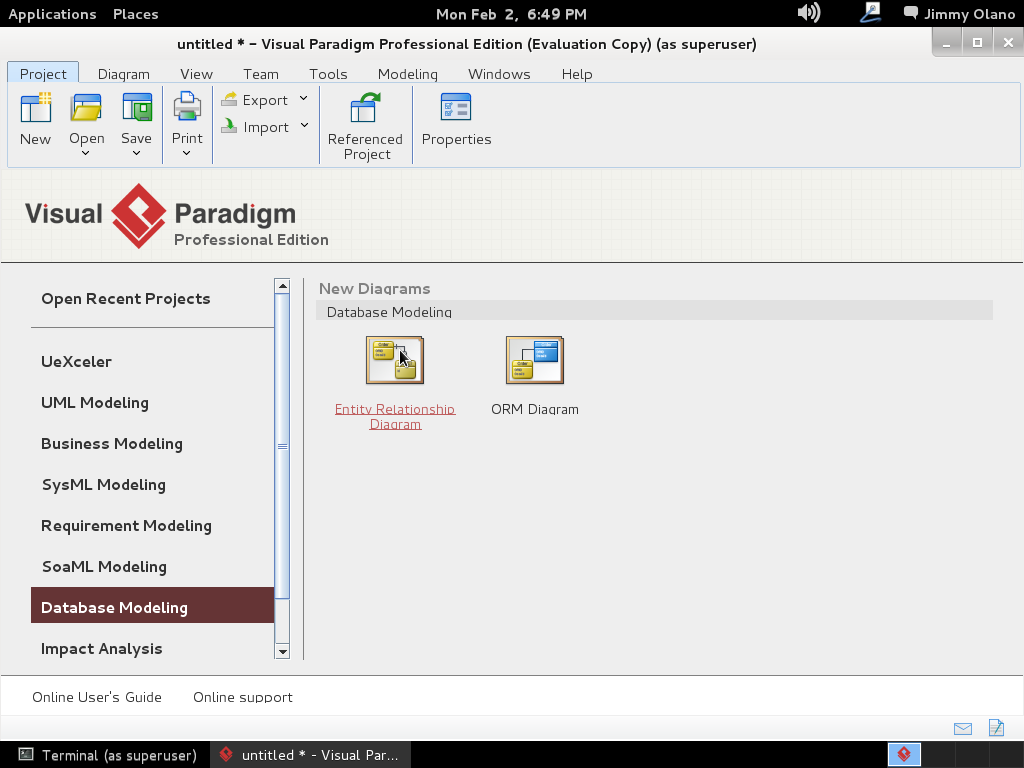
Una vez que arranca el programa seleccionamos «Database modeling»:
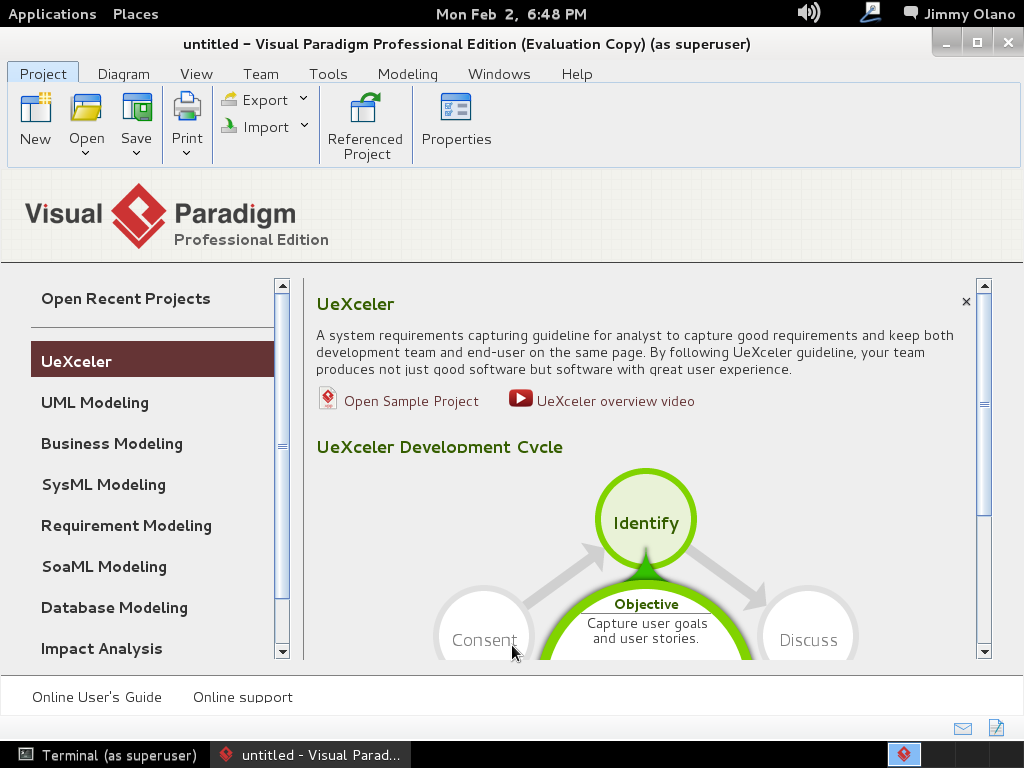
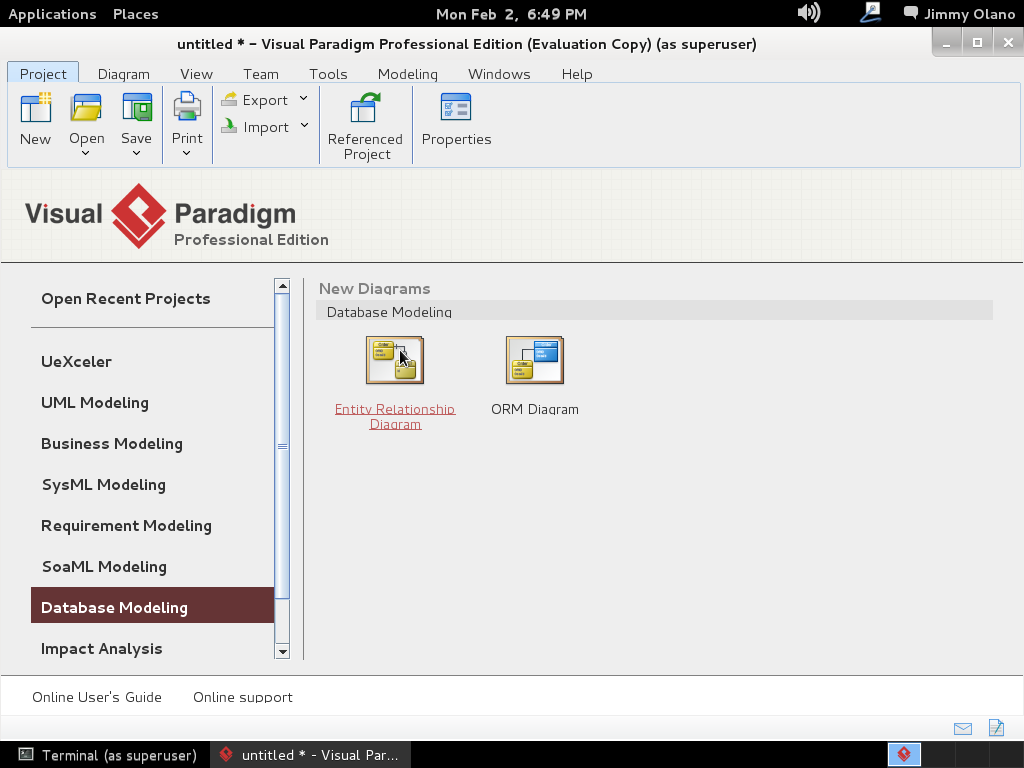 y luego hacemos click en «Entity Relationship Diagram» y le asignamos el nombre «pupils» al nuevo proyecto:
y luego hacemos click en «Entity Relationship Diagram» y le asignamos el nombre «pupils» al nuevo proyecto:
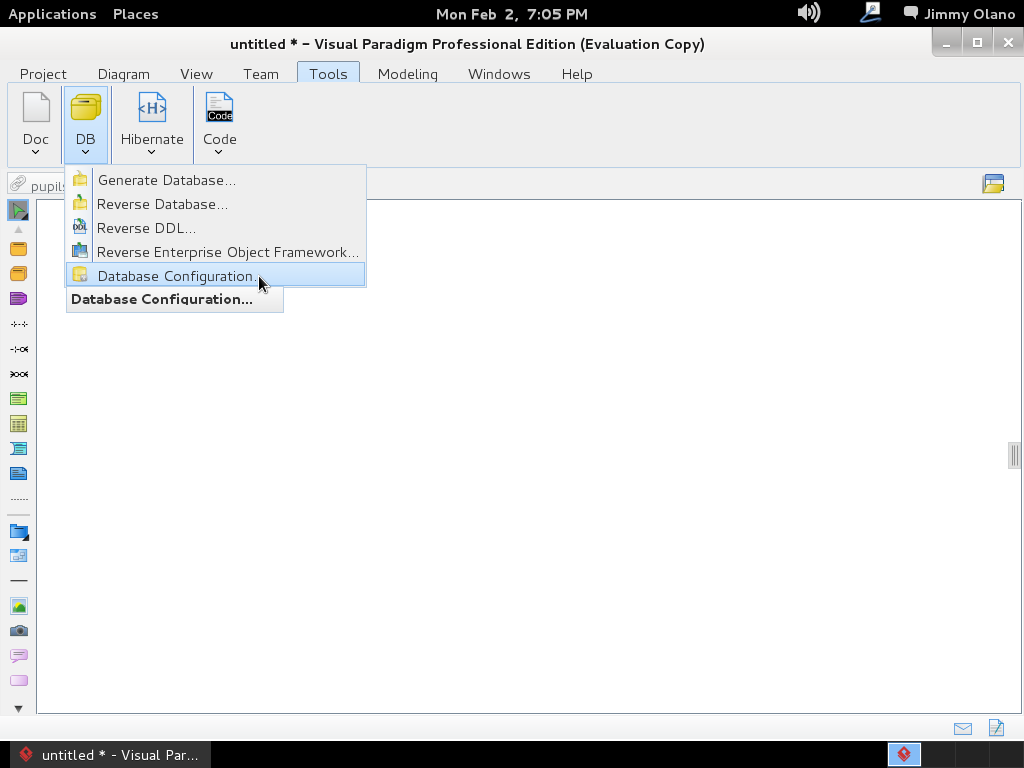
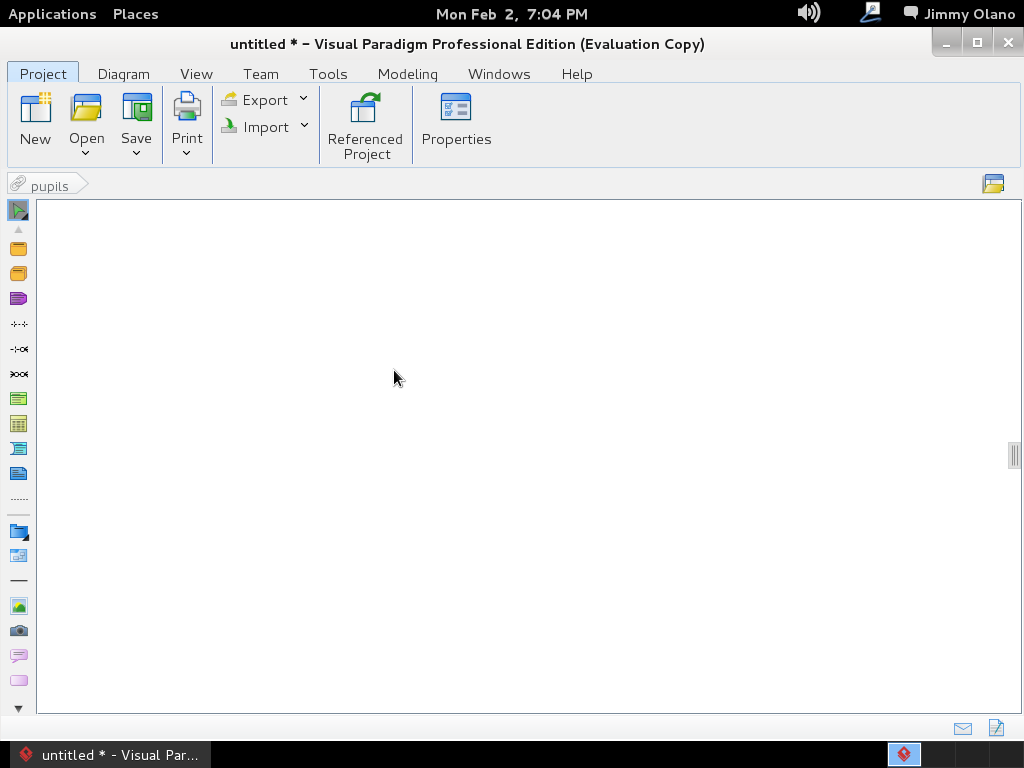 y procedemos primero que nada a configurar con cuál motor de base de datos vamos a trabajar, PostgreSQL para lo cual nos vamos a la pestaña «tools» y luego «Database Configuration«:
y procedemos primero que nada a configurar con cuál motor de base de datos vamos a trabajar, PostgreSQL para lo cual nos vamos a la pestaña «tools» y luego «Database Configuration«:
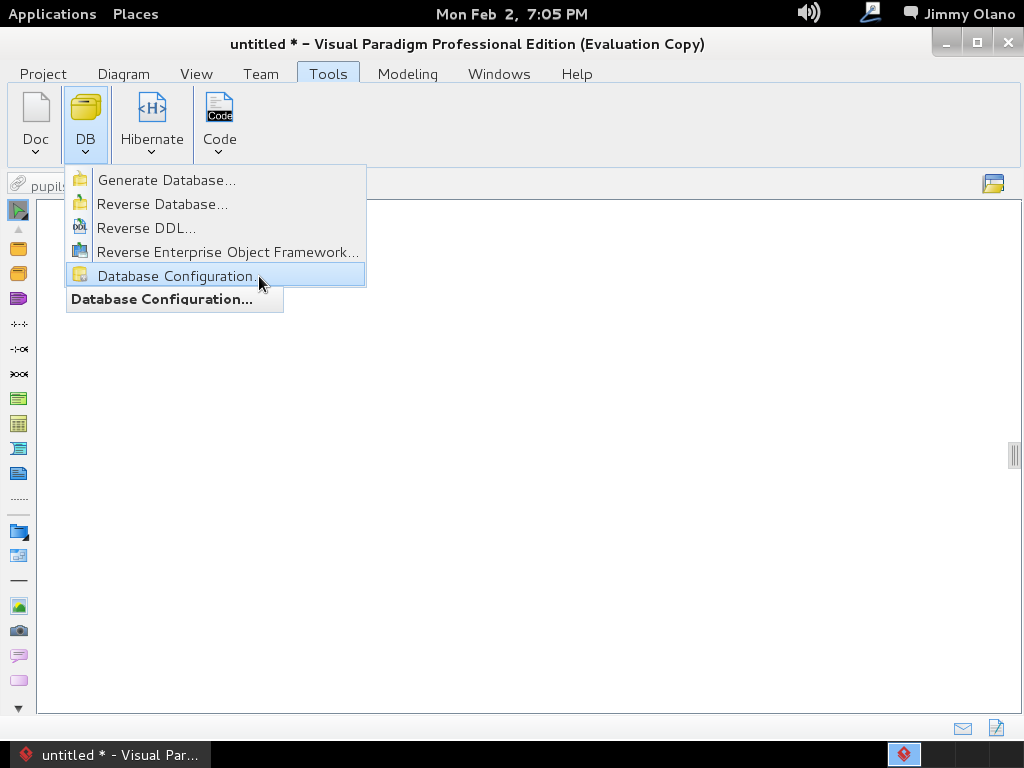 Hacemos click y se abre un cuadro de diálogo para que seleccionemos «PostgreSQL» no sin antes indicar dónde tenemos el «driver file» o «archivo controlador» que servirá para que Visual Paradigm pueda «hablar» con nuestro servidor recién instalado. Si nos fijamos bien en el mismo cuadro de diálogo nos indica de dónde podemos descargarlo:
Hacemos click y se abre un cuadro de diálogo para que seleccionemos «PostgreSQL» no sin antes indicar dónde tenemos el «driver file» o «archivo controlador» que servirá para que Visual Paradigm pueda «hablar» con nuestro servidor recién instalado. Si nos fijamos bien en el mismo cuadro de diálogo nos indica de dónde podemos descargarlo:
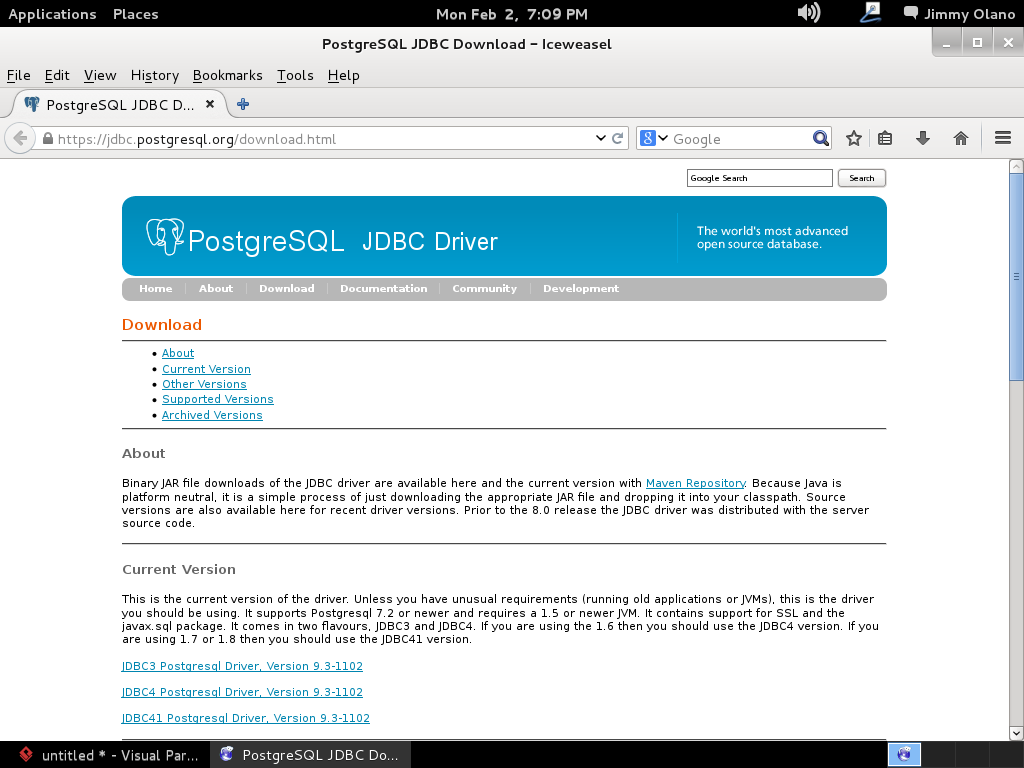
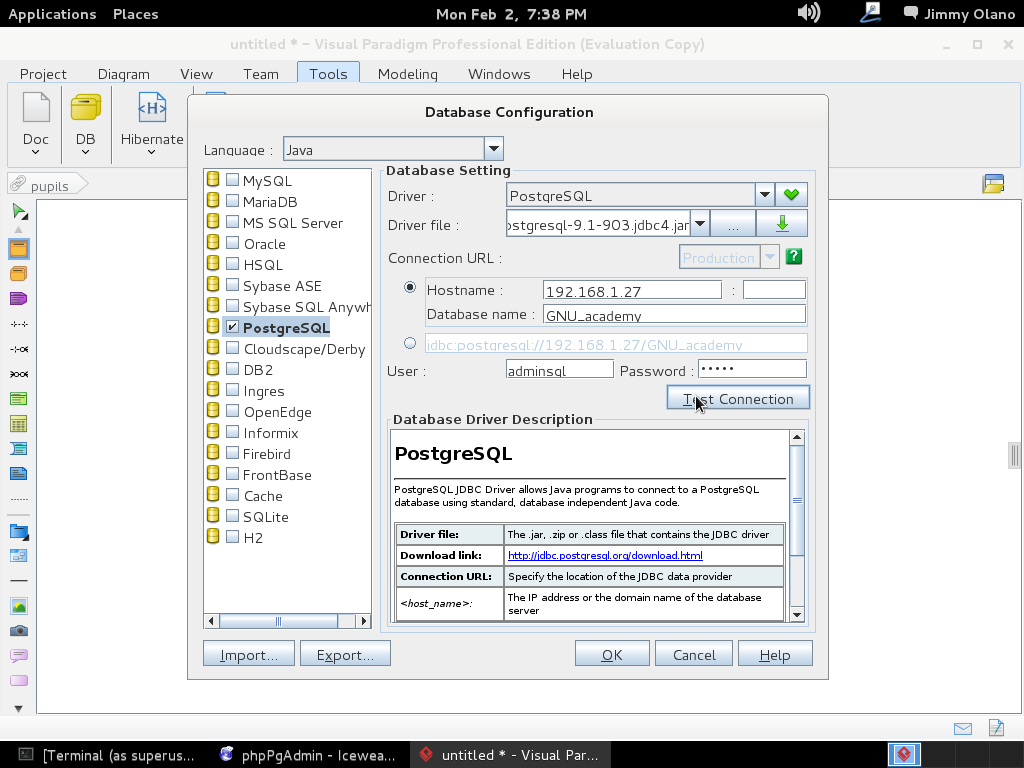 si hacemos click en «Download link» y tenemos paciencia se abre nuestro navegador web predeterminado con la siguiente página:
si hacemos click en «Download link» y tenemos paciencia se abre nuestro navegador web predeterminado con la siguiente página:
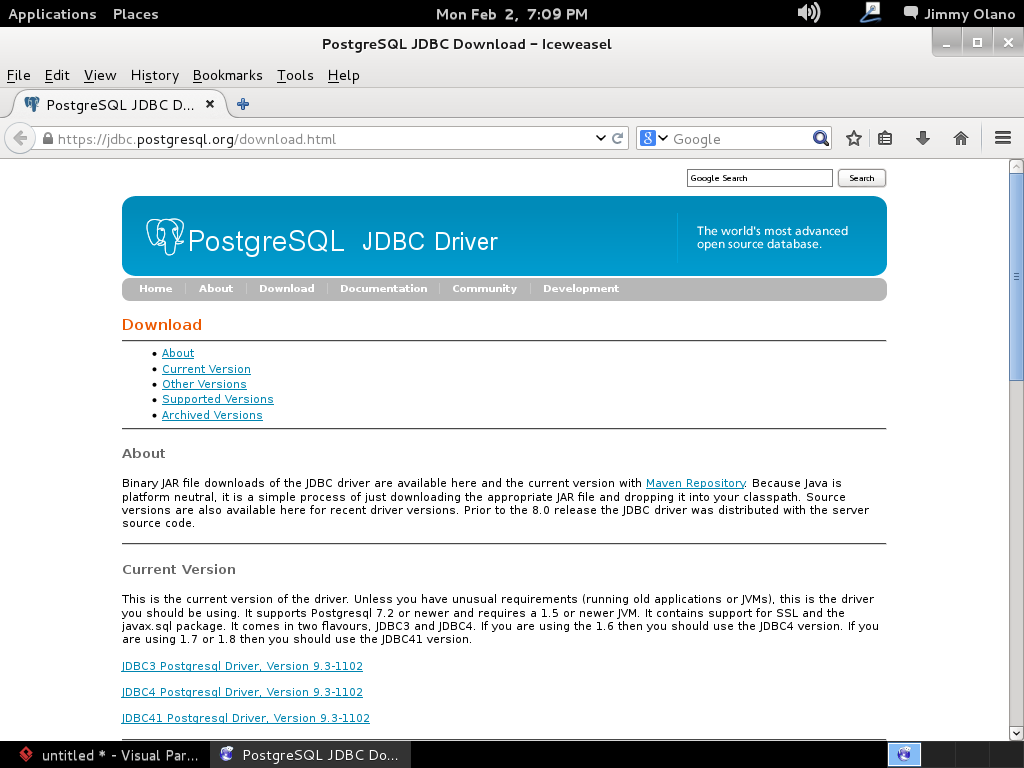
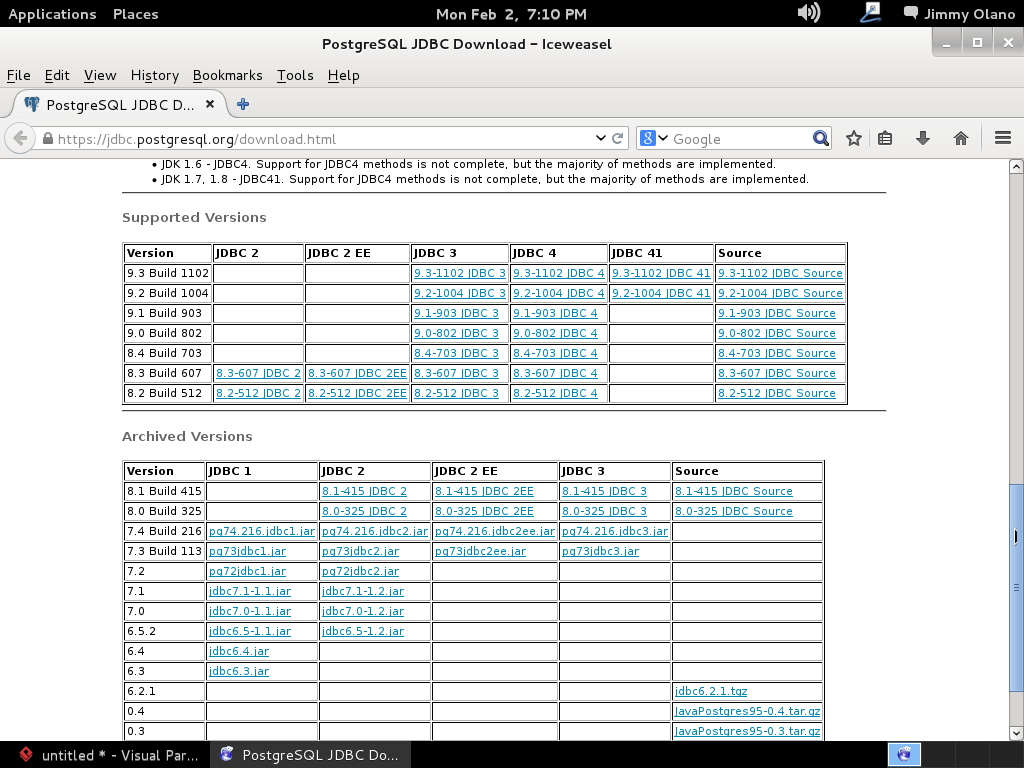 procedemos a descargar el identificado como «postgresql-9.1-903.jdbc4.jar» (observen que para cada versión de PostgreSQL hay su correspondiente controlador, sean cuidadosos al elegir por favor):
procedemos a descargar el identificado como «postgresql-9.1-903.jdbc4.jar» (observen que para cada versión de PostgreSQL hay su correspondiente controlador, sean cuidadosos al elegir por favor):
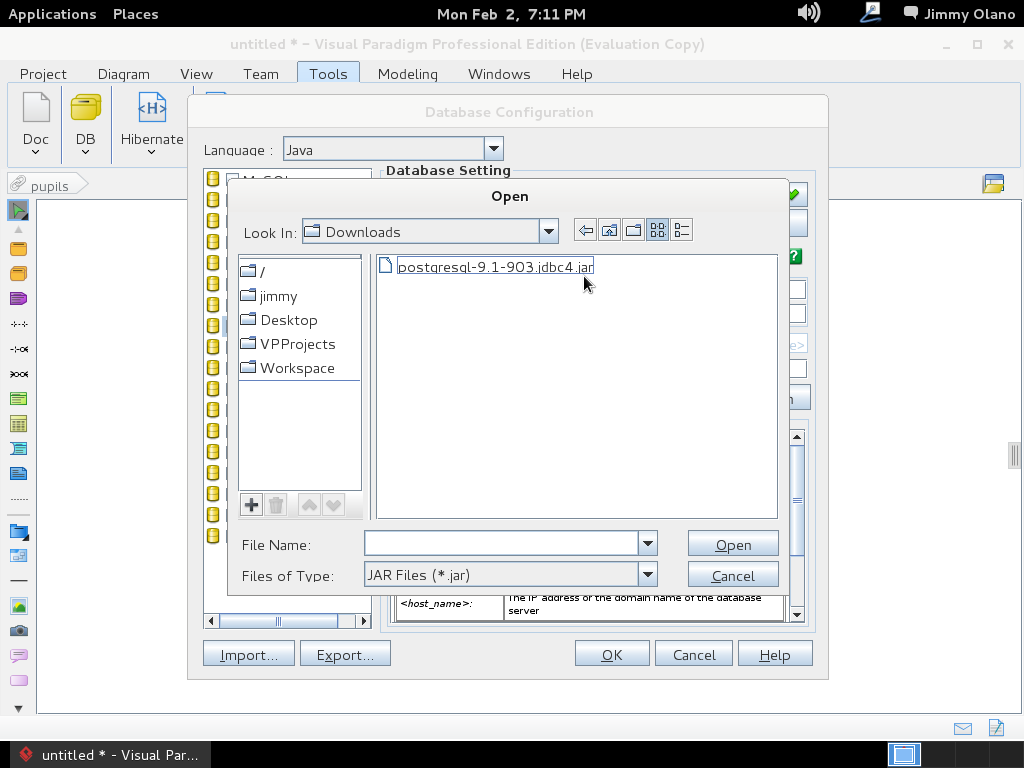
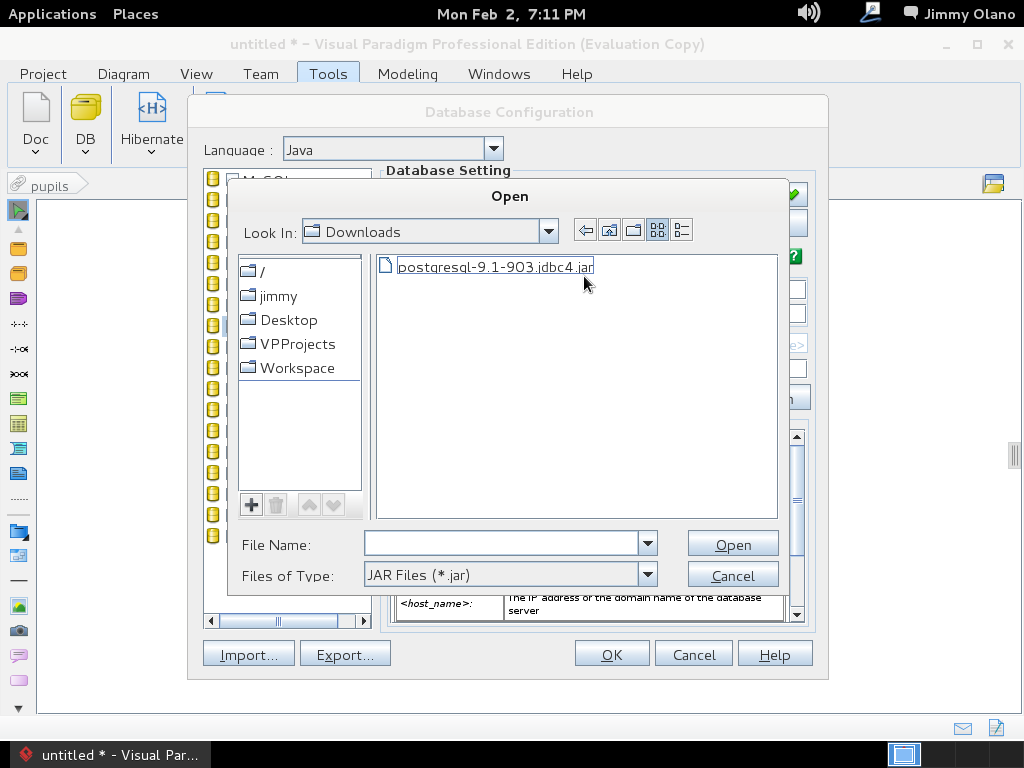 Este último cuadro de diálogo para elegir el controlador aparece al hacer click en el botón que muestra 3 puntitos en la misma línea de «Driver file». Al clickear en «Open» procedemos a llenar el resto de los valores que configuramos en las dos entradas anteriores, que en un papelito debemos haber anotado y puesto al alcance de la mano para ganar tiempo:
Este último cuadro de diálogo para elegir el controlador aparece al hacer click en el botón que muestra 3 puntitos en la misma línea de «Driver file». Al clickear en «Open» procedemos a llenar el resto de los valores que configuramos en las dos entradas anteriores, que en un papelito debemos haber anotado y puesto al alcance de la mano para ganar tiempo:
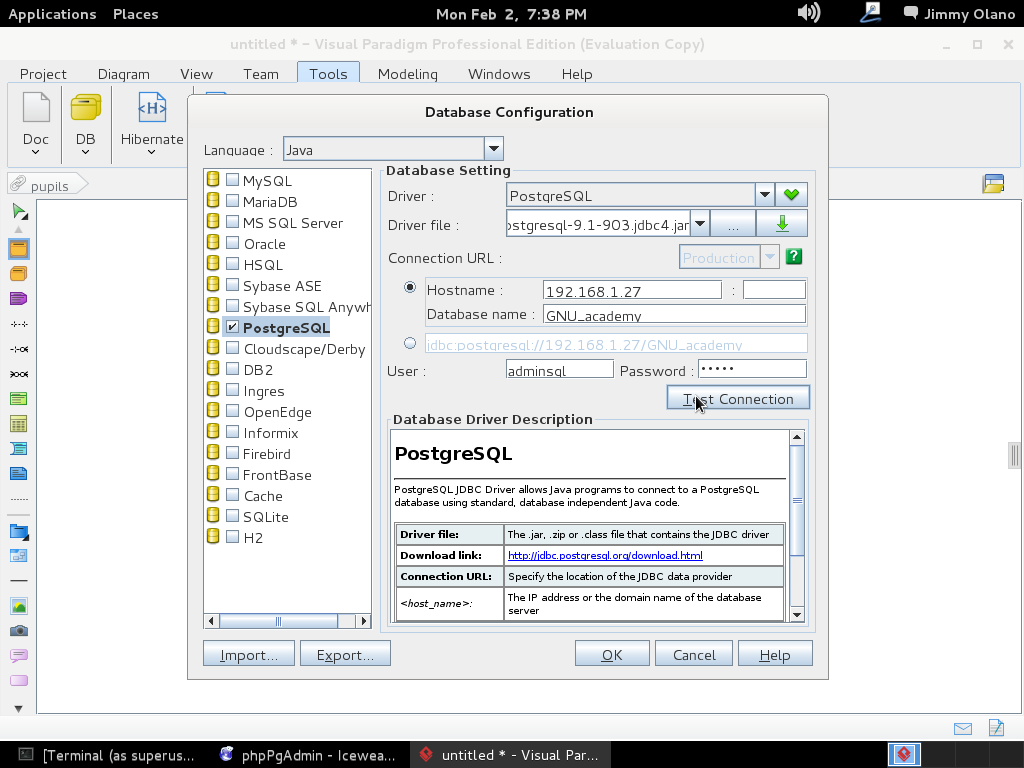
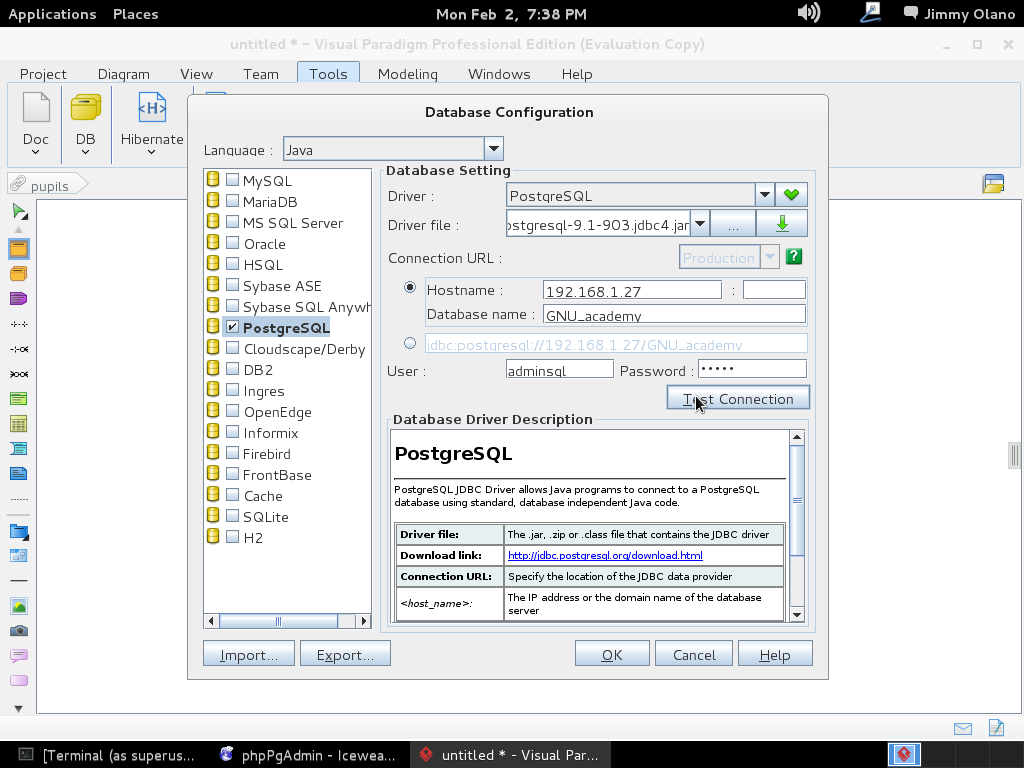
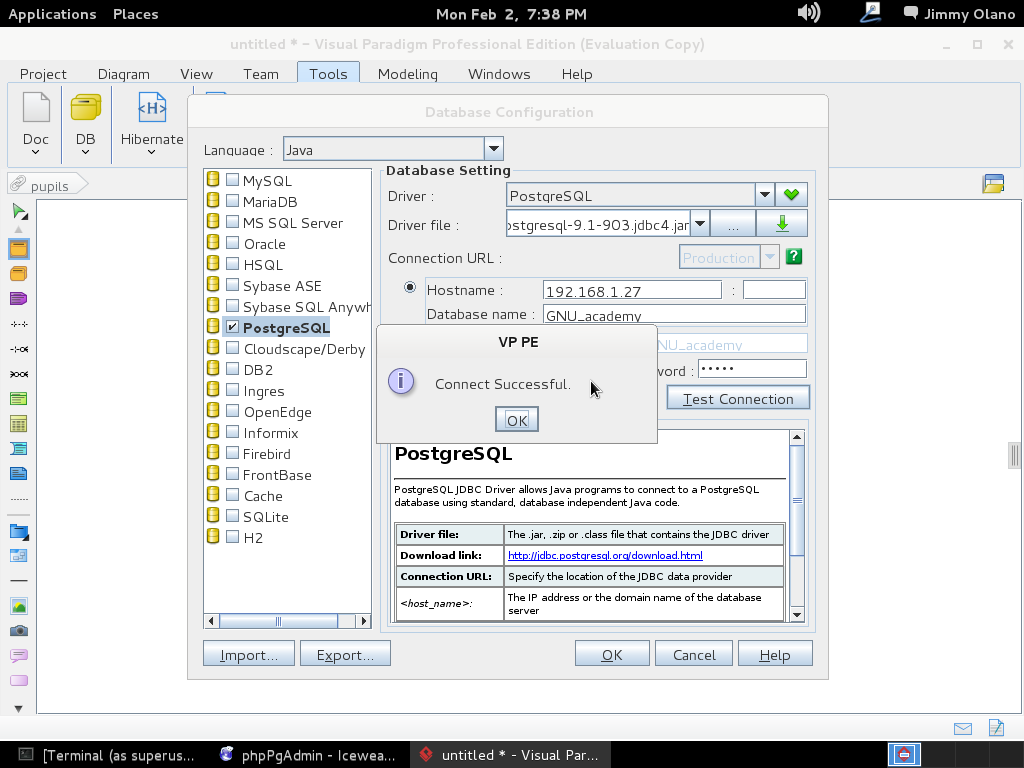
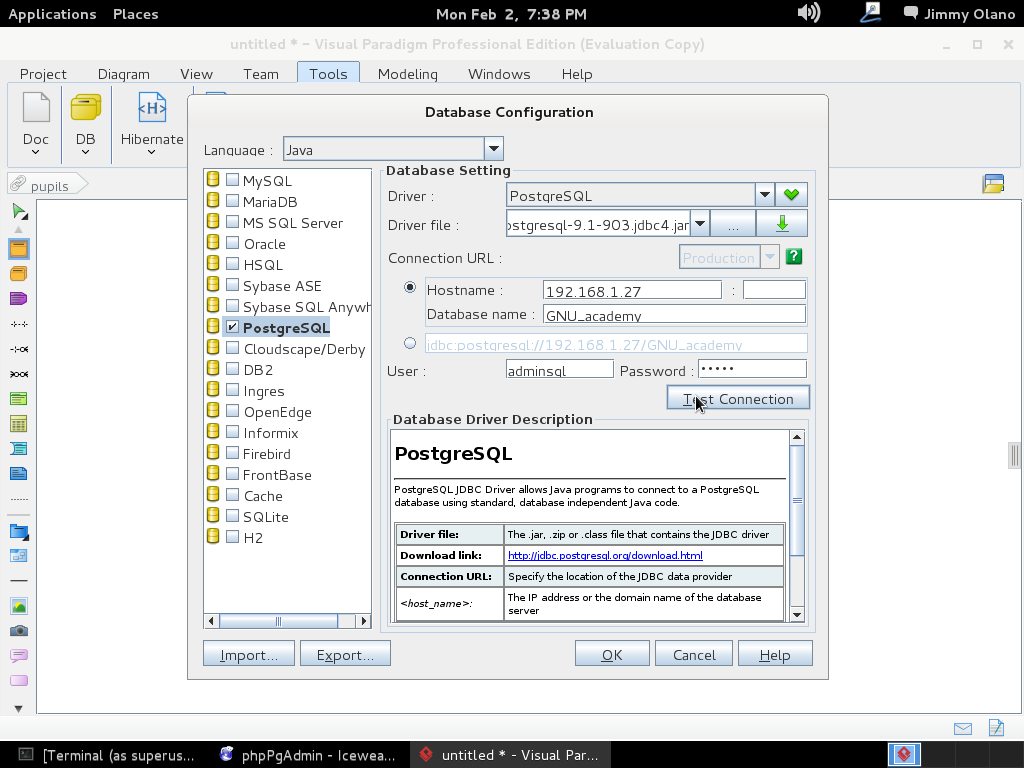 Luego hacemos click en «Test Connection» y si hemos realizado bien nuestro trabajo veremos algo como esto:
Luego hacemos click en «Test Connection» y si hemos realizado bien nuestro trabajo veremos algo como esto:
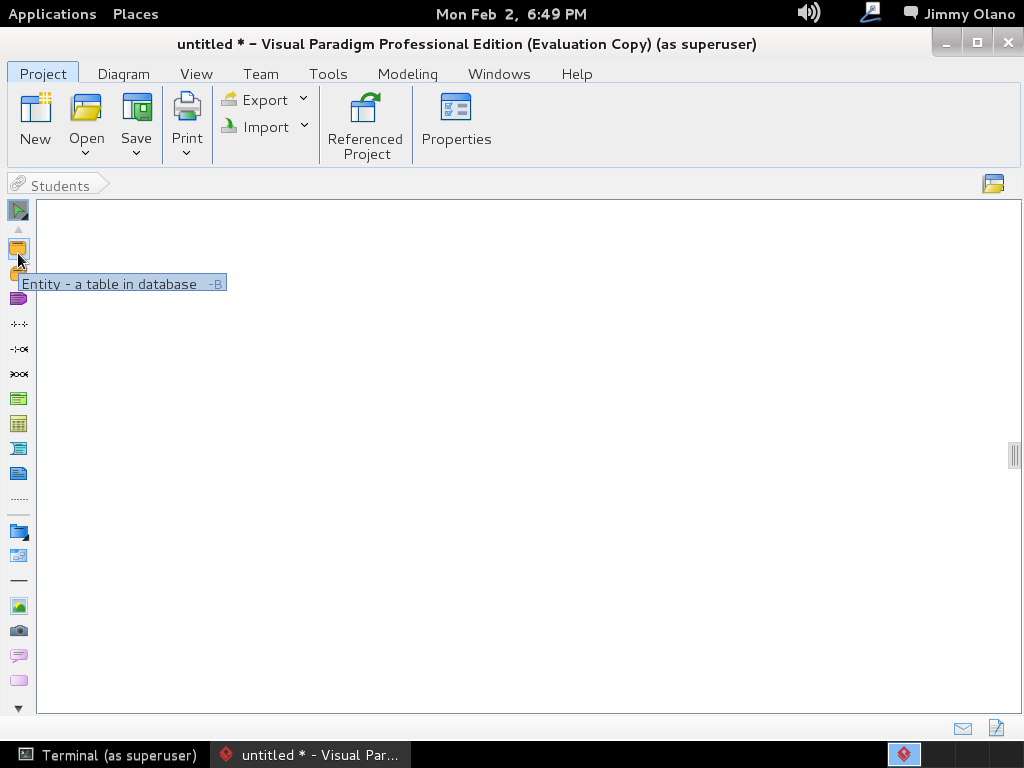
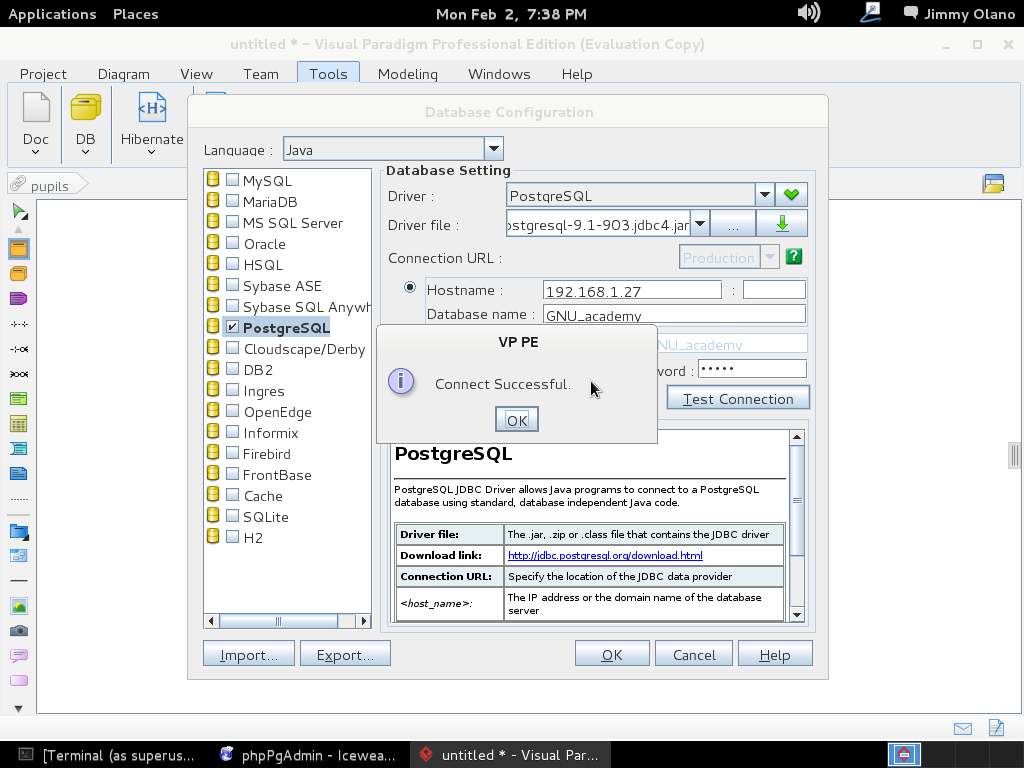 Le damos click a «OK» para entonces agregar la primera futura tabla al hacer click en «Entity -a table-» en el icono que se ve en la siguiente imagen (me disculpan el errorcito de nombre de proyecto, si se fijan) y acto seguido «dibujamos» un rectángulo con tamaño a nuestra apetencia en el área de trabajo:
Le damos click a «OK» para entonces agregar la primera futura tabla al hacer click en «Entity -a table-» en el icono que se ve en la siguiente imagen (me disculpan el errorcito de nombre de proyecto, si se fijan) y acto seguido «dibujamos» un rectángulo con tamaño a nuestra apetencia en el área de trabajo:
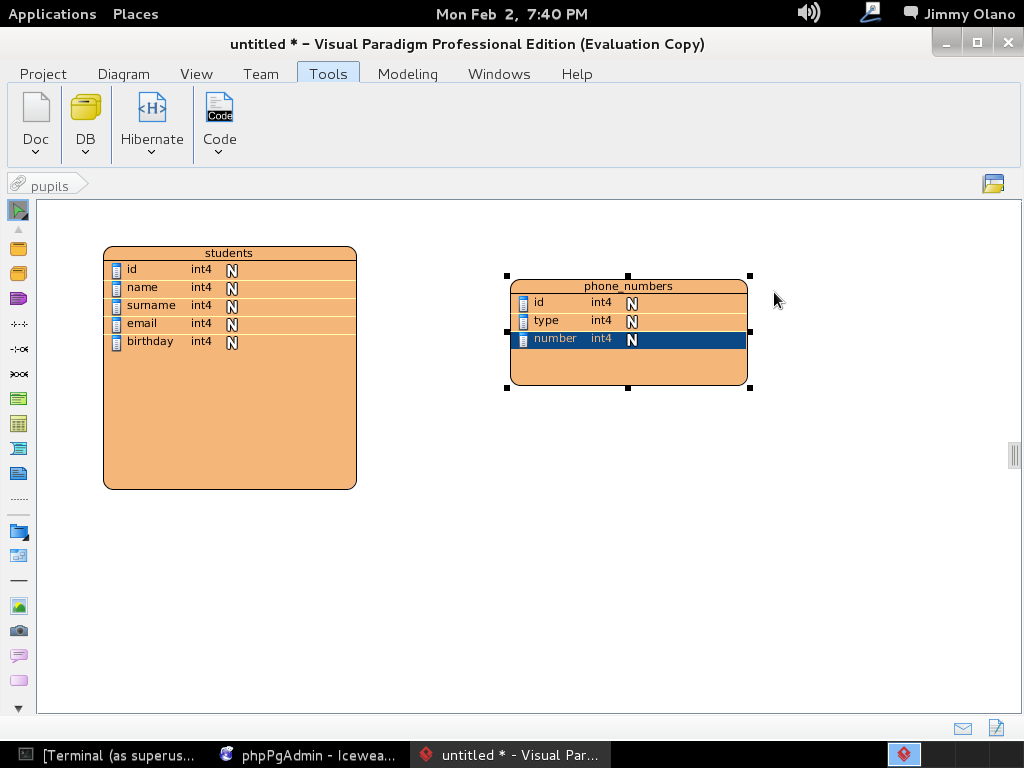
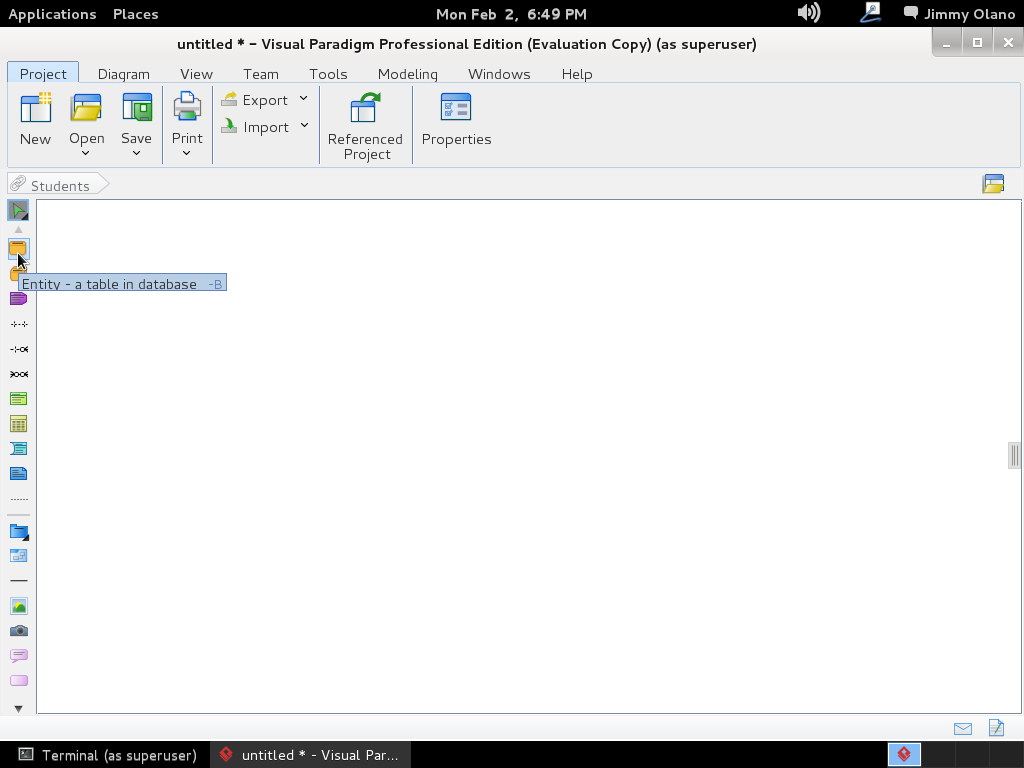 Lo que viene a continuacón es largo de describir en palabras, pero como decimos en farmacia «hágase según arte» y siendo así manipulamos dicho objeto colocandole los nombres siguientes (no se preocupen, más adelante especificaremos los tipos de datos):
Lo que viene a continuacón es largo de describir en palabras, pero como decimos en farmacia «hágase según arte» y siendo así manipulamos dicho objeto colocandole los nombres siguientes (no se preocupen, más adelante especificaremos los tipos de datos):
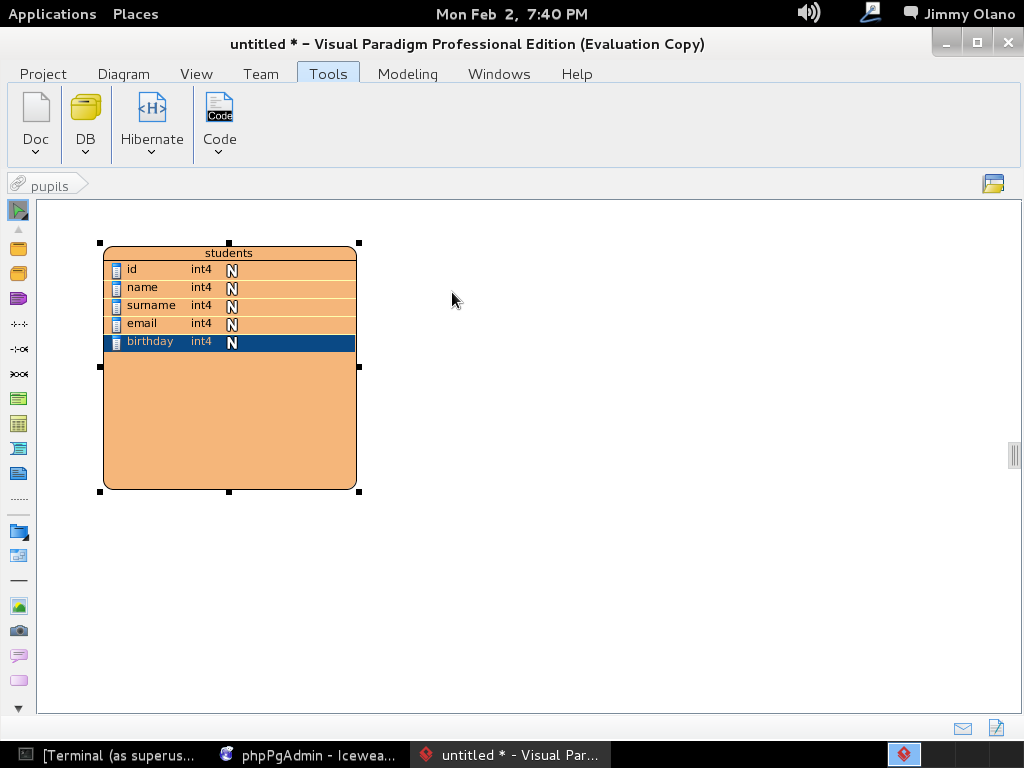
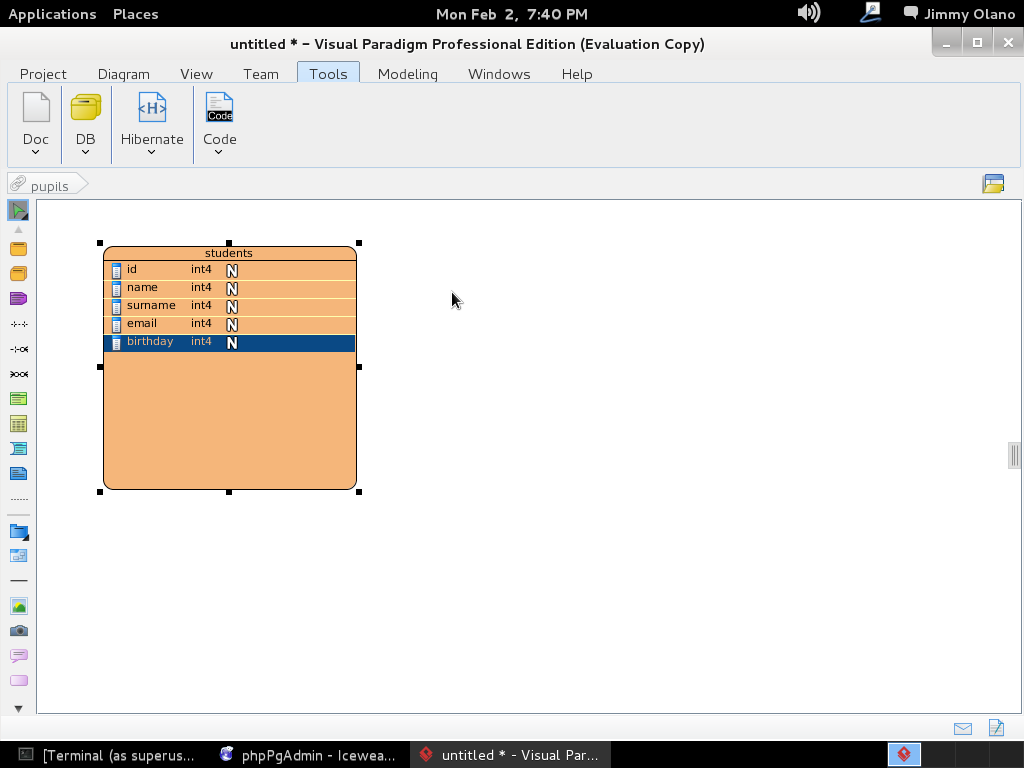 Tal como lo hicimos, de buenas a primera, los tipos de datos son «integer» de allí la letra «N» gorda rellena de blanco en cada renglón. Repetimos el procedimiento pero esta vez debe quedar de esta manera:
Tal como lo hicimos, de buenas a primera, los tipos de datos son «integer» de allí la letra «N» gorda rellena de blanco en cada renglón. Repetimos el procedimiento pero esta vez debe quedar de esta manera:

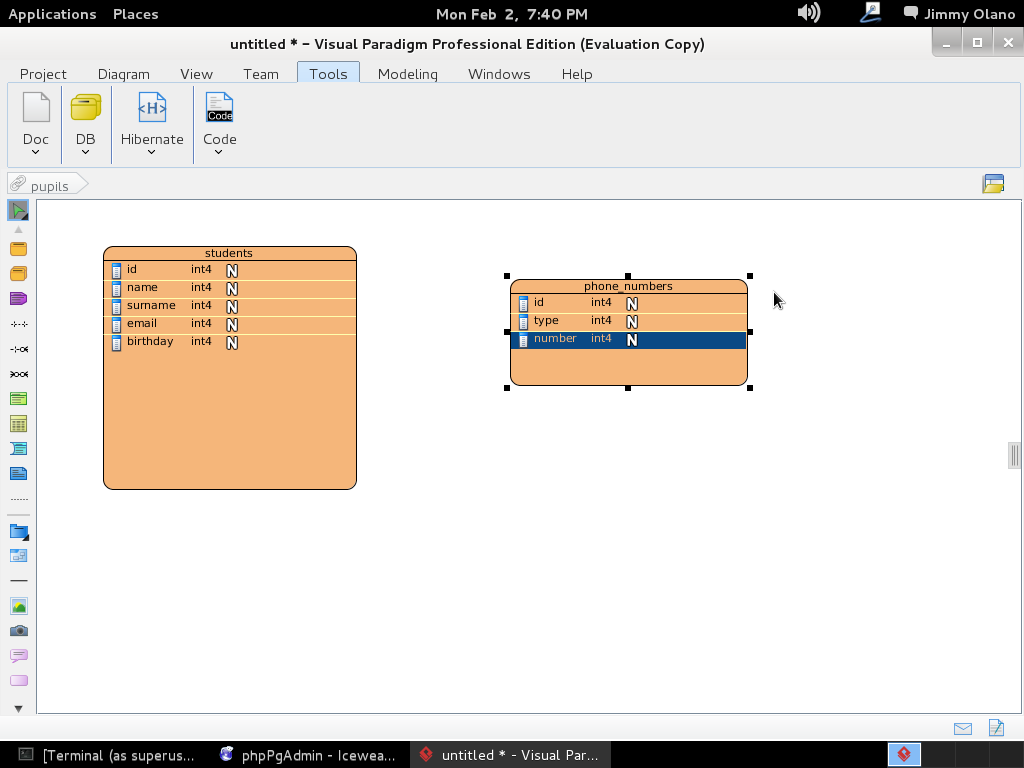
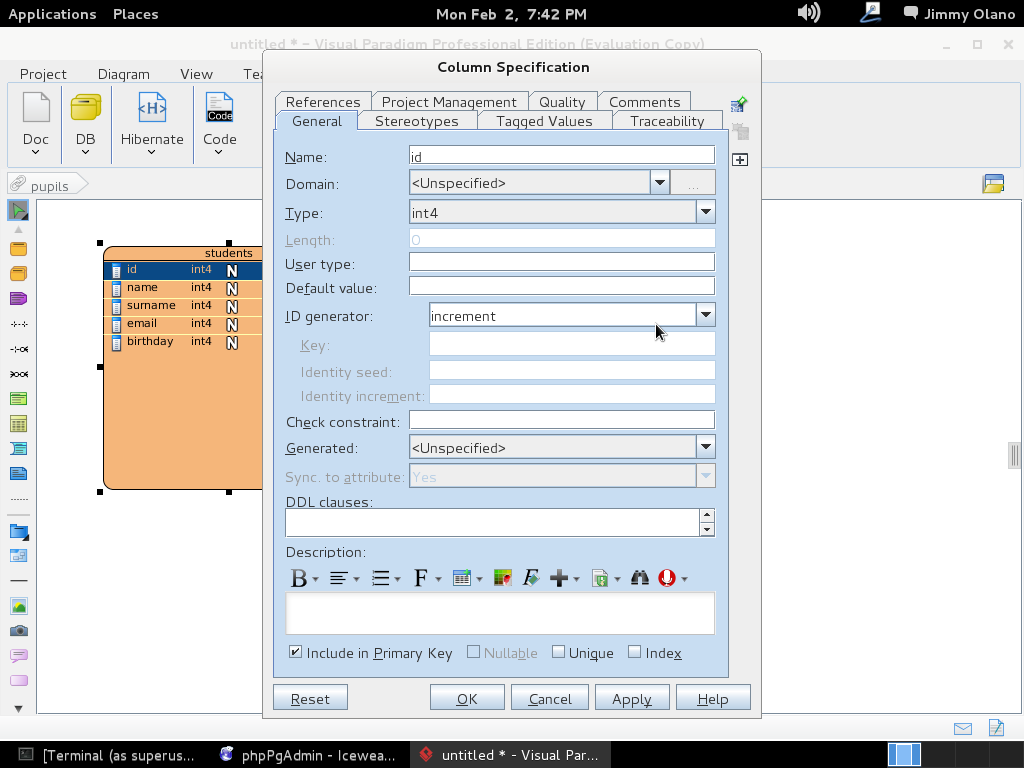
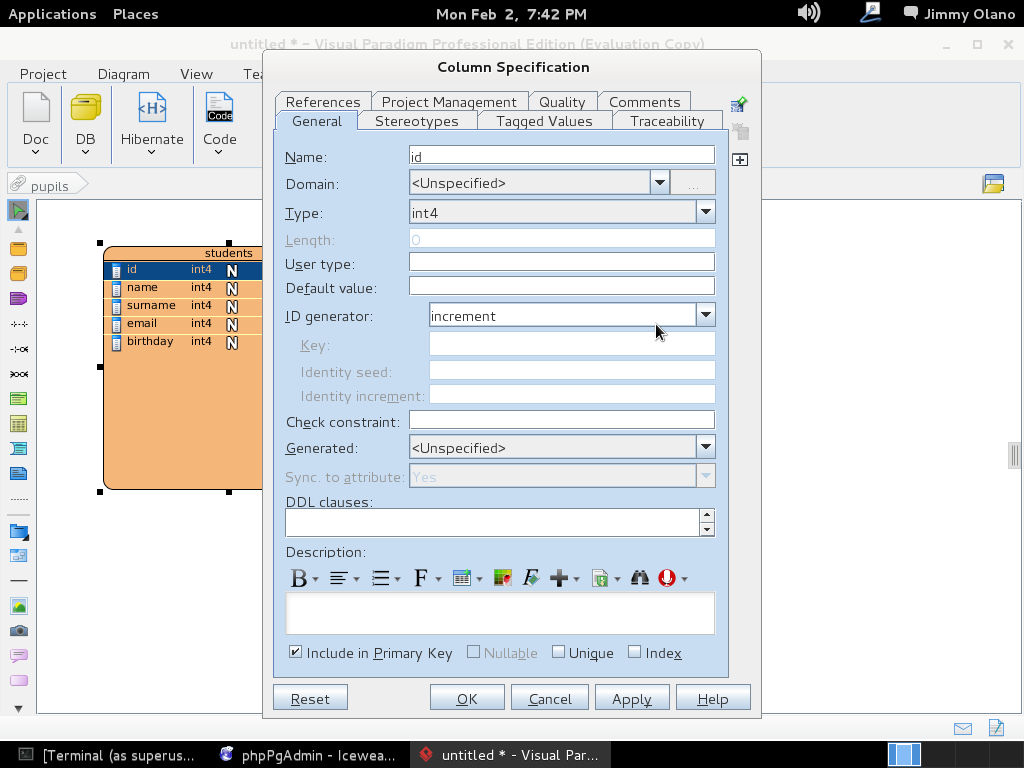
Ahora si hacemos «click derecho» – click con el botón secundario del ratón- para que en el cuadro de diálogo de cada linea (campo de la tabla) nos permita modificarlo; EJEMPLO seleccionamos el «id» de «students» y lo marcamos como «Primary Key» y un «Id Generator-> Increment»:
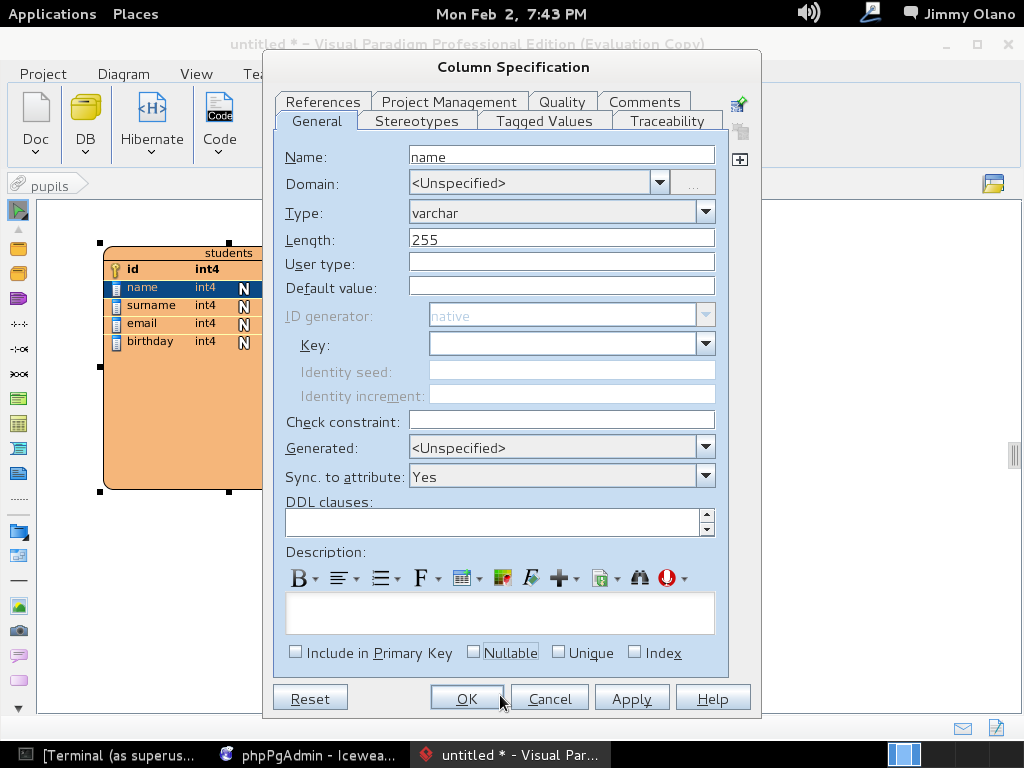
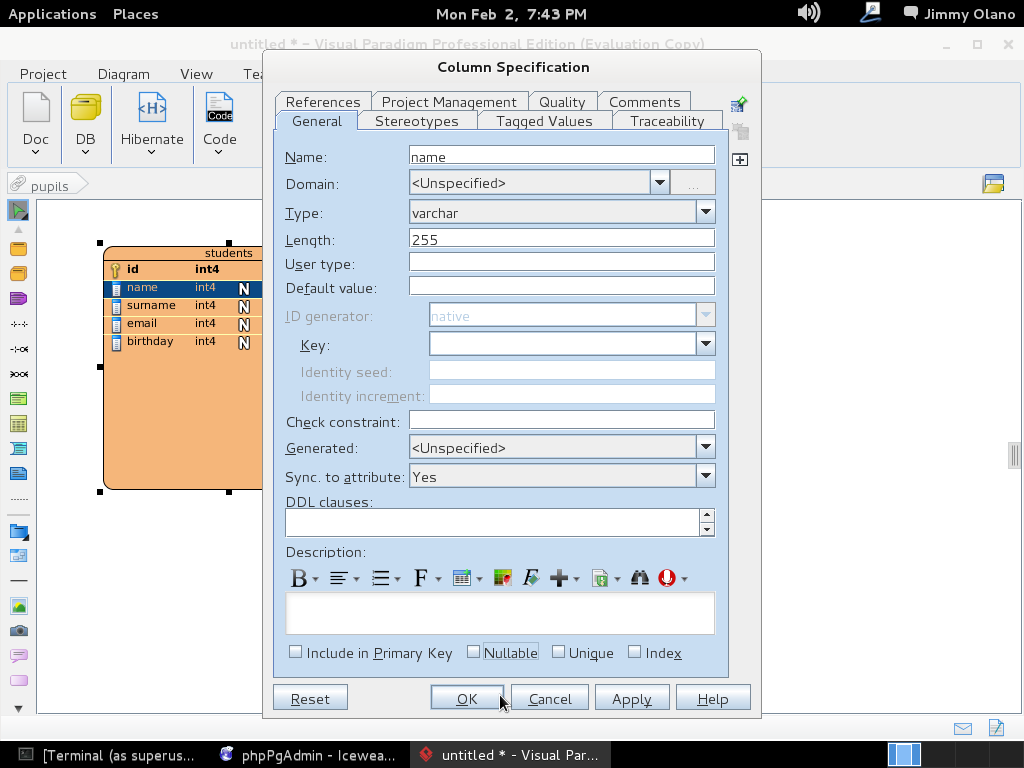
 Hacemos click en «Ok» y repetimos el procedimiento para el campo «name» PERO lo colocamos para que sea tipo «varchar» (cadena de texto) y acepte hasta 255 letras -toda una exageración- pero vuelvo a repetir «con propósitos didácticos»:
Hacemos click en «Ok» y repetimos el procedimiento para el campo «name» PERO lo colocamos para que sea tipo «varchar» (cadena de texto) y acepte hasta 255 letras -toda una exageración- pero vuelvo a repetir «con propósitos didácticos»:
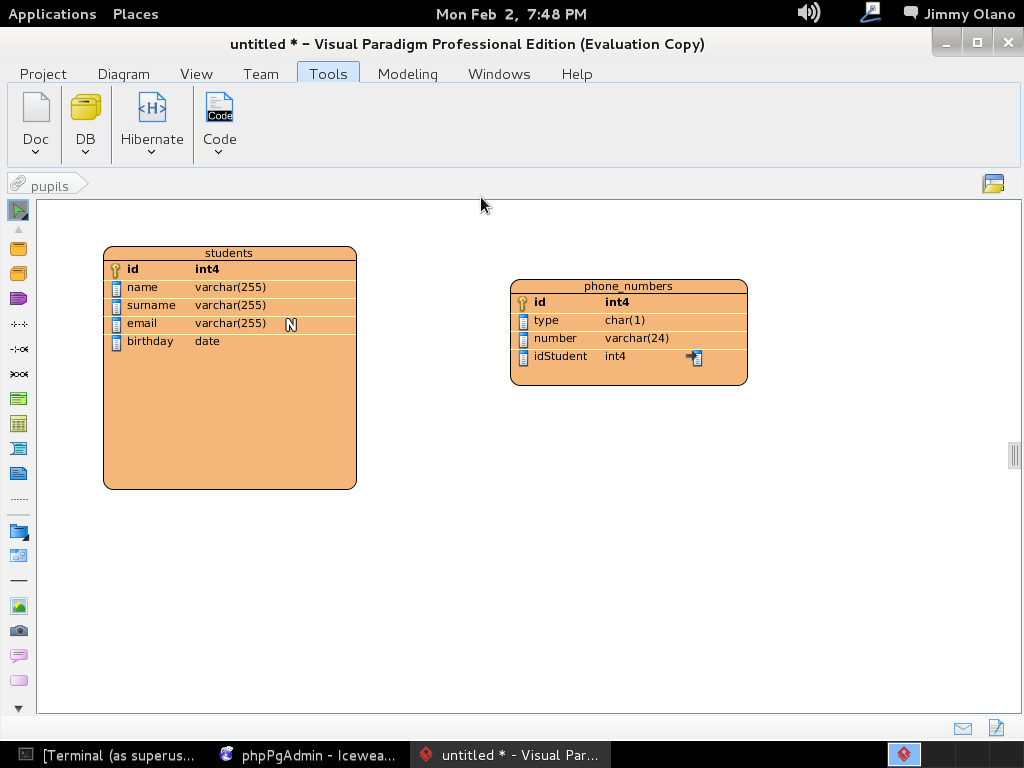
 A la final (TÓMENSE SU TIEMPO) las dos tablas han de quedar de la siguiente manera:
A la final (TÓMENSE SU TIEMPO) las dos tablas han de quedar de la siguiente manera:
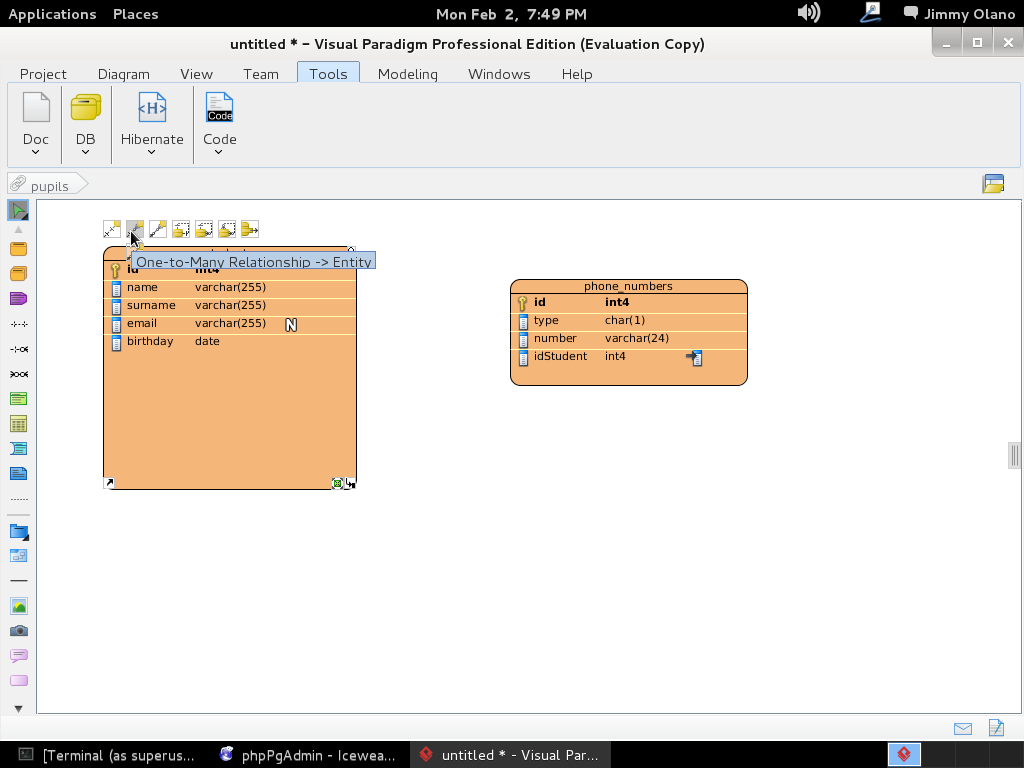
 Luego procedemos a simplemente hacer click sobre la tabla «students» y al mover el puntero del ratón hacia el borde superior aprecerá rápidamente unos iconos con descripción rápida de uso para cada uno de ellos:
Luego procedemos a simplemente hacer click sobre la tabla «students» y al mover el puntero del ratón hacia el borde superior aprecerá rápidamente unos iconos con descripción rápida de uso para cada uno de ellos:
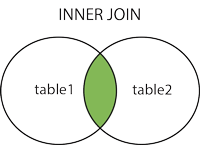
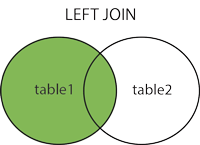
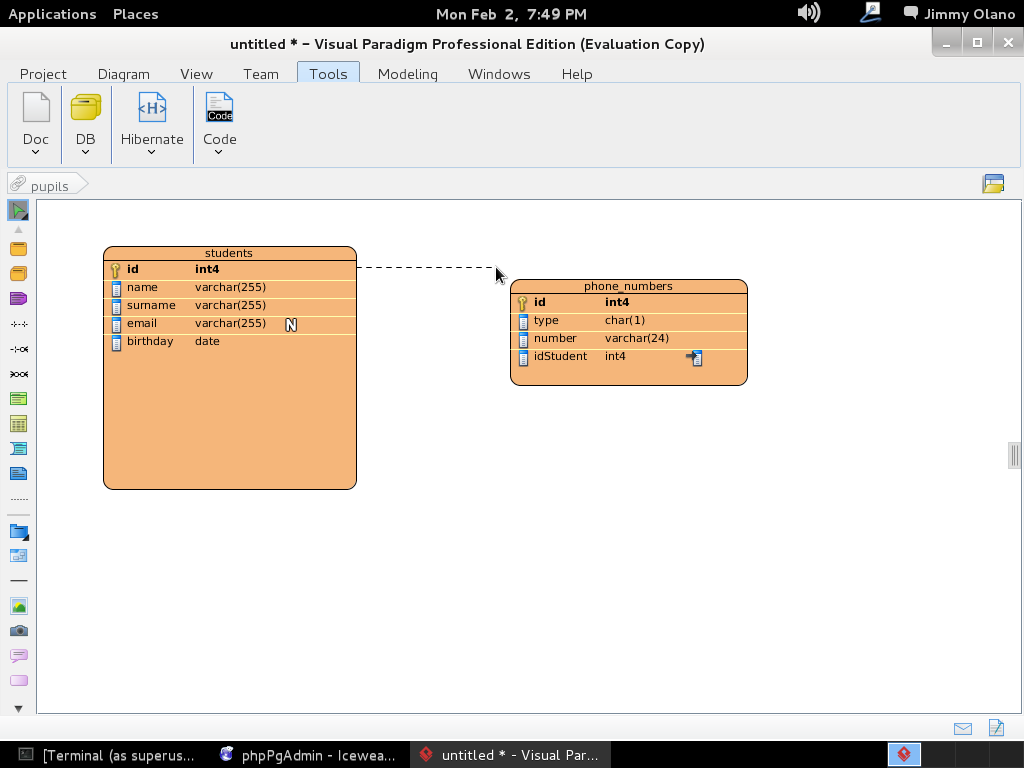
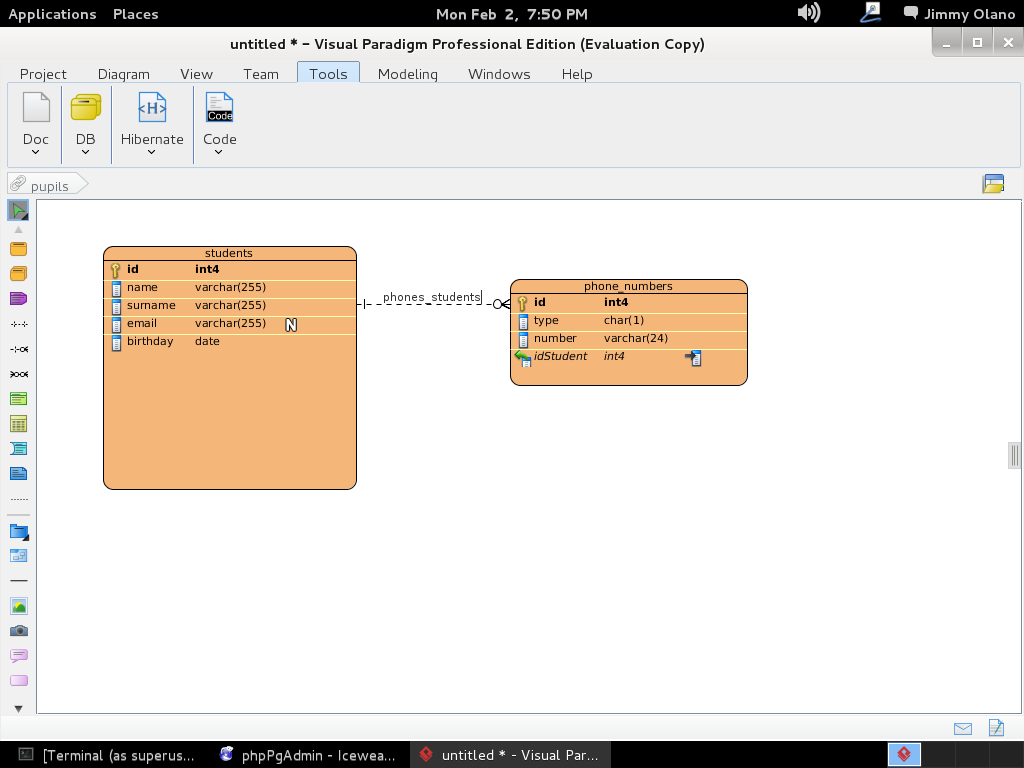
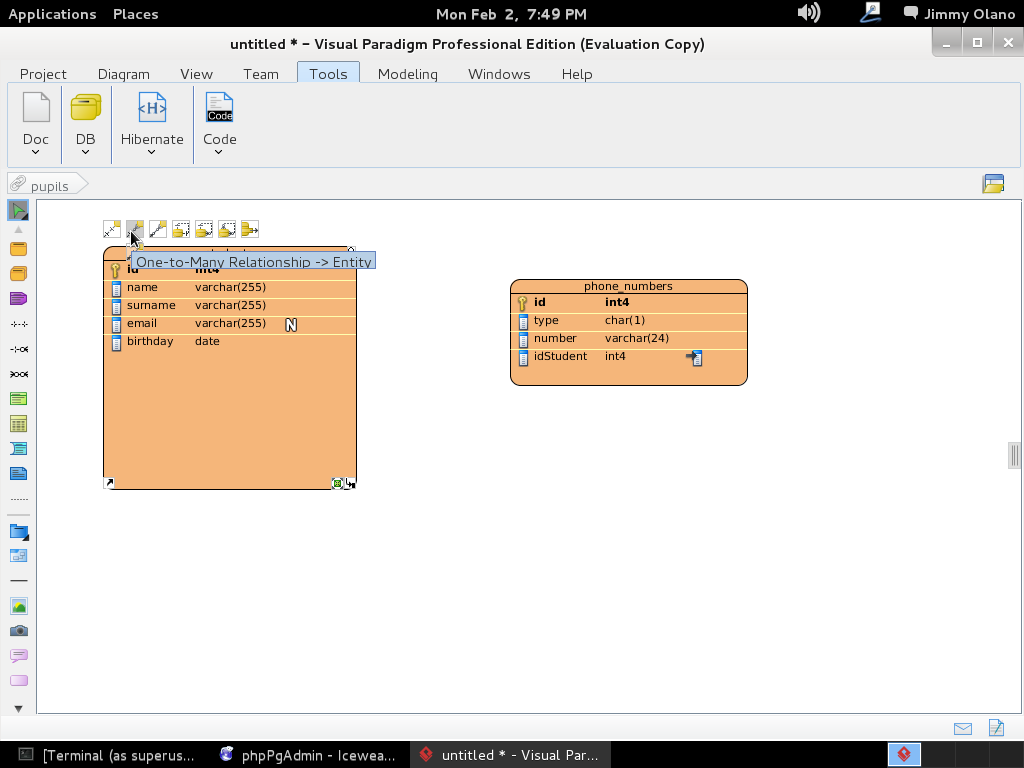 Escogemos «One-to-Many Relationship» (un estudiante puede tener varios números de telefonos distintos -o ninguno-) y arrastramos la línea hasta la tabla «phone_numbers» como aprecian en figura:
Escogemos «One-to-Many Relationship» (un estudiante puede tener varios números de telefonos distintos -o ninguno-) y arrastramos la línea hasta la tabla «phone_numbers» como aprecian en figura:
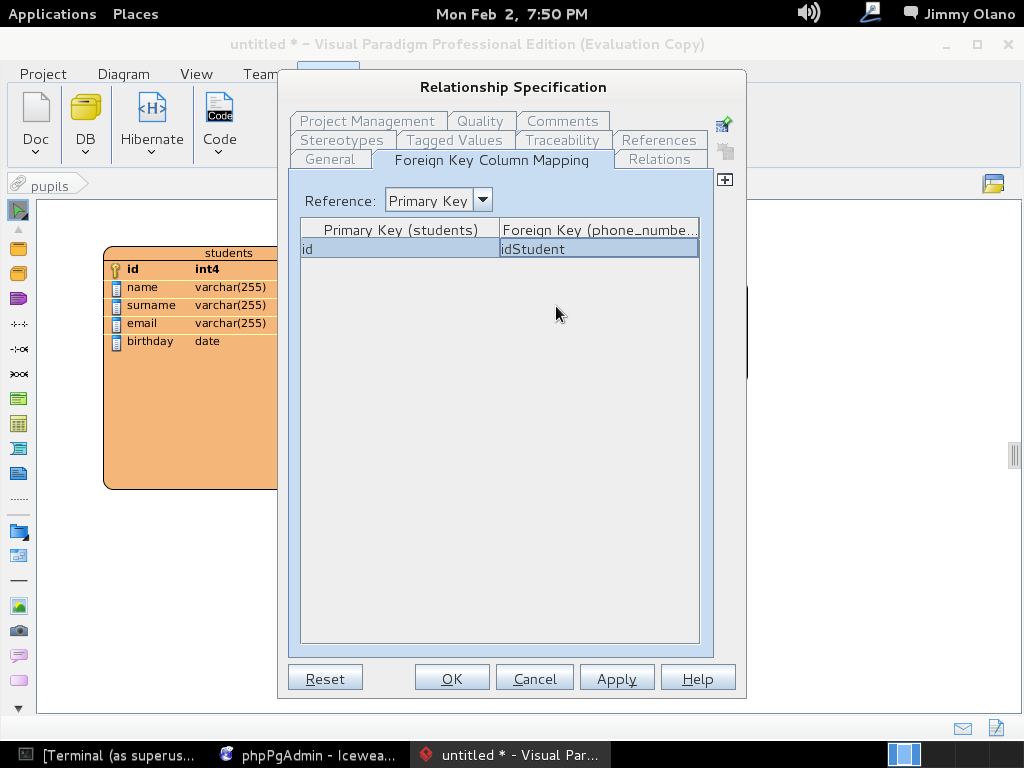
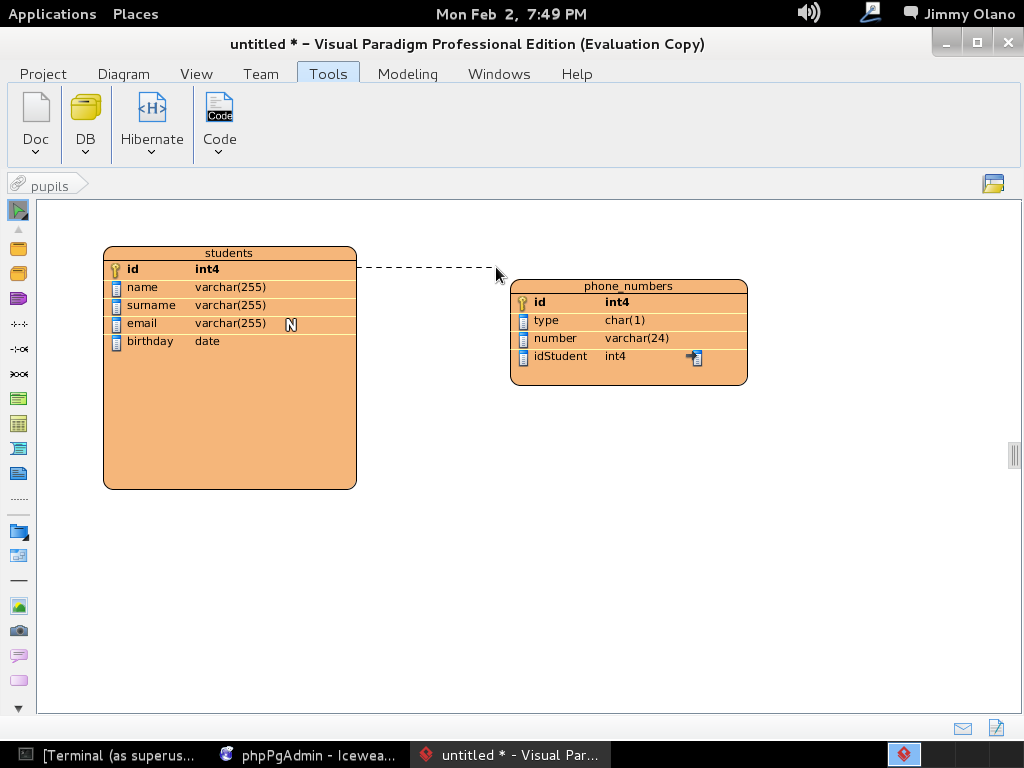 A continuación soltamos y se abre menú para escoger detalladamente la relación que queremos:
A continuación soltamos y se abre menú para escoger detalladamente la relación que queremos:
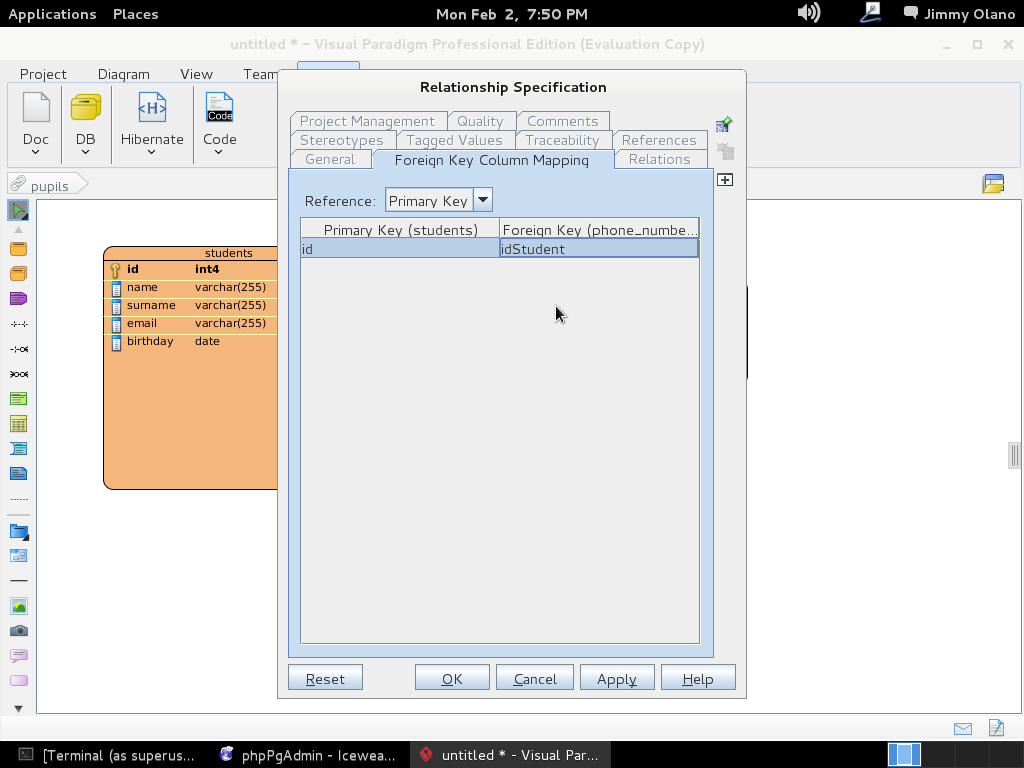
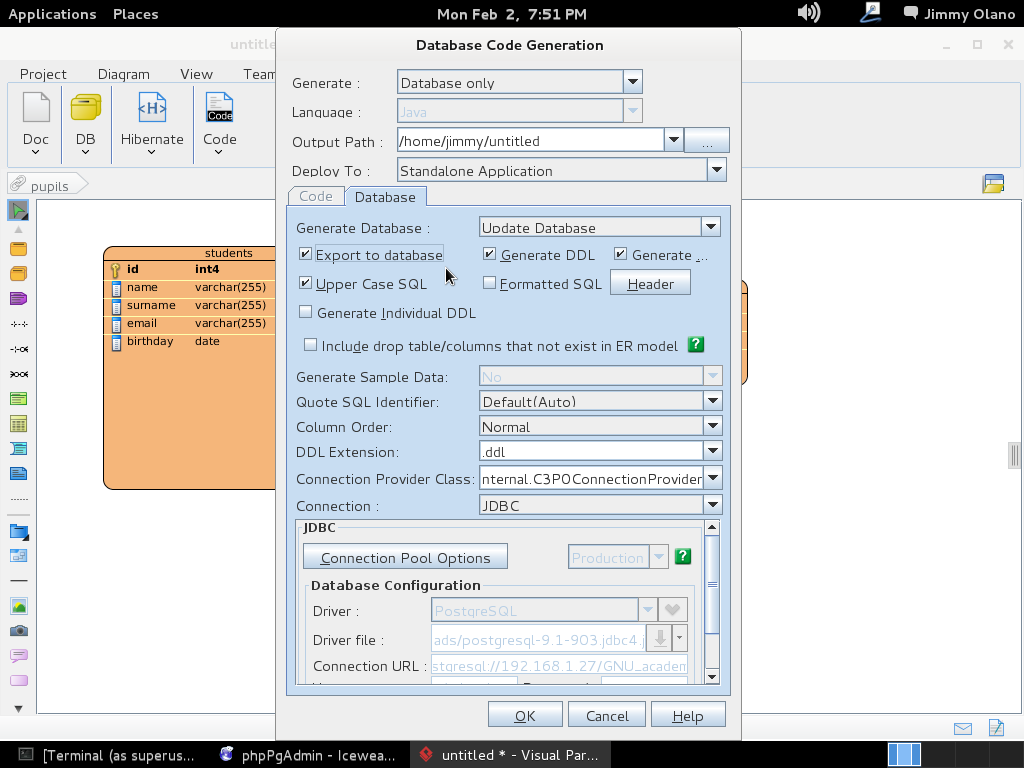
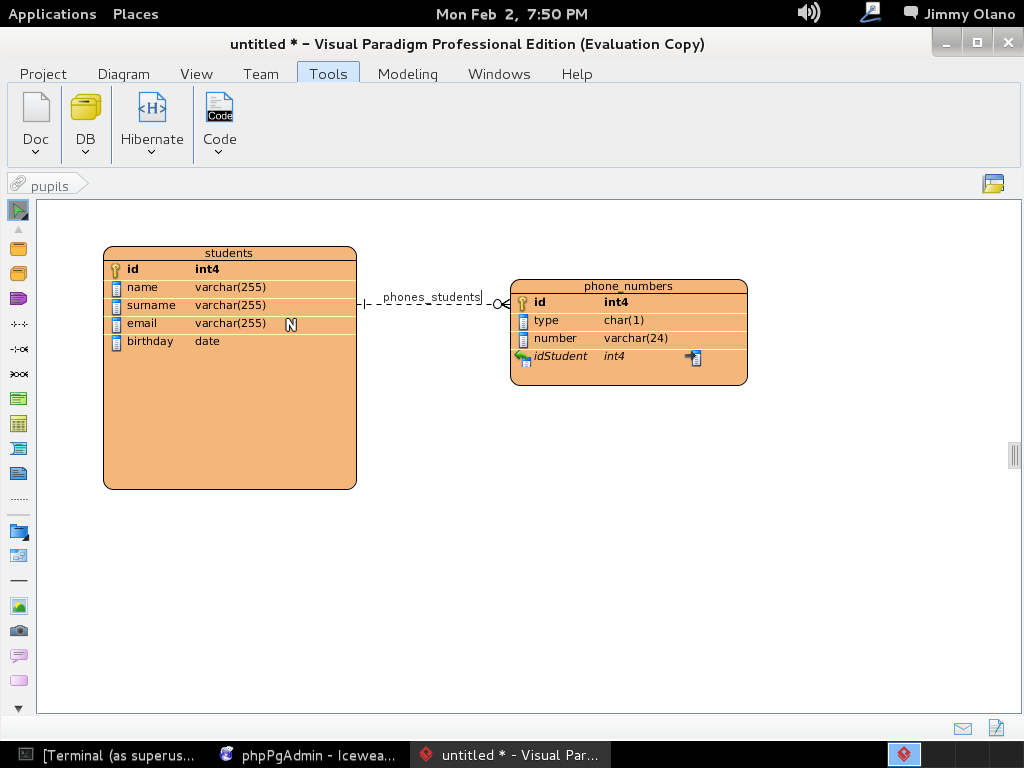 Y listo, ya tenemos definida la estructura de datos, sólo que falta el pequeño detalle de «enviarla» al servidor PostgreSQL, para ello de nuevo nos vamos la pestaña «Tools» y luego en «DB»->»Generate Database» (no se preocupen NO vamos a generar base de datos, aunque se puede hacer ya nosotros la creamos cuando instalamos phpPgAdmin ¿se recuerdan?) sólo es cuestión de seleccionar «Update Database» y marcar «Export to database», observen bien:
Y listo, ya tenemos definida la estructura de datos, sólo que falta el pequeño detalle de «enviarla» al servidor PostgreSQL, para ello de nuevo nos vamos la pestaña «Tools» y luego en «DB»->»Generate Database» (no se preocupen NO vamos a generar base de datos, aunque se puede hacer ya nosotros la creamos cuando instalamos phpPgAdmin ¿se recuerdan?) sólo es cuestión de seleccionar «Update Database» y marcar «Export to database», observen bien:
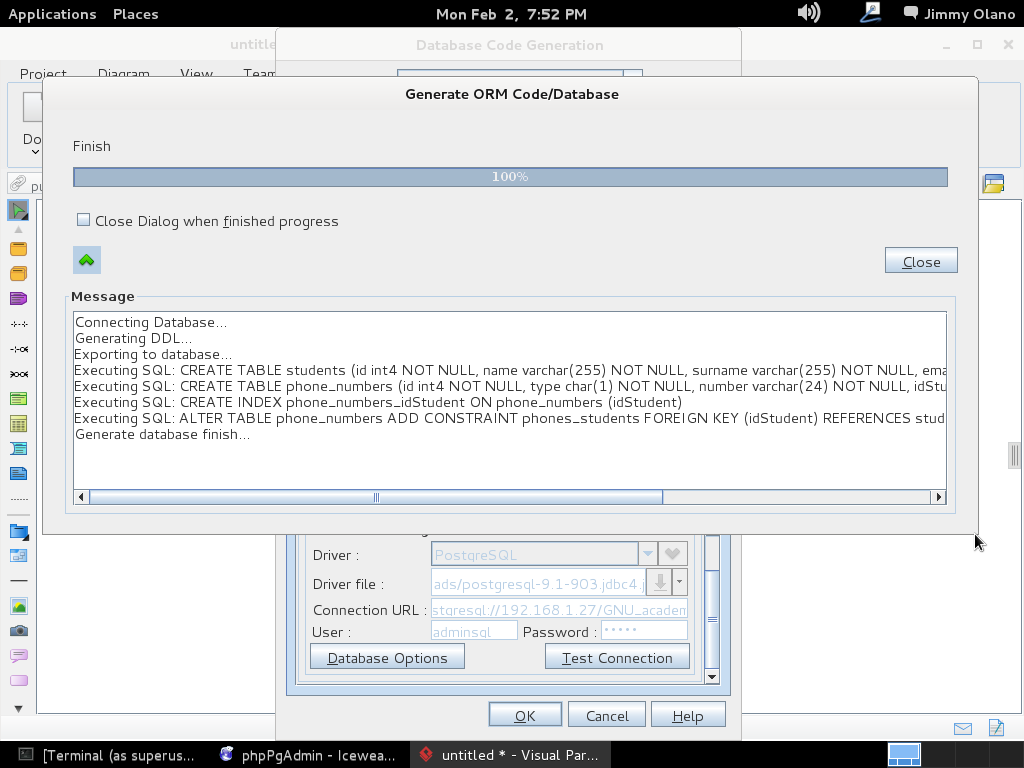
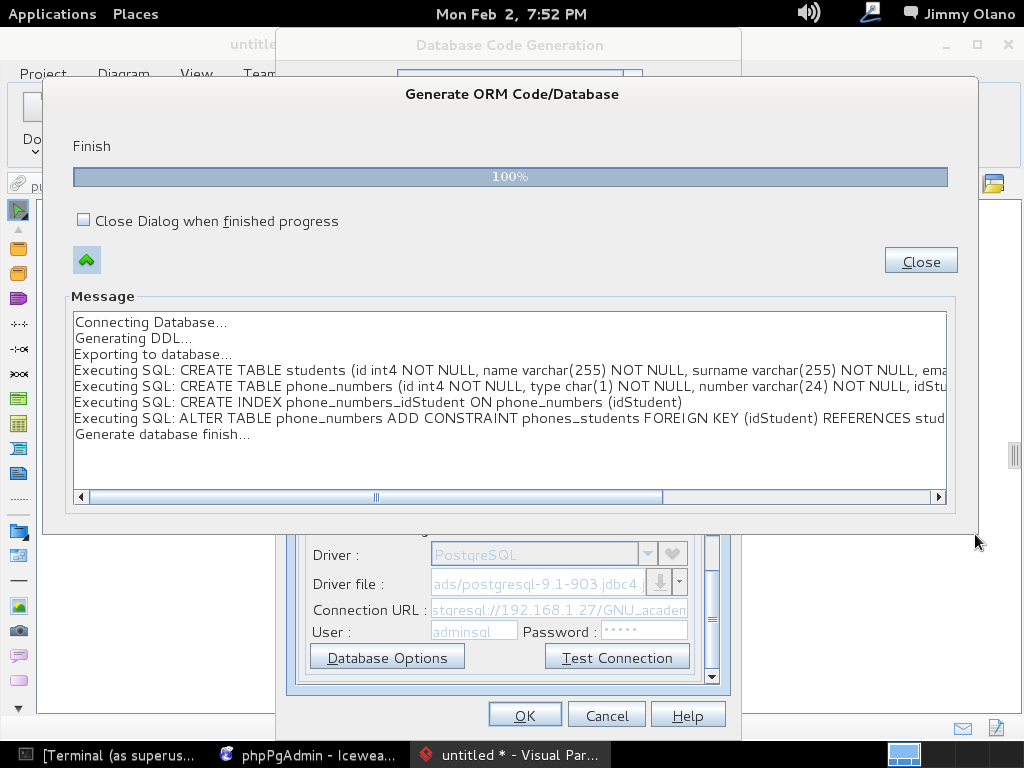
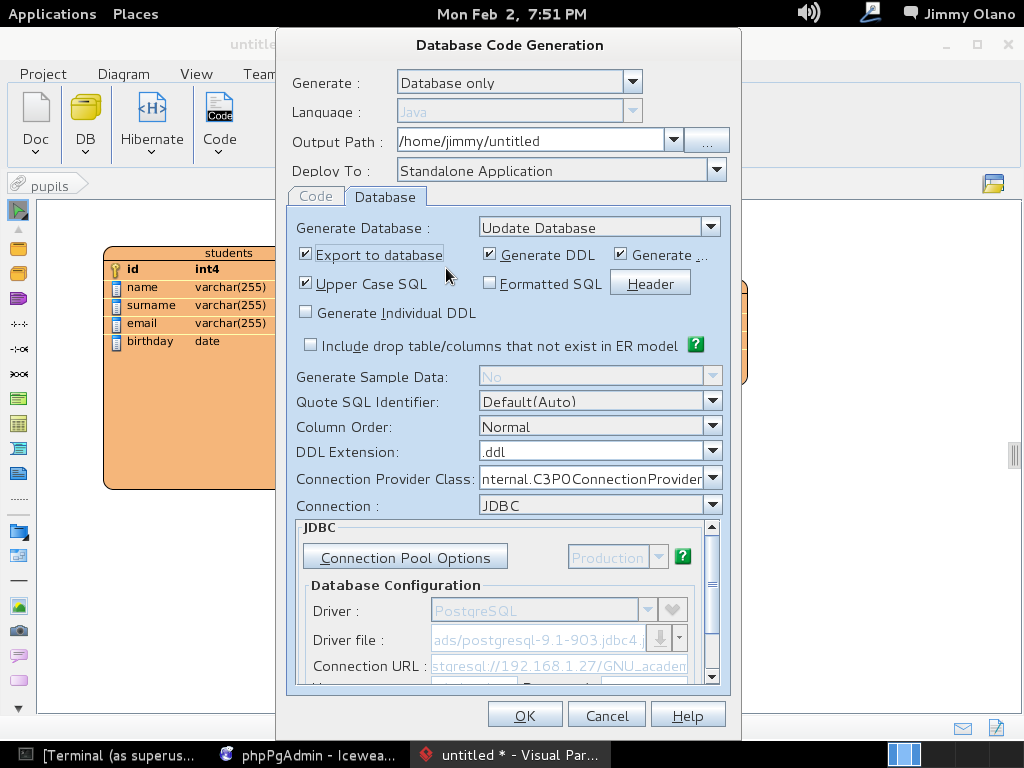 Recordemos que habíamos configurado previamente las propiedades de conexión, una vez pulsado «OK» (y sin seleccionar «Close dialog…») y si ampliamos y ajustamos el tamaño de ventana detallaremos el maravillos trabajo que nos ahorramos (sí, todas esas líneas de comandos que para este ejemplo son pocas pero imagínense que trabajamos en una empresa que manufactura clavos y nos piden hacer una aplicación que lleve el inventario de materia prima y productos terminados… ufff y eso sin meter las ventas, pedidos, despachos, comisiones de vendedores…):
Recordemos que habíamos configurado previamente las propiedades de conexión, una vez pulsado «OK» (y sin seleccionar «Close dialog…») y si ampliamos y ajustamos el tamaño de ventana detallaremos el maravillos trabajo que nos ahorramos (sí, todas esas líneas de comandos que para este ejemplo son pocas pero imagínense que trabajamos en una empresa que manufactura clavos y nos piden hacer una aplicación que lleve el inventario de materia prima y productos terminados… ufff y eso sin meter las ventas, pedidos, despachos, comisiones de vendedores…):
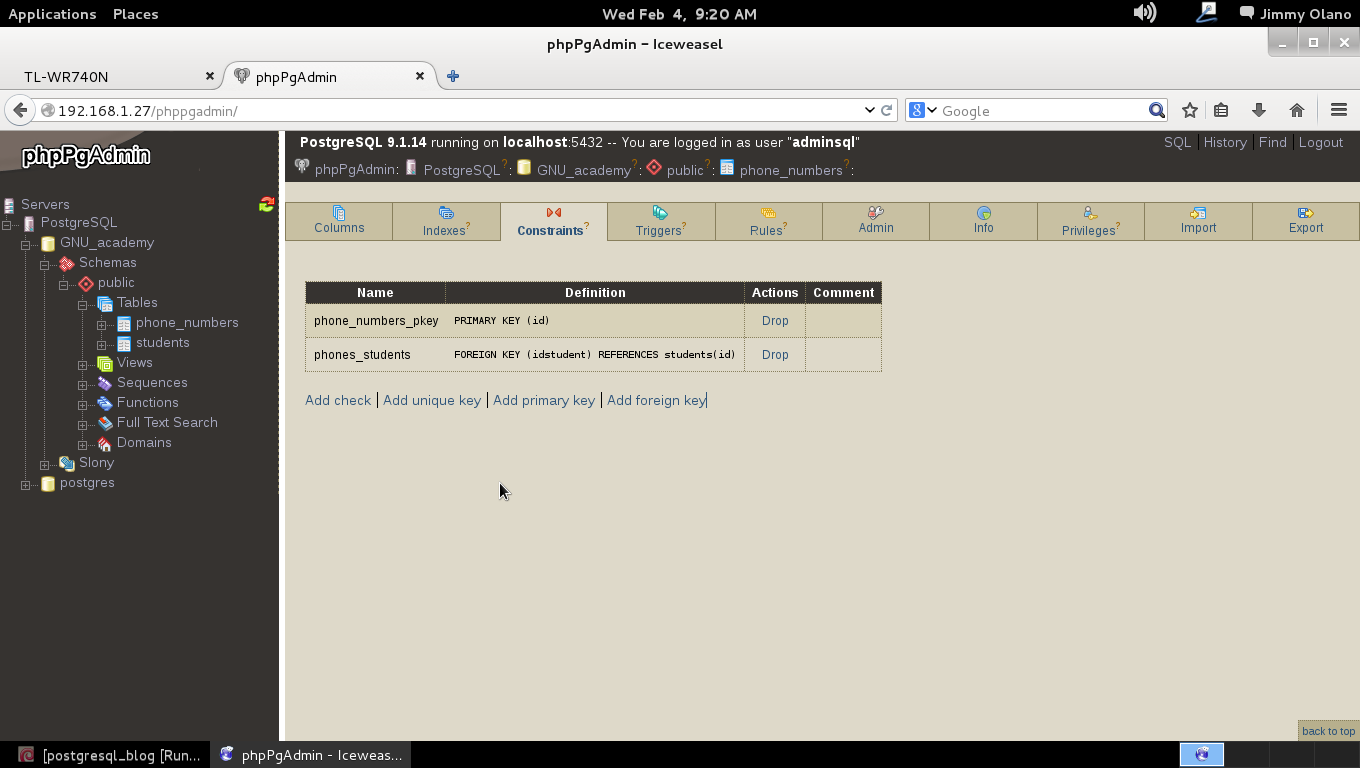
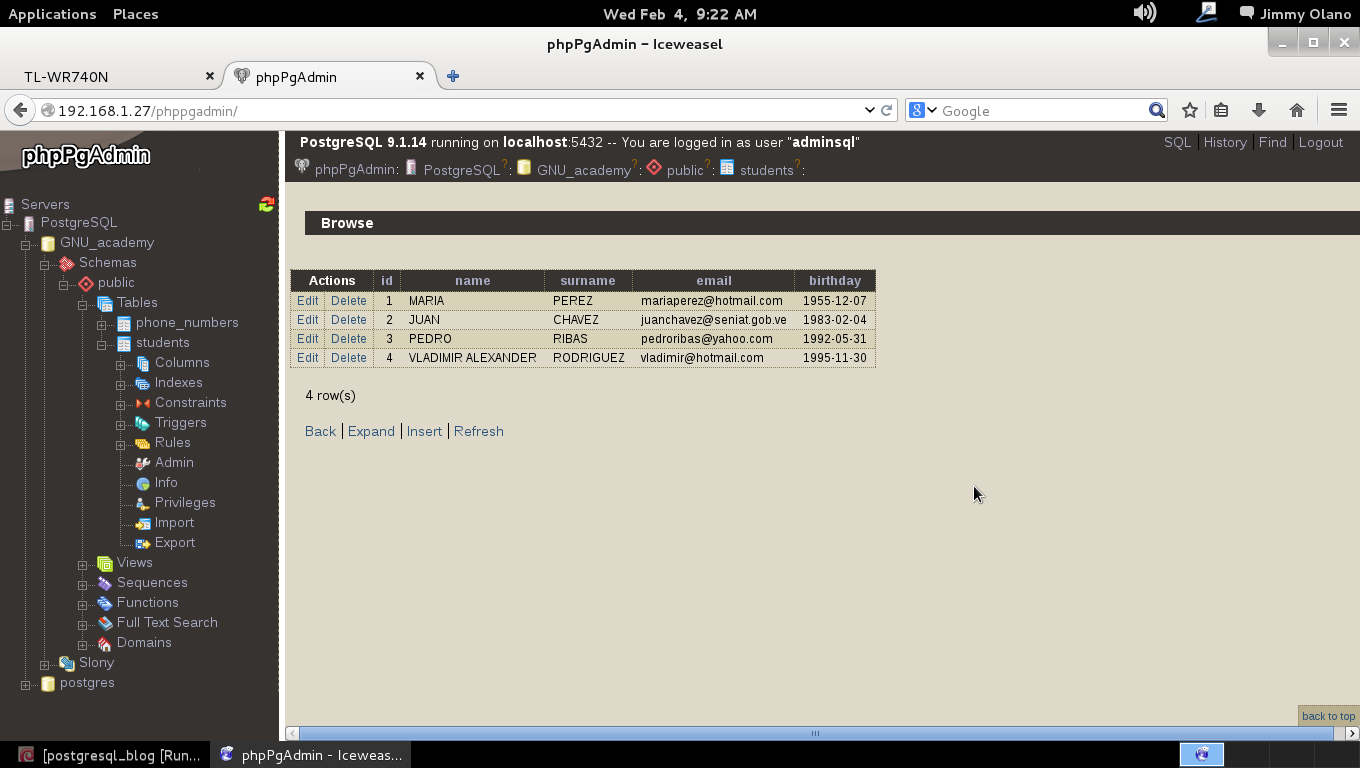
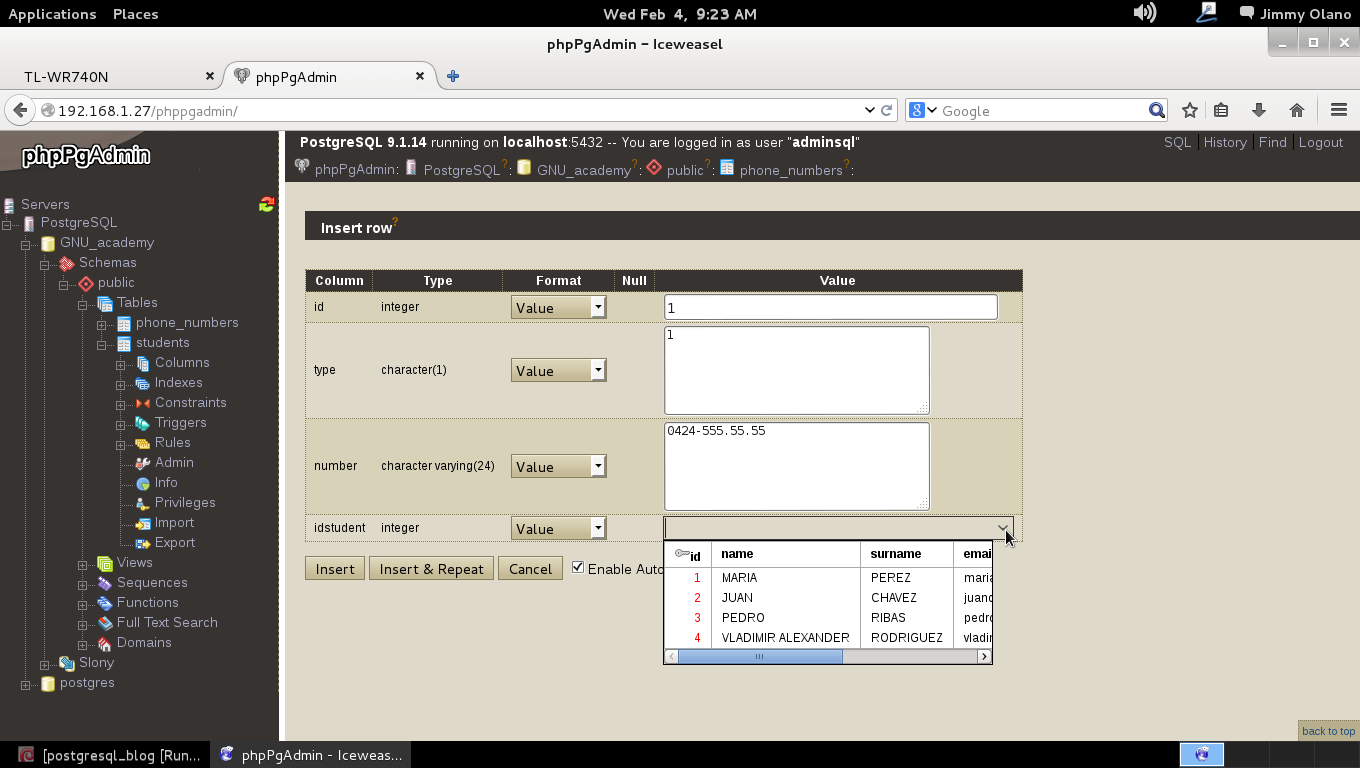
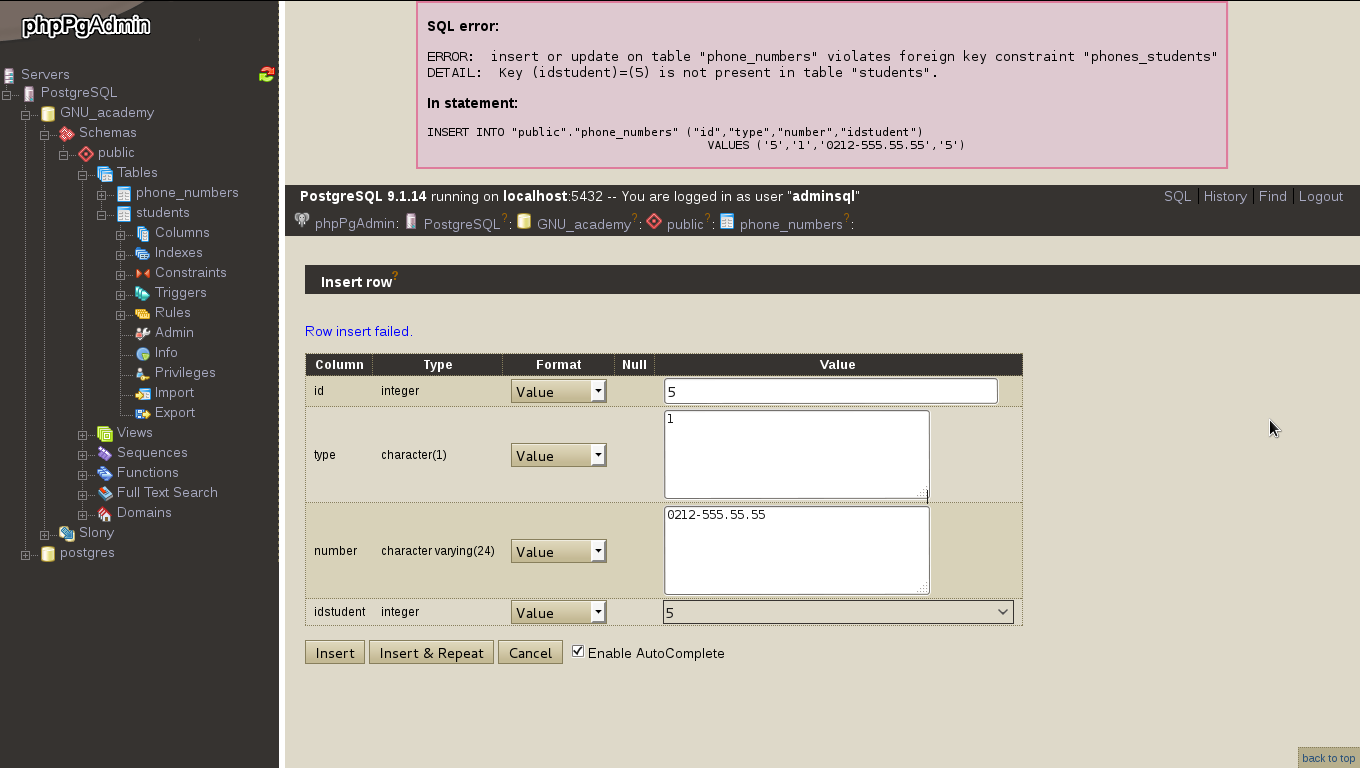
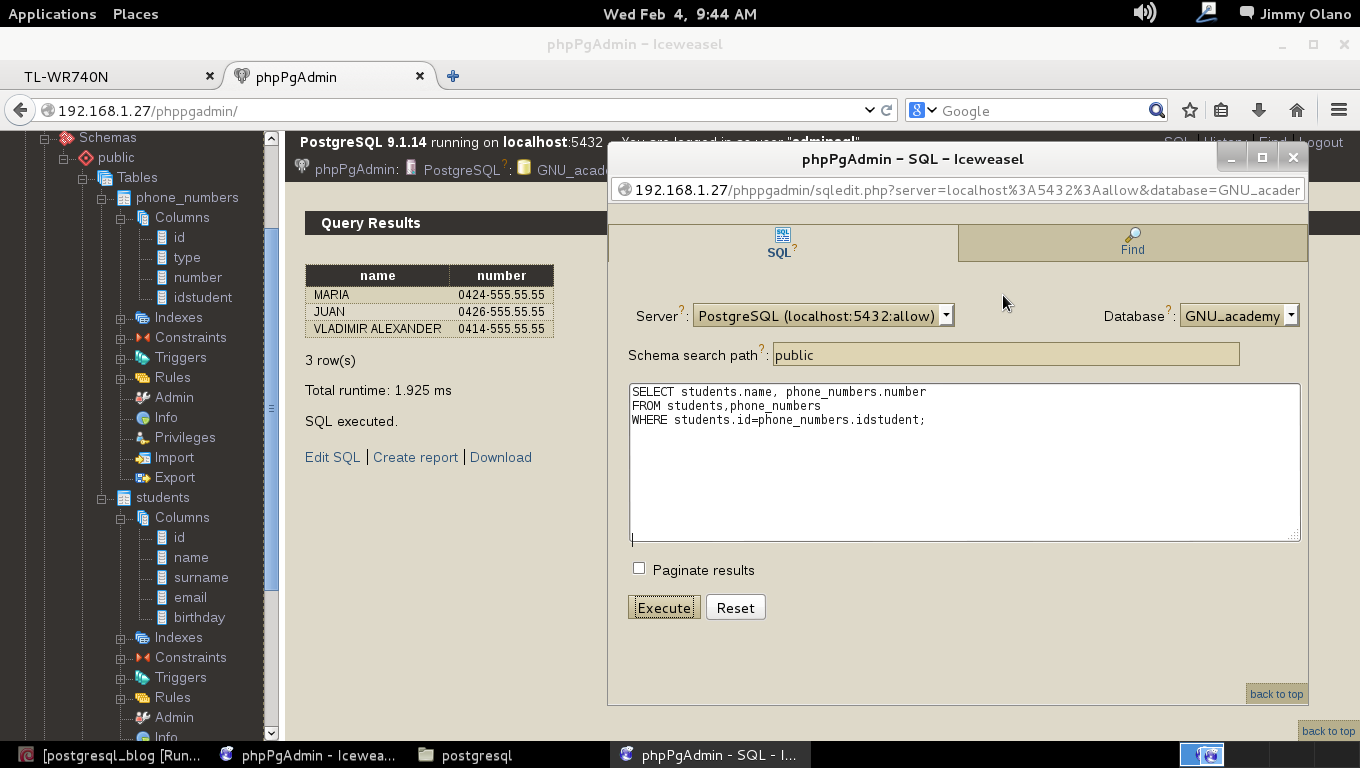
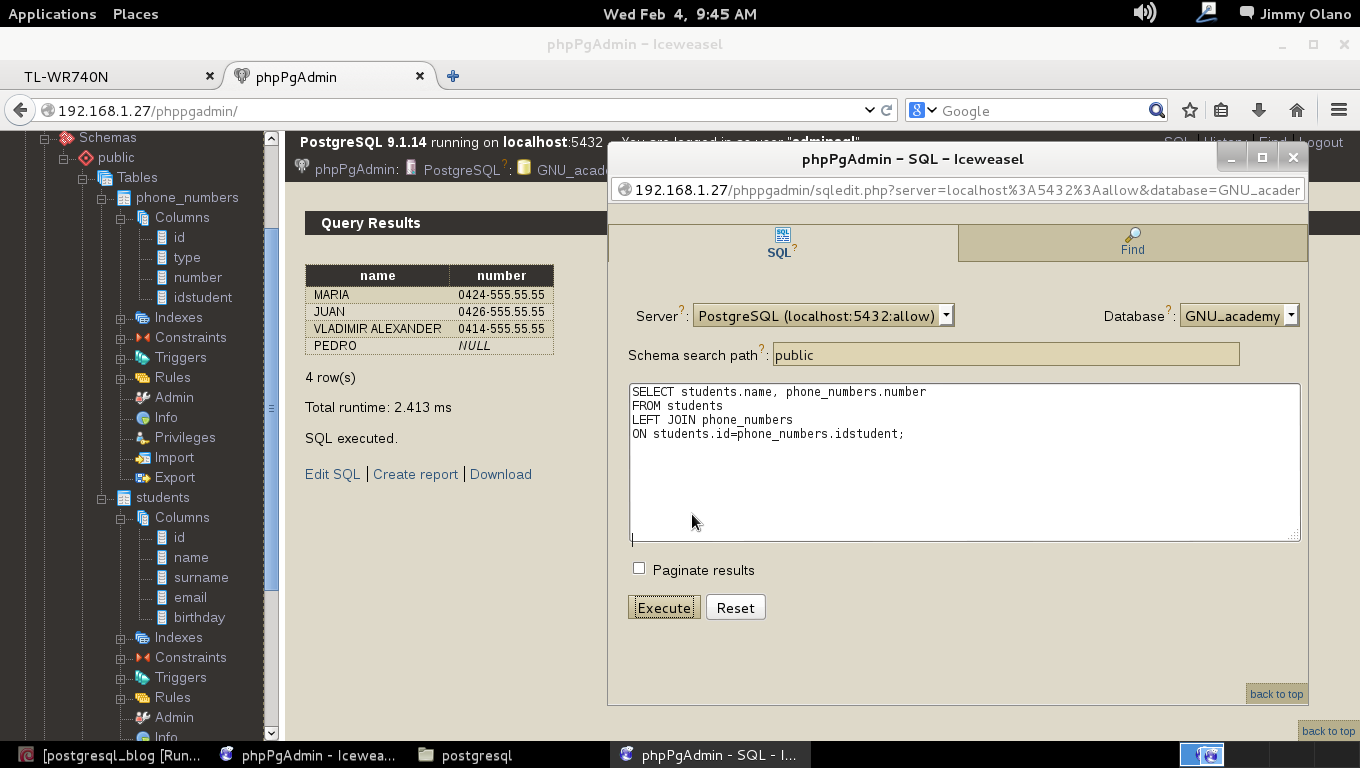
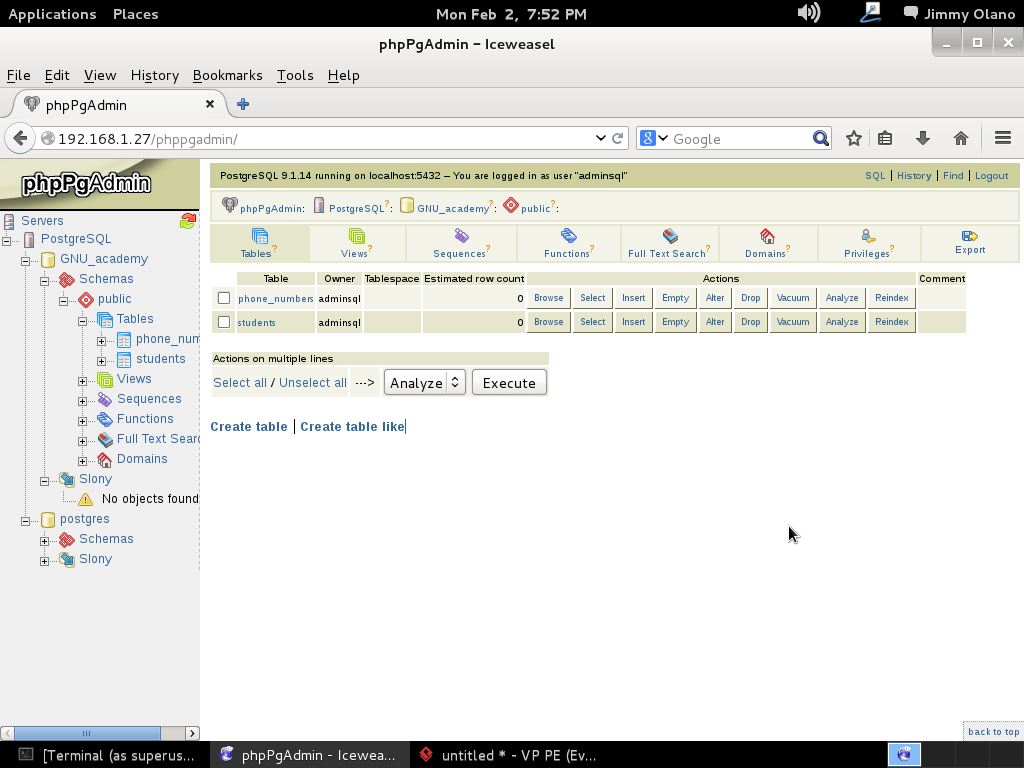
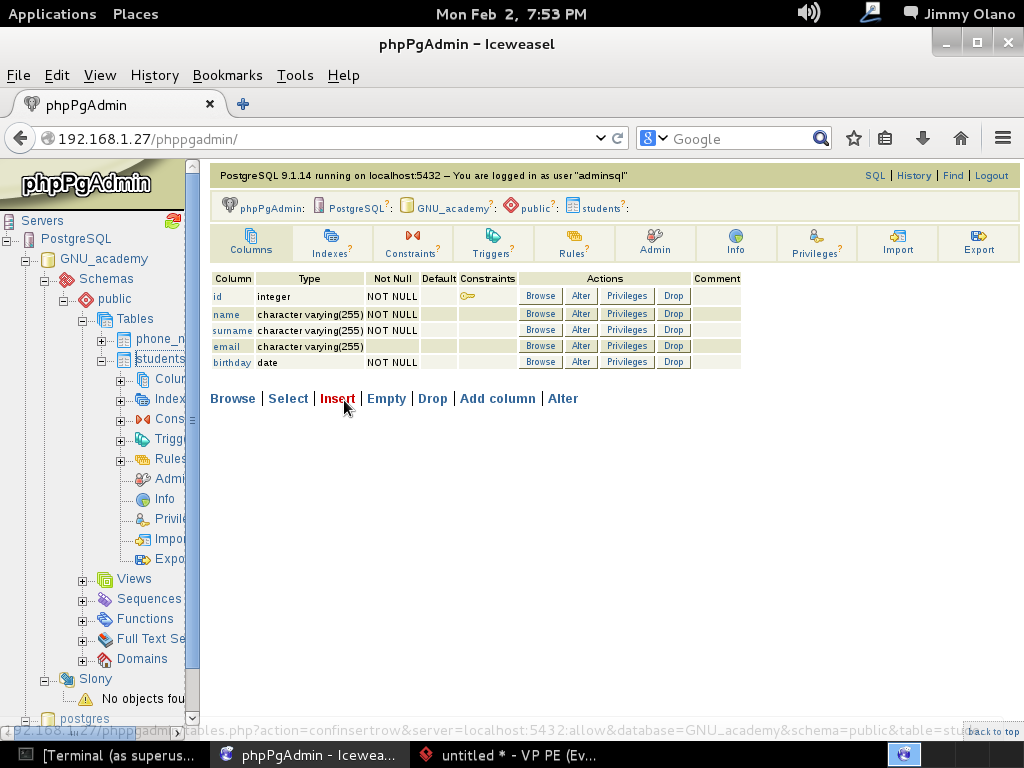
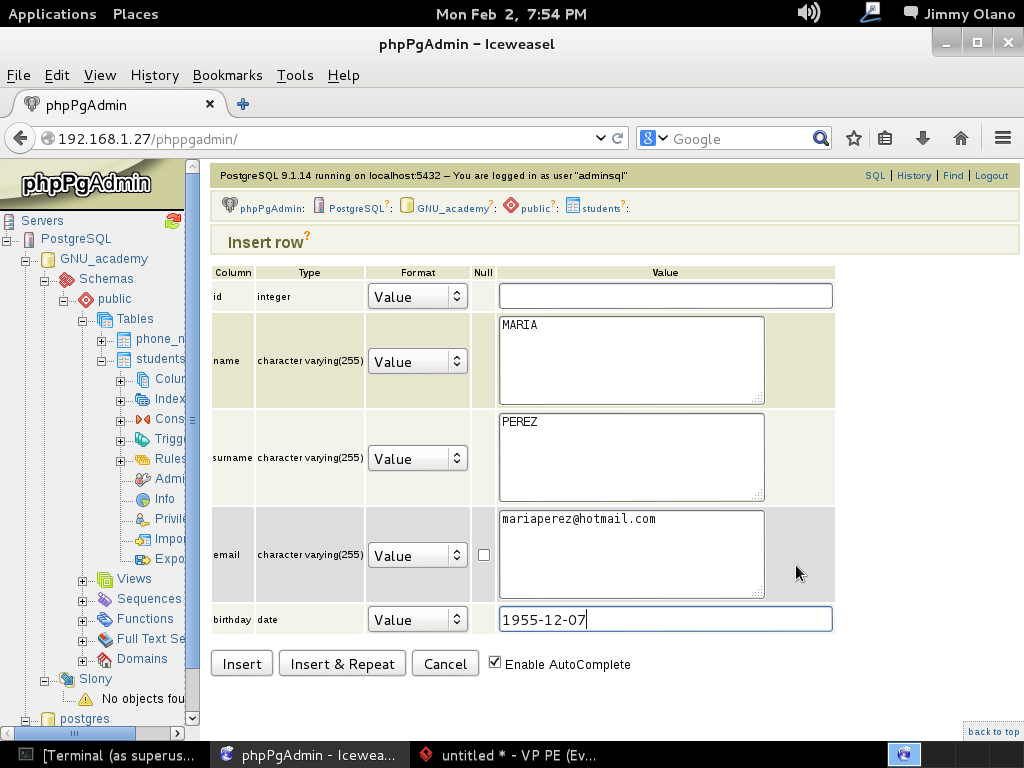
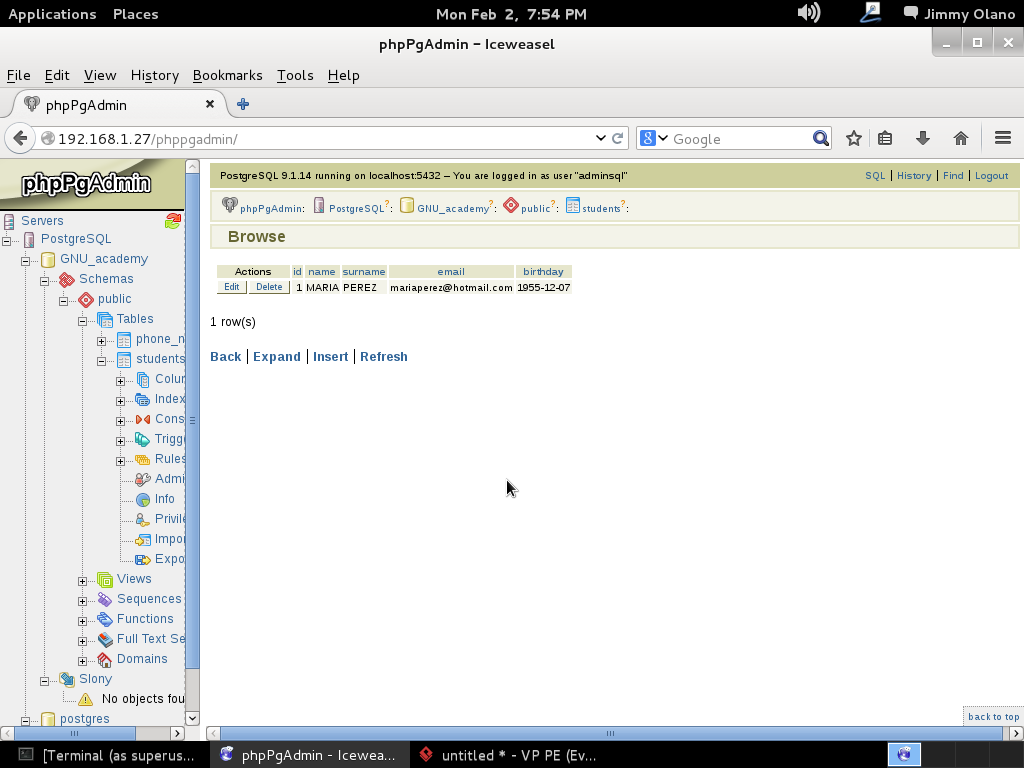
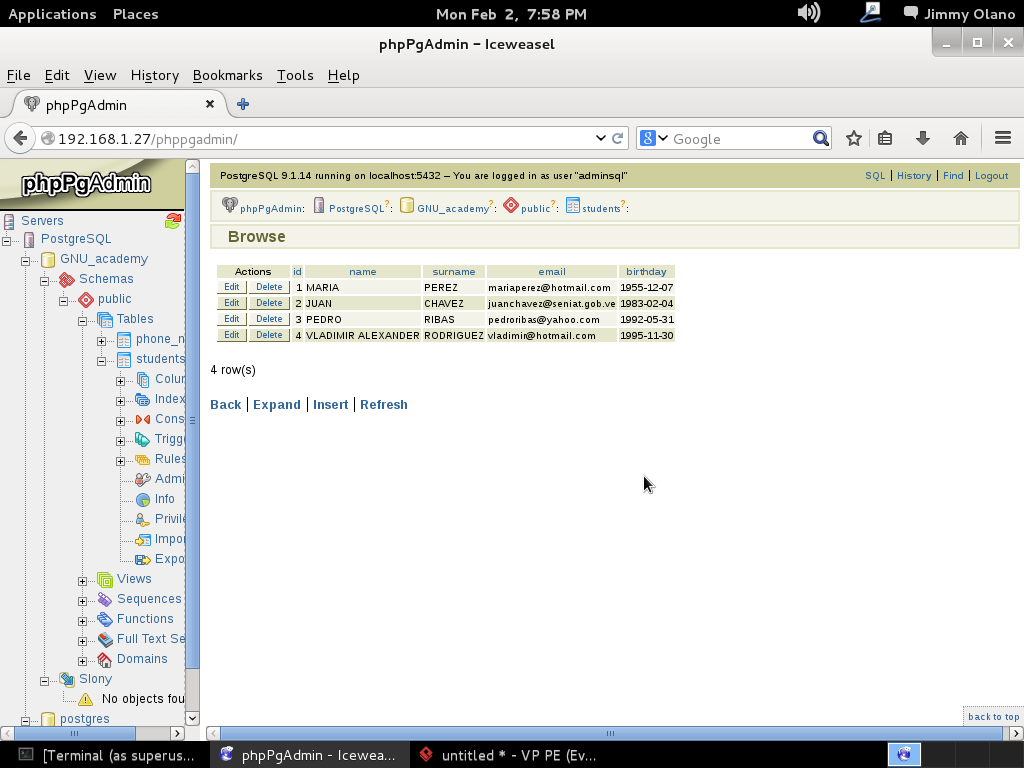
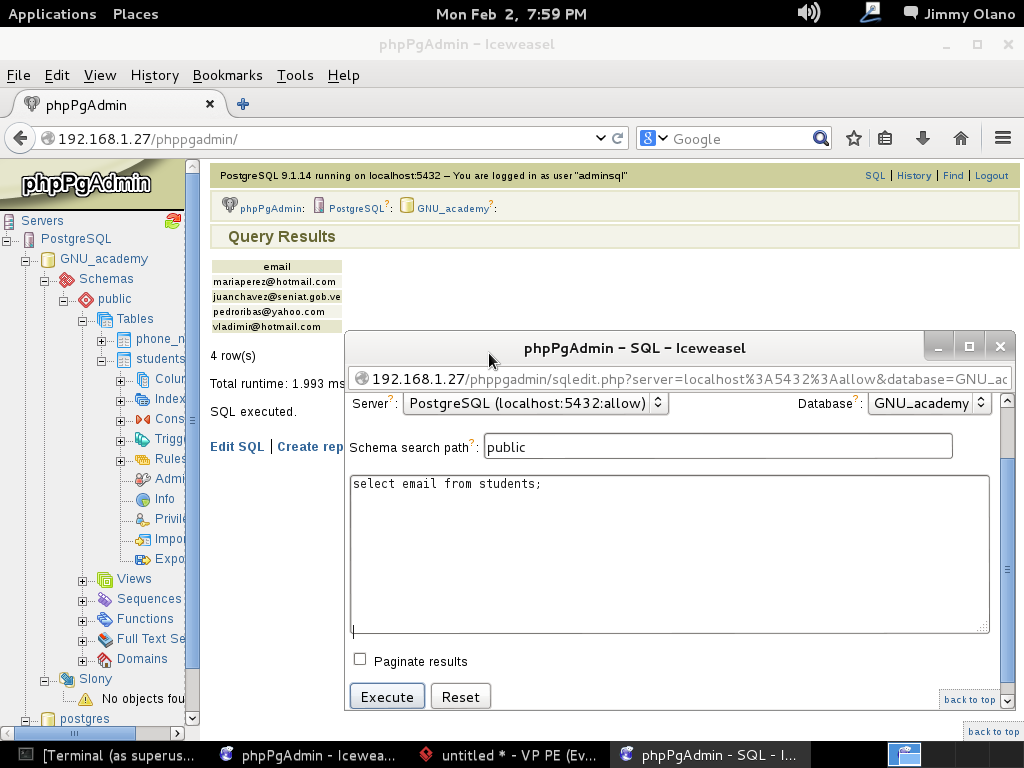
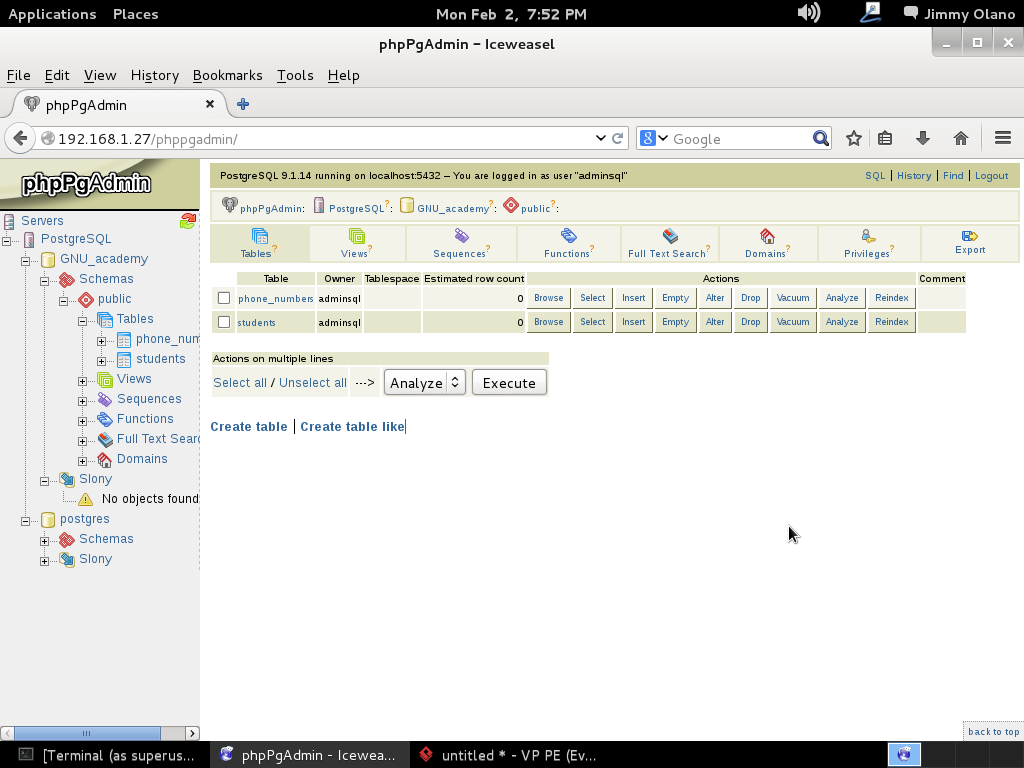
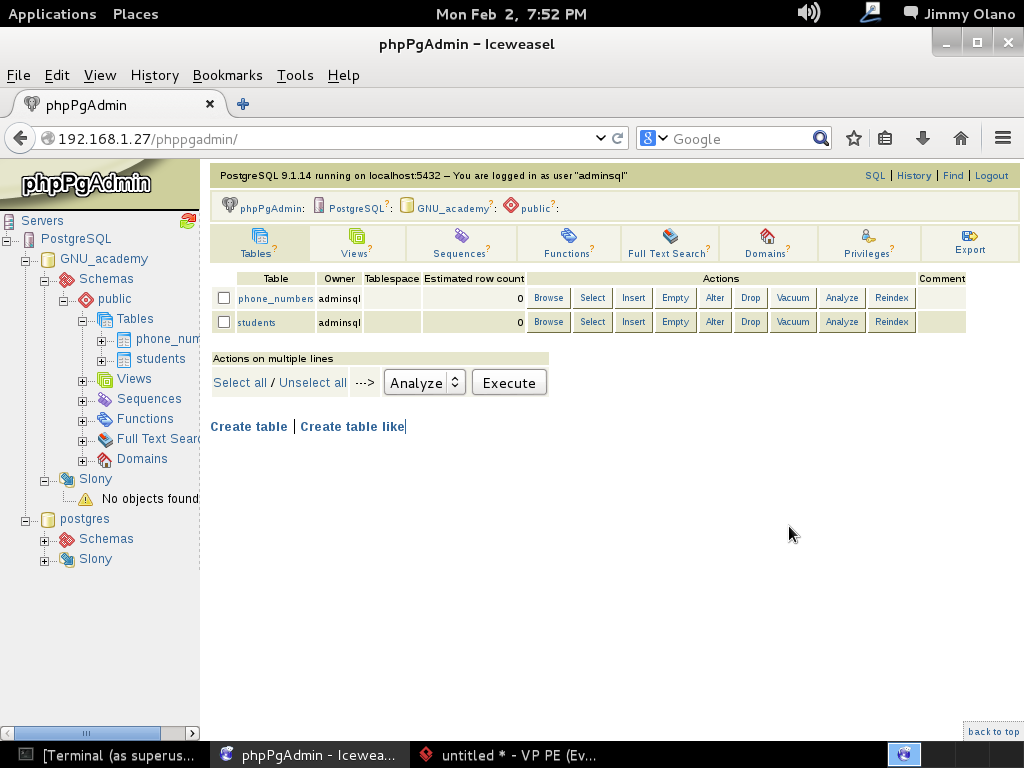
 Ya para finalizar esta entrada, y sólo por desconfianza inherente a nuestra naturaleza humana, verificamos con phpPgAdmin cómo quedaron nuestras tablas (cómo navegar e ingresar están descritos en la entrada anterior) :
Ya para finalizar esta entrada, y sólo por desconfianza inherente a nuestra naturaleza humana, verificamos con phpPgAdmin cómo quedaron nuestras tablas (cómo navegar e ingresar están descritos en la entrada anterior) :
 En nuestra próxima entrada veremos cómo añadir unos cuantos datos (registros) y los primeros comandos básicos de SQL.
En nuestra próxima entrada veremos cómo añadir unos cuantos datos (registros) y los primeros comandos básicos de SQL.
<Eso es todo, por ahora>.

 No abundaré en muchos detalles para el proceso de instalación, pero si los necesarios para lograrlo con éxito, espero me disculpen mi parquedad en esta entrada. En VirtualBox hacemos click en «Crear nueva máquina virtual» y se abre el siguiente cuadro de diálogo:
No abundaré en muchos detalles para el proceso de instalación, pero si los necesarios para lograrlo con éxito, espero me disculpen mi parquedad en esta entrada. En VirtualBox hacemos click en «Crear nueva máquina virtual» y se abre el siguiente cuadro de diálogo: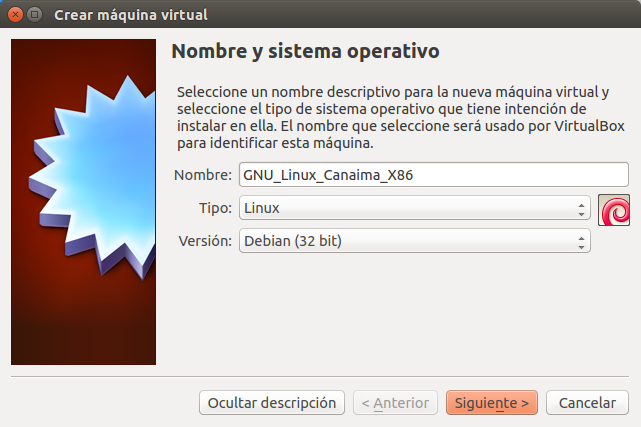
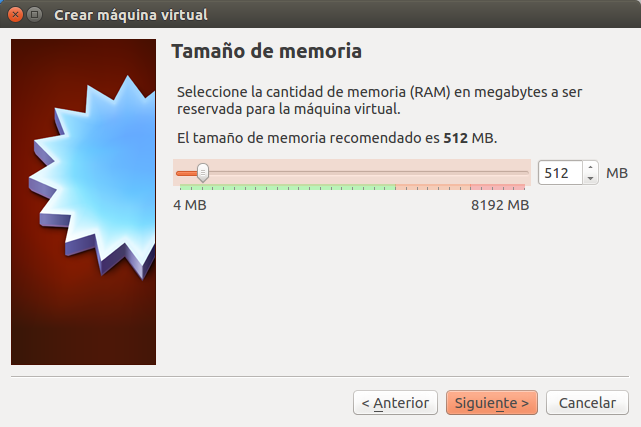
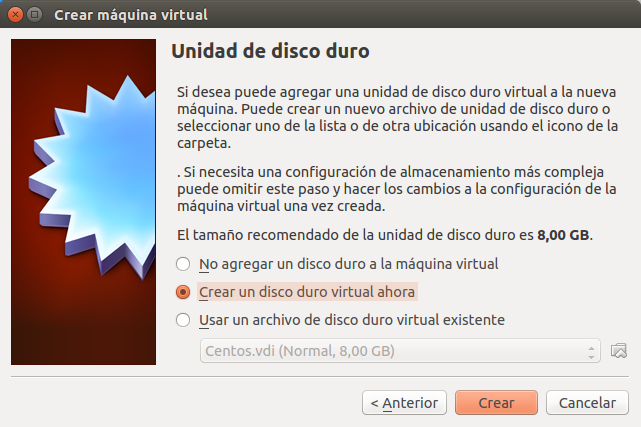
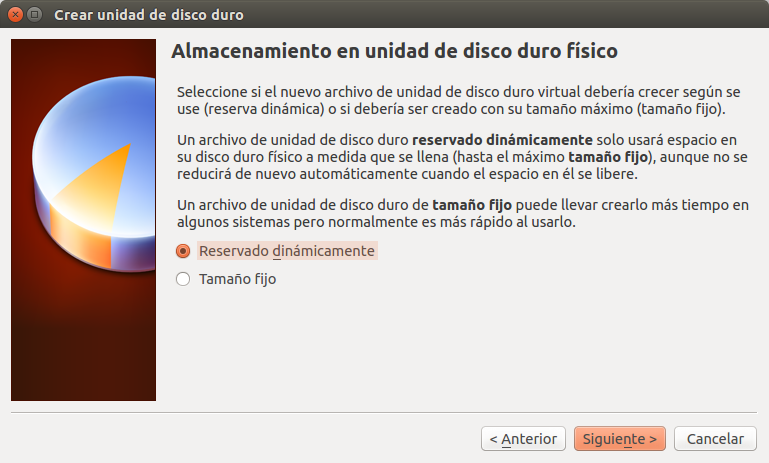
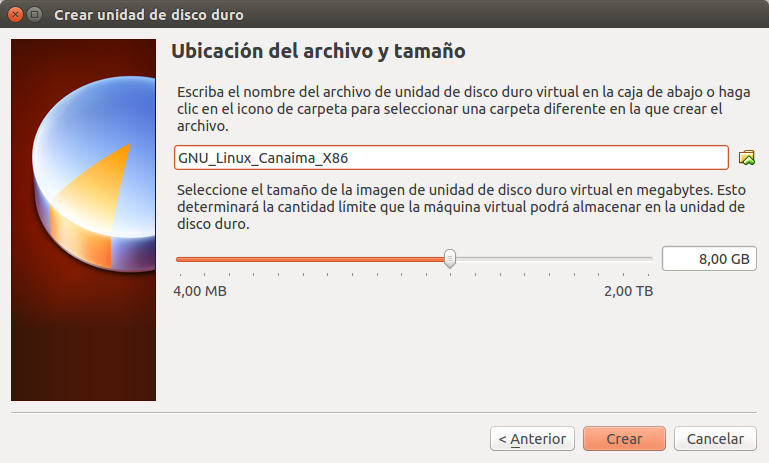 Una vez hayamos creado el disco duro virtual y finalizado la creación con los valores que sugiere VirtualBox debemos hacer unos ajustes adicionales e importantes para comenzar a isntalar el sistema operativo GNU Linux Canaima. Primero seleccionamos la máquina virtual que acabamos de crear y hacemos click en configuración y se abre el siguiente cuadro de diálogo:
Una vez hayamos creado el disco duro virtual y finalizado la creación con los valores que sugiere VirtualBox debemos hacer unos ajustes adicionales e importantes para comenzar a isntalar el sistema operativo GNU Linux Canaima. Primero seleccionamos la máquina virtual que acabamos de crear y hacemos click en configuración y se abre el siguiente cuadro de diálogo: Hacemos click en la pestaña «Sistema» donde vamos a desmarcar y bajar la opción de disquete dejando de primero el arranque por «CD/DVD/BLURAY» y de segunda «DISCO DURO» y en el dispositivo apuntador seleccionamos «Ratón PS/2»:
Hacemos click en la pestaña «Sistema» donde vamos a desmarcar y bajar la opción de disquete dejando de primero el arranque por «CD/DVD/BLURAY» y de segunda «DISCO DURO» y en el dispositivo apuntador seleccionamos «Ratón PS/2»: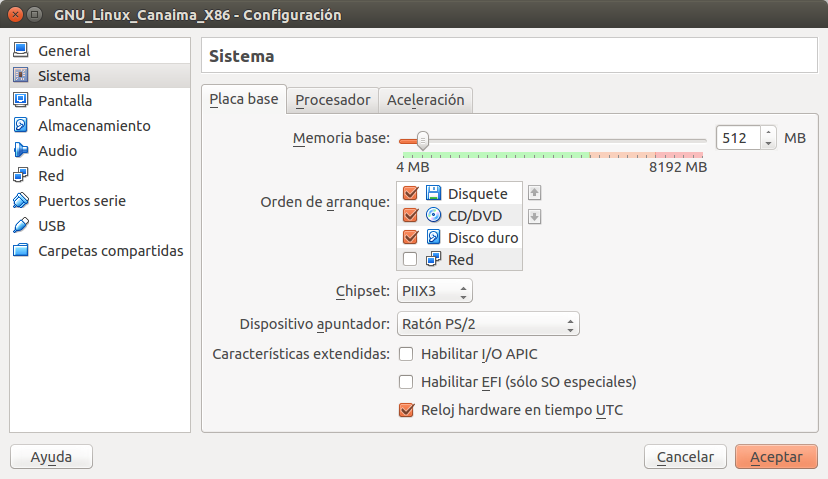 Luego hacemos click en «Pantalla» y en «Memoria de vídeo» le colocamos 32 megabytes (que era lo que tenía de video mi primera computadora 486 en los años 90, con una tarjeta PCI, para Linux es más que suficiente):
Luego hacemos click en «Pantalla» y en «Memoria de vídeo» le colocamos 32 megabytes (que era lo que tenía de video mi primera computadora 486 en los años 90, con una tarjeta PCI, para Linux es más que suficiente):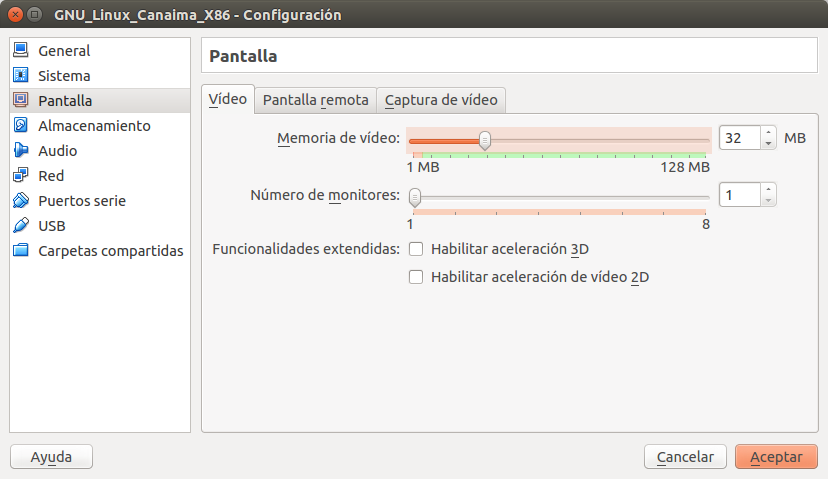 A continuación seleccionamos «Almacenamiento» iremos a lo más importante que es señalarle dónde se encuentra ubicado nuestra imagen .iso del Canaima y se lo especificamos en la unidad de cd virtual tal como lo vemos a continuación:
A continuación seleccionamos «Almacenamiento» iremos a lo más importante que es señalarle dónde se encuentra ubicado nuestra imagen .iso del Canaima y se lo especificamos en la unidad de cd virtual tal como lo vemos a continuación: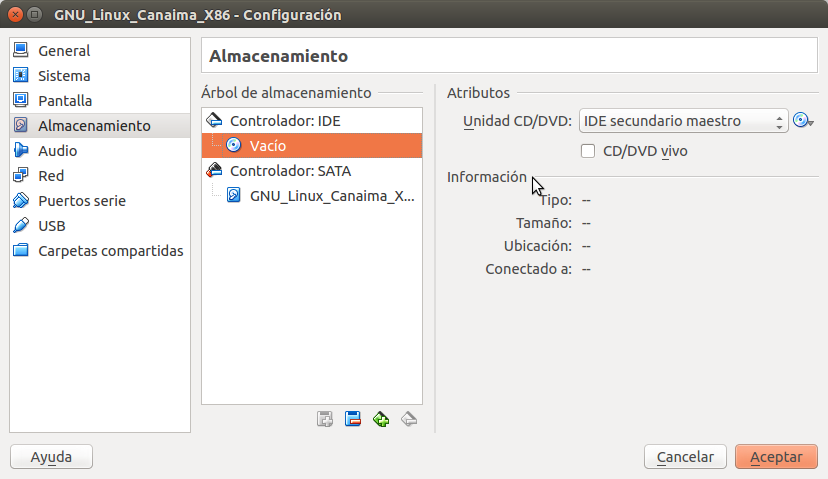
 Por último vamos a la pestaña «Red» y le colocamos en «Conectado a» le especificamos «Adaptador puente» y expandimos «Avanzadas» y desmarcamos «Cable conectado» para que no se conecte al internet.
Por último vamos a la pestaña «Red» y le colocamos en «Conectado a» le especificamos «Adaptador puente» y expandimos «Avanzadas» y desmarcamos «Cable conectado» para que no se conecte al internet.