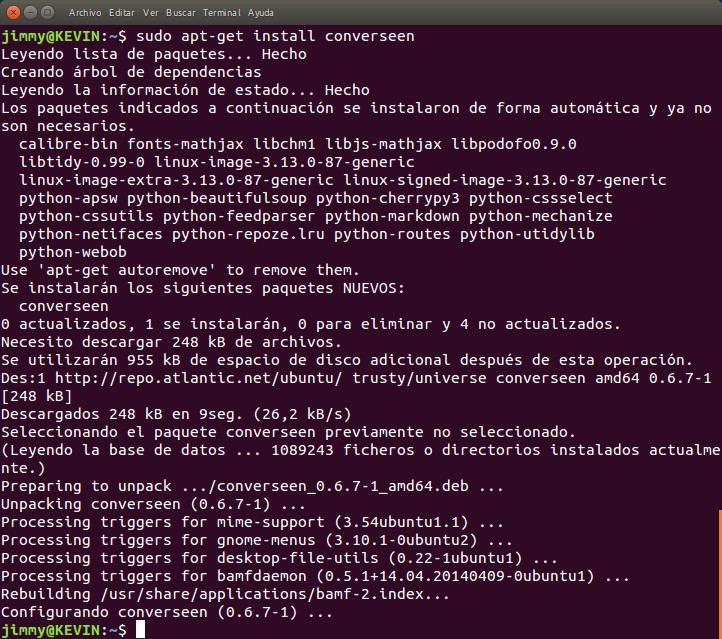
En nuestra entrega anterior -y con la ayuda del Doctor Jason Brownlee- instalamos Fedora 25 como máquina virtual para tener un entorno de desarrollo específico para Python3: pues bien, el fin último es tener una base para poder desarrollar el «machine learning» a un nivel intermedio, veamos.
¿Qué es el «machine learning»?
Es una ciencia aplicada con ayuda de los ordenadores: de una serie gigantesca de datos obtenidos de nuestro mundo analógico regido por la mecánica cuántica podemos obtener patrones, precisamente lo que hacemos nosotros los seres humanos, como por ejemplo cuando miramos una noche estrellada y percibimos constelaciones que solo están en nuestro cerebro. Muchas universidades en el mundo están abocadas a este estudio y promete ser el futuro en el cual debemos estar preparados para cuando lleguen los ordenadores cuánticos.
Un dato que nos llama la atención es que ya hoy en día tiene una aplicación práctica, para mal, denunciada por Edward Snowden en su cuenta en Twitter:
¿Qué tiene que ver esto con el «machine learning»? Pues que el dispositivo que es utilizado para detectar los patrones de atención de los televidentes durante los comerciales es grabado con un dispositivo originalmente diseñado para juegos denominado Kinetic. En realidad es un dispositivo biométrico que en el año 2011 incluso ganó un premio de 50 mil libras esterlinas por desarrollo innovador al reconocer los movimientos de nuestro cuerpo, interpretarlos y trasladarlo como acciones en los juegos de vídeo. Es así que en solo seis años se le ha conseguido un uso importante en la vida real, acercándonos cada vez más a las historias contadas en las saga de películas «Terminator».
Instalando un entorno basado en Python para el aprendizaje de las máquinas.
Instalando el entorno Python.
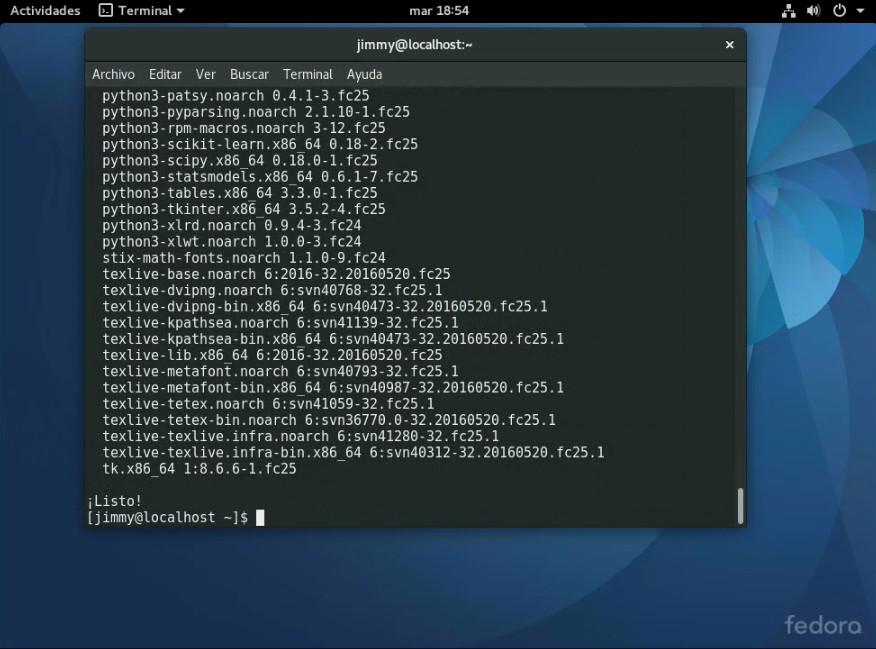
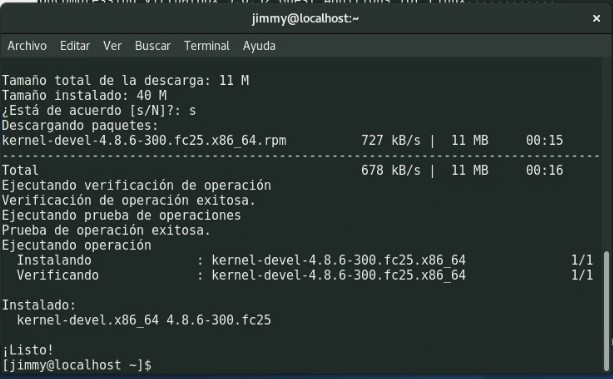
Como ya bien sabéis, ya sea por este vuestro humilde portal o por internet -que abunda información- el lenguaje de programación Python viene instalado por defecto en la mayoría de las distribuciones GNU/Linux y Fedora no es la excepción. Para saber cual versión tenemos instalada, ejecutamos nuestra máquina virtual e introducimos nuestras credenciales de usuario. Acto seguido pulsamos ALT+F2 e introducimos la orden «gnome-terminal» para ejecutar una ventana de comandos para lanzar la siguiente línea:
python3 --version
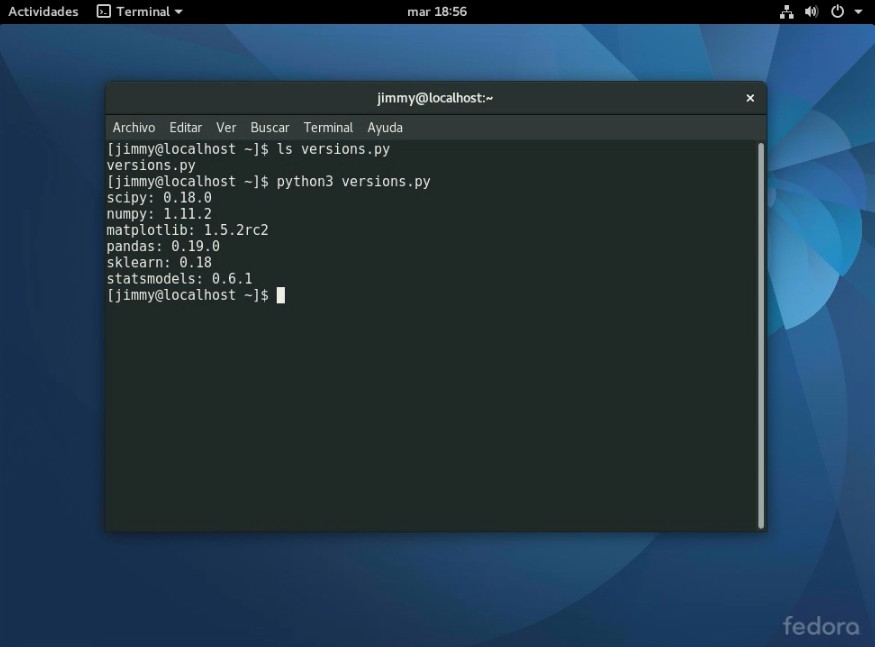
En la figura podemos observar que ya tenemos instalada la versión 3.5.2:
python3 –version
Instalando el conjunto de utilidades para Python3.
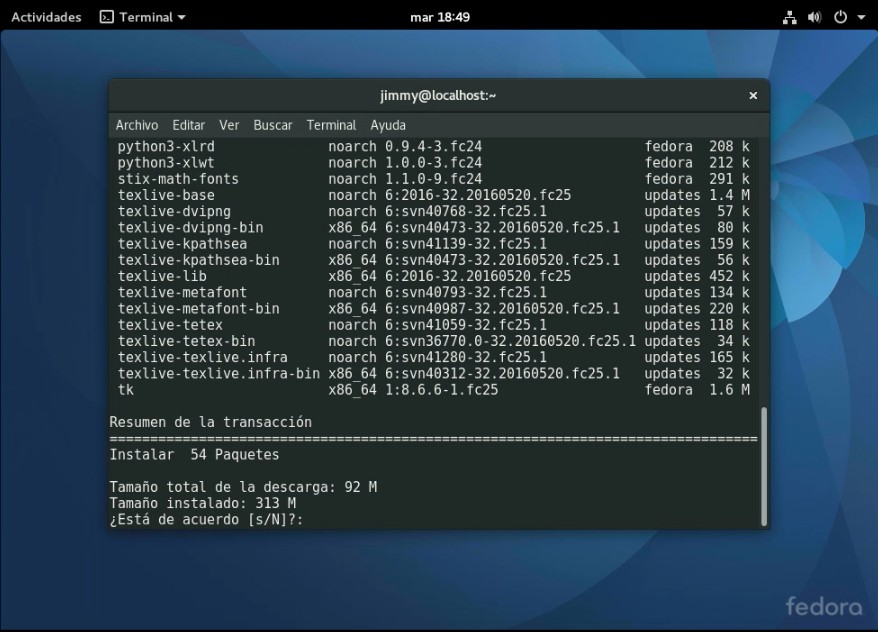
Los paquetes que necesitaremos son seis en total:
SciPy, conjunto de herramientas que integra los siguientes paquetes:
NumPy: herramienta para álgebra lineal, transformadas de Fourier y generación de números aleatorios.
Todas ellas las podemos bien instalar en una sola línea, bien una por una, depende de nuestra paciencia. Por rapidez escogeremos la primera y en la misma ventana terminal que tenemos abierta colocamos:
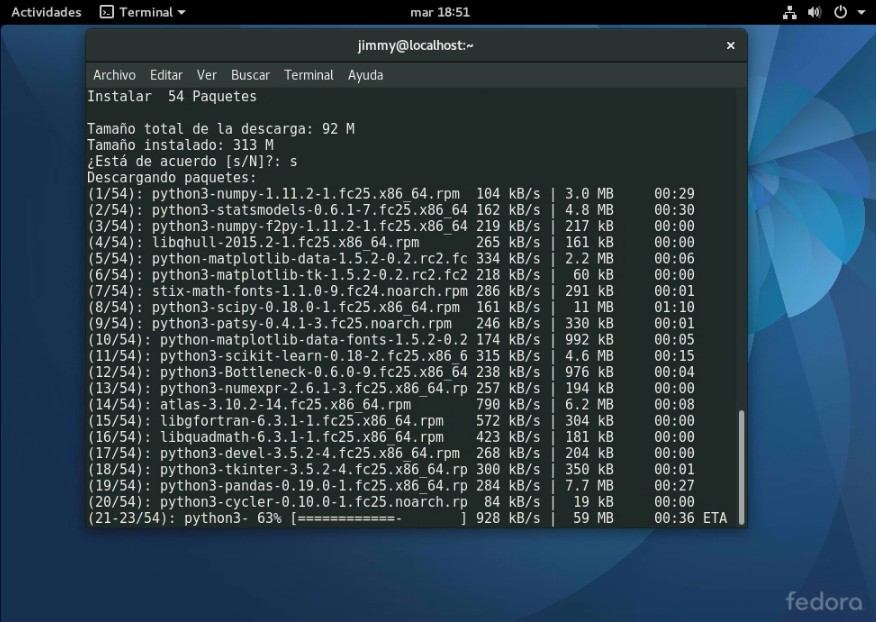
El comando DNF es la abreviatura para Dandified Yum, que tal como explicamos, es el equivalente al comando apt-get utilizado en las distribuciones GNU/Linux basadas en Debian. Así que autorizamos la descarga, que son más o menos 92 megabytes:
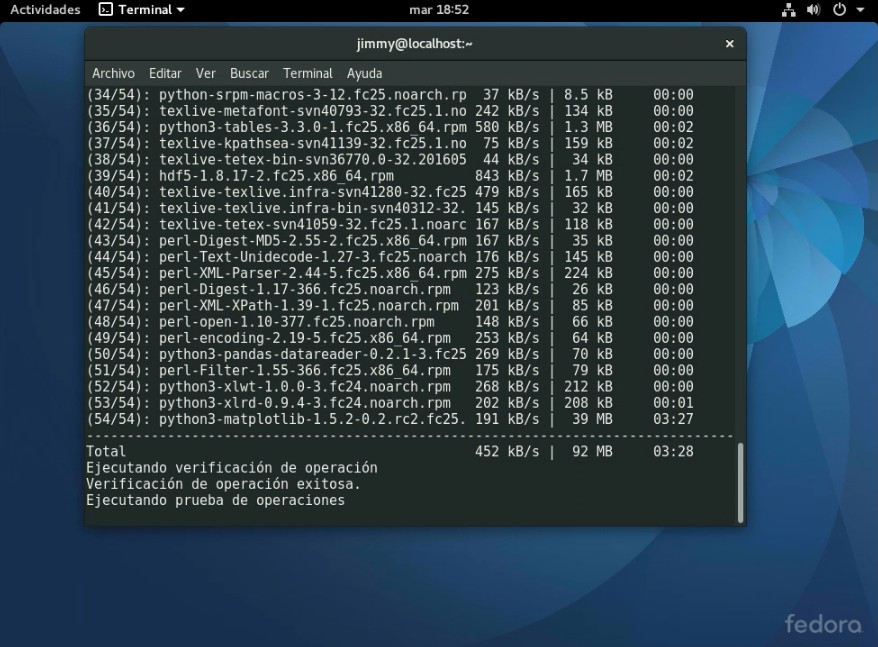
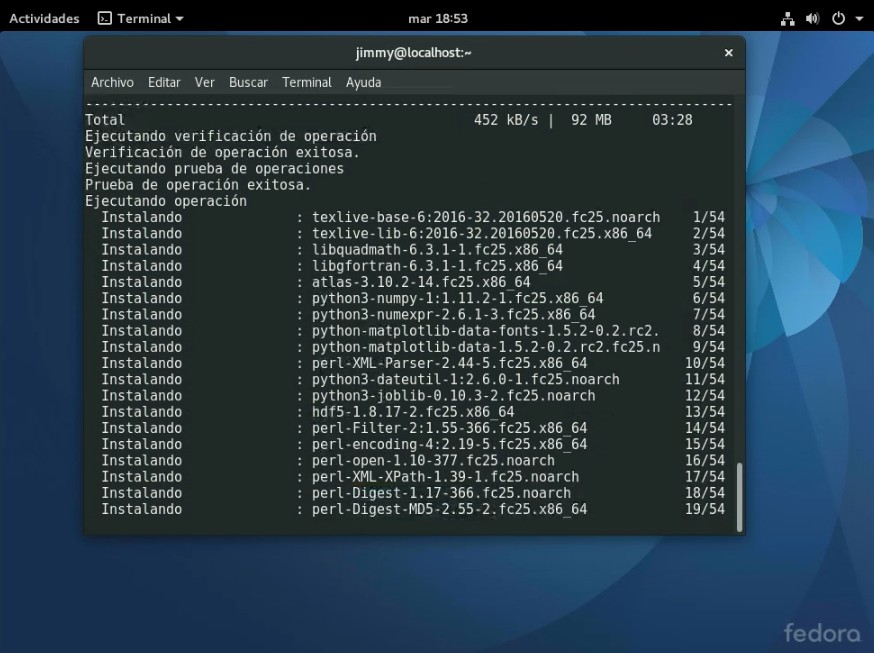
Una vez se han descargado a nuestro ordenador virtual, se hace la verificación de contenido y se procede a descomprimir e instalar; allí van 200 megabytes adicionales:
Instalando entorno Python3 para «machine learning» 3Instalando entorno Python3 para «machine learning» 4
Confirmación del entorno instalado.
Una vez finalizado procedemos a «crear» un guión en bash para averiguar rápidamente las versiones instaladas. Aquí viene la utilidad de haber instalado las utilerías de «VirtualBox Guest Additions» en nuestra entrada anterior: podremos «copiar y pegar» texto entre nuestro ordenador anfitrión y el ordenador virtual.
Habilitar el portapapeles entre VirtualBox y las máquinas virtuales.
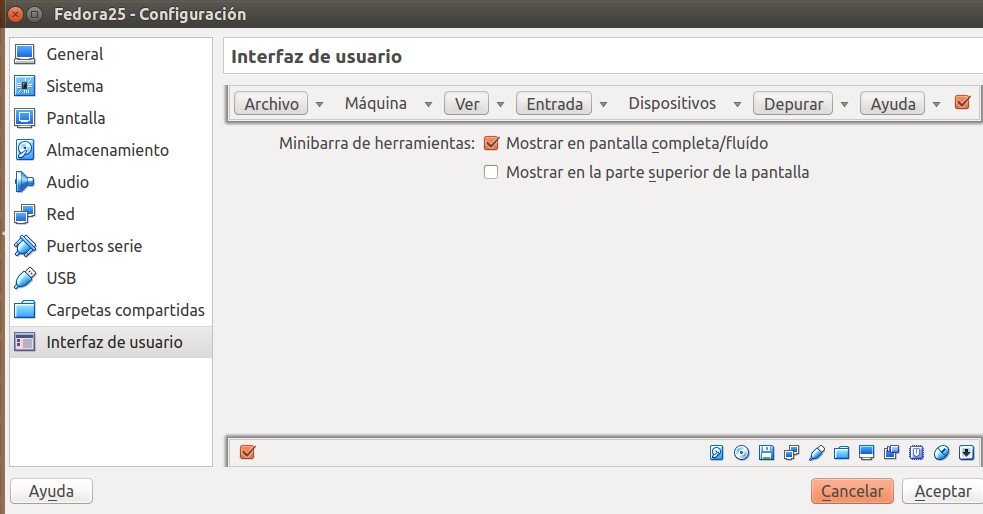
Antes de poder «copia y pegar» texto debemos primero habilitar su paso por medio de VirtualBox: seleccionamos la máquina virtual Fedora y presionamos CONTROL+S para entrar a la configuración y vamos a la sección «Interfaz de usuario» -> «Dispositivos»:
VirtualBox portapapeles entre ordenador anfitrión y ordenador virtual
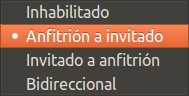
Descolgamos la lista y seleccionamos «Anfitrión a invitado» y damos «Aceptar».
VirtualBox portapapeles ordenador anfitrión a invitado
Archivo de comando «versions.py».
Ahora que podemos pasar el portapapeles a la máquina virtual (tedioso procedimiento para poder habilitarlo), seleccionamos, copiamos y pegamos lo siguiente:
En las siguientes imágenes utilizamos el editor de textos gedit, pero sentiros libres de utilizar vuestro preferido (de hecho nosotros más adelante instalamos nano):
Guión para detectar los componentes instalados de Python3 unoGuión para detectar los componentes instalados de Python3 dosGuión para detectar los componentes instalados de Python3 tresGuión para detectar los componentes instalados de Python3 cuatroGuión para detectar los componentes instalados de Python3 cinco
Leyendo el artículo del Doctor Jason Brownlee (Australia) -y aprovechando el receso de Carnaval 2017- nos decidimos a probar la distribución GNU/Linux, legendaria por demás, Fedora.
How to Create a Linux Virtual Machine For Machine Learning Development With Python 3 https://t.co/aGvlYnuwPk
First of all we want to thank Doctor Jason for his excellent article on learning about Python3 on a virtual machine and its many advantages for programming. His approach is very similar to ours, he in English, we in castilian language, so we publish this article to ADD the installation of «VirtualBox Guest Additions» in the virtual machine.
Primero que nada queremos agradecer al Doctor Jason por su excelente artículo sobre aprendizaje de Python3 sobre una máquina virtual y sus múltiples ventajas para la programación. Su enfoque es muy parecido al nuestro, él en inglés, nosotros en idioma castellano, por ello publicamos este artículo para AGREGAR la instalación de «VirtualBox Guest Additions» en la máquina virtual.
Es por ello que retomamos el camino que ya anduvimos en enero 2016 con nuestro artículo sobre la actualización de VirtualBox (recomendamos su lectura primero) y donde tratamos el tema de las «VBoxGuestAdditions». Esencialmente no hay mayor cambio:
Instalamos VirtualBox en nuestro ordenador anfitrión (máquina real).
Instalamos el Paquete de Extensiones en la máquina real.
Instalamos «VBoxGuestAdditions» en cada máquina virtual.
Por último, si lo necesitamos, compartimos ficheros con la(s) máquina(s) virtual(es).
Eso sí, haremos notar la tendencia del mundo GNU/Linux hacia la computación sobre procesadores de 64 bits, a medida que los ordenadores más viejos de 32 bits van desapareciendo por su edad y natural uso. Ya sabéis entonces: ahora Fedora solo para máquinas de 64 bits (manejo de memoria RAM de 4 gigabytes con discos duros de terabytes ¡y aún más!) y que lo único constante es el cambio.
Obteniendo Fedora a nuestro disco duro.
Nosotros acostumbramos descargar por medio de Torrent para así luego compartir desde nuestros propios ordenadores al mundo entero. Sin embargo, en una rápida búsqueda no conseguimos ningún archivo .torrent aunque en la página web de Fedora levemente lo mencionan.No queremos decir con esto que no exista, sino que simplemente, por ahora, no los conseguimos.
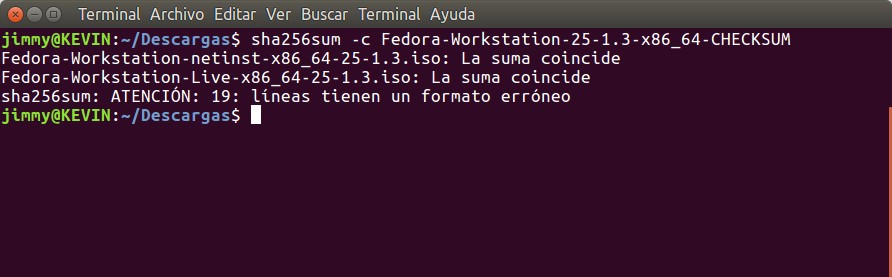
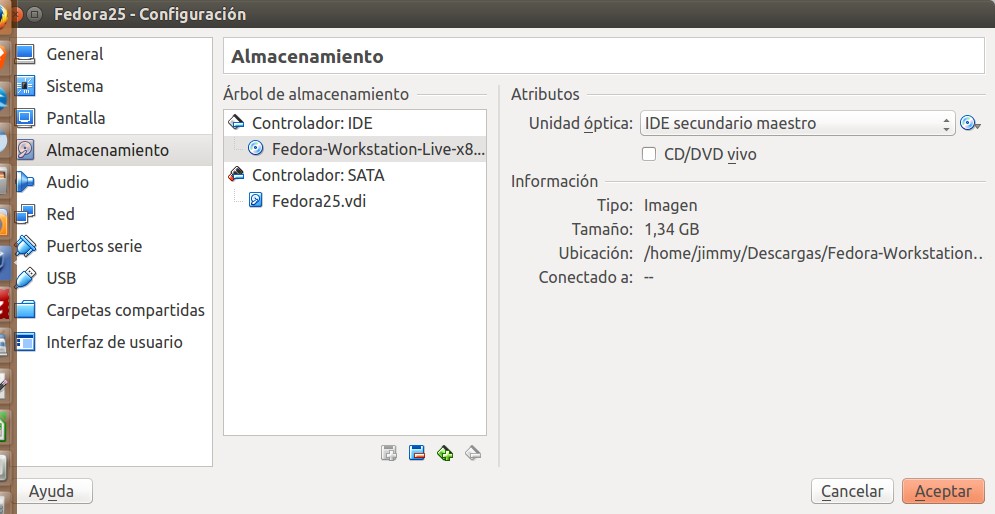
También sospechamos que influye el hecho de la seguridad que se ofrece en la página de descarga: DE PRIMERA MANO. En el enlace anterior podremos descargar la imagen ISO (Fedora tiene una página web segura https) y luego procedemos a descargar la llave GPG (GnuPG) y la importamos a nuestro sistema. Entonces descargamos el archivo de texto plano que contienen el CHECKSUM y a eso le aplicamos sha256sum el cual compara el resultado con el archivo previo y da su aprobación (desconocemos la causa del error en la línea 19 pero están comprobadas las dos imágenes iso -también, más adelante, probaremos la versión netinstall-). Mirad la imagen adjunta para que veáis de qué van las cosas:
sha256sum Fedora Workstation 25
Configurando la máquina virtual en VirtualBox.
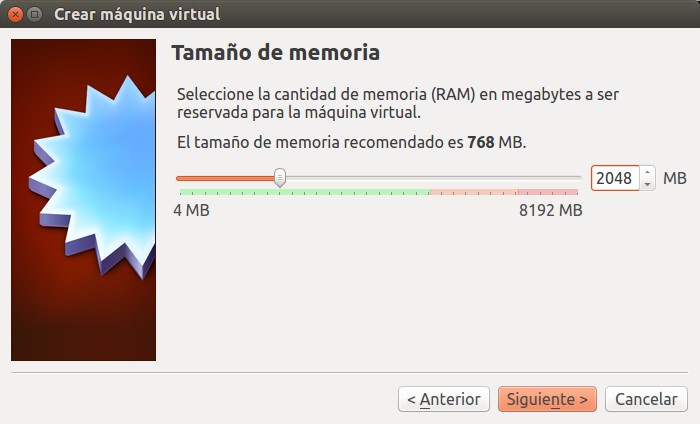
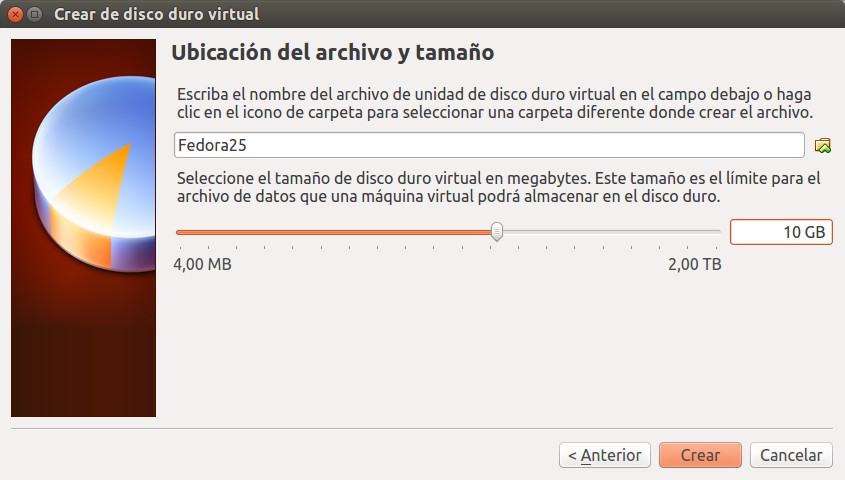
Tal como recomienda el Dr. Jason Brownlee le asignamos 2 gigabytes de memoria RAM (1 solo CPU, tenemos 4 en nuestra máquina anfitrión –máquina real-) y 10 gigabytes de espacio en disco duro virtual. Acá las tomas de pantalla del proceso:
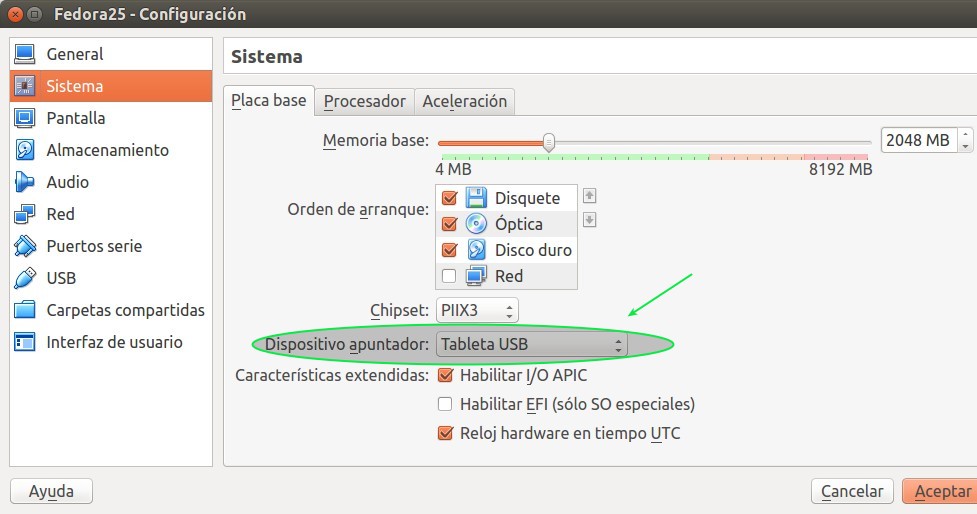
Detalle con el dispositivo apuntador en VirtualBox.
Un indicio de la modernidad -lo único constante es el cambio- es el dispositivo apuntador que por defecto trae VirtualBox: Tableta USB. Esto tal vez traiga problemas con sistemas operativos antiguos, nosotros siempre lo cambiamos a Raton/Teclado PS2 que es prácticamente universal hoy en día. Recordemos que VirtualBox le hace creer al sistema operativo que estemos instalando ciertas configuraciones de hardware, incluyendo varios discos duros, tarjetas de red, video, etcétera que en este punto no tiene mayor relevancia si el sistema operativo es moderno -¡y vaya si Fedora 25 lo es!- sino que cuando toquemos el tema del «Virtual Box Guest Additions» lo estudiaremos con sumo cuidado.
VirtualBox dispositivo apuntador por defecto
Instalando Fedora 25 ¡por fin!
Este es el paso más largo, y que trata en mayor detalle el Dr. Jason Brownlee en su tema, nosotros lo grabamos en un vídeo de 48 megabytes y lo subimos a Youtube, ¡espero os guste tanto como a nosotros cuando lo hicimos! ?
Instalando VirtualBox Guest Additions a Fedora.
Prefacio.
Ya hemos tenido ciertas «desavencias» con VirtualBox con esto de compilar los «kernel modules» y en un artículo anterior describimos con detalle nuestra experiencia al respecto. Recomendamos que por lo menos le echéis un «ojirijillo» rápidamente y volved acá con nosotros al finalizar, por favor.
Si, ya os pillamos, no leístes nada, pero bueno, acá lo resumimos: VirtualBox necesita estar a la medida de nuestro hardware, nuestra máquina real -anfitrión- y para ellos necesita estos archivos hechos a la medida para su excelente utilización:vboxdrv, vboxnetflt y vboxnetadp. Sin estos archivos simplemente no corre VirtualBox…
¿PERO QUE DECÍS, TÍO, SI VIRTUALBOX CORRE SIN PEGA ALGUNA?
Eso es correcto, es lo que estáis pensando: en los sistemas operativos populares (Debian, Ubuntu, Windows incluso) esto es cierto sin más pero hay distribuciones GNU/Linux muy específicas y es necesario recompilar dichos módulos para obtener su excelente desempeño (bueno en Windows no hay esta opción, ojo -que sepamos-).
Incluso esto que os cuento es válido para motores de bases de datos como PostgreSQL, podemos así compilar nuestros propios kernels PARA NUESTRO ORDENADOR ESPECÍFICO: esa es la ventaja que ofrece el software libre, ¡alucinante!
Detalle con nuestra tarjeta madre, máquina real.
Recordad ANTES de compilar los «kernel modules» en la máquina real el reiniciarla primero y ajustar los valores en el BIOS para soportar máquinas virtuales (hoy en día esto, generalmente, viene activo por defecto).
Cambiar los valores del SETUP de nuestra tarjeta madre puede desconfigurar seriamente nuestro sistema operativo instalado, asi que TENED MUCHO CUIDADO CON LO QUE TOCAS. Solamente os sugerimos activar UNICAMENTE la opción que permite compartir de manera eficiente los recursos reales (canales I/O, memoria, tarjeta de red) con las máquinas virtuales.
En la plataforma INTEL se necesita que tarjeta madre y procesador, ambos, soporten dicha tecnología llamada «Intel VT» o la aún mejor «Intel VT-D».
En la plataforma AMD se denomina «AMD Virtualization (AMD-V™)» y está específicamente orientada a servidores (de máquinas virtuales), todo un negocio en el alojamiento de páginas web hoy en día.
En vez de compartir un servidor web Apache, por ejemplo, os alquilan vuestra propia máquina con dirección IP exclusiva con una carta de diversos sistemas operativos, todo a vuestro gusto, INCLUSO esto permite «migrar» tus «recursos» rápidamente: mayor memoria, más procesadores, etcétera, con un solo click, luego de haber recibido vuestro pago, por supuesto.
Lo anterior es lo que denominados VENTAJAS de las máquinas virtuales, así como el artículo que inspira esta entrada, se usa una máquina virtual para contener un entorno de programación que podemos respaldar ¡y replicar en cualquier hardware moderno sin mayor dilación!
Configurando a Fedora 25 para «VirtualBox Guest Additions».
Allanando el terreno.
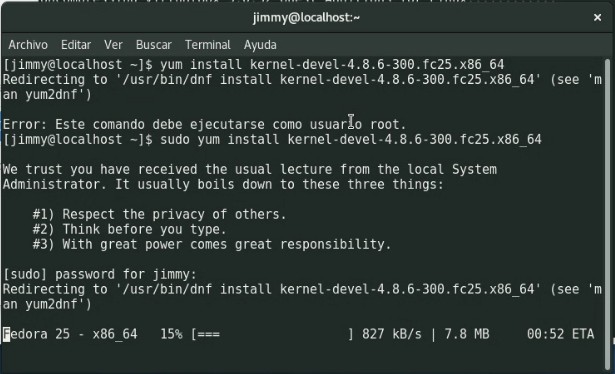
Antes de poder instalar «VirtualBox Guest Additions» debemos actualizar a Fedora, ¿cómo es esto posible si lo acamos de instalar?
El obstáculo del asunto es que necesitamos los encabezados «headers» de GNU/Linux para poder compilar los «kerner modules». Esto varía de distribución a distribución, y el cómo se instala depende del instalador por defecto. Así en Debian y sus derivados podemos usar apt pero en Fedora debemos utilizar yum. Para resumir, es simplemente una utilidad que se conecta a repositorios de software bien conocidos (o nuestros preferidos, incluso los desarrollados por nosotros mismos) e instala dicha software.
En cuanto a los derechos de usuario si que tenemos elementos comunes: debemos utilizar el comando sudo. Para ello presionamos ALT+F2 y tecleamos «gnome-terminal» para abrir una ventana de comandos. Luego introducimos la siguiente línea acompañada de nuestra contraseña de usuario para poder tener derechos de administrador o usuario «root»:
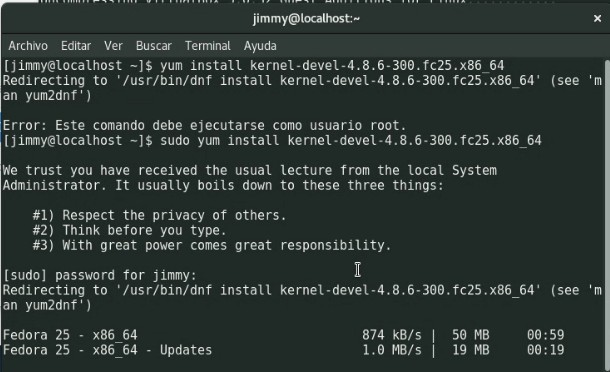
Desde internet descargaremos 50 megabytes -los «headers» en sí- y luego 19 megabytes de actualizaciones, aceptamos la descarga y procedemos a instalarla.
yum install kernel-devel-4.8.9-300.fc25.x86_64 updatesyum install kernel-devel-4.8.9-300.fc25.x86_64 and updates installed
Configurando el «Extension Pack» en la máquina real.
Al momento de emitir este tutorial, nosotros tenemos instalado el VirtualBox versión 5.0.32 y debemos descargar el correspondiente «Extension Pack» y luego «VirtualBox Guest Additions». En este enlace encontraréis TODAS las versiones almacenadas, solo buscad con CONTOL+F en vuestro navegador introduciendo vuestra versión.
En nuestro caso son los siguientes archivos:
«Oracle_VM_VirtualBox_Extension_Pack-5.0.32.vbox-extpack» (19 megabytes aproximadamente, para instalarlo en nuestro ordenador real -sistema operativo anfitrión-).
«virtualbox-5.0_5.0.32-112930~Ubuntu~xenial_amd64.deb» (4 megabytes aproximadamente, para instalarlo en nuestro ordenador real -sistema operativo anfitrión- el «Guest Additions» del lado de la máquina real -anfitrión-).
«VBoxGuestAdditions_5.0.32.iso» (56 megabytes aproximadamente, las «Guest Additions» en sí que le vamos a instalar a Fedora).
SHA256SUMS (5 kilobytes aproximadamente, muy importante comprobar la integridad de los archivos descargados, a pesar que no es una página web segura https).
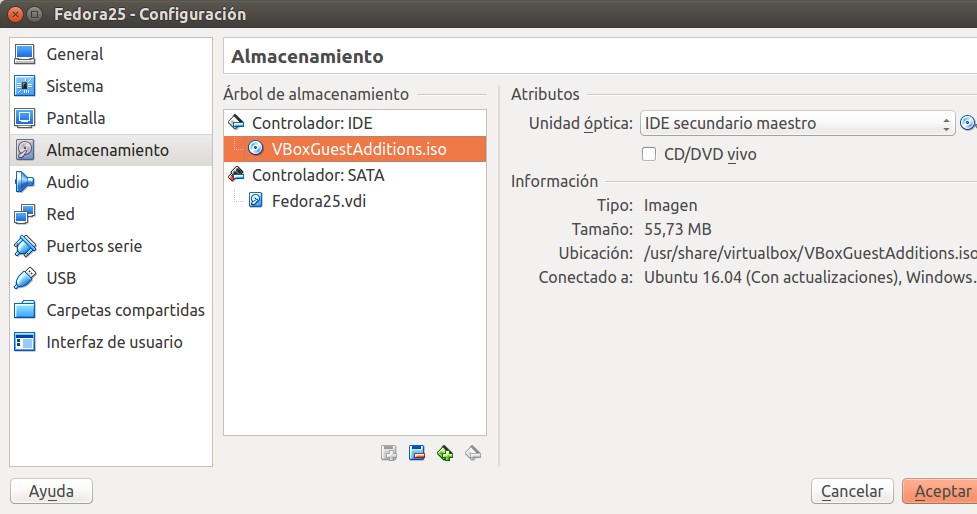
Insertando la imagen iso con «Guest Additions».
Luego seleccionamos en VirtualBox la máquina virtual con Fedora 25 y después abrimos «Configuración» y nos dirijimos a la sección de «Almacenamiento» y abrimos la carpeta donde hayamos alojado la descarga, seleccionamos y damos al botón «Aceptar»:
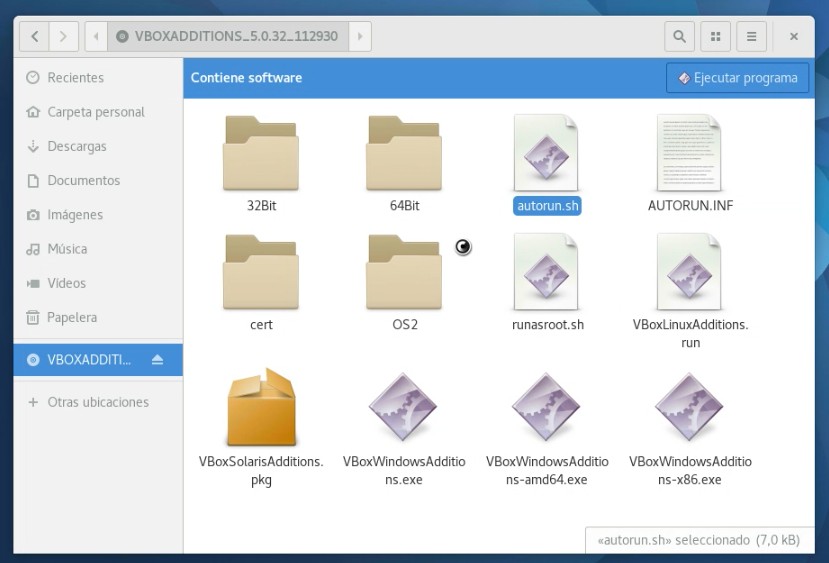
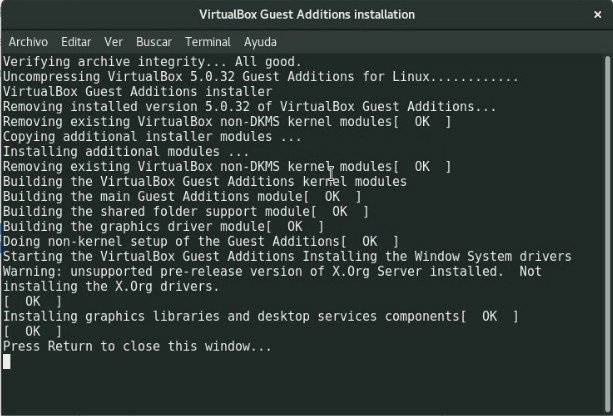
Así iniciamos a Fedora 25 y una vez iniciada nuestra sesión podemos ir al navegador de archivos y abrir la unidad óptica virtual que contiene las «Guest Additions», este sistema operativo incluso trae un botón de ejecutar aplicación o bien podremos abrir una ventana terminal como describimos anteriormente y lanzar el guión script llamado «runasroot.sh«. Es de hacer notar que la vía al cd virtual es «/run/media/su-nombre-de-usuario» para navegar por la ventana terminal.
En este punto ya eliminamos la fastidiosa tarea de presionar siempre la dichosa tecla anfitrión que «captura» el cursor y el puntero entre la máquina real y la máquina virtual.
Para los usuarios que por primera vez utilizan VirtualBox tal vez esta «tontería» sea lo más frustrante: como interactuar entre «ambos mundos», lo cual confunde mucho. Tanto es así que nosotros NO utilizamos la tecla por defecto CONTROL-DERECHO sino que la cambiamos por la tecla F9 que es la que menos conflicto causa con las aplicaciones y los entornos de programación que utilizamos. Sientanse a gusto de cambiarla por la que más le convenga, pero de hecho os decimos que al término de instalar «VirtualBox Guest Additions» su ratón fluirá libremente entre ambas «pantallas» sin problema alguno.
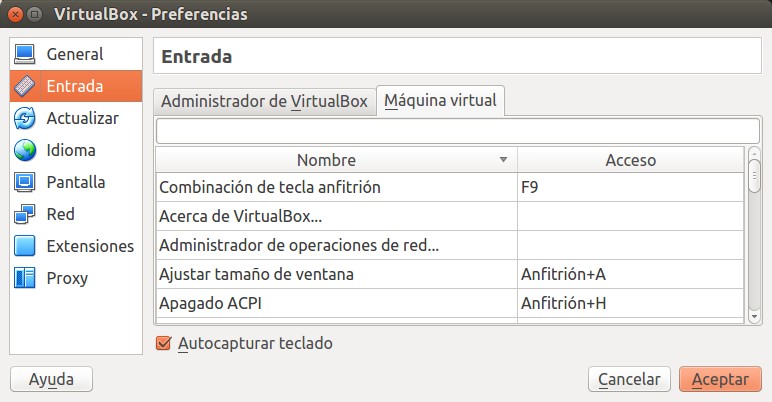
La manera de configurar vuestra tecla anfitrión es por medio del menú «Archivo->Preferencias» o simplemente presionando CONTROL+G y luego seleccionando «Entrada». Una vez allí hacemos click en «tecla anfitrión», sección «acceso»y pulsamos la tecla que más nos guste y después damos «Aceptar» cuando estemos conformes con el cambio.
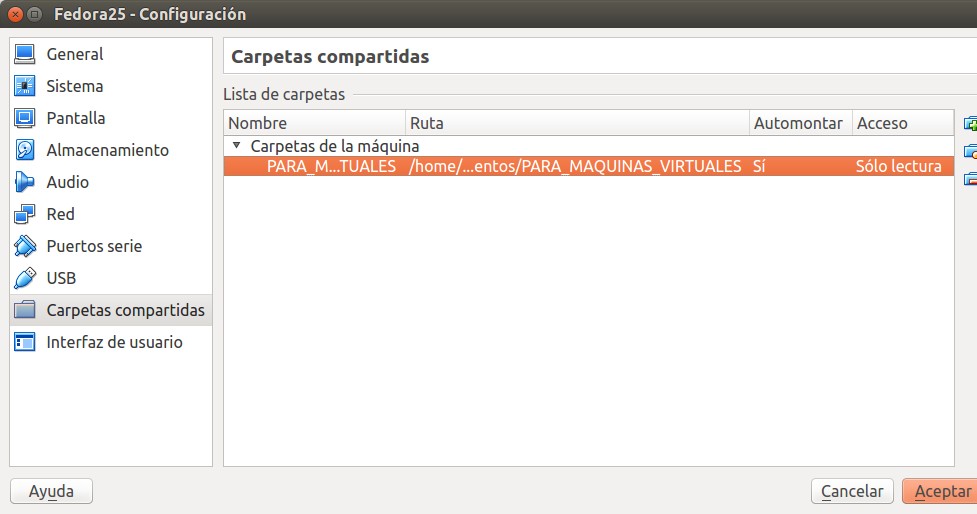
Dicho esto ahora si que procedemos a compartir las carpetas deseadas, de nuevo seleccionamos la máquina virtual Fedora 25, pulsamos configuración y nos vamos a la sección de «Carpetas compartidas» y «clickamos» en adicionar, navegamos por el disco duro de nuestro ordenador, le damos derechos de lectura y escritura y automontar automáticamente, para finalizar «Aceptar».
Siendo pragmáticos, nuestra preferencia es solo compartir una sola carpeta -un un nombre exprofeso para ello «PARA_MAQUINAS_VISTUALES», mirad la figura arriba- para todas nuestros ordenadores virtuales, pero eso ni siquiera a consejo llega; simplemente nos gusta tener todas las cosas de las máquinas virtuales en un solo sitio, nos ayuda a ubicarnos mentalmente y para mayor rapidez.
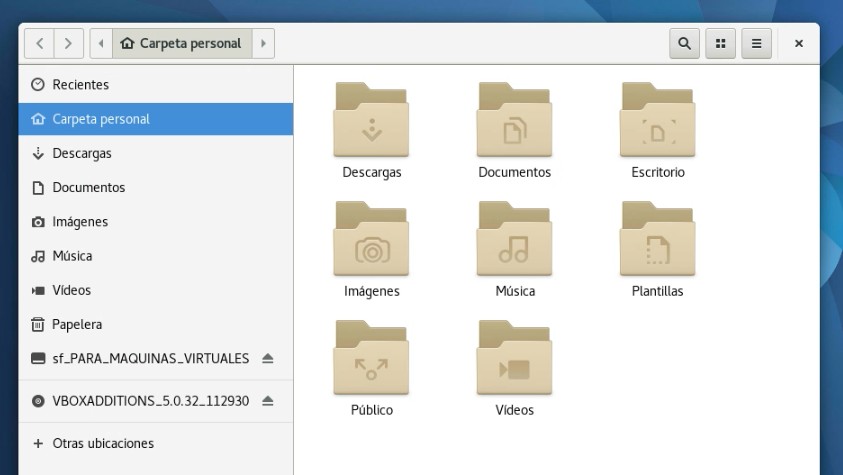
La próxima vez que ingresemos a Fedora 25 virtual, veremos algo parecido a esto en nuestro navegador de archivos:
Las ventajas de las máquinas virtuales son muchas, muchísimas, y acá apenas hemos tocado unas cuantas. El objetivo real en este caso es crear un entorno virtual para instalar Python 3 y desarrollar un ambiente de programación independiente del ordenador que estamos trabajando con solo guardar los archivos necesarios en una unidad de almacenamiento externo y siempre de la mano de VirtualBox.
¡Muchas gracias por vuestra atención, y hasta uan próxima oportunidad, nos vemos!.
En una entrada anterior enseñamos como configurar mod_rewrite en nuestro .htaccess para poner a «punto de caramelo» nuestro Apache2 pero ahora es necesario preveniros de «haber abierto la caja de Pandora»: nuestro servidor web está expuesto a tácticas de intromisión y hasta toma de control por atacantes con malas intenciones. Sirva pues la presente para complementar y ayudaros a proteger vuestros equipos.
Para los que «montamos» páginas web siempre es útil ocultar las extensiones de nuestros archivos a ser servidos y así despistar a posibles atacantes pero es mejor aún para que nuestros usuarios les sea más fácil recordar nuestras secciones e incluso promociones publicitarias, ¿ya tenemos vuestra atención?
El vicepresidente ejecutivo, Aristóbulo Istúriz, estimó que con la incorporación
de la nueva herramienta se apunta hacia la independencia tecnológica del país.
Texto: Romer Viera.
Fotos: Héctor Rattia.
Caracas.
Canaima software libre.
Ministras, ministros y representantes de empresas públicas y privadas que integran el Consejo Nacional de Economía Productiva se reunieron ayer en la sesión número 47 de esta instancia en la que, entre otras cosas, se formalizó el lanzamiento del sistema operativo Canaima GNU/Linux, en su versión 5.0, una creación cien por ciento venezolana, que a decir del vicepresidente ejecutivo, Aristóbulo Istúriz, apunta hacia la independencia tecnológica del país.
El sistema operativo se adapta a las necesidades de los estudiantes y activistas comunitarios.
La reunión se realizó en el salón Ezequiel Zamora del Palacio Blanco de Miraflores, donde Istúriz hizo énfasis en los “distintos mecanismos de dominación utilizados por el imperialismo, entre ellos, los diseñados para crear dependencia tecnológica. En este sentido, recordó el trabajo emprendido por el comandante Hugo Chávez, y continuado por el presidente Nicolás Maduro, para “romper los lazos de dominación” que atan al país a las potencias extranjeras.
Como parte de su disertación, Istúriz precisó el papel que las potencias imperiales del mundo asignan a los países en proceso de desarrollo, a los cuales reconocen solo como generadores de materia prima sin la posibilidad de aumentar sus capacidades industriales y tecnológicas.
Istúriz sostuvo su apreciación sobre lo extraordinario del proyecto Canaima. Sin embargo, manifestó que si hay algo que perfeccionarle es el aspecto relacionado con la divulgación de sus características y bondades.
El lanzamiento se efectuó en el contexto de un encuentro en el que fueron divulgados los avances de 2016 de las carteras ministeriales que integran el consejo. Logros que, de acuerdo con el Vicepresidente, representan “lo que debe ser el salto hacia un nuevo modelo económico y socialista”.
De acuerdo con Kenny Ossa, presidente del Centro Nacional de Tecnologías de Información (CNTI), el sistema operativo Canaima GNU/Linux 5.0 está basado en las plataformas libres más estables y modernas del mundo, como Debian y Linux Mint. Aseveró que es una herramienta que incorpora elementos de orden tecnológico, comunitario y estratégico, con lo que se busca garantizar la seguridad nacional y avanzar en el modelo económico productivo establecido en la Agenda Económica Bolivariana.
El sistema operativo fue diseñado para satisfacer las necesidades de usuarias y usuarios del Programa Canaima Educativo, activistas comunitarios del software libre, servidoras y servidores del sistema público nacional, estudiantes, unidades socioproductivas y personas con discapacidad visual o auditiva, entre otros.
6.517 millones para la reinversión.
Según Ossa, su utilización en todas las instancias del sector de público permitiría un ahorro de hasta 6.517 millones de dólares, capital que a su parecer podría reorientarse hacia el desarrollo tecnológico de la nación. El experto dijo conocer ejemplos sobre cómo, mediante el uso de sistemas operativo no libres, no soberanos, grandes trasnacionales de la computación “han servido a los intereses de los gobiernos extranjeros que apuestan por el fracaso de la Revolución Bolivariana. Al respecto, aseguró que hay pruebas de cómo durante el golpe de Estado petrolero de 2002 se extrajo información de los sistemas de Pdvsa debido a la imposibilidad de auditar los softwares no libres.
Ossa aseguró que Canaima GNU/Linux 5.0 es referencia en el mundo por ser el único proyecto sociotecnológico en el que un Gobierno y comunidades organizadas trabajaron para desarrollarlo y garantizar la independencia tecnológica de una nación. Indicó que las versiones anteriores del sistema son de uso común en escuelas y liceos públicos, en los Centros Bolivarianos de Informática y Telemática (CBIT) e Infocentros de todo el país. También subrayó su utilización en los equipos portátiles.
Entre las características más relevantes de Canaima GNU/Linux 5.0 destacan su interfaz gráfica amigable, estable, segura y totalmente en castellano. Además de su capacidad de utilizar el navegador Firefox, el uso de la suite ofimática Libreoffice y de otros programas como el editor de video Pitivi, el editor de mapas mentales Freemin, el editor de audio Audacity y la herramienta de maquetación Scribus. Por ser una software libre no se requiere pagar por su licencia y no presenta problemas con virus informáticos.
Según información suministrada por el CNTI, actualmente Canaima GNU/Linux 5.0 está operativo en más de 70 mil 870 estaciones de trabajo, de las 125 instituciones que participaron en el censo 2012 de adopción de las tecnologías de información libres.
No, no estamos de osos e hibernación sino de la metáfora entre el comportamiento animal y las computadoras: se trata de «dormir» a la computadora escribiendo todo lo que está en memoria RAM a un área especial en nuestro disco duro, tras lo cual podemos hasta desenchufar nuestro equipo y cuando de nuevo lo necesitemos quedaremos exactamente con los mismos programas y documentos abiertos justo donde los dejamos.
Antecedentes.
En los lejanos tiempos cuando no teníamos interfaz gráfica (podéis saber -o recordar- más en nuestros anteriores artículos sobre bash y sobre ingeniería social) pues tenía poco sentido el hablar de este proceso de hibernación. Pero es que hay más: los equipos XT tenían un simple interruptor que cortaba la energía, apagando de golpe a la computadora y perdiendo datos (ni hablaremos que los discos duros tipo IDE tenían que «parquear» el cabezal para no dañar los platos). Pero con el advenimiento de los equipos AT se incorporó más bien un botón lógico que cuando uno lo presiona el BIOS de la tarjeta madre se comunica con el sistema operativo -moderno- para entonces así poder apagar, cerrando y guardando debidamente los documentos y programas abiertos. Adicionalmente -y esto aplica a los monitores también- se les colocó una función de «dormir» lo cual hace que la máquina trabaje a una velocidad mínima a la espera de un evento determinado -pulso de tecla, movimiento de ratón, mensaje por tarjeta de red, etc.- logrando ahorrar energía. Dicha función se activa automáticamente cada cierto tiempo predeterminado y así se ahorra, a nivel mundial, de muchísima energía eléctrica.
Pero fueron las computadoras portátiles las que más se beneficiaron pues permite alargar el tiempo que trabajan con una sola carga de batería e incluso hay planes más detallados y específicos que poner a «dormir» al equipo: disminuye el brillo en pantalla, deshabilita uno o más núcleos en el CPU (ahora casi todos los equipos son doble núcleo de 64 bits), apagar la red inalámbrica, apagar el disco duro, etc.
En el caso de la hibernación es el ahorro máximo de energía: apagar el equipo para luego encenderlo muy rápidamente y justo donde estabamos trabajando, de paso ahorrando tiempo y como dijimos, se trata de escribir todo lo que está en memoria al disco duro.
¿Por qué Ubuntu no trae la opción de hibernación activada?
Pues ya saben la historia, a las computadoras se les agregó las opciones de «dormir» e «hibernar» para cumplir normas medioambientales (y ahorro en nuestros bolsillos en nuestra factura por consumo de electricidad) pero resulta ser que cada fabricante impuso sus propios «chips» integrados en las tarjetas madres para cumplir dichas funciones. Ellos, para proteger sus «secretos industriales y de manufactura», no explican a ciencia cierta cómo funcionan y son pocos los fabricantes que se dedican a trabajar de la mano con los desarrolladores de sistemas operativos. En el caso de Ubuntu fue a partir de la versión 12.04 que tomaron la salomónica decisión de deshabilitarlo (en Debian viene por defecto activado): son pocos los hardwares que son certificados para trabajar con Ubuntu y la base de datos para llevar cuenta de ellos es gigantesca y engorrosa, un trabajo a todas luces de evitar.
¿Y qué es un hardware certificado para trabajar con Ubuntu?
Pues son ordenadores que garantizan que al hibernar no perderemos absolutamente ninguno de nuestros datos, recordemos que todos los GNU/Linux son sistemas operativos estables y confiables y no se arriesgan a perder su reputación simplemente porque la mayoría de los fabricantes de niegan a vender hardware libre (aunque esto también desaliente a las empresas que trabajen por cerificar su hardware con Ubuntu).
¿Y quienes se benefician del proceso de hibernación?
Pues obviamente los equipos de escritorio y portátiles porque las versiones Ubuntu Server para nada ahorran energía: son equipos que trabajan las 24 horas del día. No obstante el software libre nos permite sin ningún problema el convertir nuestros ordenadores de uso diario como servidores de bases de datos, servidores web, etcétera y si éste es vuestro caso pues olvidad la opción de hibernar.
Requisitos para la hibernación.
Pues antes de entrar más en detalles debemos asegurarnos no sólo que tenemos espacio libre en disco duro del mismo tamaño de nuestra memoria RAM, sino que incluso contemos con una partición de intercambio especialmente hecha para ello, y en inglés recibe el nombre «swap» (no confundir con la partición para archivos temporales). Generalmente si escogimos que nuestra distribución Linux ocupe todo nuestro disco entonces habrá particionado nuestro disco duro con los valores adecuado a nuestro hardware.
Pero si fuimos nosotros quienes decidimos los valores de partición debemos revisar, en todo caso nunca está demás consultar dichos valores así que nos arremangamos las mangas de la camisa y abrimos una venta terminal y escribimos lo siguiente:
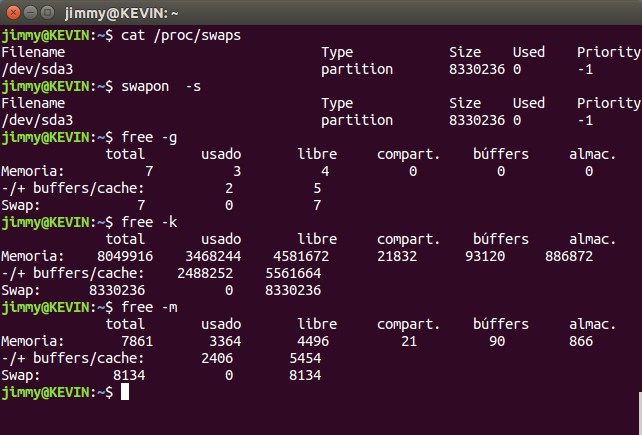
cat /proc/swaps
Como ya sabemos el comando cat sirve para visualizar el contenido de un archivo y en GNU/Linux todo es un archivo (sin caer en el tema de systemd) y la partición de intercambio tiene su archivo que lo representa. El que consultemos un archivo, ya sea por pantalla, impresora, terminal remota, etc. no representa ningún problema para nuestro ordenador, es decir no desconfiguramos nada (lo peor que nos puede pasar es que no tengamos derecho de lectura del archivo en cuestión).
Pero si queremos ir más allá podemos usar el comando swapon el cual está disponible desde 1995 (apareció en 4.0BSD) y forma parte de las utilerías de Linux. Dicho comando ofrece opciones de reporte y la primera que usaremos es:
swapon -s
o en su versión «larga» -que nos permite memorizarla mejor-:
swapon --summary
Esta opción hace exactamente el mismo trabajo de cat que indicamos al principio y así explícitamente lo indica la ayuda de swap (tecleamos «man swap» -y podemos usar el comando man para obetener ayuda de cualquier otro comando de Linux-). Con el comando swapon también podemos activar o descativar el área de intercambio pero exige conocimientos exactos de nuestro hardware para poderlo ejecutar correctamente, recomendamos mucha precaución si se deciden a ir más allá.
Hay muchos otras muchas herramientas (mirad los enlaces consutlados para hacer esta entrada) pero con 3 creemos es más que suficiente en nuestra labor didáctica, dicho tercer comando es free que nos permite ver tanto en Gigabytes, Kilobytes o Megabytes (las letras iniciales son los parámetros del comando) de nuestra memoria física y el área de intercambio -en realidad sirve para la memoria RAM pero como están intimamente relacionadas con el área de intercambio pues se incluye en los resultados-:
free -g
free -k
free -m
Acá mostramos una captura de nuestra ventana terminal:
«cat», «swapon» y «free».
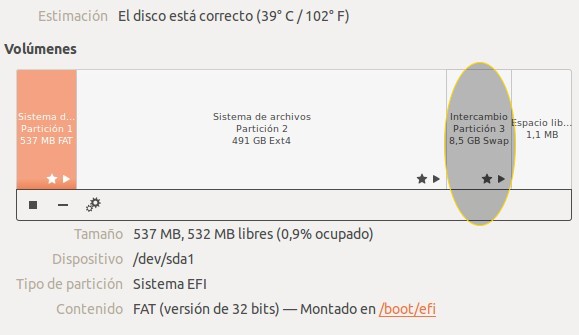
Otra alternativa es utilizar la interfaz gráfica pulsando la tecla ALT+F2 y escribimos (en Ubuntu) «disco» y automáticamente nos listará las aplicaciones debajo de la linea de comandos -si usan Debian escriban palimpsest – y hacemos click en la utilidad de discos, verán algo parecido a esto:
Ubuntu partición de intercambio.
Como vemos también nos informa del estado del disco duro, temperatura etc.
Probando si nuestro equipo es compatible con hibernación.
La manera pragmática de determinar si nuestro equipo soporta el proceso de hibernación es tener unas cuantas aplicaciones abiertas con datos sin importancia (navegador web, gedit editando una nota, algún reproductor de música) tras lo cual ejecutamos en nuestra línea de comandos lo siguiente:
sudo pm-hibernate
Al presionar la tecla intro nuestro ordenador, según la cantidad de aplicaciones abiertas, la cantidad de memoria RAM y tipo de disco duro, tomará de unos cuantos segundos hasta un minuto. Luego de que se hayan apagado todas las luces y ventiladores esperamos unos 10 segundos y procedemos a encender por su correpondiente botón.
Una vez haya arrancado de nuevo verificamos si nuestras aplicaciones de prueba están en pantalla, si suena la música, el estado de conexión de red; puede ser que parpadee la pantalla una o varias veces, movemos el ratón y observamos cuánto tarda en responder.
Si hemos llegado hasta aquí sin problemas…
Pues ¡enhorabuena! Nuestro ordenador es compatible con la hibernación ahora procederemos a habilitarlo y describiremos el proceso general pero cambiaremos los valores de acuerdo a la versión de Ubuntu que tengamos instalado:
Vamos a crear un archivo llamado «com.ubuntu.enable-hibernate.pkla«.
Dicho archivo lo guardaremos en la siguiente ubicación: » /etc/polkit-1/localauthority/50-local.d«
Debemos hacerlo con derechos de usuario raíz o «root» con «sudo su«.
Reinciamos el equipo y verificamos que nos aparezca la opción correspondiente, veremos algo como esto:
Ubuntu botón para hibernar.
Si usamos Ubuntu 13 o anterior:
Procedemos a abrir una ventana terminal y ejecutamos lo siguiente:
y luego rellenamos con esto (sientanse libres de copiar y pegar):
[Re-enable hibernate by default]
Identity=unix-user:*
Action=org.freedesktop.upower.hibernate
ResultActive=yes
Si usamos Ubuntu 14:
Deberemos rellenar el archivo con esto:
[Re-enable hibernate by default in upower]
Identity=unix-user:*
Action=org.freedesktop.upower.hibernate
ResultActive=yes
[Re-enable hibernate by default in logind]
Identity=unix-user:*
Action=org.freedesktop.login1.hibernate;org.freedesktop.login1.hibernate-multiple-sessions
ResultActive=yes
Si tenemos Ubuntu 16:
[Re-enable hibernate by default for login1]
Identity=unix-user:*
Action=org.freedesktop.login1.hibernate
ResultActive=yes
[Re-enable hibernate for multiple users by default in logind]
Identity=unix-user:*
Action=org.freedesktop.login1.hibernate-multiple-sessions
ResultActive=yes
Observaciones importantes del archivo de marras:
Ahora que conocemos el archivo que permite la hibernación hemos de considerar lo siguiente: las lineas que comienzan por «Identity», «Action» y «ResultActive» como bien pueden observar son las mismas para las versiones de Ubuntu lo que si que es diferente son las etiquetas que las encabezan. Es de notar también que el identado es importante para dichas líneas pues son en jerarquía «hijas» de las etiquetas. Además los nombres de las etiquetas son muy específicas para cada versión de Ubuntu, bueno cada cabeza es un mundo e imaginamos que son muchos y diferentes programadores que han trabajado sobre Ubuntu y que siempre debemos tener siempre en mente que en el campo del software libre nada está escrito sobre piedra, es decir: ¿nos molesta que cada versión de Ubuntu tenga sus diferencias particulares de una a otra según las liberan? El software libre nos permite descargar el código fuente, modificarlo y compilarlo para nuestra propia metadistribución, es decir, es el mismo Ubuntu con pequeñas variaciones (pero si dichas variaciones afectan de algún modo o manera a las aplicaciones que se ejecutan debemos compilar también dichas aplicaciones adaptadas y publicar nuestro propio repositorio para nuesta metadistribución ¿A ver quién se anima a trabajar en ello? Hay gente que conozco que lo hacen, ¡tienen mucho esfuerzo y tenacidad en sus convicciones!).
Si tenemos un ordenador portátil.
En las computadoras portátiles al cerrar su tapa, el comportamiento predeterminado es «dormir» o suspender pero podemos cambiar ese comportamiento siempre y cuando hayamos probado varias veces que la hibernación funciona correctamente:
Abrimos una venta terminal e introducimos lo siguiente:
sudo nano /etc/systemd/logind.conf
Buscamos la línea que contiene «#HandleLidSwitch=suspend» y la sustituimos por «HandleLidSwitch=hibernate» (nótese que eliminamos el caracter almohadilla y cambiamos «suspend» por «hibernate».
Guardamos el archivo y reiniciamos.
¿Qué problemas podemos enfrentar?
Actualizado el jueves 10 de noviembre de 2016.
Pues pusimos a hibernar nuestro ordenador y al regresar de nuestro trabajo en la calle encendimos y nos mostraba este mensaje:
Ocurrio un error al montar /boot/efi.
Pulse S para no montar o M para una reparación manual.
Al escoger la opción «no montar» pues acepta contraseña pero al no tener acceso al disco duro pues regresa a la pantalla de inicio de sesión. Al escoger la opción de reparación manual «cae» con credenciales de «root» y al introducir:
sudo apt-get update
no se ejecuta correctamente y sugiere el comando dpkg.
Aplicamos:
sudo dpkg --configure -a
y luego el comando «reboot» tras lo cual arranca correctamente. Suponemos que como tenemos configurada las actualizaciones del sistema operativo como «descargar e instalar automáticamente» pues estaba precisamente en ese proceso cuando la pusimos a hibernar.
Agradecemos a los amables colaboradores de Ubuntu-es.org por proporcionarmos la solución, podéis leer el caso en este enlace web.
Es una poderosa herramienta para el aprendizaje electrónico (o aprendizaje en línea) y, esencialmente, es un sistema de gestión de cursos basados en una interfaz web, ¿suena sencillo, cierto? Pero debajo de esta apariencia está una nueva manera de aprender muy diferente del aprendizaje presencial. Para ir asimilando progresivamente el concepto, primero debemos leer y tener una noción de los que es la Educación a Distancia para luego agregar que Moodle es la herramienta para crear Aulas Virtuales de tal manera que podemos modelar los cursos que queramos impartir a los requerimientos de los participantes y la materia a enseñar. Sin embargo, esta sigue siendo una definición simplista, aún hay mucha tela que cortar al respecto.
La educación en sí misma es toda una ciencia, ardua y difícil. Nuestros respetos hacia esa rama epistemológica, sumo respeto. Acá tocaremos muy superficialmente ese tema, y si ya han leído nuestras muchas otras publicaciones, nos orientamos más hacia lo autodidacta (o como llama el hacker @ChemaAlonso «aprender haciendo» -lo otro es «aprender aprendiendo» dice él-). Esta entrada en nuestro blog vamos a enfocarnos más bien en instalar un servidor VirtualBox con Moodle, configurarlo y usarlo. Finalmente deseamos expresar nuestro agradecimiento a la Licenciada @MarielaLLovera por su breve orientación al tema, ¡muchas gracias!
Directo al grano: Moodle con TurnKey.
La manera más rápida de instalar y poner a funcionar -sin tanto esfuerzo- es ir a la página web de TurnKey Linux en su apartado Moodle. El esquema de negocios de dicha compañía es el servicio: ofrecen alojamiento y respaldos automatizados -y por supuesto cobran por ello- y a cambio nos dan una «api key» que la introducimos en nuestros servidores y nos olvidamos de muchas tareas de mantenimiento lo cual nos libera tiempo para dedicarlo a la administración en sí de Moodle.
La página de descarga de Moodle TurnKey (aproximadamente 297 megabytes al momento de escribir este artículo) utiliza Debian 8 Jessie y se deben descargar las actualizaciones de seguridad no más terminar de instalar el servidor (se puede obviar este paso si nuestro servidor es para pruebas nada más, como es nuestro caso).
Como hoy en día los vídeos están de moda a la hora de enseñar, pues ni cortos ni perezosos hemos subido uno donde mostramos como instalamos y ponemos a punto de uso (fijaos en que los certificados autogenerados SSL para nuestro https saltarán las alarmas en nuestros navegadores web, en nuestros artículos hemos publicado bastante material explicando lo de la seguridad al navegar en páginas web).
Seguimos recalcando que hemos simplificado al máximo la tarea, debajo del capó se esconden no un motor sino varios motores: primero Debian quien sostiene todo, luego Apache2 Web Server con -como lo dijimos- SSL y como motor de base de datos MySQL, el correo electrónico (Postfix), las conexiones SSH, Adminer y por último y por supuesto Moodle (si olvidamos mencionar algún software libre os perdonáis por favor).
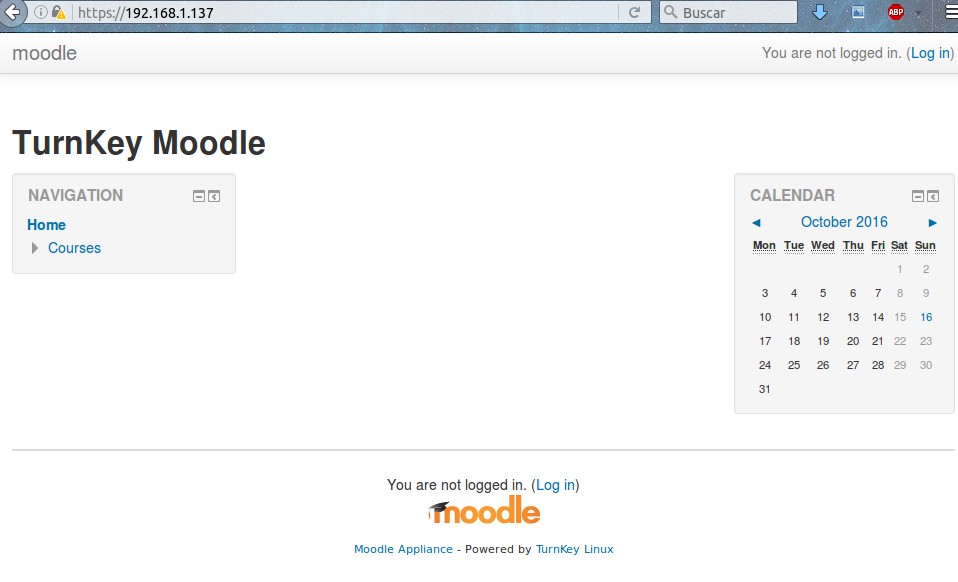
Al finalizar veremos que, para nuestro estudio, nuestro enrutador web de área local nos asignó la dirección 191.168.1.137 adonde podremos navegar y veremos una imagen parecida a esta:
Moodle Turnkey VirtualBox
Como abreboca es más que suficiente, vayamos ahora a profundizar en la materia: historia de Moodle.
Ya os hemos presentado el tutorial básico de ImageMagick el cual permite manipular imágenes en procesos por lotes, pero ha llegado la hora de «desangrar nuestra vena artística» con GIMP. Así como lo leeís, todo en mayúsculas, no nos hemos equivocado ya que GIMP es un acrónimo para «GNU Image Manipulation Program» (o como lo conocemos en castellano llano «Programa de Manipulación de Imágenes de GNU») y como ya sabemos qué es lo que significa GNU pues no nos complicamos más con el humor «nerd» que reina en el Software Libre, lo llamaremos GIMP a secas. Ah, y otra cosa, os vamos a enseñar a nuestro estilo: directo, claro y sencillo, como ya son todas nuestras entradas y tutoriales, «directo al grano» como bien reza el refrán; vamos, pues.
Acerca de GIMP 2.8.10.
Breve historia de GIMP.
Spencer Kimball y Peter Mattis son los padres de la criatura, por allá por 1995 en la Universidad de California, en Berkeley. Vio la luz pública en 1996 y es en 1997 que aprovechando una visita del Gurú Informático Richard Stallman a esa universidad le preguntaron si podían rebautizar la aplicación que ellos habían hecho (la cual se llamaba «General Image Manipulation Program»). Dado que era y estaba hecho bajo la filosofía del Software Libre, he aquí que Stallman dio su aprobación de cambiar «General» por «GNU» y, de paso, formar parte oficial del Proyecto GNU. Es por ello que GIMP nació libre y vive para ser libre su desarrollo.
Aunque surgió en ambiente UNIX, rápidamente fue portado a Linux, SGI IRIX y HP-UX pero allí no paró el asunto. Por increíble que parezca ese mismo año 1997 fue llevado a la plataforma privativa Windows y OS X (Mac) en 32 bits (en aquella época apenas salíamos de los sistemas operativos de 16 bits, nosotros fuimos testigo de eso y nos tocó vivirlo) lo cual fue una gran novedad. La persona que logró esto fue el programador danés Tor M. Lillqvist en la versión 1.1.
GIMP arrancó con un «motor gráfico» llamado Motif hasta la versión 0.6.0 para luego ser sustituido por el «GIMP tool kit» (GTK) hasta llegar hoy en día al GTK+ el cual está orientado a la programación con objetos. Por aclaratoria nada más, nosotros llamamos «motor gráfico» a las diferentes librerías -conjunto de funciones- que permiten olvidarnos del problema de dibujar en pantalla teninedo en cuenta que está adelante o atrás, cual capa es transparente o tiene prioridad sobre otra (ya veremos en el tutorial qué son las capas, paciencia).
La mascota de GIMP es Wilbur y fue creada por Tuomas Kuosmanen (tigert) en 1997 saltando a «la fama» en 2008 en el videojuego de carreras llamado «SuperTuxKart» en el cual salen las mascotas de varios proyectos de software libre y de código abierto. He aquí sus variantes, tomadas de Wikipedia en inglés:
Images of Wilber GIMP’s mascot.
A nosotros particularmente nos gusta la siguiente imagen que incluso usamos como práctica al iniciar nuestro estudio de GIMP:
Para finalizar esta breve descripción de GIMP debemos informaros que actualmente su desarrollo está desarrollado en la plataforma de control de versiones GIT (en este enlace al repositorio podréis, a futuro, ofrecer vuestros aportes de programación, estamos seguros que será así) y aunque por allí se reciben «pull requests» el lugar para hacer sugerencias más abstractas es el Google Summer of Code (GSoC) pero os advertimos que pueden tardar años en llegar a ser incorporados al programa, así es la democracia del Software Libre; no obstante vosotros podéis descargar el código fuente, modificarlo para vuestros propósitos y compilarlo a la medida de vuestro ordenador ¡SOMOS LIBRES, LIBERTAD! 😎 -.
¿Qué es GIMP y qué podemos hacer con él?
GIMP es un programa de edición de imágenes, frecuentemente es comparado con el software privativo «Adobe Photoshop»: hacen prácticamente lo mismo pero hasta allí llegan las semejanzas. Con GIMP podremos reunir imágenes y juntarlas en un único archivo que luego podremos exportar en el formato que necesitemos y hasta incluso páginas web podremos hacer, claro, desde el punto de vista «artístico» claro está.Para lo que NO está orientado en sí es para hacer imágenes, «para pintar» no nos servirá y cuando decimos pintar llamamos al proceso de los artistas de la antigüedad
Dicho formato «.xcf» no es más que un conjunto estructurado de datos en normas de almacenamiento normalizadas y reconocidas (harto conocidos por nosotros los programadores) tales como enteros de 32 bits (WORD), números de punto flotante de simple precisión (FLOAT) y cadenas de texto (STRING) -con la particularidad de que comienzan a su vez con un WORD que indica el número de caracteres más uno, los caracteres en sí y finaliza con un cero -el cual sumamos ya al principio-. Con estos elementos definidos podemos así comenzar a escribir en disco duro un archivo con esta extensión donde guardaremos los siguientes «objetos» (no son objetos como tal pero para que os hagáis una idea): capas «layers», canales «channels» y parásitos «parasites». Éstos «objetos» a su vez tienen su estructura particular pero no vamos a llegar a tanto en este humilde tutorial, allí tenéis los enlaces si queréis estudiar más.
En resumen un archivo .xcf comienza de la siguiente manera:
Los primeros 9 bytes deben comenzar obligatoriamente con el santo y seña siguiente: «gimp xcf «; de no ser así no abre el archivo (dato para los que gustan de hacer virus para herir a los demás).
Los siguientes 4 bytes indican la versión: «file», «v001» o «v002».
Un byte cero que termina la etiqueta de la versión.
Tres bytes de enteros de 32 bits sin signo que indican el ancho, alto y modo de color del lienzo (llamaremos lienzo al área visible donde podremos agregar las imágenes en capas, donde podremos «dibujar»).
Propiedades de imágenes -que tienen su formato que no explicaremos aquí- (con apuntes a cada capa) y terminan con un byte cero.
Propiedades de canales y que terminan con un byte cero.
Estas especificaciones NO deben tomarse al pie de la letra, es sólo un esbozo y sirve como panorama para saber cómo guarda los datos GIMP, si os dedicaís a programar fijaros en el código fuente en GitHub como es exactamente que se debe escribir -y leer- en disco duro el o los archivos que guardemos.
Compilaciones derivadas y suplementos.
Por ser software libre GIMP tiene muchas variantes, osea, personas que toman el código fuente, lo modifican y mejoran -o personalizan, que sería quitarle- y lo compilan y publican. Este proceso se conoce en inglés como «fork», tenedor en castellano imaginamos por la forma que nacen sus dientes de un mismo origen. Por nombrar algunos tenemos las siguientes derivaciones:
CinePaint.
GIMP Classic.
GIMP Portable.
GIMP Photo.
GIMP Shop.
INGIMP.
Seashore.
A su vez GIMP soporta unos suplementos o «extensiones»: por ejemplo GAP (GIMP Animation Pack) para desarrollar animaciones y GPS (GIMP Paint Studio) que permite guardar tareas repetitivas para ser ejecutadas en otros archivos de la misma manera.
Instalación en Debian y sus distribuciones.
Podemos instalar GIMP como siempre, desde la línea de comandos, no sin antes actualizar la lista de paquetes isntalados contra los del neustro repositorio configurado. La toma de pantalla que veís aquí es en Ubuntu 16 y en general es lo mismo para cada distribución basada en Debian:
Iniciando por primera vez GIMP en nuestro ordenador.
Tal como explicamos en nuestro tutorial sobre lineas de comandos, solo tenemos que pulsar las teclas CONTROL+F2 y escribir «gimp» en la caja de texto y presionar la tecla Introducir (intro o enter). Esperamoss a que cargue en memoria y todo depende del ordenador que tengamos (número de núcleso, memoria RAM y memoria de tarjeta de video) puede ir de unos cuantos segundos hasta medio minuto. Una vez ejecutado veremos algo muy similar a esto:
GIMP pantalla de inicio
Lo primero que notamos es que en realidad se abren no una sino tres ventanas a la vez, la cual numeramos en la imagen para mejor comprensión (podéis hacer click en la imagen anterior para agrandar) y las subdivimos de esta manera:
Caja de herramientas.
Opciones de herramientas.
Menú de capas.
Menú de pinceles.
Área donde «dibujaremos» y llamaremos lienzo.
Lo primero que debemos reconocer, incluso para nosotros que programamos ordenadores, es la gran cantidad de botones y menús de GIMP: ¡ES IMPACTANTE! Tomaros unos momentos para que os familiaricéis con la interfaz gráfica del usuario, NO OS APURÉIS tomad las cosas con calma que ya os propondremos una solución.
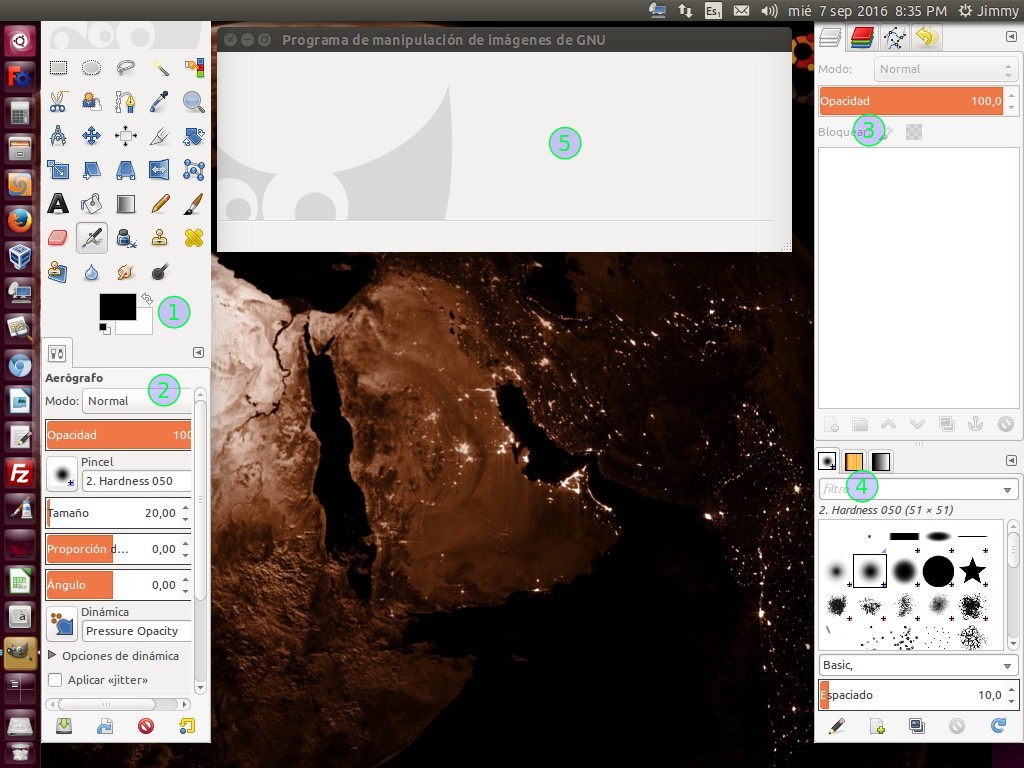
Afortunadamente GIMP tiene una opción en los menús desplegables, bajo «Ventanas» de donde «descolgaremos» el sub menú y pulsaremos sobre «Ventana única», he aquí una captura del menú:
GIMP modo de ventana unica.
Os advertimos que en un monitor normal de hoy en día, un monitor LCD de 17 pulgadas con una resolución nativa de 1024 por 768 píxeles no alcanzaréis a ver todos los menús de GIMP, así que este tutorial lo hicimos con un monitor de ese tamaño el cual es lo bastante popular y ubicuo. Recomendamos un monitor de 22 pulgadas y una tarjeta gráfica con 1 gigabyte de memoria de vídeo para trabajar comodamente.
Como esto va de enseñar y aprender enumeramos los menús principales:
Archivo.
Editar.
Seleccionar.
Vista.
Imagen.
Capa.
Colores.
Herramientas.
Filtros.
Ventanas.
Ayuda.
Es en la décima opción donde podremos hacer click en la opción de «ventana única» y luego veremos algo como lo siguiente:
GIMP venta única con menús numerados
Luego del menú número 9 «se desaparecen» los menús pero en la flecha os indico donde hacer click para ver los restantes y poder seleccionar el comportamiento de «ventana única».
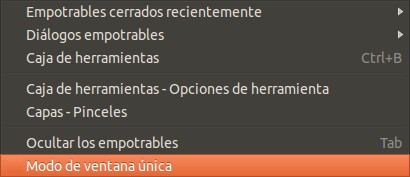
Aún nos falta establecer otra preferencia más para poder trabajar con mayor tranquilidad en GIMP. Para ello hacemos click en el menú 2 «Editar» y luego hacemos click en «Preferencias» (de ahora en adelante usaremos un lenguaje más directo y abreviado: «vamos a Editar->Preferencias» y ya vosotros sabréis que vaís a hacer con vuestro ratón y teclado):
GIMP menú Editar – Preferencias
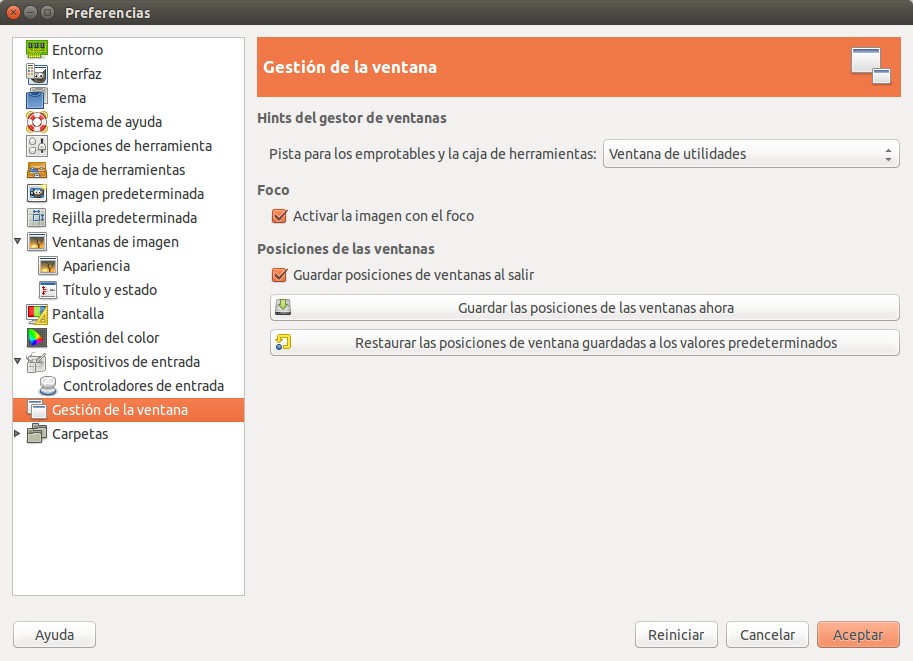
Una vez abierta las preferencias nos vamos a «Gestión de la ventana» y pulsamos el botón «Restaurar las posiciones de ventana guardadas a los valores predeterminados», esto nos dejará a GIMP listo para su uso cada vez que lo necesitemos ya que fácil e inadvertidamente podemos mover y descuadrar la «Caja de herramientas», «Opciones de la Caja de Herramientas», «Menú de capas» y «Menú de pinceles». Una vez hecho esto cerramos a GIMP y lo volvemos a ejecutar para el siguiente paso de nuestro tutorial.
GIMP Preferencias – Gestión de la ventana
NOTA:
Salimos de GIMP con el atajo de teclado, presionamos y mantenemos presionado CONTROL y luego presionamos «Q» (lo cual denotaremos de ahora en adelante como CTRL+Q). Ejecutamos de nuevo GIMP y seleccionamos «Ventana única» -¿otra vez? La práctica hace al maestro, además si observamos la ventana «GIMP Preferencias – Gestión de la ventana» nos aseguramos que esté seleccionado «Guardar posiciones de ventanas al salir» lo cual garantiza que NO tendremos que volver a configurar nuestra distribución de ventanas de GIMP para nuestro trabajo.
Creación de nuestra primera imagen.
Ya al haber iniciado de nuevo a GIMP y sentirnos a gusto con nuestro «entorno de trabajo» procedemos a crear nuestra primera imagen con CTRL+N y se nos muestra el siguiente cuadro de diálogo (lo numeramos para facilitar su comprensión, recordad también el formato .xcf y donde guarda estos valores):
GIMP Crear una imagen nueva
Plantilla: GIMP trae unos tamaños predeterminados para evitarnos la introducción del tamaño de manera manual con los valores más usados. En nuestro caso usaremos un tamaño de papel A4 (norma ISO 216), ampliamente utilizado en Europa, no obstante los que sigaís usando el tamaño imperial podéis usar el tamaño carta que es el que más se le parece (pero no son exactamente el mismo tamaño). Al descolgar el submenú correspondiente podréis ver todos los tamaños disponibles y al escoger uno de ellos se llena automáticamente los valores de anchura, altura y unidades.
Espacio de color: aquí podremos optar por dos opciones, a todo color combinando los colores básicos roo, verde y azul «red green blue RGB» o blanco y negro. por defecto es RGB ya que es la opción más usada.
Rellenar con: podremos escoger «color de frente», «color de fondo» (ambos están en «CAJA DE HERRAMIENTAS» viene preseleccionado negro en frente y blanco en fondo, luego aprenderemos como cambiarlos), «blanco» y «transparencia». La opción «blanco» deviene del color de los lienzos utilizados en la antigüedad cuando se pintaba al óleo y se necestiba una base que resaltara los colores de las pinturas; en este siglo 21 lo que más desarrollamos son páginas web así que haremos una imagen en formato PNG que permite transparencias así que este tutorial lo enfocaremos en ese sentido.
Comentario: pues aquí podremos dejar una nota que nos parezca interesante o relevante, es bueno colocar que la realizamos con GIMP cuando la exportemos a formato PNG llevará ese metadato o etiqueta que los motores de búsqueda web tales como DuckDuckGo o Google utilizarán para indexar nuestro sitio web.
No, no olvidamos la opción de resolución X e Y que indica el número de puntos (píxeles) por pulgada pero dejaremos por defecto la que trae, que es más que suficiente. Para explicar brevemente este punto tomemos cualquier periódico o revista con una lupa y veremos que lo que nos parece un color continuo son simplemente puntitos RGB separados por pequeños espacios y que nuestro cerebro une como si fuera algo «sólido»: mientras más puntitos por unidad de medida más difícil para nosotros notar los puntitos -y se gasta más tinta a la hora de imprimir-. De lo anterior también justificamos lo de la medidad: haremos una imagen que podramos imprimir cómodamente en una hoja de papel dado el caso que nuestros navegantes web deseen imprimir nuestro sitio en internet.
Insertar logotipos.
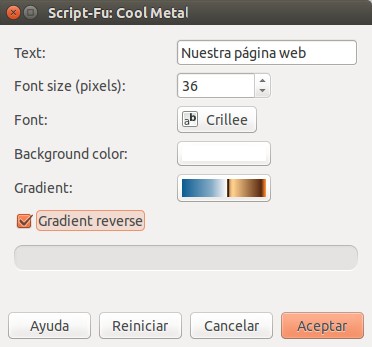
Para nuestro siguiente paso iremos a «Archivo» -> «Crear» -> «Logotipos» y escogeremos «Cool Metal» y le estableceremos los siguientes valores y pulsaremos «Aceptar»:
GIMP Archivo – Crear – Logotipos – Cool Metal (Script-Fu)
Veremos entonces algo aprecido a esto, donde podemos observar que cada «proyecto» que hagamos se nos abre en una pestaña nueva. Le daremos el nombre de proyecto para que tengamos siempre claro que es el formato .xcf que estamos usando, un formato especial de GIMP y que NO será imagen hasta que la exportemos.
GIMP pestañas de proyectos abiertos
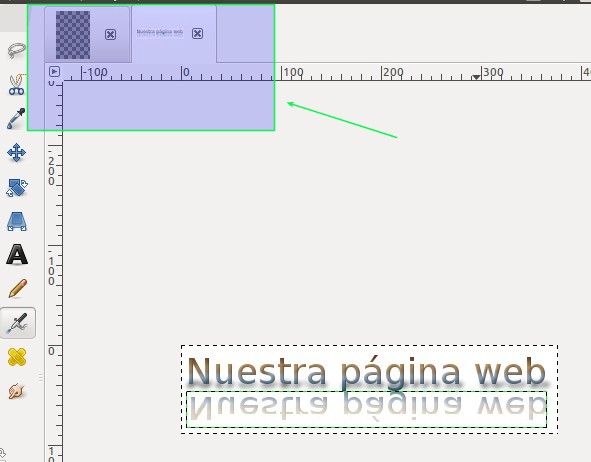
Aún no guardaremos nada en nuestro disco duro, sino que tomaremos el logotipo que acabamos de crear y presionamos CTRL+A y luego CTRL+C, hacemos click en la pestaña donde creamos esta nuestro primer proyecto y hacemos CTRL+V (vamos, que ya lo entendéis bien, es el infame seleccionar todo, copiar y pegar). Como habréis notado el logotipo es bien pequeño en relación con el lienzo de nuestro primer proyecto así que pulsamos SHIFT+T (o vamos a la «caja de herramientas» y hacemos click en «Herramienta de escalado») para que se abra el siguiente cuadro de diálogo:
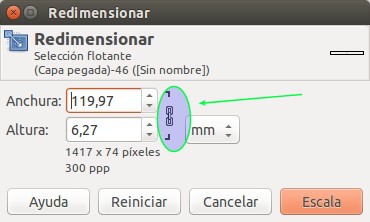
GIMP Redimensionar capa
Muy importante que hagamos click en el ícono de cadena que os resalto en la imagen anterior para que conserve la relación de anchura y altura; colocamos 120 en anchura (la medida en milímetros) y luego pinchamos «Escala» y automáticamente nos cambia el valor a 119,97 ¿recordáis los píxeles por pulgada que escogimos al escoger el tamaño A4? pues bien lo hicimos totalmente a propósito porque como sabéis una pulgada son exactamente 25,4 milímetros así que si dividimos 300 entre 25,4 nos dará una cifra irracional que la podemos redondear a 11,8110 puntos por milímetro y como queremos que mida 120 milímetros pues multiplicamos 11,8110*120=1.417,32 puntos (milímetros se van con milímetro al hacer la divisón) y el problema aquí es que nuestro monitor no nos puede dibujar esa tercera parte -0,32- de un punto o píxel sino que tiene que ser un número entero. De hechos, observamos que automáticamente nos especifica una medida de «1417 x 74 píxeles»: eso es lo que puede y va a dibujar en pantalla. El aprendizaje del asunto es el siguiente: si vamos a usar el sistema métrico internacional, cuya medida es el milímetro todo lo demás debemos especificarlas en milímetros y no en pulgadas como hicimos con lo de la resolución al crear el primer proyecto. Queda como ejercicio para vosotros el crear un nuevo proyecto con una medida A4 y escoger la resolución en «píxeles por milímetro» y repetir todo el procedimiento ¡y os cercionaréis que lo que os enseñanos es correcto!
Otra cosa que ya habréis notado es que lo que hicimos fue REDIMENSIONAR UNA CAPA ¿y en cual momento aprendimos el concepto de capas y el trabajar con ellas? Pues es que GIMP simplemente nos agrega a nuestro proyecto los otros proyectos como capas de manera automática, ésa es la manera que el programa luego contiene uno dentro de otros para guardar los datos en neustro disco duro en formato .xcf.
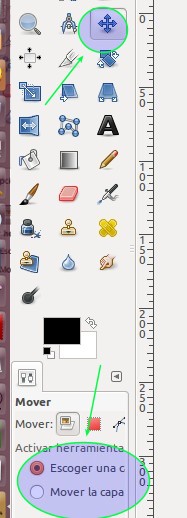
Ahora debemos centrar nuestro logotipo en nuestro proyecto o lienzo, para ello presionamos la tecla M y con las teclas de dirección lo movemos a la posición deseada (sinceramente en este punto es más rápido «arrastar y soltar» por medio del ratón, asimismo con ratón podemos hacer click en el icono con dobles flechas cruzadas y prestad atención que al seleccionarlo se activa en la «caja de opciones de herramienta» donde os recomendamos hacer click en «Mover la capa activa» -esto nos será útil cuando tengamos MUCHAS capas agregadas al proyecto y para poderlas seleccionar rápidamente en «Menú de capas» EXACTAMENTE LA QUE QUERÁIS).
GIMP Herramienta mover y sus opciones
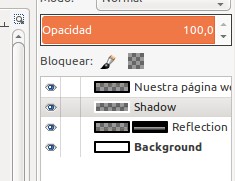
Ahora notamos que en realidad NO ESTÁ NUESTRO LOGOTIPO COMPLETO sino que en realidad lo que hicimos fue copiar una sola capa del mismo (son cuatro capas creadas por el asistente «CoolMetal») y os lo hacemos notar en la siguiente figura:
Cuatro capas de Cool Metal
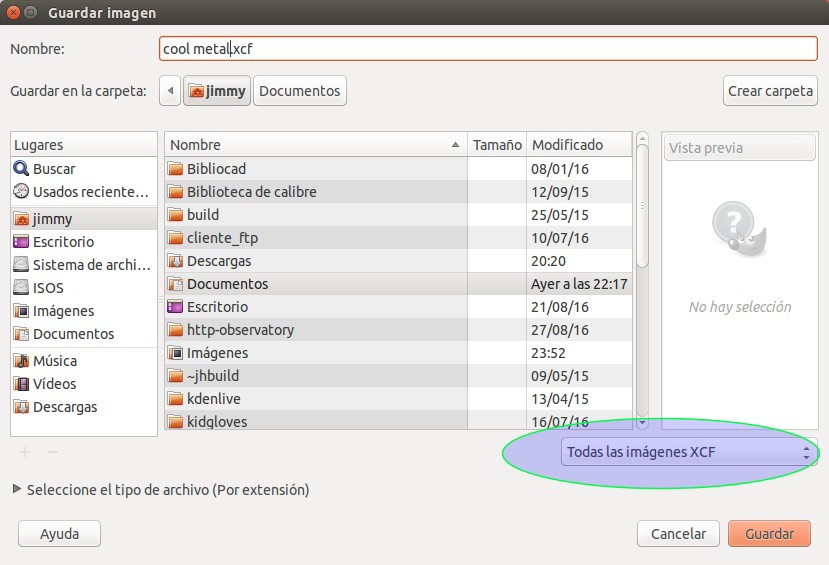
Aunque podemos practicar el copiar y pegar cada una de las capas, el proceso es muy engorroso en verdad. Todo el proceso anterior en realidad nos sirvió como práctica para el siguiente paso que daremos: guardaremos nuestro logotipo «Cool Metal» como archivo .xcf (lo cual nos permitirá a futuro reutilizarlo en otros proyectos y modificarlo si es necesario) para ello presionamos CTRL+S (o vamos al menú «Archivo»->»Guardar» con el ratón) y le colocamos un nombre y escogemos una carpeta Y NOS ASEGURAMOS que escogemos la opción XCF:
GIMP Guardar imagen Cool Metal en formato XCF
Luego haremos click en la pestaña que contiene nuestro primer proyecto (la hoja A4) y presionamos CTRL+ALT+O (una «o» de oso, no un cero),vamos a la carpeta donde guardamos el «cool metal.xcf» y nos aseguramos de seleccionar en tipo de imagen «Todas las imágenes XCF» -como está resaltado en la figura anterior- ¡Y LISTO YA TRAJIMOS LAS CUATRO CAPAS QUE COMPONEN NUESTRO LOGOTIPO!
Un último consejo: dichas cuatro capas para redimensionarlas y moverlas COMO UN SOLO OBJETO primero debemos «encadenarla» haciendo click con el ratón en el ícono de cada una de las capas (aquí no vale método de teclado, se debe hacer con el ratón) ANTES de mover y/o redimensionarlas:
GIMP encadenar las 4 capas de cool metal
Al final os debe quedar algo parecido a lo siguiente:
GIMP Proyecto A4
Pues ya sabéis como guardar, sólo que os recomiendo que le deís el siguiente nombre al archivo: «GIMP Proyecto A4.xcf» ya que más adelante lo utilizaremos de nuevo.
Crear un fondo de pantalla a partir de una fotografía.
Reconocimiento y agradecimiento público.
Agradecemos apliamente al Ingeniero -y profesor- Carlos Ostos por impartir el curso de GIMP donde, por fin, hicimos nuestros pininos en el campo del diseño gráfico.
Curso GIMP Conoce la alternativa LIBRE para la edición de imagen !TOTALMENTE GRATUITO! Valencia – Venezuela pic.twitter.com/aFq8e9hLDP
Asimismo agradecemos al programa gubernamental «Academia de Software Libre» adscrito al Ministerio del Poder Popular para Educación Universitaria, Ciencia y Tecnología, curso realizado en sus instalaciones:
Recientemente tuvimos la estupenda oportunidad de asistir al Congreso de Tecnologías Libres 2016 y tuvimos la necesidad (madre de las invenciones) de publicar las fotografías que capturamos en el evento. En un principio redimensionamos unas pocas para nuestra cuenta Twitter, pero pronto nos dimos cuenta que la tarea es tediosa y debemos aligerar la carga con herramientas del Software Libre. No hace mucho tiempo uno de nuestros faros en GNU/LINUX -en lengua castellana- Ubunlogpublicaron un artículo sobre ImageMagick: instalación y usos básicos del mismo. Pero como nos percatamos que el proceso masivo de 300 imágenes en una sola linea de comando puede «colgar» nuestra computadora por largo tiempo decidimos publicar esta entrada con el valor agregado de nuestros anteriores temas publicados y además unos «scripts» que tal vez les puedan ser útiles a ustedes, amén de la recomendación de un «plugin» para WordPress con el cual escribimos estas líneas a la fecha (quien sabe, tal vez algún día evolucionemos hacia otra plataforma de blogging).
Bien lo retrata en su página web la historia de ImageMagick que pasamos a traducir y resumir, contada en idioma inglés por John Cristy (Principal ImageMagick Architect):
Corría el año de 1987 cuando el Dr. David Pensak, supervisor de John Cristy en la empresa de productos químicos llamada Dupont, le solicitó poder mostrar imágenes de 24 bits (color verdadero) en los nuevos -y costosos- monitores de 256 colores ya que hardware de aquella época tenía muy poca potencia -y por ende debían ser convertidos a 256 colores-. Es por ello que John Cristy utilizó el buscador de moda para ese entonces: Usenet. Obtuvo respuesta de Paul Ravelin donde le indicaba no una, sino varias soluciones de software para la tarea encomendada y puso a su disposición un servidor FTP del «Information Sciences Institute» (ente adscrito a la Universidad del Sur de California) con el código fuente de numerosas aplicaciones. Tras varios años de conseguir muchas de las respuestas, en lo que a computación se refiere, en su trabajo para la empresa Dupont -y el exigente Dr. David Pensak- él se decidió a mejorar y retribuir todo el software utilizado y decidió igualmente liberar las herramientas de procesamiento de imágenes para que otros -¡ejem! nosotros por ejemplo- nos beneficiriamos de ello (de hecho nosotros contribuimos en esta entrada con un «script» en «bash» y otro en lenguaje PHP, así que la historia ¡sigue y sigue!).
Pero como del «dicho al hecho hay enorme trecho» él primero tenía que solicitar permiso a la empresa Dupont en la cual laboraba, ya que en horas de trabajo fue que él desarrolló dichas herramientas. Es así que de nuevo interviene el Dr. David Pensak y convence a sus superiores de otorgar permiso de «copyleft» a John Cristy ya que no era ni un producto químico ni biológico y ellos no tenían noción del valor del software para entonces. Es así que el 1° de agosto de 1990 ImageMagick ve la luz en Usenet en el grupo «comp.archives» (gracias de nuevo Dr. Pensak).
A mediados de los años 1990, y con miles de usuarios en el mundo entero, ImageMagick versión 4.2.9 fue incluido en un nuevo sistema operativo que era distribuido libremente: GNU/Linux.
Es así que luego de su distribución junto a GNU/Linux el sr. Bob Friesenhahn contacta a John Cristy a fin de «normalizar» la aplicación para que sea compatible con el resto de las herramientas de dicho sistema operativo (más adelante veremos que gracias a esto es que hoy en 2016 nosotros podemos desarrollar «scripts» o guiones funcionales y compatibles en otros idiomas de programación).
A partir de la versión 5 de ImageMagick se incorpora de esta manera el lenguaje C++ y se unen al desarrollo los siguientes programadores:
Ya eran decenas de miles de usuarios de ImageMagick cuando sucedió lo impensable: el desarrollo evolucionó tanto que en un momento dado la nueva versión era incompatible con una API existente e hizo que los usuarios reaccionaran bruscamente y exigieron paralizar la programación mientras que los desarrolladores quería seguir adelante. John Cristy no dio su brazo a torcer así que ImageMagick -de la mano de Bob- recibe su primera bifurcación de código y nace Magick++, el primer «fork» (como se conoce en el idioma inglés). Recordemos que precisamente esta es una de las normas de la licencia que rige el software libre, así que John Cristy continuó solo su camino.
Pero no trabajó solo por mucho tiempo: Anthony Thyssen le indicó ciertas fallas en la linea de comandos, los cuales no solo se corrigieron sino que también se mejoraron hasta tal punto que vieron que era necesario emitir una nueva versión: ImageMagick 6.0.
Tan lejos llegaron las librerías de Anthony Thyssen que el mismo John Cristy quedó sorprendido de la capacidad del código fuente original, y que públicamente reconoce la labor hecha en el avance de la colaboración en proyectos de software libre. A continuación, y en honor de quienes contribuyeron (y respetando las normas de la licencia GNU bajo la cual está concebida ImageMagick) nombramos a:
Fred Weinhaus (cientos de «scripts» que son libres para uso no comercial, caso contrario contactar a Fred Weinhaus para su autorización).
ImageMagick tiene ya una edad de 25 años al momento de escribir este artículo, y rumbo a los siguientes 25 años se desarrolló la versión 7.0 con importantes novedades descritas en este enlace web. Además, ustedes pueden encontrar la licencia que rige a ImageMagick en este otro enlace.
Instalación de ImageMagick en Ubuntu.
La instalación es común a las distros GNU/Linux basados en Debian:
Finalmente, para verificar si está correctamente instalado en nuestro ordenador, podemos ejecutar las siguientes lineas de comando con las cuales «crearemos» el logotipo de ImageMagick, visualizaremos sus especificaciones con el comando identify y luego lo abriremos en una ventana gráfica con el comando display:
Al ejecutar el comando display tal vez recibiréis un mensaje un tanto singular: el reporte de unas fuentes de texto faltantes. La explicación rápida es que son fuentes privativas, no libres, y no acompañan a las distribuciones GNU/Linux. Más información en este enlace web.
Tal vez, cuando estéis más avezado o avezada con ImageMagick, necesitareís instalar las librearías avanzadas (una de tantas que existen) con el siguiente comando:
apt-get install graphicsmagick-imagemagick-compat
Como vosotros podéis ver, de primero utilizamos el comando convert el cual pasamos a describir en la siguiente sección.
Comando «convert».
El comando que nos interesa para redimensionar de manera masiva -y a nuestra manera- una gran cantidad de imágenes es el comando «convert«. Específicamente para redimensionar lo acompañamos del argumento «-resize» y de seguido los dos valores de ancho y alto deseados. Sin embargo, debemos conocer un poco más acerca de algunos de los otros argumentos disponibles:
Lo más básico: renombrar imágenes de manera masiva seleccionando un patrón de búsqueda y un prefijo que automáticamente numerará el comando. Por ejemplo si introducimos la orden «convert *.jpg fotos.jpg» ImageMagick renombrará todos los archivos jpg en la carpeta donde estemos ubicados en la linea de comandos de la siguiente manera: foto-1.jpg , foto-2.jpg , foto-3.jpg , etc.
Ya vimos cómo renombrar masivamente un grupo de imágenes pero para convertir una sola solo debemos, desde luego, indicarle su nombre específico, y si queremos o necesitamos, otro nombre específico de salida para mantener el original; es decir, si omitimos el segundo nombre ImageMagick reemplazará el archivo de imagen original -cuidado con esto-. Las siguientes opciones soportan ambas maneras en este párrafo descritas y renombran masivamente según el párrafo anterior.
Para rotar una imagen utilizamos el argumento «-rotate» seguido del ángulo a rotar, por ejemplo «convert imagen.jpg -rotate 90 nueva_imagen_rotada.jpg«.
Si queremos convertir a otro formato de archivo simplemente especificamos el o los archivos deseados acompañado del nombre con la extensión deseada. Por ejemplo «convert imagen.jpg imagen.png» o si queremos convertir todas las imágenes jpg en una carpeta: «convert *.jpg imagen.png» (recordad que ImageMagick agregará un sufijo numerado a cada archivo convertido: imagen-1.png , imagen-2.png , imagen-3.png , etc.)
También podemos bajarle calidad a una imagen utilizando el argumento «-quality» acompañado del porcentaje deseado -formato jpg-.
Si necesitamos redimensionar utilizamos, por ejemplo, «convert imagen.jpg -resize 1024×768» con lo cual obtendremos una imagen de tamaño 1024 píxeles de ancho por 768 píxeles de alto sin conservar el archivo original. Para obtener un archivo nuevo (otro ejemplo) emplearíamos «convert imagen.jpg -resize 1024×768 imagen_redimensionada.jpg«.
Por último podemos combinar los diferentes argumentos, teniendo en cuenta el problema con el que nosotros nos tropezamos: el redimensionamiento masivo de imágenes puede hacer que nuestro ordenador quede bloqueado durante un buen tiempo, por eso decidimos utilizar un «script» que procesa uno a uno cada archivo.
Actualizado el miércoles 18 de septiembre de 2019: el comando convert es compatible con gif animados como el siguiente que rotamos 180° para mostrar el signo de interrogación de apertura:
Signo de interrogación, apertura
Uso de ImageMagick en un «bash script».
Ya en una entrada anterior hablamos procesar una serie de imágenes y aplicarle Reconocimiento óptico de caracteres con el programa Tesseract y vamos a reutilizar el «script bash» o proceso por lotes allí muy bien explicado, así que si os gusta id, leedlo y volved.
#!/bin/sh
####Licencia de uso###
# Copyright 2016 Jimmy Olano at ks7000.net.ve
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
######################
patron="P*.JPG"
nomarch="lista.txt"
clear
ls $patron > $nomarch
while read linea
do
echo "Procesando "$linea
convert $linea -resize 1024x768 $linea
echo "aplicando logotipo a "$linea
php funde_logo.php $linea
rm $linea
done <$nomarch
rm $nomarch
echo "Trabajo terminado, imagenes redimensionadas e insertadas con logotipo."
Como veís publicamos de una buena vez el script y pasamos a describirlo linea por linea para su rápida comprensión:
En la línea N° 1 especificamos que es un archivo de procesos por lotes.
De la línea 2 a la 16 le establecemos la licencia Apache la cual es adecuada para pequeños proyectos y así garantizamos legalmente que nuestro trabajo se podrá seguir compartiendo y ampliando con el tiempo y se impedirá la creación de patentes hechas a base del mismo.
En la línea 17, entre paréntesis, colocamos el patrón de archivos a buscar para redimensionar. Nosotros utilizamos «P*.JPG» por nuestra cámara marca Panasonic que le agrega ese prefijo seguido de una numeración única y consecutiva.
Línea 18: asignamos el nombre del archivo donde guardaremos los nombres de los archivos a redimensionar. Nota: de hecho sabemos que hay una estructura alterna más eficiente para procesar archivos: «for file in *.png; do comando; done», la idea de utilizar un archivo auxiliar es para, a futuro, poder llevar auditoría o registro de los archivos modificados. Es así que podemos, por ejemplo, cambiar el nombre de «lista.txt» a «archivos_redimensionados_dia_mes_año.log» por la extensión utilizada en inglés para el verbo «to log» o registrar o llevar un registro.
En la línea 19 limpiamos la consola para legibilidad en la ejecución de la tarea.
En la línea 20 buscamos los archivos que cumplan con el patrón de búsqueda de la línea 17 y guardamos sus nombres -para posterior uso- en el archivo nombrado de la línea 18.
De la línea 22 a la 28 se encuentra el ciclo o rutina principal deseado. En la línea 20 borramos -a menos que debamos hacer auditoría- (ver explicación de la línea 18). Con la línea 21 notificamos al usuario que la tarea ha finalizado (más sin embargo no llevamos una variable lógica -verdadero o falso- con los resultados de cada uno de los comando ejectuados, es susceptible de ser emjorado). A continuación mostramos las líneas debidamentes numeradas, trabajo hecho y alojado cortesía de Github:
Ahora pasamos a describir la rutina principal:
En la línea 21 comenzamos a leer el archivo «lista.txt» el cual contiene los nombres de los archivos con los cuales trabajaremos.
Entre la línea 21 y 28 establecemos el ciclo que se ejecutará hasta que hallamos leído de manera secuencial todos y cada uno de los nombres almacenados.
En la línea 23 le indicamos al usuari sobre cual archivo vamos procesando.
Línea 24: aquí es donde utilizaremos a imageMagick con la variable «$linea» que contiene el archivo que redimensionaremos (ver línea 23). Usamos el argumento «-resize» para obtener una imagen de 1024 por 768 píxeles reemplazando el archivo original.
Línea 26: llamamos a un «script» o guión en lenguaje PHP. Lo explicaremos en la sección siguiente, pero os adelanto que de allí obtendremos un archivo totalmente nuevo.
Línea 27: borramos el archivo original a fin de ahorrar en espacio en disco (no, no importa si ya tenemos discos duros con decenas de terabytes: cuando montamos un servidor web que reciba decenas de miles o incluso millones de visitas el ahorro de espacio en disco en muy importante).
Uso de PHP en un guión o archivo de proceso por lotes.
Aunque a la fecha no hemos escrito un tutorial sobre lenguaje PHP podemos adelantar que es un lenguaje de proceso por lotes de lado del servidor lo cual lo convierte en una poderosa herramienta para realizar páginas web de manera dinámica e interactiva con el usuario.
Ya vimos cómo con el lenguaje de marcación HTML5 podemos «escribir» o hacer páginas web pero limitadas a presentar siempre el mismo aspecto, y para cambiarlo debemos tomar el archivo, editarlo y guardarlo para, por ejemplo, agregar una nueva imagen o texto a nuestra web. Con el lenguaje PHP podremos, mediante un guión -con extensión .php- insertar comandos que responden a variables para, por ejemplo, mostrar diferentes logotipos según el tamaño de pantalla del dispositivo con la cual visitan nuestra página e incluso conectarnos a una base de datos para extraer texto, imágenes o cualquier otra información allí almacenada y así «personalizar» nuestro portal web. Es por ello que se habla de «páginas web estáticas» y «páginas web dinámicas»: con PHP obtenemos HTML según lo que necesitemos exhibir de acuerdo a variables de tiempo o valores específicos.
De hecho, el lenguaje con que funciona este blog está escrito en PHP y al conjunto de guiones -o procesos por lote- se denomina WordPress y estas líneas están guardadas en una base de datos MySQL. Hay muchísimos tutoriales sobre lenguaje PHP que podéis buscar con DuckDuckGo así que no profundizaremos demasiado en esta presentación pero es necesario que para continuar nuestra enseñanza visitéis, leed y comprended nuestra entrada sobre creación de imágenes CAPTCHA ya que las librerías que utilizaremos son las mismas. Y no os preocupéis, no vamos a montar un servidor web en el estricto sentido de la palabra, pero si usaremos elementos que se usan de manera común en ellos pero con la novedad de que lo ejecutaremos con la línea de comandos.
Línea de comandos en PHP.
En el sitio web oficial de PHP se describe detalladamente el uso de archivos PHP en una ventana terminal (linea de comandos). Allí detallan que hay tres maneras de ejecutar archivos con contenido PHP (no necesariamente con extensión «.php») desde la línea de comandos:
Decirle a PHP que ejecute un archivo específico, por ejemplo «php archivo.php».
Decirle a PHP que ejecute lo que a continuación se escribe, siempre colocandolo entre comillas simples, por ejemplo «php -r ‘$algo=4; print_r($algo);’».
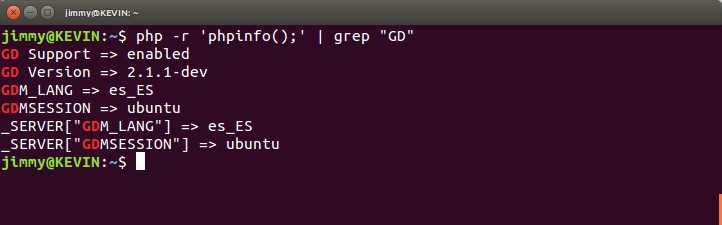
Concatenar comandos «bash» con el símbolo de tubería «|», eso en GNU/Linux es llamado standard input (stdin), por ejemplo «php -r ‘phpinfo();’ | grep «GD»»
En la tercera opción colocamos un ejemplo para conocer si tenemos instaladas las librerías GD necesarias para nuestro caso: insertar un logo en todos de cada una de las imágenes que deseamos redimensionar. Al ejecutarlo podremos ver algo como esto:
php -r ‘phpinfo();’ | grep «GD»
Buscamos que «GD Support» esté habilitado, «enabled»; caso contrario debemos instalarlo con la siguiente orden:
sudo apt-get install php5-gd
Asimismo se indica que se le pueden pasar argumentos dados al ejecutar un guión PHP invocandolos dentro del guión con el comando «$argv[]». Se debe colocar entre corchetes el número de argumento en el mismo orden que se escribe en la línea de comandos, haciendo la salvedad que $argv[0] siempre será el nombre del archivo que contiene las instrucciones en lenguaje PHP.
Veamos unos sencillos ejemplos:
Creamos un archivo php con el siguiente contenido:
<?php
print_r($argv[0])
?>
Luego llamamos al script con la siguiente orden «php archivo.php»
Por pantalla veremos algo parecido a esto:
php archivo.php
Explicación de nuestro bash en PHP.
Como ya estudiamos de manera resumida y rápida el uso de la línea de comandos con guiones PHP, a continuación mostramos de manera numerada -cortesía de Github- el archivo de proceso por lotes «funde_logo.php«:
Y describimos línea por línea su funcionamiento:
En la línea 1 declaramos que usaremos el lenguaje PHP entre esta línea y la línea 46 (para este caso todo el archivo).
De la línea 2 a la 27 insertamos las licencias de uso, son dos porque la primera aplica al guión en sí, su código fuente, y la segunda para indicar que estamos utilizando código escrito en PHP que de por sí tiene su propia licencia de uso.
En las líneas 28~30 insertamos un comentario sobre lo que realizaremos.
En la línea 31 cargamos el archivo que recibimos desde el primera argumento externo (argumento externo) al guión mediante el comando imagecreatefromjpegen la variable $destino .
En las líneas 32~33 insertamos comentarios adicionales.
En la línea 34 cargamos el archivo de imagen (que contiene el logotipo deseado en la imagen redimensionada creada con anterioridad fuera del guión PHP) en la variable $origen.
Líneas 35 y 36 más comentarios.
En la línea 37 se hace el trabajo principal: insertamos el logotipo en la imagen con el comando imagecopymerge. Este comando merece una explicación detallada a continuación.
El comando imagecopymerge tiene los siguientes argumentos:
El nombre del archivo que le insertaremos el logotipo.
El nombre del archivo del logotipo.
La coordenada X donde insertaremos el logotipo en la imagen.
La coordenada Y donde insertaremos el logotipo en la imagen.
La coordenada X del logotipo en si mismo.
La coordenada Y del logotipo en si mismo.
La anchura deseada del logotipo.
La altura deseada del logotipo.
El porcentaje de transparencia del logotipo: 100 es completamente opaco, no se mostrará nada el archivo original en el logotipo insertado
Líneas 38 a 40: comentarios.
Línea 41: preparamos lo que tenemos en memoria para volcarlo al disco duro con el comando imagejpeg con los argumentos siguientes: la variable $destino (a la cual le insertamos el logotipo), el nombre con el que queremos guardar el archivo (un prefijo llamado «CTL2016-» junto al nombre del archivo original pasado por el argumento externo al script PHP) y, por último, el nivel de calidad deseado, en este caso un 80%.
Líneas 42, 43, comentarios.
Líneas 44 y 45 liberamos la memoria donde almacenamos las imágenes.
Debemos aclarar que para saber las coordenadas donde insertaremos el logotipo, pues simplemente abrimos una de las fotografías tomadas con el software Pinta, luego abrimos el logotipo con el mismo programa en otra ventana, seleccionamos todo y copiamos, volvemos a la primera venta y pegamos y arrastramos a la posición deseada y tomamos nota de las coordenadas, hágase según arte como dicen en farmacia.
En cuanto a las coordenadas del logotipo pues sencillamente es TODO: de [0, 0] hasta [370, 150] : el ancho y alto total del mismo.
El comando «mogrify».
Uno de nuestros «faros» en el mundo específico de Ubuntu es la página web Ubunlog.com quienes publicaron un mini tutorial con otro comando de ImageMagick: el comando mogrify.
Podéis ir a ese sitio web y leer (y aprender) sobre ese otro comando que nos permite redimensionar de manera masiva nuestras imágenes. Un detalle que notamos con este comando es que podemos redimensionar a cualquier tamaño específico pero si queremos -o necesitamos- que la imagen se ajuste (encoja y alargue, según sea el caso) debemos acompañar del signo de cierre de admiración para denotar esto. Es una ligera diferencia, he aquí un ejemplo de cada uno de los dos comandos:
mogrify -resize 800x200! prueba.jpg
El comando redimensionará exactamente a 800 píxeles de ancho por 200 píxeles de alto y la imagen se expandirá (en nuestro caso nuestra imagen original era de 3504×2332 píxeles) en ambas direcciones, por lo que se verá deformada.
mogrify -resize 800x200 prueba.jpg
En este caso NO utilizamos el signo de cierre de admiración (con la misma imagen de 3504×2332 píxeles) y al ejecutar el comando anterior nos produce una imagen de 201×200 píxeles lo cual respeta la relación ancho contra altura de la imagen original.
Converseen: interfaz gráfica basada en ImageMagick.
Como ImageMagick es Software Libre y está escrito en lenguaje C, el equipo de programación de fasterland.net en la persona de Francesco Mondello, sacaron partido de esto y desarrollaron una interfaz gráfica para otros sistemas operativos, con ustedes un bonito vídeo de presentación de Converseen:
Converseen, thanks to ImageMagick, the powerful image manipulation library on which the program leans it’s basis, can supports more than 100 image formats including DPX, EXR, GIF, JPEG, JPEG-2000, PhotoCD, PNG, Postscript, SVG, TIFF and many others. Converseen is very easy to use, it’s designed to be fast, practical and, overall, you can get it for free!
Converseen incluso va más allá y le da valor agregado al permitir convertir un archivo en formato pdf en una serie de imágenes (por ahora desconocemos si las utilerías para manejar archivos en formato pertenecen a ImageMagick y por eso decimos que es un valor agregado):
Como podéis observar, Converseen PERMITE redimensionar de manera masiva las imágenes de una o varias carpetas e incluso ofrece una vista previa, prefijo para nombres de archivos (y ubicarlos en otra carpeta) y mucho más, ¡es como una navaja suiza!
Por último en esta sección, os dejamos el vídeo tutorial sobre cómo instalarlo en Ubuntu y el enlace hacia la propia página web del autor donde publica una entrada al respecto:
A nosotros en lo particular nos encanta la línea de comandos, donde para instalar Converseen solo debemos introducir estas dos sentencias (puede tardar algo de tiempo, dependiendo de su velocidad de descarga de internet):
Aunque esta parte es algo más avanzada para este humilde tutorial, dado lo delicado del asunto procedemos a explicarlo «en cristiano» o en castellano llano para que lo tengáis presente y trataremos de explicarlo lo más simple posible.
Como mencionamos ImageMagick está ampliamente extendido del mundo Unix de donde nació y tal como lo relatamos lo incorporaron a Linux y otros sistemas operativos. Pero bajo linux la potencia de ImageMagick se elevó a nivel tal que se usa mucho en servidores web con ayuda de otros lenguajes tales como (no limitados y/o combinados) HTML, PHP, PYTHON, etc.
He aquí que hay páginas web que ofrecen herramientas de edición y/o creación de imágenes a los usuarios. De hecho nosotros aprovechamos el código existente para crear CAPTCHAS para distintas páginas web de nuestros clientes (de nuevo, humildemente desarrolladas). En este caso es bastante seguro la creación de imágenes con PHP y sus librerías pero con ImageMagick hasta podemos permitir que nuestros usuarios web «suban» imágenes a nuestro servidor y allí es donde radica el problema.
Si un atacante malicioso -o no- subiera una imágen con código embebido meticulosamente manipulado para tal efecto al aplicarle el comando convert que estudiamos permite ejecutar el comando «infectado» en la línea de comandos.
El caso está ampliamente documentado en el siguiente enlace, pero no pudimos reproducir el comportamiento del fallo esperado porque regularmente mantenemos actualizados nuestros equipos a los repositorios oficiales.
Convertir una imagen PNG en SVG
Actualizado el día domingo 2 de diciembre de 2018
En esta oportunidad tuvimos la necesidad de convertir un hermoso gráfico con la arquitectura de funcionamiento de un popular sistema de monitorización, OpenNMS e intentamos con varias páginas web que prometen «villas y castillos» pero los resultados fueron pésimos.
«Si quieres que se haga bien, hágalo usted mismo» así que investigando conseguimos que se puede lograr convertir primero la imagen de PNG a PNM y luego con otro programa de PNM a SVG. para la primera tarea ¡cómo no! ImageMagick:
convert archivo.png archivo.pnm # PNG a PNM
potrace archivo.pnm -s -o archivo.svg # PNM a SVG
El resultado es el mismo pésimo trabajo que obtuvimos en línea, pero al menos no dependemos de terceros para futuras labores, esperamos sea útil a alguien en la red.

 Esta entrada no pretende ser una guía exhaustiva de Python ni tampoco algo avanzado en el campo de la inteligencia artificial, apenas es la presentación de todo aquello, un abrebocas: primero estableceremos un entorno de programación y luego ejecutaremos un mini curso de 14 lecciones sobre «machine learning» cuyo material es proporcionado al mundo entero por el Dr. Jason Brownlee en su página web (en idioma inglés).
Esta entrada no pretende ser una guía exhaustiva de Python ni tampoco algo avanzado en el campo de la inteligencia artificial, apenas es la presentación de todo aquello, un abrebocas: primero estableceremos un entorno de programación y luego ejecutaremos un mini curso de 14 lecciones sobre «machine learning» cuyo material es proporcionado al mundo entero por el Dr. Jason Brownlee en su página web (en idioma inglés).