Este año 2016 ha evolucionado el Congreso Nacional de Software Libre hacia algo mejor y con mayor inclusión: el Congreso de Tecnologías Libres (CTL2016) y como ya se ha hecho costumbre la ciudad de Valencia es escala en su ruta nacional. Digo evolucionar porque ya no es solo software libre sino también hardware libre y además cualquier otra tecnología libre en todos los campos del conocimiento humano. Como todo inicio (o reinicio en este caso) al principio se experimenta siempre dificultades pero siempre tengamos muy presente: lo único constante es el cambio -y el único cambio que le gusta al ser humano es el cambio de pañal, cuando ya es tarde–.
Congreso de Tecnologías Libres CTL2016
Acerca del CTL2016.
En palabras oficiales publicadas en su página web:
El Congreso de Tecnologías Libres (CTL), es la evolución natural del Congreso Nacional de Software Libre (CNSL), ajustada al tiempo histórico con nueva imagen, nuevas ideas y nuevos objetivos que integran una amplia gama de temas: hardware, software, cultura, entre otros, manteniendo los mismos valores de la Libertad del Conocimiento que nos ha caracterizado. El CTL, es de igual manera un evento itinerante, el cual en cada fin de semana durante tres meses recorre trece ciudades de la República Bolivariana de Venezuela. Este evento y todas las actividades que le conciernen, serán siempre y sin excepción totalmente LIBRE Y GRATUITO para todas las personas que asistan. Las limitaciones de acceso solo dependerá de las capacidades de los espacios físicos. La naturaleza del evento será siempre inclusiva, sin discriminación de opinión, posición política, religión, género, raza, orientación sexual, condición económica, conocimientos técnicos o cualquier otro aspecto del Ser Humano. En este evento no se exige ninguna tendencia política, cualquiera que sea la posición de los organizadores y colaboradores se les da la misma inclusión. Nos orientamos a cumplir con los objetivos del Plan de la Patria en todos los espacios que dispongamos. Además del apoyo total a las Políticas de Estado; leyes, normas técnicas, entre otros.
El Congreso de Tecnologías Libres (CTL), es la evolución natural del Congreso Nacional de Software Libre (CNSL), ajustada al tiempo histórico con nueva imagen, nuevas ideas y nuevos objetivos que integran una amplia gama de temas: hardware, software, cultura, entre otros, manteniendo los mismos valores de la Libertad del Conocimiento que nos ha caracterizado. El CTL, es de igual manera un evento itinerante, el cual en cada fin de semana durante tres meses recorre trece ciudades de la República Bolivariana de Venezuela. Este evento y todas las actividades que le conciernen, serán siempre y sin excepción totalmente LIBRE Y GRATUITO para todas las personas que asistan. Las limitaciones de acceso solo dependerá de las capacidades de los espacios físicos. La naturaleza del evento será siempre inclusiva, sin discriminación de opinión, posición política, religión, género, raza, orientación sexual, condición económica, conocimientos técnicos o cualquier otro aspecto del Ser Humano. En este evento no se exige ninguna tendencia política, cualquiera que sea la posición de los organizadores y colaboradores se les da la misma inclusión. Nos orientamos a cumplir con los objetivos del Plan de la Patria en todos los espacios que dispongamos. Además del apoyo total a las Políticas de Estado; leyes, normas técnicas, entre otros.
Entes auspiciantes en Carabobo CTL2016 ( ¡gracias! )
- Secretaría de Comunicación e Información de la Gobernación de Carabobo.
- Instituto de Capacitación y Educación Socialista.
Gracias al @INCESLARA por facilitar sus instalaciones físicas.@Liliana00644180 #ctl2016 @CTL_ve pic.twitter.com/miCkS18R05
— KS7000 (@ks7000) 10 de junio de 2016
Contactos Nacionales CTL2016.
Contactos Regionales CTL2016.
- Liliana Vasquez, Trabajadora INCES Carabobo.
- Luisana Herrera, Periodista de la Unidad Territorial Carabobo.
- Janrayber Hernández, a cargo del Registro de Asistentes.
- Mariagabriela López, trabajadora de SUSCERTE.
Ponencias.
Viernes 09 de junio de 2016.
Apertura.
Palabras de apertura @dcecchis @CTL_ve #CTL2016 #Carabobo
cc @UTCarabobo @ASLCarabobo @SoyNadia_ pic.twitter.com/ytq8nstx65— KS7000 (@ks7000) 10 de junio de 2016
«Software libre, para una sociedad libre» por Oscar Zambrano.
Con la primera ponencia @OscarGNU
cc @CTL_ve #CTL2016@lubrio #CArabobo #SoftwareLibre pic.twitter.com/o4SqIYmEQA— KS7000 (@ks7000) 10 de junio de 2016
@OscarGNU inicia el #CTL2016 en #Carabobo con el tema "Software Libre para una Sociedad Libre" pic.twitter.com/9xsxNAViU3
— CTL (@CTL_ve) 10 de junio de 2016
«Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
El Software Libre con Canaima Educativo, por Armando con sólo 14 años en el #CTL2016 #Carabobo pic.twitter.com/0iCC45gbIF
— Mariagabriela (@lmariagabriela) 10 de junio de 2016
«Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
Inicio de ponencia sobre certificación electrónica a cargo de @utccorrea y presentado por @lmariagabriela #CTL2016. pic.twitter.com/sfnfetcf31
— KS7000 (@ks7000) 11 de junio de 2016
«La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre» por Armando J. León D.
CTL_ve : RT lmariagabriela: Siguiendo la Jornada del #CTL2016 #Carabobo, Armando León habl… pic.twitter.com/XbYQ1ZLSeZ pic.twitter.com/HtNBhanF61
— Oscar Palencia (@monagaslibre) 10 de junio de 2016
«Carreras y tecnologias que debes tomar en cuenta en el 2016» por Ángel Guadarrama.
Comenzó la segunda tanda del día del #CTL2016 en #Valencia, con el amigo @fr33co pic.twitter.com/tp4WgvjZSY
— Gerardo Maduro (@gerardomaduro) 10 de junio de 2016
Sábado 10 de junio de 2016.
«Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
Multimedia en software libre. Datos-Información-conocimiento-sabiduría @lauyader #CTL2016 @tecnologialibre pic.twitter.com/c0ipDzuLos
— ♛Andrea Gomez♛ (@Andry_Carol) 11 de junio de 2016
«Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
Ntra ponencia: Hacia una Estrategia Nacional de Ciberseguridad y Ciberdefensa en el @CTL_ve 2016 Capítulo Carabobo pic.twitter.com/aOxDPoDZDN
— SUSCERTE (@SUSCERTE) 11 de junio de 2016
«Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
Excelente presentación José espinoza #CTL2016 @jmespiz Ionic para el desarrollo de aplicaciones híbridas. @ pic.twitter.com/ldLUwqKxxE
— ♛Andrea Gomez♛ (@Andry_Carol) 11 de junio de 2016
«EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
Seguimos en el #CTL2016 #Carabobo con Abiud Matos: El Sw Libre como Herramienta en la Sistematización Pedagógica pic.twitter.com/xfx12cHw1Z
— Mariagabriela (@lmariagabriela) 11 de junio de 2016
«Uso seguro de las redes sociales» por María Gabriela.
"Uso seguro de las redes sociales" por María Gabriela @lmariagabriela .#CTL2016 @CTL_ve sábado 11 de junio de 2016. pic.twitter.com/dzwvb6BYVK
— KS7000 (@ks7000) 12 de junio de 2016
«Ingeniería Social y Software Libre» por Manuel Tovar.
Ya en el cierre del #CTL2016 en #Valencia a cargo del @senseitovar. @CTL_ve @OscarGNU @Davidragar @lmariagabriela pic.twitter.com/TUMr6f4iHx
— Gerardo Maduro (@gerardomaduro) 11 de junio de 2016
Palabras de cierre por parte de Dany De Cecchis.
Palabras de cierre de parte de @dcecchis @CTL_ve #CTL2016 #Valencia #Carabobo sábado 11 de junio de 2016. pic.twitter.com/C3Tkk7qB00
— KS7000 (@ks7000) 12 de junio de 2016
Con gran éxito termino el @CTL_ve Carabobo de la mano de @UTCarabobo y sus participantes. #CTL2016 pic.twitter.com/8IqWIoCSxX
— Mariagabriela (@lmariagabriela) 13 de junio de 2016
Galería fotográfica.
-

- Minutos previos al inicio de ponencias.
-

- Símbolos Patrios e insignias en el auditorio del INCES, avenida Lara, Valencia, Carabobo.
-

- Símbolos Patrios e insignias en el auditorio del INCES, avenida Lara, Valencia, Carabobo.
-

- Símbolos Patrios e insignias en el auditorio del INCES, avenida Lara, Valencia, Carabobo.
-

- Símbolos Patrios e insignias en el auditorio del INCES, avenida Lara, Valencia, Carabobo.
-

- Minutos previos al inicio de ponencias.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Palabras de apertura por parte de Dany De Cecchis y anuncio de la primera ponencia.
-

- Presentación de la ponencia «Software libre, para una sociedad libre»
-

- Presentación de la ponencia «Software libre, para una sociedad libre»
-

- Presentación de la ponencia «Software libre, para una sociedad libre»
-

- Presentación de la ponencia «Software libre, para una sociedad libre»

-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- Palabras de cierre a cargo de Dany De Cecchis.
-

- Palabras de cierre a cargo de Dany De Cecchis.
-

- Palabras de cierre a cargo de Dany De Cecchis.
-

- «Defendiendo nuestro País Potencia»
-
- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- «Ingeniería Social y Software libre» por el Sensei Manuel Tovar.
-

- Presentación de la ponencia «Ingeniería Social y Software libre».

-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- Presentación de «Uso seguro de las redes sociales» por MAría Gabriela (SUCERTE).
-

- «Uso seguro de las redes sociales» por María Gabriela (SUCERTE).
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-
- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «EL Software Libre como herramienta en la sistematización de la práctica pedagógica» por Abiud Josue Matos Lugo.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
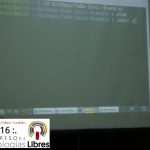
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
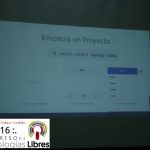
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
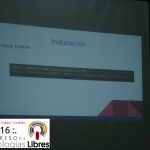
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
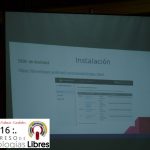
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
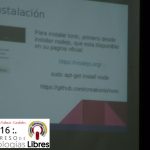
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-
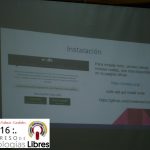
- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- «Aplicaciones Moviles: Primeros pasos con Ionic» por José Espinoza.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-
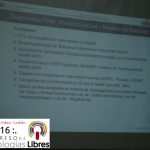
- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-
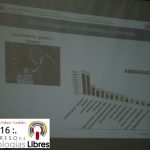
- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa» por Carlos Acosta.
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa».
-

- Presentación de la ponencia «Hacia una estrategia de CiberSeguridad y Defensa».
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-
- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-
- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-
- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-
- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- «Multimedia con Software Libre, una experiencia en la Universidad de Carabobo, Facultad de Ciencias de la Educación» por Luis Auyaudermont.
-

- Inicip de las ponencias del día sábado 11 de junio de 2016.
-

- Jardín del auditorio del INCES, fresco y con frimes valores patrios despide las ponencias del día viernes 10 de junio de 2016.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.

-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.

-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «Fundación Instituto de Ingeniería para la investigación y desarrollo tecnológico» por Merbys Correa.
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- Entrevista a Oscar Zambrano por parte de los medios de comunicación.
-

- Entrevista a Oscar Zambrano por parte de los medios de comunicación.
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- Presentación «La Formación Integral del Sistema Comunidad, Universidad y Empresa (CUE) como centro de Capacitación para el Fortalecimiento del Uso de las (TICL) en Herramientas Aplicadas al Software Libre».
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-
- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Ponencia «Carreras y tencologias que debes tomar en cuenta en el 2016» por Angel Guadarrama.
-

- Entrada principal al INCES de la Avenida Lara minutos antes del inicio de las ponencias vespertinas del viernes 10 de junio de 2016.
-

- Intervención de David Ragar en ponencia «Cuando el software libre llego a mi vida».
-

- Intervención de David Ragar en ponencia «Cuando el software libre llego a mi vida».
-

- Intervención de David Ragar en ponencia «Cuando el software libre llego a mi vida».
-

- Intervención de David Ragar en ponencia «Cuando el software libre llego a mi vida».
-

- Intervención de David Ragar en ponencia «Cuando el software libre llego a mi vida».
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- «Cuando el software libre llego a mi vida» por Enyerbeth Blanco.
-

- Presentación de la ponencia «Cuando el software libre llego a mi vida».
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- Intervención de Dany De Cecchis en ponencia «Software libre, para una sociedad libre».
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
-

- «Software libre, para una sociedad libre» por Oscar Zambrano.
Enlaces relacionados:
- Congreso de Tecnologías Libres.
- Unidad Territorial Carabobo.
- Superintendencia de Servicios de Certificación Electrónica.