El día de ayer por medio del perfil de línea de tiempo del Doctor Juan González observamos el interesante artículo tutorial sobre Python publicado por Juan J. Merelo Guervós el cual incluye retos de programación. Ni tardo ni perezoso, a pesar de llegar cansado a mi hogar, y tras una vigorizante taza de café negro con leche de avena sin azúcar nos dimos a la tarea de practicar algunas cositas para mantener el cerebro en forma y al día con las novedades en programación.
Para abrir el mes de junio seguimos el hilo en nuestros artículos que buscan difundir el conocimiento libre del Patrimonio Tecnológico de la Humanidad. En anterior oportunidad estudiamosPHP curl, una herramienta basada en cURL y por ende en libcurl (¡ea, esto último no lo mencionamos allá!). Como en ese caso obtuvimos un método para descargar páginas web enteras, incluso si hay que pasarle datos con el método POST y/o hay que introducir usuario y contraseña. Esta entrada busca extraer, analizar e incluso modificar dichos datos ¡vente con nosotros!
Suena incoherente: usamos curl en nuestra línea de comandos frecuentemente para diversidad de tareas pero no sabíamos que el lenguaje PHP tiene su propia versión llamada, cómo no, curl. El asunto es cómo se implementa y qué podemos hacer, nosotros en la línea de comandos lo acompañamos en el trabajo con grep pero en PHP la cosa es un poco diferente, ¡vamos a averiguar cómo!
Introducción.
Exactamente cómo implementaron cURL en PHP no lo sabemos, tal vez PHP haga llamado directo al curl y recoja sus resultados, sirviendo entonces como intermediario solamente… No tiene sentido pero si analizamos que muchos sitios web compartidos con otros dominios tienen PHP pero a uno no lo dejan ingresar por la línea de comandos entonces ¡vaya que si vale la pena el trabajo intermedio!
Por otra parte puede ser que especulamos demasiado y los buenos desarrolladores de PHP tienen su propia versión… ¡pero recordad que trabajamos con Software Libre que permite la modificación y reutilización del código! Pero echemos una leve ojeada al comando curl.
Comando curl.
Ya sabemos como va es esto del software libre: hay más de 1400 colaboradores en curl y el proyecto está alojado en GitHub desde el año 2010; aceptan contribuciones bajo la forma de «pull requests»: en resumen uno copia y trabaja con esa copia privada modificandola -y mejorandola, por supuesto- y devolviendo el trabajo al original para su aprobación. No se garantiza que se acepte toda la propuesta, e incluso ellos podrán tomar ciertas cosas propuestas y otras no, o en el mejor de los casos todo vaya bien y nos convirtamos en el colaborador 1401… y así haremos nuestra contribución al Patrimonio Tecnológico de la Humanidad.
Pero ¿quiénes desarrollan curl? Daniel Stenberg -sueco, habitante de Estocolmo- es el principal desarrollador y comenzó el proyecto por allá en 1996 basado en el trabajo de un programador brasileño llamado Rafael Sagula. Esta sencilla herramienta herramienta carioca fue bautizada como httpget con unas cuantas centenares de líneas y Stenberg las amplió para liberarla en 1997 con el nuevo nombre de «HTTP proxy support». Pero con el advenimiento de «nuevos» protocolos al proyecto tales como GOPHER y FTP pronto dejó de tomar sentido llamarlo solamente «HTTP»… así que ese mismo año vio la luz la versión número dos.
Para 1998 más protocolos y capacidades fueron agregados así que volvió a cambiar de nombre para la versión 4.0 -manteniendo la numeración de versiones- así que el 20 de marzo de ese año marca el nacimiento formal de curl. El nuevo nombre hace alusión al programa del lado del cliente, de allí la letra «c» inicial. Las otras tres letras os lo podéis imaginar ya: Uniform Resource Locator -URL- o Localizador de Recursos Normalizados.
El mismo Stenberg reconoce que hay muchos proyectos con el mismo nombre curl pero para la época que ellos lanzaron la versión cuatro no había (o conocían) de otros proyectos con el mismo nombre. Es por ello que nosotros al principio especulamos del origen de curl en el lenguaje PHP, pero es que ¡Incluso existe un curl desarrollado en software privativo! (no le haremos publicidad pues no nos pagan por ello, buscadlo vosotros mismos con DuckDuckGo). Tan famoso es que ya se considera como verbo en idioma inglés y muchos creen que es un protocolo pues lo tratan como tal pero ya sabemos que en realidad es una navaja suiza con muchísimas funciones.
curl para la línea de comandos.
En principio el comando curl fue desarrollado para scripts ya que sus entradas y salidas utilizan las ya famosas stdin y stdout. No ampliaremos más porque en este blog hallaréis información sobre su uso con la línea de comandos. El artículo que motivó la publicación de esta entrada está en el siguiente «tuit» y precisamente es para la línea de comandos -y pretendemos que corra en PHP curl-:
A partir del año 2000 fueron desarrolladas, o mejor dicho, el código existente fue migrado completamente como librerías y a partir de allí se le hizo una interfaz de usuario para la línea de comandos. Está escrito en lenguaje C y aún hoy en día dichas bases siguen sustentando el proyecto con la ventaja que se puede reutilizar en otros proyectos y compilarlos todos juntos. Seguimos sospechando que precisamente eso hicieron en PHP pero esa es nuestra humilde opinión que como reafirmamos: en software libre este comportamiento es un honor a su filosofía de desarrollo: ejecutar, estudiar, distribuir, mejorar y redistribuir.
Versiones actuales y desarrolladores estrellas.
Nosotros en nuestro GNU/Linux Ubuntu 16 tenemos instalada la versión 7.40.00 pero en realidad la última versión estable es la 7.54.0.
Si bien son muchísimos los colaboradores, es justo mencionar los que más han contribuido en los últimos años de una manera marcada y constante:
Daniel Stenberg.
Steve Holme.
Jay Satiro.
Dan Fandrich.
Marc Hörsken.
Kamil Dudka.
Alessandro Ghedini.
Yang Tse.
Günter Knauf.
Tatsuhiro Tsujikawa.
Patrick Monnerat.
Nick Zitzmann.
Disipación de toda duda.
En este punto de nuestra investigación nuestras sospechas se hacen realidad: uno de los primero lenguajes en adoptar la librería curl es precisamente PHP el cual motoriza un 25% de las páginas web a nivel mundial. El extracto , en inglés, reposa en el libro electrónico -liberado con licencia «Creative Commons»- «Everything about curl«:
The libcurl binding for PHP was one of, if not the, first bindings for libcurl to really catch on and get used widely. It quickly got adopted as a default way for PHP users to transfer data and as it has now been in that position for over a decade and PHP has turned out to be a fairly popular technology on the Internet (recent numbers indicated that something like a quarter of all sites on the Internet uses PHP).
A few really high-demand sites are using PHP and are using libcurl in the backend. Facebook and Yahoo are two such sites.
La traducción hecha por nosotros al idioma castellano:
El software de enlace (librerías) de curl para PHP fue uno, cuidado sino, el primero de los enlaces que realmente captura y lo usa ampliamente. Rápidamente fue adoptado como una manera por defecto para transferir datos y se ha mantenido en esa posición por más de una década mientras tque PHP se ha convertido en una tecnología bastante popular en internet (cifras recientes indican que algo asó como una cuarta parte de todos los sitios web en internet utilizan PHP).
Realmente unos pocos sitios web de alta demanda están usando PHP acompañado de las librerías de enlace de curl corriendo entre bamabalinas. Facebook y Yahoo son dos de tales sitios.
Protocolos soportados por curl.
HTTP, HTTPS, FTP, FTPS, GOPHER, TFTP, SCP, SFTP, SMB, TELNET, DICT, LDAP, LDAPS, FILE, IMAP, SMTP, POP3, RTSP y RTMP (esos son todos, por ahora -y vienen más, no se detiene el proyecto-).
PHP curl.
Ahora si que pasamos a hablar del software que nos ocupa en este vuestro sitio web de compartición del conocimiento. Como ya hemos hablado bastante de historia y teoría pasamos directamente a describir cómo trabajar con PHP curl:
Inicializar curl con curl_init().
Pasarle los parámetros – esencial es la URL – con curl_setopt().
Retribuir y mostrar -o guardar- con curl_exec().
Cerrar y liberar recursos con curl_close().
Nuestro primer ejemplo práctico.
Lo siguiente que haremos es abrir una ventana terminal, tomar nuestro editor de texto favorito y escribir el siguiente código para ser guardado en un archivo que llamaremos php_curl.php:
[cc lang=»php» tab_size=»2″ lines=»80
[/cc]
Por supuesto, llamad vuestro archivo como queráis, guardadlo en vuestra carpeta donde ejecute vuestro servidor PHP y dadle los permisos de lectura y ejecución necesarios. En la primera línea inicializamos, en la segunda línea le pasamos la dirección web deseada -un dominio que devuelve nuestra dirección IP asignada por nuestro ISP-, en la tercera línea lo ejecutamos y en la cuarta línea cerramos y liberamos recursos. Una explicación más detallada a continuación.
Inicialización.
Debemos crear una instancia y guardarla para futuras referencias, este objeto basado en curl nosotros lo llamamos $objCurl y este nombre es el que debemos pasar a los otros comandos. El comando curl_init() solamente acepta un parámetro, la URL que es un dato imprescindible, tal vez debido a ser tan importante fue el único que establecieron en este comando. Aunque en el ejemplo no lo colocamos por razones didácticas, de ahora en adelante «para que no se nos olvide» lo estableceremos siempre en la primera línea del script o guion del programa.
Configuración.
Este es el comando más denso, notad que le damos el nombre de configuración porque su nombre así lo sugiere: curl_setopt(), osea «setopt» -> «set options». Acepta tres parámetros, separados por comas:
Primero debemos indicarle el objeto que contiene la inicialización de curl, en nuestro caso la variable $objCurl.
Segundo le pasaremos el tipo de valor que le pasaremos en el tercer parámetro, en nuestro caso la URL y la constante que lo define -nombrada de manera nemotécnica- es CURLOPT_URL.
El tercer parámetro es el valor en sí mismo de lo que indicamos en el segundo parámetro.
Debemos indicaros que usamos una sola línea para configurar, pero pronto veremos que esta parte es la más abultada por la infinidad de datos y tipos de datos que podemos pasar. Es mejor que vayaís preparando para aprender que esta sección siempre será multilínea y que debemos indentarla y escribirla lo más explícito posible para corregir a futuro de forma fácil nuestro código.
Ejecución.
Simplemente le decimos a PHP que hemos terminado de establecer lo que queremos obtener –o lo que queremos enviar, ya veremos más adelante- y acepta un parámetro que sigue siendo el objeto que hemos creado y configurado. En este punto ya os recordaremos que estamos trabajando con funciones y este comando devuelve verdadero o falso para indicar si tuvo éxito (para comparar la respuesta usaremos siempre «==» para estar seguros del tipo de variable y el resultado obtenido). En el ejemplo no colocamos ninguna variable que reciba el resultado del que hablamos como función ¿dónde está lo que nos interesa? En realidad el valor numérico (verdadero o falso) es lo que podemos guardar en una variable, el resto del resultados se va al stdout y eso será lo que enviaremos al navegador web que solicitó nuestro primer guión PHP sobre curl. Debido a esto recibiremos el mismo código HTML de la página que estamos solicitando (pero con los enlaces web absolutos cambiados).
Si probáis con descargar diferentes páginas, unas funcionarán, otras no, todo depende de si la página es estática, dinámica, si tiene JavaScript, en fin, cantidad de cosas que pueden NO ser compatibles con PHP curl: por eso debemos aprender las muchísimas opciones de configuración que nos sean útil en cada trabajo que se nos presente para ganarnos así el pan nuestro de cada día como Dios manda.
Liberación de recursos.
Os podrá sonar que nos contradecimos con lo siguiente: la función curl_close() se encarga de cerrar, como su nombre indica pero no devuelve resultado acerca del trabajo que le mandamos a realizar. Consideramos que esto es un «bug» porque a la hora de detectar dónde fugan recursos en nuestro servidor deberemos recurrir a otras herramientas apartes de PHP, pudiendo ser evitado esto con una sencilla rutina de nuestra parte e indicar que está sucediendo y qué está mal. Ah, perdón, casi lo olvidamos: el parámetro único que acepta es el objeto que creamos -y queremos destruir- con curl_init().
Nuestro primer ejemplo práctico pero mejorado.
Un sencillísima rutina de control de errores nos puede ahorrar muchísimos dolores de cabeza.
Nota: hay mejores métodos para el manejo de excepciones, pero aprendamos poco a poco. Ah, y nosotros lo llamamos «control de errores» y eso tampoco es el nombre correcto (excepciones) pero así nos abstraemos.
Por ello reescribiremos nuestro ejemplo pero con condicionales if~else:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]
$objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == true) {
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl);
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Notad que pasamos de una buena vez el URL en en el inicio con curl_init(). Además guardamos el valor del resultado en una variable, evaluamos el valor que tiene y ejecutamos o mostramos un mensaje apropiado según la respuesta obtenida. Muchos programadores y programadoras piensan que hacer nuestro software de esta manera, aparte de ayudarnos a nosotros mismo, abre las puertas a los hackers cuando se presentan excepciones -o errores, como les llamamos- porque «develan mucho». Ese razonamiento es válido en el software privativo pero en el software libre no tiene asidero alguno porque cualquier hacker tiene acceso al código fuente, así que hagamos la depuración fácil para nosotros mismos.
Guardando el resultado en una «variable aparte».
Como explicamos PHP curl envía al stdout la respuesta y asu vez eso lo pasamos al navegador, ¿qué tal si analizamos primero lo que recibimos y luego lo reenviamos? Por ejemplo, podríamos «acomodar» los enlaces absolutos de las imágenes que contiene la página web que llamamos (URL). Para ello vamos a emplear culr_setopt() con CURLOPT_RETURNTRANSFER establecido en el valor 1, mirad:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com»);
if ($objCurl == true) {
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
$resul = curl_exec ($objCurl);
if ($resul == true){
curl_close ($objCurl); print «Nuestra direccion IP es: «; print $resul;
} else {
echo «No se pudo ejecutar PHP curl
«;
}
} else {
echo «No se pudo inicializar PHP curl.
«;
}
?>[/cc]
Y así «manipulamos» el resultado con el texto que coloreamos en verde; ahora vamos un paso más allá. 😎
Guardando el resultado en un archivo.
Aunque ya tengamos el resultado deseado en una «variable» supongamos que estamos creando un robot (o bot como los mientan ahora en este siglo) y queremos guardar el resultado en un archivo ¿qué tiene que ver PHP curl con esto si ya sabemos el lenguaje PHP y sabemos como hacerlo aparte?
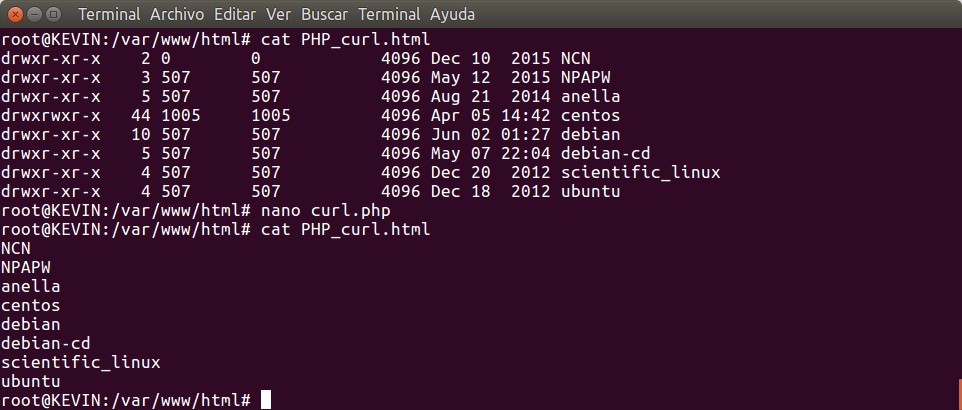
Pues resulta que con CURLOPT_FILE en curl_setopt() permite guardarlo en un archivo, pero antes tenemos que abrir el archivo y pasarle la «referencia» a PHP curl:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] $objCurl = curl_init(«http://www.soporteweb.com/»);
if ($objCurl == false) {
print «No se pudo inicializar PHP curl.
«;
} else {
$nom_arch = ‘PHP_curl.html’; $arch = fopen( $nom_arch , «w»);
if ($arch == false ) {
print «No se pudo abrir el archivo ‘».$nom_arch.»‘
«;
curl_close ($objCurl);
} else { $resp = curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_RETURNTRANSFER.
«;
curl_close ($objCurl);
} else { $resp = curl_setopt ($objCurl, CURLOPT_FILE, $arch);
if ( $resp == false ) {
print «No se pudo establecer CURLOPT_FILE.
«;
curl_close ($objCurl);
} else { $resul = curl_exec ($objCurl);
if ($resul == false) {
echo «No se pudo ejecutar PHP curl.
«;
} else { print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado:
curl_close ($objCurl);
}
}
}
}
}
?>[/cc]
Así de sencillo, con las correspondientes rutinas de depuración para nosotros. Como tal vez se vea un poco largo hemos coloreado las partes importantes para que sigáis el hilo. ¿Que por qué nos hemos ido por la negación siempre de primero? Pues revisando la función fopen() verificamos que si es exitosa devuelve una referencia al archivo más no un valor de tipo booleno -verdadero-. En cambio si falla la función siempre devuelve un valor boleano falso. Lo de seguir usando la negación por defecto es para llevar el mismo estilo parejo al resto del código.
Mejorando la claridad de la sintaxis con ayuda de exit().
Una función «vieja» en PHP es la función die() que es totalmente equivalente a exit() que es más «elegante». El chiste del asunto es emplear la conjunción or (operador lógico «o») para unir la acción que queremos realizar con la función exit(). Dicha función permite como parámetro una cadena de texto o un entero entre cero y 254 (el 255 está reservado para uso exclusivo de PHP). Nos gusta mejor la opción de pasarle una cadena de texto con el mensaje que queremos presentar al usuario ¡o a nosotros mismos!
Otro punto importante es que la función exit() aparte de mostrar mensaje y cerrar adecuadamente los objetos en memoria es que sale inmediatamente y no ejecuta el resto de las líneas que quedan a partir de su llamada.
Veamos entonces cómo emplearlo en nuestra labor que hoy nos ocupa (para no alargar tanto cada línea fijaos el uso del punto y coma para separar bloques de código multilíneas):
$objCurl = curl_init("http://www.soporteweb.com/")
or exit("No se pudo inicializar PHP curl.
");
$nom_arch = ‘PHP_curl.html’; $arch = fopen( $nom_arch , «w»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
print «El archivo fue guardado con el nombre ‘PHP_curl.html’.
«;
// curl_close NO devuelve resultado: curl_close ($objCurl);
?>[/cc]
¡Qué gran mejora en la legibilidad! Debemos aclarar que exit() de manera implícita llama a los procedimientos de cierre y liberación de recursos de memoria (destructor lo nombran en lenguaje C++) así que como ven es una vía muy pragmática para nuestros propósitos.
Si queréis probar como funciona la rutina con control de excepciones, colocad una dirección web que no exista y mirad que sucede, ¡experimentad! También os recomendamos probar otros protocolos, por ejemplo FTP en un servidor público como por ejemplo «ftp://ftp.cesca.es/» donde veremos un listado de archivos disponibles para ser descargados.
Probando otros protocolos: FTP.
En el párrafo anterior os sugerimos probar el protocolo FTP y no hubo nada que cambiar en el código que teníamos -aparte de la URL, por supuesto-. Pero PHP curl tiene sus opciones y a continuación pasamos a revisar alguna de ellas. La primera que revisaremos limita el listado obtenido de archivos y directorios, osea, no muestra los permisos de cada uno de ellos. La sintaxis en el comando curl_setopt() -y todas las opciones utilizan esta función- es la siguiente:
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»]curl_setopt($objCurl, CURLOPT_FTPLISTONLY, 1)
or exit("No se pudo establecer CURLOPT_FTPLISTONLY"); [/cc]
Si el servidor FTP no fuera público o exigiera una conexión tipo anónimo usaremos esto:
curl_setopt($objCurl, CURLOPT_USERPWD, "anonimo:su@correo-e.com")
or exit("No se pudo establecer CURLOPT_USERPWD");[/cc]
Con esta novedad de introducir credenciales de conexión nos encontramos con otro tipo de manejo de excepciones: dado el caso las credenciales no funcionen (mala escritura, contraseña vencida, usuario inexistente, etc) dentro del obejto PHP curl se guardará en una instancia aparte el resultado del intento de conexión, para ellos contamos con:
[cc lang="php" tab_size="2" lines="80" widht="10%"] echo curl_error($objCurl);[/cc]
https://twitter.com/souzace/status/868869012414840832
Pasando valores por medio del método POST.
Finalmente llegamos al meollo del asunto: poder pasar a un servidor web una o más variables por medio del método POST a un servidor web. Para propósitos de aprendizaje diremos que es uno de los métodos más populares debido a su cierta privacidad ya que el usuario no puede ver el enlace como en el método GET y tampoco es «cacheable» por los navegadores web.
Primero haremos una rchivo que nos muestre todas las variables que reciba y las liste por pantalla, de manera increíble solo necesita una sola líneas de código (guardar con el nombre de «curl_post.php«):
var_dump($_POST);
?>[/cc]
Una vez tengamos este archivo ya sea en nuestro servidor local o en nuestro servidor remoto podremos comenzar a escribir el siguiente script:
$objCurl = curl_init("http://localhost/curl_post.php")
or exit("No se pudo inicializar PHP curl
");
curl_setopt($objCurl, CURLOPT_POST, 1)
or exit(«No se pudo establecer CURLOPT_POST»);
//Pasamos las variables que nos interesan al servidor curl_setopt($objCurl, CURLOPT_POSTFIELDS, «var1=uno&var2=dos&var3=tres»)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.»);
curl_close ($curl);
?>[/cc]
Debido a los mensaje que incluimos en cada exit() y con el coloreado del código no hay nada que explicar… excepto unas cuantas acotaciones:
Las variables que pasamos en el método POST deben estar por pares unidas con el ampersand y separadas por medio de un signo de igualdad.
Los espacios no se permiten, debemos pasar «%20» o mejor dicho debemos darle un formato especial antes de enviarlo. El comando que nos ayudará será urlencode() y para nosotros castellanohablantes es importante representar bien los acentos, etc.
[cc lang=»php» tab_size=»2″ lines=»80″ widht=»10%»] //Pasamos las variables que nos interesan al servidor
$var_post = urlencode(«var1=Venezuela&var2=América del Sur&var3=Güigüe»); curl_setopt($objCurl, CURLOPT_POSTFIELDS, $var_post)
or exit(«No se pudieron establecer las variables en CURLOPT_POSTFIELDS»);[/cc]
Fuera de tema: «Tamper data for Mozilla Firefox».
Adam Judson es un desarrollador que tiene -nos tiene- como usuarios a más de 80 mil personas en su trabajo de programación desde el año 2007. Él desarrolló «Tamper Data» para este popular navegador, una herramienta para, según sus propias palabras «pruebas de seguridad en aplicaciones web por medio de la modificación de los parámetros POST».
Dicha herramienta la podemos instalar en nuestro navegador (requiere reinicio del navegador y no es compatible con «Google Web Accelerator») y con ella podremos visitar cualquier sitio web que utilize envio de datos POST y al activarlo en una ventana aparte mostrará sin molestar ni influir en nada el tráfico saliente de nuestro ordenador por medio de nuestro navegador web Firefox. ¿Por qué anuncia pruebas de seguridad? Porque nosotros muy bien sabemos como programadores que el código fuente de nuestras aplicaciones web están a la vista de los usuarios ¿pero que tal lo que no se ve? Pues acá entra «Tamper Data»: por más que coloquemos validación HTML5 y JavaScript del lado del cliente, si no utilizamos HTTPS el tráfico entre el usuario y nuestro servidor puede ser modificado por terceros. Y aunque si usaramos HTTPS tampoco podemos confiarnos de nuestros usuarios, verbigracia la misma herramienta que estamos recomendando puede modificar los datos si en la venta que se nos abre hacemos click en «modificar». Al activar este botón, cuando sale algo de nuestro ordenador nos pregunta si deseamos modificar algún dato, ¡y allí podremos echar por tierra toda la hermosa programación hecha en HTML5 y javaScript!
Este comentario es «fuera de tema»: para combatir esto último lo que debemos hacer es, en lenguaje PHP -o vuestro lenguaje utilizado- volver a validar los datos recibidos desde el usuario, ¡PERO HAY MÁS! Es obligatorio agregar «disparadores» y «restricciones» incrustados en nuestra base de datos (recomendamos PostgreSQL por su capacidad de incluso aceptar guiones en lenguaje Python) para volver a validar datos al agregar los datos a nuestro motor informático. Más detalles escapan de esta entrada, pero este resumen es el mejor que podemos expresar al respecto.
Ejecutando PHP curl en modo de depuración.
«Verbose» en idioma inglés describe un modo de hablar más de lo necesario. Pero en nuestro mundo del software libre nuestra búsqueda del conocimiento es insaciable, «solo sabemos que no sabemos nada» por ello le dedicamos esta sección empinada a ahondar en PHP curl. Aparte de aprender más y mantener nuestro cerebro haciendo ejercicios, debido a la gran cantidad de protocolos y opciones es sumamente fácil para nosotros el cometer errores solicitando opciones inexistentes o incompatibles entre ellas, si son varios los parámetros que les pasemos.
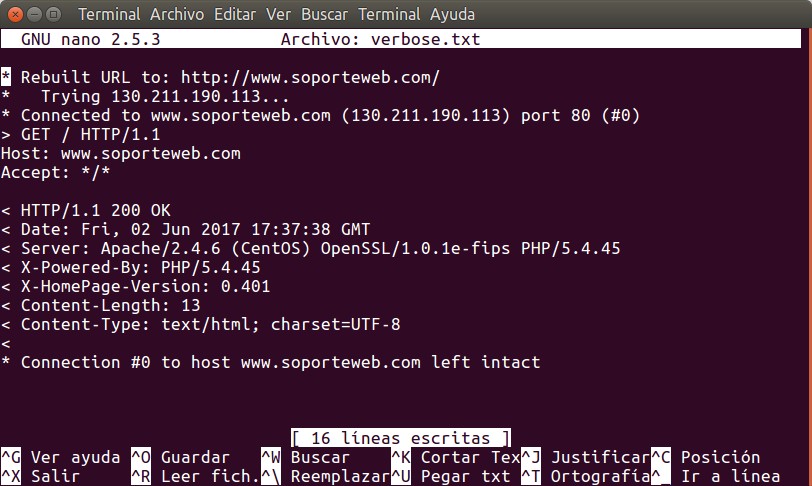
Para activar el modo de depuración -vamos que la traducción al castellano de «verboso» no cuela- en PHP curl echamos mano de la alternativa CURLOPT_VERBOSE en la ya consabida función curl_opt() ¡pero esperen -como dice el «infomercial» de T.V.- hay más! PHP curl, dijimos, lo tenemos claro, emplea stdin y stdout que son los más conocidos pero también utiliza stderr ¡para algo que no es error, sino DEPURACIÓN! Teoricamente no debería ser pero en la práctica, el mundo real esto es de facto que lo hacen -y haremos-: capturar el stderr para llevar los mensajes de depuración hacia un archivo de escritura y de adición. Este archivo si no está creado, lo hace, y lo abre para agregar dichos datos y si existe le adiciona al final, de tal manera que llevamos una especie de bitácora para nuestro estudio y control.
$ObjCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt ($ObjCurl, CURLOPT_URL, «http://www.soporteweb.com»)
or exit(«No se pudo establecer la URL.
«);
curl_setopt($ObjCurl, CURLOPT_VERBOSE, 1)
or exit(«No se pudo establecer el modo de depuración.
«);
$verbose_arch = fopen(‘verbose.txt’, ‘a’); curl_setopt($ObjCurl, CURLOPT_STDERR, $verbose_arch)
or exit(«No se pudo establecer CURLOPT_STDERR
.»);
curl_exec ($ObjCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($ObjCurl);
?>[/cc]
Y veremos algo parecido a esto:
CURLOPT_VERBOSE
Explicamos que:
Las líneas que comienza con un asterisco son mensajes informativos de PHP curl.
Las líneas que comienzan con «>» es información que se le envia al servidor web, ftp, etc.
Las líneas que comienzan con «<» es la información que recibimos de tal servidor.
Los servidores web basados en ASP.NET devolverán un error «HTTP/1.1 500 Internal Server Error» y no podremos hacer nada ya que no se rigen por las normas comunes basadas en RFC y recomendaciones de WWW.
Otros usos para PHP curl.
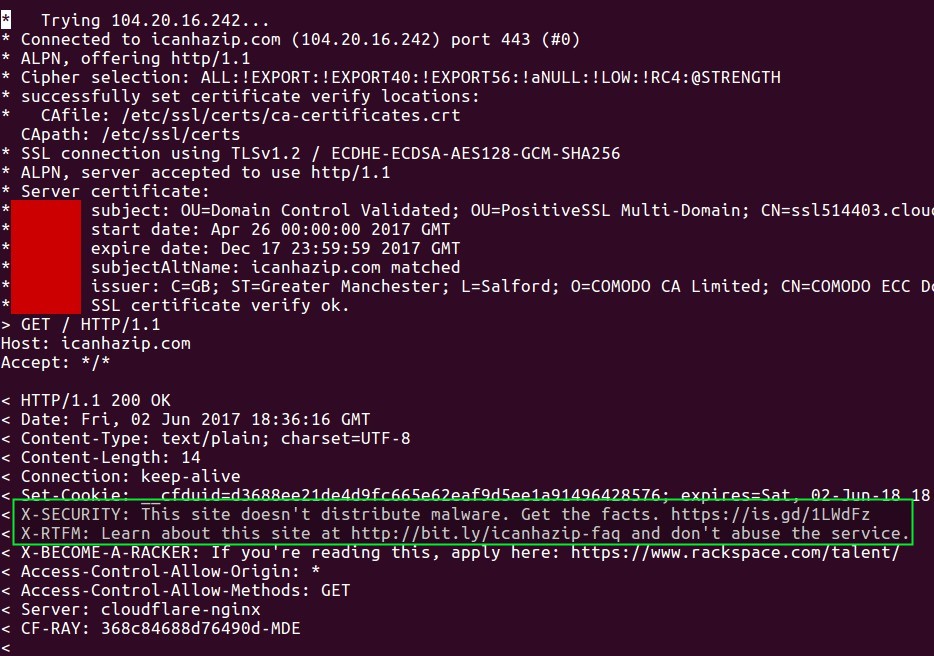
Por nuestros experimentos vimos que PHP curl permite grabar en archivos «flujos de datos» de una manera básica, sin estar amarrado a protocolos (si lo usamos con FTP veremos que nos hacen falta los comandos populares y que solo podremos usar si tenemos un cliente FTP como tal). Eso deja abierta la posiblidad a darle infinidad de usos sin siquiera saber -ni preocuparnos- «con quien estamos hablando». Un ejemplo de ello es con el acceso a servidores con tecnología ASP.NET o la mismisa consulta de nuestra dirección IP que devuelve un resultado no normalizado ni con metadato alguno (solo nosotros, seres humanos, estamos con la plena certeza que es una dirección IPv4).
Por ejemplo, si en vez de usar soporteweb.com para retribuir nuestra dirección IPv4 usamos el servicio que presta icanhazip.com en el modo de depuración veremos algo como esto:
icanhazip.com Get the facts
Y al seguir el enlace indicado abrimos el blog de Major Hayden (sí, ese es el nombre, no no es mayor de ningún ejército ni alcalde de ninguna ciudad) un administrador de sistemas GNU/Linux con 6 años de experiencia quien ha tenido excelentes maestros y está dispuesto siempre aprender… como nosotros mismos, quienes escribimos y quienes leemos este humilde sitio web.
Auguramos que curl y PH curl seguirá creciendo y mejorando para nuestro beneplácito y que nosotros, a la larga, algún día aportaremos nuestro granito de arena a la causa del software libre, de una u otra manera, de manera inexorable.
curl_setopt(): parámetros mas socorridos.
La lista es larga en verdad pero mencionaremos, al menos, los que avizoramos de alguna utilidad dada la experiencia que hemos logrado a lo largo de los años:
CURLOPT_USERAGENT
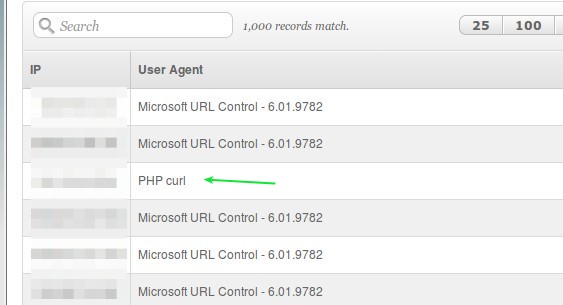
Con esta opción podremos indicarle al servidor con el cual le estamos requiriendo información acerca de nuestra identidad. Curiosamente PHP curl por defecto no envía indentificación alguna acerca del nombre del software pero es que también el servidor que atiende la consulta tampoco la requiere como obligatoria. En la práctica les mostramos (las direcciones IP las ocultamos -junto con otros detalles- de las visitas a esta vuestra página web):
PHP curl no se identifica -por defecto-
Así que le aplicamos código y así quedaría la visita de nuestro bot en cierne:
Usando PHP curl CURLOPT_USERAGENT
CURLOPT_CONNECTTIMEOUT
A veces estimamos en cuánto tiempo debería responder determinado proceso y si no se realiza pues no está bien afinado nuestro servidor no sin antes descartar fallas de internet, etc. Para ello CURLOPT_CONNECTTIMEOUT es el idóneo para que nuestro script no se cuelgue indefinidamente, al cabo de cierto tiempo que le establezcamos y si no logra conectar con el servidor la tarea finalizará. El tercer parámetro que pasaríamos a continuación es el número de segundos, lo cual es una eternidad en tiempo de computadores, por ello también contamos con CURLOPT_CONNECTIONTIMEOUT_MS que viene expresado en milisegundos si estamos realmente apurados.
Es una excelente opción para desarrollar herramientas de diagnóstico a equipos remotos y podremos llevar un ergistro de eventos en nuestra base de datos (sí, que ya hay mucho software para eso pero también hay tareas tan pequeñas que no necesitamos «una mandarria sino un simple martillito»)
CURLOPT_COOKIE y CURLOPT_COOKIEFILE
Una «cookie» en inglés o galletita en castellano, es una pieza de información que plantan los servidores web en nuestros navegadores para identificarnos de manera absoluta. Al igual que el método POST debemos saber el nombre de la galletita y por ende su contenido, así que no la generamos nosotros -obvio- pero si debemos tener una para poder obtener respuesta de algunos servidores, quienes comparan si tienen la galletita en su lista de memoria (las galletitas tienen vencimiento o validez en el tiempo) y así podrán:
bien sea aceptar nuestra petición ó
incluso devolvernos unos valores personalizados.
De allí viene el gran temor a la violación de nuestra privacidad, una delgada línea demarca las buenas de las malas intenciones.
De esto último viene la necesidad de CURLOPT_COOKIEFILE, muchas veces son tantas las galletitas usadas por nosotros los programadores que mejor es enviar un archivo completo con ellas incluídas. Aquí debemos colocar el nombre del archivo en la opción anterior debemos enviar los valores en sí.
Otra manera de pasar una gran cantidad de galletitas es pasar el jarrón completo, un fichero, y para que no se nos olvide la sintaxis le pusieron el curioso nombre CURLOPT_COOKIEJAR. Un ejemplo sería:
Con esta opción podemos deshabilitar que verifique certificados en una conexión https (o mejor dicho TLS). Esto normalmente está habilitado pero uno a veces necesita, por economía, un certificado autofirmado el cual no está validado ante ningún tercer ente. Con esta opción cambiada a false en el tercer parámetro evitaremos este problemita.
CURLOPT_FOLLOWLOCATION
Actualmente las redirecciones de página se ha vuelto el pan nuestro de cada día motivado a la popularidad de las páginas web. Una página de cualquier gobierno del mundo de muy seguro que tendrá miles y hasta millones de visitantes y como comprenderán un solo servidor web jamás ni nunca se daría abasto. Lo que se ha inventado es poner granjas de servidores en distintas partes del mundo con copias constantes de los dominios deseados y redireccionado el tráfico con ayuda de potentes DNS: todo esto se conoce como CDN o «Content Delivery Network».
La idea del asunto es que cuando uno solicita una página web los DNS encargados redireccionan nuestra solicitud a la granja de servidores más cerca a nosotros de manera geográfica donde habrá una copia de la web que queremos. ¿A qué viene todo este cuento con PHP curl? Que es muy probable que la respuesta que obtengamos será una cabecera tipo 300 indicandonos que la direcciíon adecuadad para nosotros y entonces volvemos a hacer la petición -la misma petición- pero a otro servidor más cercano (o mas desocupado, o que tenga nuestra idioma, etc. -el que nos convenga-).
PHP curl ya está preparado en ese escenario y estableceremos CURLOPT_FOLLOWLOCATION a verdadero y por defecto PHP curl redireccionará hasta un máximo de 5 oportunidades nuestra solicitud (más adelante veremos otra función que nos dirá cuántas redirecciones siguió con la variable CURLINFO_REDIRECT_COUNT establecida).
Un problema se presenta al hacer una consulta POST: después del primer redireccionamiento PHP curl NO HACE una consulta POST sino una consulta GET (por razones históricas y de costumbres en los navegadores) y esto es un problema porque son métodos distintos y no obtendremos respuesta (aparte de que nos volveremos «locos» buscando dónde está el error). Para prevenir este inconveniente en vez de fijar CURLOPT_POST a «true» tomaremos otra opción, CURLOPT_CUSTOMREQUEST fijado a «POST»:
Otra advertencia más: cuando uno sube archivos por medio de CURLOPT_POSTFIELDS en la segunda redirección no será enviado dicho fichero. También para prevenir esto urge emplear CURLOPT_POSTREDIR fijado el valor a 3 para que maneje los redireccionamientos 301 y 302 reenviando el archivo en cada oportunidad (es más tráfico de datos pero ¿cómo hacemos con los CDN’s que llegaron para quedarse?).
Panorama general del resto de las opciones de curl_setopt()
Ya en este punto os habreis dado cuenta de la importancia de esta función, recordad que solo hemos visto apenas cuatro que van en este orden: curl_init(), curl_setopt(), curl_exec() y curl_close(); pues bien hay 23 funciones más de las cuales más adelante estudiaremos una de ellas (por ahora).
He aquí un listado clasificado por el tipo de contenido que hay que pasar en el tercer parámetro de curl_setopt(), de un vistazo (en marrón las que hemos visto y analizado):
Aquellas cuyo valor debe ser booleano (verdadero<>0 ó falso=0):
Aquellas cuyo valor debe ser un recurso de flujo de datos:
CURLOPT_FILE
CURLOPT_INFILE
CURLOPT_STDERR
CURLOPT_WRITEHEADER
Aquellas cuyo valor debe ser una función o una función de cierre:
CURLOPT_HEADERFUNCTION
CURLOPT_PASSWDFUNCTION
CURLOPT_PROGRESSFUNCTION
CURLOPT_READFUNCTION
CURLOPT_WRITEFUNCTION
Aquellas cuyo valor debe ser una muy específica:
CURLOPT_SHARE
Función curl_setopt_array.
Nos dimos cuenta como la función exit() mejoró muy bien la legilibilidad de nuestro código y además proporciona información a nuestros usuarios en caso de tratamiento de excepciones. Pero hay una manera aún mejor de configurar las opciones justo antes de ejecutar curl_exec() con el detalle que es como la famosa película de vaqueros: tiene lo bueno, lo malo y lo feo pero sin lo feo. Lo bueno -y muy bueno- es que como dijimos mejora la apariencia de nuestro código y abre nuevas posibilidades con el uso de una matriz: podemos realizar una función que consulte una base de datos y llene dicha matriz. Lo malo es que al pasar todo de un solo golpe a la unficón ésta acepta todo o no acepta nada y tendremos nuestra bella salida diciendo «no se pudo establecer culr_setopt_array» pero no nos indicará dónde, cuál es el elemento que falla.
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«); $opciones = array(
CURLOPT_URL => ‘https://icanhazip.com’,
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose );
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Percataos que colocamos el URL en la matriz para abultar y activamos el modo de depuración de resto todo lo demás es el mismo ejemplo que colocamos anteriormente. Lo curioso del asunto es que curl_setopt() y curl_setopt_array() pueden trabajar juntos perfectamente, lo anterior lo podemos reescribir como lo próximo y funciona plenamente:
$objCurl = curl_init()
or exit("No se pudo inicializar PHP curl.
");
curl_setopt($objCurl, CURLOPT_URL ,’https://icanhazip.com’)
or exit(«No se pudo establecer el CULROPT_URL»);
$verbose = fopen(‘verbose.txt’, ‘a’)
or exit(«No se pudo abrir el archivo verbose.txt
«); $opciones = array(
CURLOPT_VERBOSE => 1,
CURLOPT_STDERR => $verbose );
curl_setopt_array($objCurl, $opciones)
or exit(«No se pudo establecer curl_setopt_array()»);
curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
curl_close ($objCurl);
?>[/cc]
Analizando los resultados de la última conexión.
Comentamos que PHP curl puede utilizarse para fabricar una sencilla herramienta de monitoreo de servidores. Pensando en esto indagamos en ciertas opciones que trae la librería y de la cual podemos obtener gran cantidad de información, siempre pensando en guardarlo en una base de datos para su posterior análisis de manera masiva. Pero debemos comenzar por lo básico y no irnos precipitadamente.
Aparte de las opciones de depuración, que ya logramos vertirlas en un archivo que llamamos simplemente «verbose.txt» (y cuyo nombre podemos cambiar a la fecha y hora actual para que siempre sea un archivo distinto y almacenar -o borrar, o procesar, etc.- cuando queramos) podemos echar mano de otra función para obtener los datos de la conexión. Tal función es denominada curl_getinfo() a la que introducimos nuestro manejador creado por curl_init().
Esta función devuelve falso si no tiene información o una matriz con elementos predefinidos -no todos-. Para poder escribir esta matriz en un archivo agarramos a la función serialize() para convertirla en una cadena de texto antes de guardarla.
De una vez vamos a la práctica con el primer ejemplo que presentamos, el más «refinado» con las llamadas exit() ¿lo recordais? Pero vamos un paso adelante y lo modificamos, primero para que tome la URL por el método GET: escribimos en la barra de direcciones la ubicación de nuestro guion y al final agregamos un signo de cierre de interrogante con la palabra «url», luego un signo de igualdad y a continuación el dominio o página que queremos descargar y guardar -para luego analizar según el propósito que tengamos, que para cada persona es muy variopinto. Supongamos que nuestro guion está en nuestro servidor local y se llama «curl.php», el llamado sería el siguiente (obvien el prefijo «http://» porque lo agregamos en el script):
También agregaremos dos mensajes adicionales: si no se pasa una URL entonces alerta que debe pasar una y otro mensaje para indicar que ha sido guardada en un archivo (recordad que usamos la opcion CURLOPT_RETURNTRANSFER al valor de 1). Coloreamos el código para su mayor comprensión:
if ($_GET["url"]){ $objCurl = curl_init("http://".$_GET["url"])
or exit("No se pudo inicializar PHP curl.
");
$nom_arch = ‘servidor.html’; $arch = fopen( $nom_arch , «a»)
or exit(«No se pudo abrir el archivo ‘».$nom_arch.»‘
«);
curl_setopt ($objCurl, CURLOPT_RETURNTRANSFER, 1)
or exit(«No se pudo establecer CURLOPT_RETURNTRANSFER.
«);
curl_setopt ($objCurl, CURLOPT_FILE, $arch)
or exit(«No se pudo establecer CURLOPT_FILE.
«);
curl_setopt ($objCurl, CURLOPT_CONNECTTIMEOUT, 7)
or exit(«No se pudo establecer CURLOPT_CONNECTTIMEOUT.
«); curl_exec ($objCurl)
or exit(«No se pudo ejecutar PHP curl.
«);
$nom_arch = «servidor_respuesta.txt»; $archivo = fopen($nom_arch, «a»)
or exit(«No se pudo abrir el archivo'».$nom_arch.»‘
«);
$resp = curl_getinfo($objCurl)
or exit(«No se pudo obtener información de la ultima conexion.
«);
fwrite($archivo, serialize($resp))
or exit(«No se pudo escribir en el archivo ‘».$nom_arch.»‘
«);
fclose($archivo)
or exit(«No se pudo cerrar el archivo ‘».$nom_arch.»‘
«);
// curl_close NO devuelve resultado: curl_close ($objCurl);
echo «URL descargada y guardada.
«; } else {
echo «Debe pasar una URL para ser descargada y analizada.
«; }
?>
[/cc]
Es crucial llamar esta función ANTES de llamar la función curl_close() que es cuando aún existe el objeto en memoria.
Matrix con campos predefinidos.
Esos datos que guardamos en el anterior software que inventamos ya están seleccionados por los desarrolladores de PHP curl y son los siguientes (repetimos, NO son todos los disponibles):
«url»
«content_type»
«http_code»
«header_size»
«request_size»
«filetime»
«ssl_verify_result»
«redirect_count»
«total_time»
«namelookup_time»
«connect_time»
«pretransfer_time»
«size_upload»
«size_download»
«speed_download»
«speed_upload»
«download_content_length»
«upload_content_length»
«starttransfer_time»
«redirect_time»
«certinfo»
«primary_ip»
«primary_port»
«local_ip»
«local_port»
«redirect_url»
«request_header» (solamente está definido si CURLINFO_HEADER_OUT está establecido por una llamada previa a curl_setopt())
Totalidad de los campos de get_info()
Podemos solicitar cualquiera de estos campos pasando como parámetro los siguientes valores a la función curl_getinfo() -con una breve descripción y ordenados alfabéticamente-:
CURLINFO_APPCONNECT_TIME – Tiempo, en segundos, desde el inicio hasta la conexión/apretón de manos SSL/SSH del host remoto.
CURLINFO_CERTINFO – Serie de certificados TLS.
CURLINFO_CONDITION_UNMET – Información del condicional de timepo unmet.
CURLINFO_CONNECT_TIME – Tiempo, en segundos, que tomó el establecimiento de la conexión.
CURLINFO_CONTENT_LENGTH_DOWNLOAD – Logitud del contenido de la descarga, leída desde el campo “Content-Length:”.
CURLINFO_CONTENT_LENGTH_UPLOAD – Tamaño especificado de subida .
CURLINFO_CONTENT_TYPE – “Content-Type:” del documento solicitado. NULL indica que el servidor no envío un encabezado “Content-Type:” válido.
CURLINFO_COOKIELIST – Todas las cookies conocidas.
CURLINFO_EFFECTIVE_URL – Último URL efectivo.
CURLINFO_FILETIME – Hora del documento remoto obtenido; si devuelve -1, la hora del documento es desconocida.
CURLINFO_FTP_ENTRY_PATH – Ruta de entrada en el servidor FTP.
CURLINFO_HEADER_OUT – El string de la petición enviada. Para que funcione, se ha de añadir la opción CURLINFO_HEADER_OUT al manejador, llamando a curl_setopt()
CURLINFO_HEADER_SIZE – Tamaño total de los encabezados recibidos.
CURLINFO_HTTP_CODE – Último código HTTP recibido.
CURLINFO_HTTP_CONNECTCODE – El código de respuesta de CONNECT.
CURLINFO_HTTPAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticación disponible/s de acuerdo a la respuesta anterior.
CURLINFO_LOCAL_IP – Dirección IP local (fuente) de la conexión más reciente.
CURLINFO_LOCAL_PORT – Puerto local (fuente) de la conexión más reciente.
CURLINFO_NAMELOOKUP_TIME – Tiempo, en segundos, en resolver el nombre.
CURLINFO_NUM_CONNECTS – Número de conexiones que curl ha tenido que crear para lograr la transferencia anterior.
CURLINFO_OS_ERRNO – Número de error (errno) de un fallo de conexion. Es número es específico de cada SO y sistema.
CURLINFO_PRETRANSFER_TIME – Tiempo, en segundos, desde el inicio hasta justo antes de que comience la transferencia del fichero.
CURLINFO_PRIMARY_IP – Dirección IP de la conexión más reciente.
CURLINFO_PRIMARY_PORT – Puerto de destino de la conexión más reciente.
CURLINFO_PRIVATE – Datos privados asociados a este manejador de cURL, previamente establecidos con la opción CURLOPT_PRIVATE de curl_setopt()
CURLINFO_PROXYAUTH_AVAIL – Máscara de bits que indica el/los método/s de autenticaición proxy disponible/s de acuerdo a la respuesta anterior.
CURLINFO_REDIRECT_COUNT – Número de redireccionamientos, con la opción CURLOPT_FOLLOWLOCATION habilitada.
CURLINFO_REDIRECT_TIME – Tiempo, en segundos, de todos los pasos de redireción antes de que la última transación haya empezado, con la opción CURLOPT_FOLLOWLOCATION habilitada.
CURLINFO_REDIRECT_URL – Con la opción CURLOPT_FOLLOWLOCATION inhabilitada: URL de redirección encontrado en la última transacción, que debería ser solicitado manualmente luego. Con la opción CURLOPT_FOLLOWLOCATION habilitada: está vacío. El URL de redirección en este caso está disponible en CURLINFO_EFFECTIVE_URL
CURLINFO_REQUEST_SIZE – Tamaño total de las peticiones realizadas, actualmente solo para peticiones HTTP.
CURLINFO_RESPONSE_CODE – El último código de respuesta.
CURLINFO_RTSP_CLIENT_CSEQ – Siguiente CSeq cliente de RTSP.
CURLINFO_SSL_VERIFYRESULT – Resultado de la verificación del certificado SSL solicitado por la opción CURLOPT_SSL_VERIFYPEER.
CURLINFO_STARTTRANSFER_TIME – Tiempo, en sengudos, hasta que el primer byte está a punto de transferirse.
CURLINFO_TOTAL_TIME – Duración total, en segundos, de última transferencia.
Futuro de cURL.
Como bien es sabido por todos nosotros, Internet como tal está basado en las siete capas de red según el modelo de interconexión de sistemas abiertos (ISO/IEC 7498-1), más conocido como “modelo OSI”, (en inglés, Open System Interconnection) y cURL hace uso de la séptima capa para las transferencias por internet orientadas a ficheros. Por ello su autor Daniel Stenberg deja bien claro que eso es lo que seguirá haciendo cURL ahora y durante mucho tiempo. A continuación una traducción automatizada de su entrada en el blog al respecto:
No soy de los que pasan el tiempo mirando hacia el horizonte soñando con la grandeza futura y haciendo planes sobre cómo ir allí. Trabajo en cosas ahora mismo para trabajar mañana. No tengo idea de lo que haremos y trabajaremos en un año a partir de ahora. Conozco un montón de cosas en las que quiero trabajar a continuación, pero no estoy seguro de si alguna vez llegaré a ellas o si realmente enviarán o si tal vez serán reemplazadas por otras cosas en esa lista antes de que llegue a ellas.
El mundo, Internet y las transferencias cambian constantemente y nos estamos adaptando. No hay sueños a largo plazo más que apegarse al plan simple y único: hacemos transferencias de Internet orientadas a archivos utilizando protocolos de capa de aplicación.
Las estimaciones aproximadas dicen que ya podemos tener mil millones de usuarios. Lo más probable es que si las cosas no cambian demasiado drásticamente sin que podamos mantener el ritmo, tendremos incluso más en el futuro.
Resumen.
Recuerden lo que siempre dijo en vida nuestro Gran Maestro: «un punto, un punto y una línea recta«; aprovechen estos conocimientos para desarrollar programas y utilidades para fortalecer el Patrimonio Tecnológico de nuestra Humanidad no para escribir virus y gusanos que marguen las vidas de los demás.
<Esto es todo, pora ahora>.
Actualizado el sábado 27 de enero de 2018.
Recientemente, pocos días atrás, el creador de cURL, Daniel Stenberg, publicó la versión 7.58 la cual contiene una curiosa correción al proceso de agregar un «espacio en blanco» (sí, un simple y vulgar espacio en blanco) en el «pase» de las cabeceras URL (ver en GitHub el causante de este desaguisado) lo cual nos parece muy significativo, pues somos de los que insistimos y somos fastidiosos en corregir hasta el último caracter al programar (si véis algún error por estos lares hacednos un comentario abajo). Pero no somos los únicos, mirad el siguiente «tuit»:
Se acaba de parchear cURL para #Debian 9. Un "espacio en blanco" que lo machaba solo: https://t.co/LSr1zr5NNU Sí, un espacio en blanco (para los que me llaman "rompe pe…" cuando les corrijo los putos espacios :'D).
Utilizamos VirtualBox sobre Ubuntu 16, una distribución «hija» de Debian, la «madre» de todas las distribuciones GNU/Linux (o al menos una de las más importantes). Son 3 DVD’s de los cuales usamos el número uno para una instalación básica, sin mayores pretensiones, para realizar nuestras pruebas de programación. Es bien conocido que con VirtualBox podemos crear imágenes estáticas del ordenador virtual y hacer nuestras prueba para luego restaurar a sus estado original, esto es muyt útil para nosotros. Escogimos, como siempre, a Youtube con ángel custodio del vídeo de instalación, esperamos os sea de provecho la información contenida.
Requisitos mínimos de instalación:
Una vez que haya reunido información sobre el hardware de su ordenador debe verificar que su hardware le permita realizar el tipo de instalación que desea efectuar. Dependiendo de sus necesidades, podría arreglarse con menos del hardware recomendado listado en la siguiente tabla. Sin embargo, la mayoría de usuarios se arriesgan a terminar frustrados si ignoran estas sugerencias.
Se recomienda como mínimo un Pentium 4, a 1 GHz para un sistema de escritorio.
Tipo de instalación
RAM (mínimo)
RAM (recomendado)
Disco duro
Sin escritorio
128 Megabytes
512 Megabytes
2 Gigabytes
Con escritorio
256 Megabytes
1 Gigabyte
10 Gigabyte
Los requisitos de memoria mínimos necesarios son en realidad inferiores a los indicados en esta tabla. En función de la arquitectura, es posible instalar Debian en sistemas con tan sólo 20 MB (en el caso de s390) a 60 MB (para amd64). Lo mismo se puede decir del espacio necesario en disco, especialmente si escoge las aplicaciones que va a instalar manualmente, consulte Sección D.2, “Espacio en disco requerido para las tareas” para obtener más información de los requisitos de disco.
Es posible ejecutar un entorno de escritorio gráfico en sistemas antiguos o de gama baja. En este caso es recomendable instalar un gestor de ventanas que es consuma menos recursos que los utilizados en los entornos de escritorio de GNOME o KDE. Algunas alternativas para estos casos son xfce4, icewm y wmaker, aunque hay más entre los que puede elegir.
Es prácticamente imposible dar requisitos generales de memoria y espacio en disco para instalaciones de servidores ya que éstos dependerán en gran medida de aquello para lo que se utilice el servidor.
Recuerde que estos tamaños no incluyen todos los otros materiales que se encuentran habitualmente, como puedan ser los ficheros de usuarios, el correo y otros datos. Siempre es mejor ser generoso cuando uno está pensando qué espacio destinar a sus propios ficheros y datos.
Se ha tenido en cuenta el espacio de disco necesario para la operación normal del sistema Debian GNU/Linux en sí en estos requisitos de sistema recomendados. En particular, la partición /var de Debian contiene mucha información de estado específica a Debian, además de su contenido habitual, como puedan ser los ficheros de registro. Los ficheros de dpkg (que incluyen información sobre los paquetes instalados) pueden fácilmente consumir unos 40 MB. Además, hay que tener en cuenta que apt-get ubica los paquetes descargados aquí antes de instalarlos. Por regla general deberá asignar por lo menos 200 MB para /var, y mucho más si va a instalar un entorno gráfico de escritorio.
Un lenguaje importante y que hemos dejado de lado por años es el ya muy famoso lenguaje PHP. En desagravio publicamos esta entrada y le queremos dar características especiales: no insisteremos en ser detallistas al extremo, se trata de una introducción, un tutorial que lleve paso por paso a cualquier persona que desee aprender dicho lenguaje de programación. Por ello no publicaremos su historia, configuración del servidor, etcétera. Os recordamos que para aprender PHP sería bueno tener conocimientos mínimos de HTML, CSS y JavaScript.
Cuando tuvimos que actualizar nuestros conocimientos sobre Diseño Asistido por Computadora (CAD) nuestra experiencia era limitada y amarrada al software privativo Autocad® y como estamos decididos a ser libres nos decantamos por Freecad para realizar nuestro trabajo. Comenzamos así nuestro aprendizaje, que sobre el tema abunda en internet pero quien de inmediato llamó nuestra atención por su trabajo estructurado y paciente fue «ObiJuan» González y su Escuela de Padawan’s «CloneWars». Por ello cuando tuvimos noticias de que se le había otorgado el premio de Google llamado O’Reilly Open Source Award en reconocimiento a su labor (aunque es tonto de nuestra parte) nos contentamos en sumo grado y de que no solamente el Software Libre esté en tan alto nivel en España sino que también el HARDWARE LIBRE está surgiendo en América tutelado por (a pocas personas llamamos por su título, y por sus títulos menos) el Ingeniero y Doctor Juan González Gómez.
El jueves 11 de mayo en Austin (Estados Unidos), durante la celebración del congreso mundial OSCON, fue entregado el premio O’Reilly 2017. Fueron creados en el año 2005 por Tim O’Reilly y hasta el 2009 llevaban el prefijo Google-O’Reilly pero hasta la fecha de hoy simplemente lleva el nombre O’Reilly Open Source Award: un reconocimiento a los individuos por su dedicación, innovación, liderazgo y destacada contribución al código abierto.
El premio, creado y organizado por Google en colaboración con la factoría de Tim O’Reilly, desde el 2005, se entregó este jueves 11 de mayo en Austin (Estados Unidos) durante la celebración del congreso mundial OSCON, evento que reúne a toda la comunidad de ingenieros y desarrolladores de software y hardware libre.
Es así que ObiJuán se ha ganado su hito en la muy famosa Wikipedia (hasta que Skynet? cobre conciencia de sí misma y borre nuestra adición de los ganadores del año 2017 en esa página, ja, ja, ja).
Ni os imagináis la ilusión que me hace aparecer en wikipedia?Este es el mayor de los premios¡Muchas gracias a todos!https://t.co/wgUTcNScTP
Eterno empedernido de la saga de películas «La Guerra de las Galaxias «Star Wars»» -¡ejem! nosotros también ?- se autodenomina por este juego de pronunciación en inglés y castellano del Maestro Jedi de los films Obi-Wan Kenobi como ObiJuán (nosotros castellanizamos aún más las cosas con la inclusión del acento) este madrileño ejemplar comenzó sus andanzas …
¡Este blog no va de ciencias sociales! No somos biógrafos de profesión, nuestra intención es dar justo reconocimiento al que «sabemos que sabe»; los lectores de este humilde portal y de nuestra cuenta Twitter pueden dar fe de que siempre reconocemos al que sabe más que nosotros y es así que aprendemos y luego difundimos el conocimiento adquirido. Sigamos pues, con nuestra entrada de hoy.
…comenzó sus andanzas en el servicio militar obligatorio («la mili») y es allí donde le «encasquetaron» el apodo por ser tan fanático de «Star Wars».
Ya desde el año 1996 «lidia» con Linux pero ya desde muy joven «lo que se le da» es lo de la informática. Sufrió lo mismo que Richard Stallman (y nosotros también desde los años 80): un mundo privativo donde te ofrecen «comprar, usar y desechar» * pero no preguntes cómo funciona*.
Uno de sus primeros cacharros fue ZX-Spectrum donde comenzó con el lenguaje BASIC (¿y quién no ha comenzado con ese lenguaje? ¡Ah, ahora los chavales estudian Python, menuda «paliza» para nosotros los vejetes!). Luego aprendió por su propia cuenta Pascal (¡ea, que yo tuve que pisar la universidad para poder aprender este lenguaje! ?) , C, Prolog, y ensamblador (eax, ebx, ebp y esp fueron sus grandes amigos). Luego al entrar en el mundo GNU/Linux reafirma C, y aprende C++ y Python.
Comenzó la universidad en 1991 y su primera obra fue el Sistema Tower Pro Tarjeta CT6811 para su sueño hecho realidad: el robot Tritt (que ya vendrá algún día el «Mazinger ?», porque ya el R2D2 lo tuvo… ¡como impresora 3D, con dinastía y todo!). De 1996 al 98 se dedica en cuerpo y alma -pesetas de por medio- al campo de los micro-robots y es cuando emprende su cruzada de hacer una España con un fuerte desarrollo endógeno para librarse de la dependencia tecnológica extranjera: producir y crear todo en su tierra natal (dichas batallas aún se libran fuertemente y se ganan poco a poco con muchísimo esfuerzo, solo que ahora no está solo, sus padawan‘s lo acompañan y apoyan).
En 2003 ya hablaba de los problemas del hardware libre mediante conferencia dictada en el VI Congreso de Hispalinux y llegó a la conclusión que son los planos de hardware son los que cumplen con las 4 premisas del software libre y por ende es así que debe ser considerado el hardware libre (ahora va de que preguntéis de dónde proviene el nombre GNU y obtendréis una respuesta enrevesada parecida).
En 2007-08 trabajó sobre un mando para wii y pudo lograr que controlara su robot Skybot, demostrando con ello que las empresas privativas tienen aún mucho más campo que cubrir si tan solo se dignaran a compartir el conocimiento.
Su «grito de guerra» es:
«Más vale proyecto publicado con licencia libre, que ciento en el cajón»
"Más vale proyecto publicado con licencia libre, que ciento en el cajón" #proverbioFriki
Patrimonio Tecnológico de la Humanidad: es que vamos a avanzar muchísimo más como Humanidad si compartimos el conocimiento! ¡Salimos ganando todos! La riqueza se va a distribuir muchísimo más… Esto se vio desde el principio en el mundo de la ciencia. Si tú no compartes lo que has descubierto, y te lo revisan otras personas, no avanzas, ya no es ciencia lo que haces.
Patrimonio Tecnológico de la Humanidad
Tuvo una fuerte influencia el trabajo del profesor Adrian Bowyer quien lanza al mundo la primera impresora para tercera dimensión «3D» a modo de hardware libre: fue desde entonces una revolución imparable en la cual ObiJuán se especializó y contribuyó -y seguirá aportando- en su conocimiento y masificación. Hasta ahora tiene construidas 270 impresoras 3D y podéis leer su trabajo enCloneWars en este enlace.
Así mismo lleva un canal en Youtube con multitud de tutoriales donde explica y comparte con suma paciencia su conocimiento y experiencia, añadiéndole como siempre su toque personal:
ObiJuán es apasionado de la tecnología y en 2016 comezó su proyecto épico: la reconstrucción del CPU del «Apolo 11», el proyecto espacial de la NASA que llevó a nuestra humanidad a la Luna; la «paleoarquitectura» de los ordenadores, sin duda una tarea ardua. Escuchemos en palabras del propio ObiJuán el proyecto de marras:
Para él fue una bendición la tecnología que aportó Arduino en los años 90, fue como la revista «Mecánica Popular» aplicado al mundo de la electrónica. Si Arduino abrió la posibilidad de combinar los componentes y ponerlos a funcionar con los FPGAs (Field Programmable Gate Array) tendremos la posibilidad de construir nuestros propios «chips» y eso ahora mismo es lo que mantiene más ocupado a ObiJuán. Esto es así porque a pesar de todos los títulos universitarios que ha logrado, lo que le apasiona es construir y verificar por sus propios medios (vamos que la ciencia se han de replicar los mismo resultados en las mismas condiciones): es de los que crea y observa, basado en la teoría, pero la destreza manual es bien sabido que abre nuestros cerebros a nuevas conexiones sinápticas y nuevas formas y maneras de ver las cosas, ¡es de los que dicen «no me fío de lo que me dices o alegas, dejadme probar y comprobar»!
A ObiJuán no le gustan los agradecimientos; nosotros por estos lares tampoco (de hecho, debido a la dura situación de nuestro país hasta ahora es que aceptamos donaciones) pero cuando la obra es grande ES IMPOSIBLE QUE PASE DESAPERCIBIDA. Desde 1989 que comenzamos a estudiar en la Facultad de Ingeniería de la Universidad de Carabobo nuestro punto de difusión de conocimiento era el boulevard al lado del cafetín principal, AHORA LO ES EL INTERNET POR EL MUNDO ENTEROy aunque en esa época ya sabíamos que difundir el conocimiento era la clave, no es sino hasta hace poco -en serio y en firme desde el año 2014- que entramos en el mundo del saber del software libre. Pero he aquí que ObiJuán no solo usa y difunde el software libre, ¡EL HARDWARE LIBRE TAMBIÉN! Nos aventaja por largo rato, y además se involucra en persona en causas sociales ¿Cómo no reconocer su labor? ¡Sería una injusticia!
Hoy tuvimos el regocijo de leer un artículo publicado por los colegas de LinuxAdictos donde hablan sobre comandos pocos conocidos para la terminal GNU/Linux. Es por ello que decidimos publicar nuestra propia entrada pero dandole valor agregado: vamos a enfocarlo desde nuestra distribución preferida, Ubuntu Desktop (actualmente usamos las 16.04 LTS) y también como suplemento a nuestra otra entrada sobre la introducción a la cónsola de comandos; ¡venid y acompañadnos en la búsqueda del conocimiento!
Pues eso, comandos poco conocidos que ya vienen por defecto ya instalados en Ubuntu, nada más teclearlos los podemos utilizar. Lo que haremos acá es teclear el comando «man» seguido de un espacio y el nombre del comando a conocer, leeremos su descripción en inglés y las traduciremos y le buscaremos propósitos prácticos, comencemos pues.
Comando «calendar»:
El comando «calendar» pertenece al paquete de bsdmainutils que viene por defecto en la distro GNU/Linux que utilizamos para esta entrada, Ubuntu 16.04 Xenial. Dado el caso extraño que no lo tengáis instalado podéis hacerlo con el comando «sudo apt-get install bsdmainutils» y sin ir a mucha profundidad en la materia, podréis ver los archivos que componen ese paquete de software en este enlace.
Este paquete proviene del muy antiguo sistema Unix (el comando «man calendar» especifica que un comando calendar apareció en la «Version 7 AT&T UNIX» en 1979) y ciertamente que nos fue difícil encontrar a quien o quienes actualmente mantienen dicho repositorio, ya que el mero hecho de ser un calendario implica lo más dinámico de este mundo: el transcurrir del tiempo es siempre cambiante. En un «fork» al que tuvimos acceso hecho por Andrey Ulanov < drey @ rt.mipt.ru > en el año 2002 comenta que proviene de OpenBSD e incluye una licencia que se hereda de cada uno de sus componentes, por ejemplo el módulo pathnames.h nos da la siguiente información:
/* $OpenBSD: pathnames.h,v 1.3 1996/12/05 06:04:41 millert Exp $ */
/* $Id: pathnames.h,v 1.1.1.1 2002/11/26 23:37:38 drey Exp $ */
/*
* Copyright (c) 1989, 1993
* The Regents of the University of California. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* 3. All advertising materials mentioning features or use of this software
* must display the following acknowledgement:
* This product includes software developed by the University of
* California, Berkeley and its contributors.
* 4. Neither the name of the University nor the names of its contributors
* may be used to endorse or promote products derived from this software
* without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
* FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
* DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
* OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
* HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
* LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
* OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
* SUCH DAMAGE.
*
* @(#)pathnames.h 8.1 (Berkeley) 6/6/93
*/
Como véis se remota hasta el año de 1989, época en la cual apenas nosotros entrábamos a estudiar en la universidad, ¡fascinante como pasa el tiempo! Otra cosa es la fuente de bsdmainutils en la distribución Debian donde el propio Ian Murdock introdujo código fuente según se puede leer en esta página (no obstante acá la reproducimos de igual manera):
This is a collection of programs from 4.4BSD-Lite that have not (yet)
been re-written by FSF as GNU. It was constructed for inclusion in
Debian Linux. As programs found here become available from GNU sources,
they will be replaced.
This package was originally put together by Austin Donnelly
<and1000@debian.org>, but is heavily based on bsdutils, originally put
together by Ian Murdock <imurdock@gnu.ai.mit.edu>. Please report any
problems or suggested additions or changes to Austin Donnelly.
Then the package has been maintained by Charles Briscoe-Smith
<cpbs@debian.org>. I gathered data for the 1999-2001 calendar files
from various sources on the Internet, and I'd also like to thank Oliver
Elphick, Julian Gilbey, Daniel Martin and Jaldhar H. Vyas for providing
much useful data on the various religous calendars. I have edited the
files they provided to fit calendar's requirements, so any errors should
be attributed to me.
After cpbs@debian.org, Marco d'Itri <md@linux.it> maintained it for
almost two years, before Tollef Fog Heen <tfheen@debian.org> took over.
The package is now maintained by Graham Wilson <bob@decoy.wox.org>.
This package may be redistributed under the terms of the UCB BSD
license:
Copyright (C) 1980 -1998 The Regents of the University of California.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions
are met:
1. Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
4. Neither the name of the University nor the names of its contributors
may be used to endorse or promote products derived from this software
without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
Usando el comando «calendar».
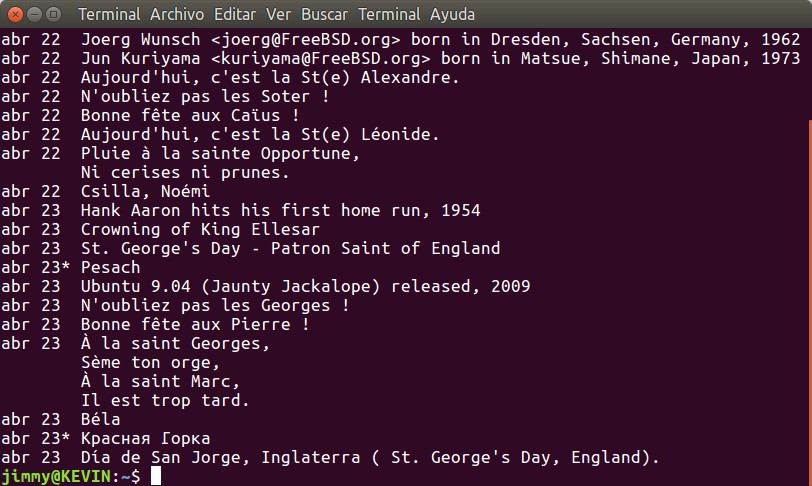
Nada más en la terminal al introducir el comando sin ningún parámetro veremos algo similar esto, os indicamos que la salida por pantall dependerá de la fecha de vuestro ordenador y os dará resultados similares o diferentes:
Figura 1:
bsdmainutils calendar 22 y 23 de abril
Notad la última línea en castellano, ya os explicaremos luego. Como bien podéis observar la cosa va en idioma inglés lo cual no representa problema, tal cual el latín en el mundo antiguo fue la lengua franca así lo es hoy este idioma. Lo que os advertimos es que hay varios idiomas más, tales como el francés y el ruso [justo arriba del Día de San Jorge esta en ruso el «Красная горка (праздник)» -aparición de Jesucristo a sus discípulos y la conversión del Apóstol Tomás-] y aunque no tiene calendarios del planeta entero, la intención del programa es bueno y tiene dos utilidades extras que estudiaremos pronto.
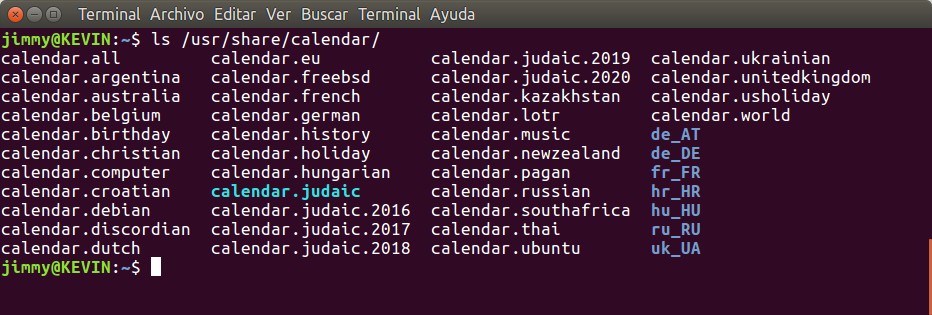
¿De dónde saca este programa calendar los datos a mostrar por pantalla? En la carpeta /usr/share/calendar/ de nuestros ordenadores se almacenan una serie de ficheros con el nombre, cómo no, calendar pero con diferentes extensiones cada uno, por ejemplo .russian, .christian o .computer.
Figura 2
ls usr/share/calendar
Como bien imaginamos por los metadatos, cada extensión describe lo que contiene el archivo y cuando llamamos al programa calendar simplemente lee y extrae los datos correspondientes a la fecha actual de cada fichero, pero hay más: también hay unos directorios con nombres claves que describen las dos primera letras el idioma separados de un guión bajo y dos letras más en mayúsculas que describen el país. Así tenemos que el directorio de_AT contiene en idioma alemán («deuschtland» en inglés) del país Austria (AT) donde se habla el alto alemán, más inclinado hacia el latín; de segundo en el listado está de_DE que corresponde al idioma Alemán de Alemania (ea, eso sonó feo en nuestro bello idioma castellano, nuestro idioma no es amistoso con esto de las redundancias).
Como somos unos «hackers» -o estamos en camino de ‘graduarnos’- podemos hacer uso del comando grep y la ‘tubería’ «|» para filtrar resultados por una palabra clave específica, por ejemplo «Bonne fête» o «Feliz cumpleaños» en francés, para ello teclearemos lo siguiente: calendar | grep «Bonne fête» y solo tendremos dos líneas –o ninguna o varias, repetimos que eso depende de la fecha de nuestro ordenador-.
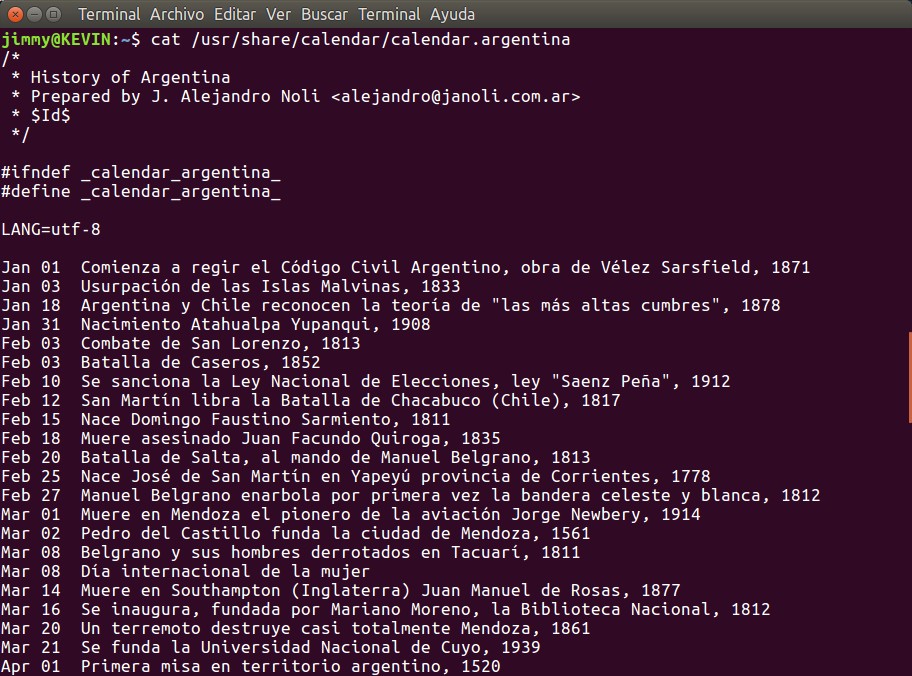
Esto es para búsquedas puntuales y exactas (claro que con el uso de expresiones regulares podremos ampliar la búsqueda -mayúsculas/minúsculas, caracteres comodín, etc), pero ¿qué tal si queremos ver temas específicos? Veamos alguno de estos ficheros de datos con fechas y busquemos uno que está en nuestro idioma, por ejemplo «calendar.argentina». Si le damos el comando cat en la ubicación /usr/share/calendar al fichero calendar.argentina:
Figura 3
cat usr/share/calendar/calendar.argentina
Evidentemente escrito en lenguaje C notamos un encabezado describiendo el autor, unas variables de enlace para ser compiladas, el conjunto de caracteres a emplear y el conjunto de datos, uno por cada línea. Comienza con el mes abreviado en tres letras del idioma inglés, espacio, dos dígitos -cero a la izquierda de ser necesario-, caracter tabulador y luego la descripción del evento del correspondiente día.
Sumamente importante a destacar es que debemos separar la fecha de la descripción por medio del caracter tabulador( Tab↹ ), de lo contrario la línea no será mostrada en el calendario (nuevo en esta versión y que se diferencia de versiones anteriore según «man calendar«).
Hasta acá lo único especial son los comandos en lenguaje C ya que los eventos están muy bien «formateados» en texto plano pero son precisamente esas referencias en C las que nos indican que hay algo más. Esto quiere decir que «calendar» tiene una estructura rígida y que deben tener esos encabezados pero la cosa no termina allí. Si detalláis en la «Figura 2» nosotros agregamos un fichero calendar.venezuela con encabezado en toda regla y unos pocos acontecimientos históricos de nuestro país pero nada de nada, no lo muestra para nada. Eso quiere decir que solamente se atiene a los archivos que vengan con el paquete para probar esto último modificamos el fichero calendar.unitedkingdom:
Y modificamos la línea del 23 de abril, Día de San Jorge, le colocamos la descripción en castellano y la muestra por pantalla sin problema alguno (figura 1). Lo bueno del software libre es que tenemos acceso directo al código fuente y podemos modificar y compilar, ya sea de manera estática o dinámica, a gusto con nuestras modificaciónes. Pero antes de hacer esto sigamos estudiando las opciones ya establecidas en el comando «calendar» y luego veremos que más podemos hacer.
Parámetros del comando «calendar»:
Primero podemos consultar los eventos de cualquier otra fecha simplemente acompañando de un espacio, el comando del parámetro «-t«, otro espacio, y la fecha en formato AAAAMMDD, por ejemplo el 30 de diciembre de 2017 lo solicitamos de la siguiente manera:
calendar -t 20171230
Desglosamos la respuesta y no vemos por ningún lado la nota con el fallecimiento del gran Ian Murdock, padre de la distribución Debian (madre a su vez de Ubuntu) y que tiene su propio fichero calendar.debian. Por si acaso es que estamos cegatones volvemos a aplicar el comando grep de la siguiente manera:
calendar -t 20171230 | grep "urdock"
El cual no devuelve nada, aunque si usamos
calendar -t 20171230 | grep "KPD"
Sí que obtenemos respuesta: «Gründung der KPD, 1918», «Kommunistische Partei Deutschlands» o establecimiento del Partido Comunista Alemán, el 30 de diciembre de 1918. Es por ello que tecleamos el comando
sudo nano /usr/share/calendar/calendar.debian
y agregamos la siguiente línea (recordad de insertar pulsar la tecla Tabulador entre la fecha y la descripción):
Dec 30↹Ian Murdock, stalwart proponent of Free Open Source Software, Father, Son, and the 'ian' in Debian.
Guardamos y listo, guardamos el recordatorio de tan lamentable fallecimiento para futuras generaciones ??.
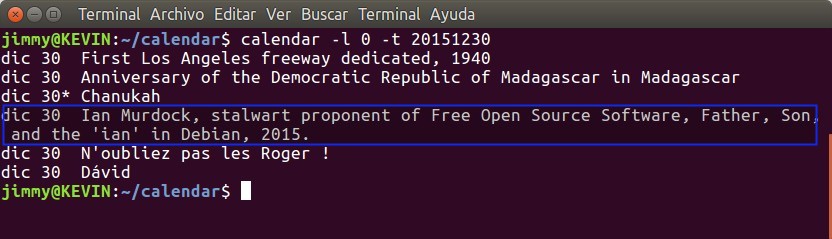
Por defecto el comando calendar muestra dos días de acontecimientos (el nombre correcto son recordatorios) pero podemos especificar el número de días con el parámetro -l acompañado del número de días hacia adelante que queremos visualizar (nota: el otro parámetro que hace exactamente el mismo trabajo es -A pero como se presta a confusión con el otro parámetro –a usaremos siempre -l). Así si queremos ver exactamente los recordatorios del 30 de diciembre debemos teclear lo siguiente:
calendar -l 0 -t 20151230
Figura 4
calendar -l 0 -t 20151230
Con el parámetro -B podemos especificar hacia atrás en el tiempo, desde la fecha señalada por el parámetro -t, el número de días que queramos ver. Por cierto que si se obvia el parámetro -t se toma la fecha del ordenador y si es viernes mostrará hasta el próximo lunes siguiente (si hay recordatorios); el parámetro -w se basa en eso para especificar el número de días hacia el futuro, pero no hayamos especialmente útil esa opción.
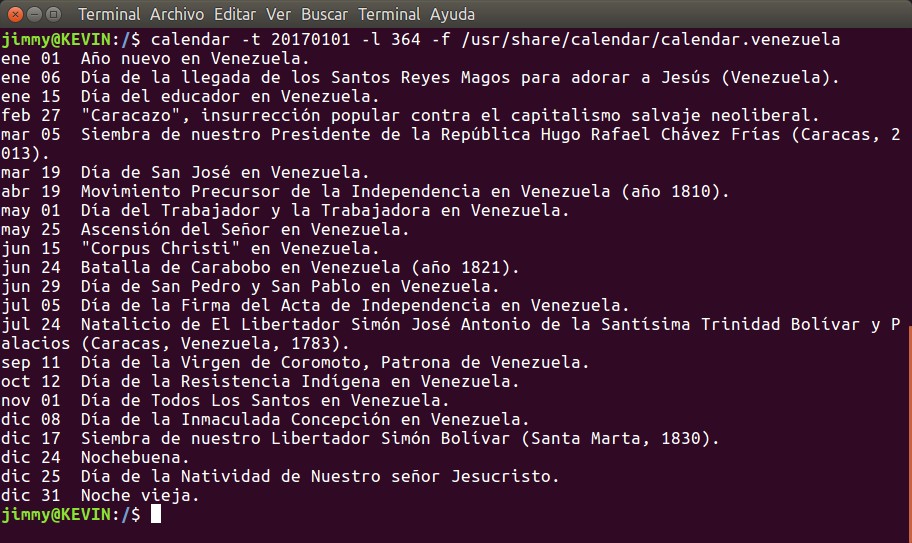
¿Recuerdan que comentamos haber realizado un calendario para Venezuela? Pues bueno llegó la hora de poder visualizarlo con el parámetro -f acompañado de la ruta de ubicación del archivo de marras, para ello metemos:
¿Qué tal nos ha quedado? Para subir este archivo y contribuir con el software libre publicaremos dicho archivo en GitHub con licencia «Creative Commons» e instrucciones sobre como instalarlo y utilizarlo.
Instalando «calendar.venezuela» en nuestro ordenador.
Según las instrucciones en el archivo calendar.alldeberíamos copiar dicho archivo a nuestra carpeta personal «~/.calendar/» si queremos editar dicho archivo. Esto es así ya que si compartimos un ordenador con varias personas lo lógico es que cada quien tenga su calendario particular, es decir, en el fichero «calendar.all» podemos especificar cuales ficheros queremos ver y/o utilizar. Si lo copiamos a nuestro perfil personal podemos editarlo sin molestar a los otros usuarios del sistema.
En nuestro caso decidimos modificar el archivo calendar.all para todos los usuarios para que tengan acceso al fichero de recordatorio de Venezuela (ambos en la carpeta /usr/share/calendar/). Para ello agregamos al archivo la siguiente línea, justo al final, por orden alfabético:
#include <calendar.venezuela>
Luego guardamos y podemos inmediatamente comprobar si funciona. De igual manera así como agregamos, podemos «quitar» ficheros de recordatorios que no pensamos usar. En realidad quitamos es la referencia o referencias, no el o los archivos en sí mismos.
Comandos «cal» y «ncal»:
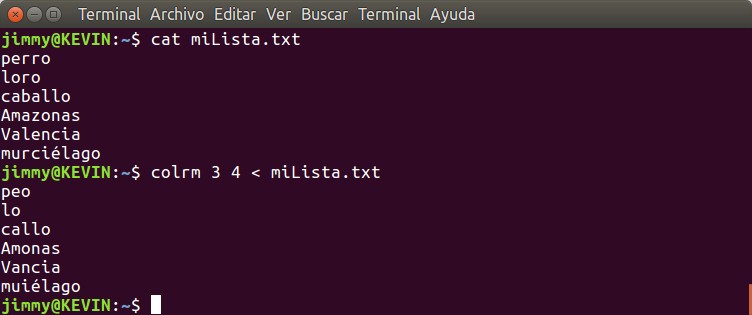
Si necesitamos ver por pantalla el mes actual simplemente tecleamos cal y lo veremos por pantalla y el día actual estará resaltado. De manera similar funciona ncal pero en vez de tener los días de la semana en el eje de las abscisas los coloca en el eje de las ordenadas. Los parámetros son comunes a ambos comandos, pero tienen sus excepciones (os queda como tarea averiguar cuáles):
Si no queremos ver resaltado el día actual usaremos el parámetro -h.
Si queremos ver un mes específico del año actual usaremos -m n donde n es el número del mes. También podemos colocar las tres primeras letras del mes (inglés o castellano, sin embargo no reconoce francés ni ruso).
Si queremos ver el año completo -en curso- colocamos -y. Si necesitamos un año específico lo colocamos al lado (calendario gregoriano). Por ejemplo podremos saber que el 26 de diciembre del año 7017 será un día viernes. ?
Podremos combinar mes y año en la misma orden, ejemplo: cal -m 12 2117 mostrará el mes de diciembre del año 2117.
Algo muy útil es visualizar el mes anterior, el actual y el venidero: para ellos usamos el parámetro -3.
Para ver varios meses hacia adelante, -A seguido del número de meses; -B especifica los meses hacia atrás. Ejemplo: «cal -B 1 -A 3″.
Como sabemos el día cero en informática es el domingo, día del Señor, quien al séptimo día tomó descanso (sábado para los judíos). Para nosotros los católicos el domingo es día de adorar a Dios así que comenzamos a trabajar los lunes, por ello podemos especificar que las semanas comienzen los días lunes con -M y con -S comienzan los domingos (opción por defecto). Esta opción no funciona con cal no obstante ncal tiene un parámetro -b que tiene el mismo estilo de cal, ¡probad!
Comando «yes»:
Brevemente diremos que es un comando para nosotros los «nerds»: el comando yes repite indefinidamente por pantalla el texto que lo acompañe. Para detenerlo debemos usar la combinación de teclas CTRL+C (esto es válido para todos los comandos de terminal). Viene con el conjunto de utilerías básicas GNU.
Comando «col»:
El comando col también es poco conocido pero tiene el aliciente de trabajar con los comandos nroff,tbl y colcrt; sin embargo le hallamos cierta utilidad didáctica si lo combinamos con los caracteres especiales utilizados para el shell y el lenguaje C. Es por ello que comenzaremos de atrás para adelante: presentamos los caracteres especiales y terminamos con el comando col.
Pues bien, en el juego de caracteres ASCII (ahora sustituidos por los caracteres UNICODE y representados de manera práctica con UTF-8 –revisad nuestro tutorial sonbre HTML5- ) los primeros 31 caracteres son especiales, llamados «de sistema» y tienen diversos usos especiales. Como abreboca tenemos el ACK (acknowledgement) o reconocimiento: si recibimos un datagrama por TCP (o un paquete por puerto serial) y el contenido es recibido de conformidad a reglas preexistentes simplemente contestamos enviando dicho caracter, el número 6 en sistema de numeración decimal (en sistema binario es 000 0110 e igual es 6 en octal y hexadecimal). Además de esta numeración en el lenguaje C (así como Java, Perl e incluso Visual Basic) se le representa con caracteres de escape (esto se presta a confusión a la hora de traducir al castellano, ojito como lo interpretáis). Estos caracteres de escape tienen la función de salir, escaparse de la representación tal como son y se interpretan por pantalla e impresoras de matriz de punto (y algunas de inyección de tinta) de manera diferente. ¿Qué diantres tiene esto que ver con la terminal GNU/Linux o «shell»? ?
Vamos a la práctica directamente con solamente un caracter: el número 11 que corresponde al tabulador vertical (no confundir con el tabulador horizontal) al cual podemos almacenar en una variable con ayuda del operador $ el cual interpreta los códigos «escapados» por medio de «\0» -si es octal- o «\x» si es hexadecimal. En este caso sería «\013» en octal o «\xob» en hexadecimal. Corred los siguientes ejemplos en vuestra terminal:
Como notaréis aparentemente no vemos nada por pantalla y para notar como trabaja el tabulador vertical podemos acompañarlo de texto descriptivo de la siguiente manera, mirad la animación:
comando col
Allí veís el famoso comando col en acción. Otra forma de representar al tabulador vertical en lenguaje C es con «\v«:
jimmy@KEVIN:~$ linea=$'\vLinea 1.\vLinea 2.\vLinea 3.'
jimmy@KEVIN:~$ echo "$linea"
Linea 1.
Linea 2.
Linea 3.
jimmy@KEVIN:~$
Comando «colrm»:
El comando colrm nos permite remover la primera n columnas ya sea de un archivo de texto o lo que ingresemos por cónsola de comandos. Hacemos notar que la numeración comienza en uno y no en cero como la mayoría de las matrices en computación. El ejemplo aclara dudas:
comando colrm n+1 columnas
Otro uso es suministrarle dos parámetros: la columna de inicio y el largo que removerá:
comando colrm n m columnas
Comando «column»:
El comando column viene a ser de utilidad si queremos mostrar en columnas una lista que tengamos ya sea en un archivo o en una entrada de texto de terminal con el conector tubería «|«.
comando column
Comando «from»:
Este comando permite visualizar lo que hallan enviado los usuarios por el sistema de correo en un ordenador GNU/Linux. Sirve como sistema de comunicación enre los usuarios registrados en un ordenador.
Comando «hexdump»:
Permite desglosar los códigos ASCII en su representación decimal, octal o hexadecimal e incluso aplicandole un formato específico (aparte de los que trae de manera predeterminada) ya sea de un archivo o por entrada de terminal. Acá vemos el formato más útil para dicho comando, pero las posibilidades son infinitas:
jimmy@KEVIN:~$ echo "ABCD" | hexdump -v -e '/1 "%_ad# "' -e '/1 "%02X hex"' -e '/1 " = %03i dec"' -e '/1 " = %03o oct"' -e '/1 " = _%c\_\n"'
0# 41 hex = 065 dec = 101 oct = _A_
1# 42 hex = 066 dec = 102 oct = _B_
2# 43 hex = 067 dec = 103 oct = _C_
3# 44 hex = 068 dec = 104 oct = _D_
4# 0A hex = 010 dec = 012 oct = _
Esencialmente usamos el comando echo para enviar las cuatro primeras letras del abecedario por medio del comando «tubería» «|» y entregarselo a hexdump el cual lo desglosa caracter a caracter y muestra su código ASCII en diferentes sistemas de numeración para luego insertar un retorno de carro al final de cada línea «\n«.
Comando «look»:
Si por ejemplo necesitamos buscar palabras que tengan un prefijo común, por ejemplo «oft», introducimos «look oft» lo cual devuelve unas cuantas palabras… en inglés (often: a menudo, frecuentemente). Si bien indica que depende de la configuración que tengamos en ENVIRON (por ejemplo podemos ver cual lenguaje tenemos configurado si tecleamos echo $LANG) siempre utiliza el idioma inglés por defecto. Para buscar una lista de palabras en idioma castellano deberemos especificar que usaremos el diccionario ubicado en /usr/share/dict/spanish. ¿Utilidad? Tal vez querramos hacer un ataque de fuerza bruta a una contraseña usando palabras comunes, quien sabe.
Comandos «wall» y «write»:
Con wall podremos enviar un mensaje a todos los que estén conectados o conectadas por cónsola, quieran o no recibir el mensaje. Por el contrario, si queremos enviar a un usuario específico usamos el comando write acompañado del nombre de usuario y la erminal donde esté conectado. Para saber quiénes están en línea usaremos who.
Otros comandos poco conocidos:
lorder, ul.
Comandos que se deben instalar desde repositorios oficiales.
La verdad es que revisando los temas publicados por nuestros colegas de GNULinuxBlog (por ahora quien publica el tema, el sr. Elías Rodríguez Martín y el sr. José Miguel, creador del blog) encontramos uno en particular muy útil y que nosotros habíamos enfocado de una manera un tanto complicada en comparación con la facilidad de lo que allí proponen. Cuando conseguimos que alguien es más listo que nosotros inmediatamente lo reconocemos y aprendemos de dichas personas, no tenemos rubor en admitirlo, por eso os pedimos que nos acompañéis en nuestro artículo de hoy: compartir ficheros de una manera rápida y sencilla con Python.
Ya brevemente hemos descrito cómo instalar Shutter en Ubuntu cuando publicamos nuestro tutorial sobre Tesseract OCR y en esta oportunidad le vamos a dar todo el protagonismo que Shutter merece con su reportaje dedicado y, para variar, lo instalaremos bajo la distribución Fedora 25, ¡acompáñanos!
Actualizado el día martes 11 de diciembre de 2018
¡También explicamos como instalar las herramientas de edición (de imágenes, por supuesto)!
Repetimos que esta página no va de ciencias sociales, sin embargo somos fanáticos de la ortografía y en esta oportunidad os presentamos una herramienta para corregir nuestros escritos, que ya son bastantes, por demás. Ahora es el punto donde nos diréis «ea, tío, ¿de qué vais si eso está integrado en ‘todos’ los programas?» Pues bueno preparaos a sorprenderos con los que os vamos a contar, ¡vamos a aprender a programar para corregir nuestra ortografía!