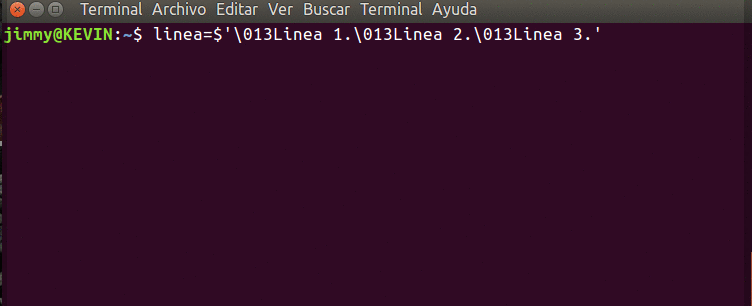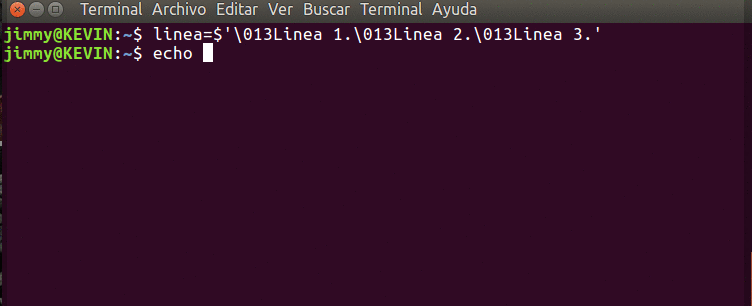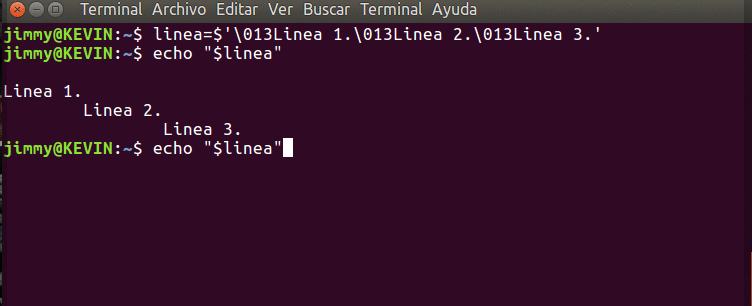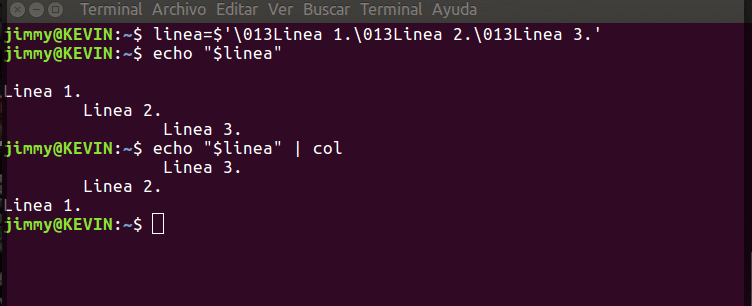
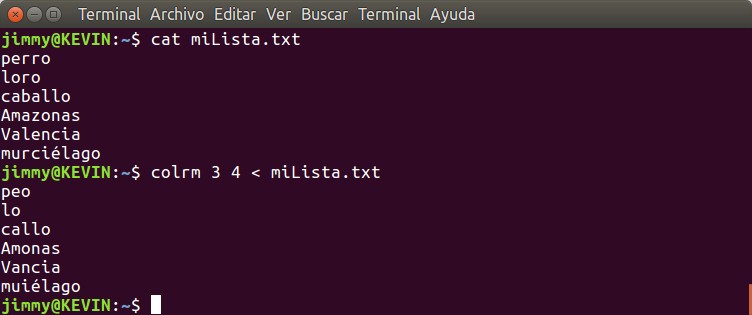
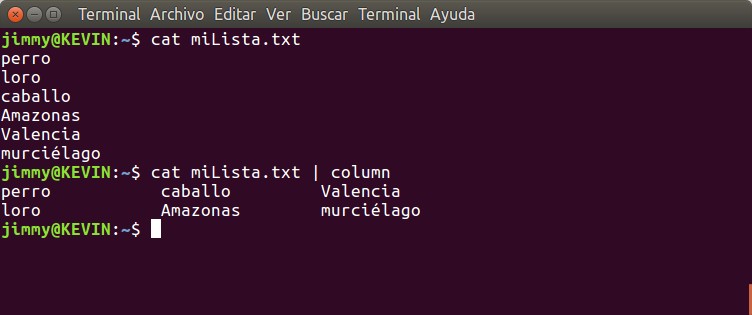
Iniciamos operaciones en 1993 en el sur de Valencia con una maquina XT8088 con 2 unidades de floppy de 5 1/4 y un monitor monocromatico: ¡HEMOS LLEGADO LEJOS!
Interesante es saber sobre cómo funciona el navegador web Mozilla Firefox (para nosotros, nuestro favorito) y vamos a diseccionar y explicar de manera sencilla, sin mayores pretensiones, sus diversos componentes. Para ello comenzaremos de atrás para adelante: el último Proyecto de Mozilla Firefox llamado «Quantum«, ¡Investiguemos juntos!
En el tutorial anterior sobre registro de eventos con «logging» utilizamos a «argparse« para permitir a nuestros usuarios y usarias a establecer un nivel de registro de eventos en caso de ser necesario hacer seguimiento a nuestra aplicación. Prometimos allí ahondar con un tutorial completo sobre el tema y aquí lo prometido, ¡estudiemos juntos!
Introducción.
Para no caer en la redundacia, os recomendamos leer nuestro trabajo anterior, la sección «aislada» sobre argparse. Allí colocamos como ejemplo el comando ls;en realidad casi todas las aplicaciones que corren sobre la línea de comando aceptan argumentos a la derecha conformando parte de la orden de ejecución al presionar la tecla enter o intro.
Como dijimos en nuestro anterior tutorial sobre el registro de eventos en nuestras aplicaciones, argparse proviene de optparse el cual a su vez fue «descontinuada» desde la versión Python 2.7 ¿Por qué entrecomillamos? Lo hacemos porque como es software libre cualquiera puede hacer una bifurcación «fork» y continuar desarrollandolo a su gusto y conveniencia. De hecho se lleva un desarrollo en paralelo en GithHub como adelante veremos.
Lo bueno del asunto es que son bastantes similares en cuanto a su sintaxis y esto es así para facilitar a los desarrolladores que usaron optparse y ahora necesitan la migración a argparse.
Código previo a argparse.
Pero antes de entrar de lleno en argparse y como éste es un tutorial dedicado a dicha librería, vamos a ir un poco más allá: las bases sobre las cuales funciona argparse. Ya bien lo dice Richard Stallman, padre del software libre: «Nadie, ni siquiera Beethoven podría inventar la música desde cero. Es igual con la informática».
He aquí que una de las librerías básicas en el entorno de programación Python lo es sys. Para agregarlo a nuestros programas debemos enlazarlo con el comando import sys y podremos comenzar a usar sus objetos, los cuales no estudiaremos completamente en este tutorial sino que vamos a centrarnos en uno de sus componentes: sys.argv. Por medio de éste podremos acceder a la cadena de texto completa con la que el usuario o usuaria haya invocado nuestra aplicación por medio de la línea de comando. De una vez vamos a la práctica, tras esta muy breve teoría:
import sys
print("Número de argumentos: ", len(sys.argv))
print("Los argumentos son : ", str(sys.argv))
Explicación: sys.argv es, simplemente, una lista con cada palabra (entendiendose como palabra cualquier cadena de texto delimitada por al menos un espacio) con la que se invoca el guion «script» de nuestro, o de cualquier, programa.
La primera línea «enlaza» con la librería sys, permite cargarla en memoria y nos permite acceder a sus métodos , eventos y constantes.
La segunda línea usa la función len() que obtiene el largo de la lista, osea, el número de elementos -léase palabras-con la que se invocó nuestro guion «script».
La tercera línea muestra por pantalla todos y cada uno de los elementos de la lista especial.
Lo más curioso del asunto es que podemos no solamente acceder a la lista sino que también podemos cambiar sus valores, ¡probad! Lo que si es cierto es que el primer elemento (elemento cero) será siempre el nombre del fichero que almacena el guion escrito en python, con todo y extensión (aunque si no tuviera extensión .py igual se ejecuta) y los demás elementos de la lista son los argumentos o parámetros ya sea que lo escriba el usuario o le sea pasado al programa por el comando tubería «pipe» o «|» o en una variable en un guion «script» BASH.
Instalando argparse en nuestros ordenadores.
Para eliminar todo tipo de dudas, usamos Python versión 3.X -ya lo hemos dicho en nuestras entradas anteriores, revisad- y probablemente ya tengáis instalado argparse en vuestro ordenador. Al usar el comando import argparse y de no estar instalado de inmediato sale el mensaje de error en Python por lo que podemos instalarlo de diferentes maneras.
Por medio de pip3.
Para instalar argparse por medio de pip3 debemos escribir pip install argparse con los debidos derechos de administrador y así poder descargarlo de internet. Explicamos: pip3 es un esfuerzo en reunir en un repositorio de aplicaciones oficial de muchos software hecho por terceros pero que son supervisadas de manera directa por el equipo desarrollador de Python. Para saber si tenemos instalado pip3 simplemente escribimos pip3 –version y mostrará la versión instalada (ah, y de paso mirad otro ejemplo de argumentos en una aplicación «–version«) y dado el caso que no la tengamos instalada podremos usar:
En GitHub hallaremos el repositorio de Thomas Waldmann quien claramente advierte que el desarrollo de argparse es almacenado oficialmente por el equipo de desarrollo de Python pero que él mantiene una copia para quienes tengan Python 2.X y quieran agregar argparse a sus aplicaciones. De tal manera que si vosotros no lo tenéis instalado y no queréis -o no podéis- usar pip3 pues clonad el proyecto y ejecutad setup.py
Para los que les gusta la «arqueología» de software en Google podéis deleitaros en el siguiente enlace (tal parece que años atrás estaba alojado por aquellos lares antes de ser migrado el código fuente de argparse a la Fundación Python).
Observación importante:
Si sois como nosotros que tenemos instalado tanto Python 2 como Python 3 os damos el siguiente dato: si abrís un guion o programa con Python 2 y usáis argparse se generará un archivo precompilado «.pyc» cuya finalidad es cargar más rápidamente nuestro programa en sucesivos llamados. Luego si abrís el mismo «script» con Python 3 obetendréis un mensaje de error más o menos indicando «error en magic number«. Lo que debéis hacer es simplemente borrar todos los archivos «*.pyc» -por si las dudas- que en cuanto se vuelvan a ejecutar se generarán de nuevo. Advertidos quedáis ? .
Primeros pasos con argparse.
Tan solo debemos escribir nuestro guion de la siguiente manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.parse_args()
Primero llamamos a la librería y luego a un ubjeto analizador le asociamos con nuestra descripción de aplicación. Luego le ordenamos que muestre por pantalla los argumentos recibidos desde la línea de comandos. Así de sencillo -y esa es la idea- con tres simples líneas tenemos acceso al pase de parámetros y opciones por la línea de comando. Al llamar sin más el guión no veremos ningún resultado -aparente-. Pero si ejecutamos lo siguiente:
python3 tutorial_argparser.py -a
Veremos la siguiente respuesta:
usage: tutorial_argparser.py [-h]
tutorial_argparser.py: error: unrecognized arguments: -a
Nota importante: nosotros guardamos el programa en un fichero llamado tutorial_arparse.py y tal vez se sientan tentados a no escribir tanto y nombrarlo simplemente argparse.py ¡No lo hagáis! Sucederá que al ejecutar el guion se llamará a si mismo primero antes que buscarlo en las librerías Python. Este es el comportamiento predeterminado para nosotros cargar nuestras propias librerías: toda «importación» buscará primero en la carpeta donde está guardado el guion. Ya sabéis entonces.
Como véis ya argparse está trabajando para nosotros. La primera línea con el encabezado «usage:» indica los argumentos válidos -en este caso opcionales ya que está encerrados entre corchetes- y vemos que tiene la opción «-h». La segunda línea nos indica que ha sucedido un error en el archivo tutorial_argparser.py e indicando que es un argumento no reconocido lo que le acabamos de escribir: «-a«.
Lo que tenemos que experimentar ahora es precisamente «correr» el programa con el argumento «-h» y como probablemente ya sabéis ése es precisamente la orden para solicitar ayuda, veamos:
python3 tutorial_argparser.py -h
Obtendremos el siguiente mensaje:
usage: tutorial_argparser.py [-h]
Tutorial sobre argparse.
optional arguments:
-h, --help show this help message and exit
De nuevo la primera línea nos muestra los argumentos disponibles. La segunda ofrece la descripción de nuestro programa, la que le indicamos al inicializar la librería. La tercera línea (obviamente las líneas en blanco no la numeramos por propósitos didácticos) nos indica lo que hace el argumento solicitado: muestra el mensaje de ayuda y sale sin ejecutar ningún otro código. Notad que incluso nos muestra una opción «larga» del argumento de ayuda: «–help«. El siguiente paso es agregar nuestro primer argumento, veamos.
Agregando nuestro primer argumento a nuestro programa.
Argumento opcional:
Para que un argumento se opcional debemos antecederlo de un guion «-«; modifiquemos nuestro fichero de la siguiente manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument("-a", help="Detecta y confirma nuestro primer argumento.")
argumento = analizador.parse_args()
if argumento.a:
print("Argumento opcional solicitado: -a")
print("Argumento acompañado de:"+argumento.a)
else:
print("Ningún argumento.")
Allí con el método «.add_argument» establecimos la palabra clave «-a» y colocamos una breve descripción que será mostrada al solicitar ayuda con la consabida «-h» o «–help» la cual de una buena vez pedimos y obtenemos:
usage: tutorial_argparser.py [-h] [-a A]
Tutorial sobre argparse.
optional arguments:
-h, --help show this help message and exit
-a A Detecta y confirma nuestro primer argumento
Ahora empezamos a probar el nuevo argumento, se lo pasamos a la aplicación con el comando
$ python3 tutorial_argparser.py -a
y gentilmente nos advertirá que se necesita un argumento para la opción «-a«, es decir, será opcional, pero una vez que lo llamamos debemos acompañarlo de una cadena de texto, mirad:
Argumento opcional solicitado: -a
Argumento acompañado de:¡Hola!
Es hora de acompañar el argumento «-a» de una opción larga, nemotécnica, así que establecemos que sea «–aviso«: ya uséis uno u otro el comportamiento será el mismo.
analizador.add_argument("-a", "--aviso", help="Detecta y confirma nuestro primer argumento.")
argumento = analizador.parse_args()
if argumento.aviso:
print("Argumento opcional solicitado: --aviso")
print("Argumento acompañado de:"+argumento.aviso)
else:
print("Ningún argumento.")
Notad que tuvimos que cambiar el método «.a» por «.aviso«. También debemos agregar un entrecomillado si la frase que queremos pasar contiene varias palabras, de lo contrario argparse los interpretará como si fueran varios argumentos diferentes unos de otros:
Debemos acotar que, por defecto, argparse espera que sean cadenas de texto los argumentos que le pasemos a menos que le indiquemos expresamente lo contrario. Si necesitaramos pasar algún valor numérico, y que sea interpretado como tal, debemos agregar la opción type=int en donde definimos el argumento. Para darle utilidad esto último, cambiamos para que muestre repetidamente tantas veces como indique el número que pasemos, mirad atentamente:
mport argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"-a",
"--aviso",
help="Detecta y confirma nuestro primer argumento",
type=int
)
argumento = analizador.parse_args()
if argumento.aviso:
print("Argumento opcional solicitado: --aviso")
for x in range(0, argumento.aviso):
print("Argumento acompañado de:"+str(argumento.aviso))
else:
print("Ningún argumento solicitado")
Los cambios que hicimos implican usar la función str() que convierte la variable de tipo entero numérico a cadena de texto para poder usar el ciclo «for():«, así imprimirá el mensaje tantas veces como sea solicitado.
La isntrucción «type=» es poderosa, de hecho puede albergar cualquier tipo de variable, objeto ¡e incluso una función! Por ser tan avanzada por ahora no la estudiaremos en profundidad.
Ahora vamos a ver argumentos necesarios para ejecutar nuestro guion.
Argumento obligatorio.
Muchas aplicaciones precisan de un argumento obligatorio, por ejemplo, si está diseñada para analizar y trabajar con el contenido de un fichero pues es necesario indicarle que se debe pasar un nombre de archivo. Para ello modificaremos de nuevo de esta manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"archivo",
help="Indica el nombre del fichero a trabajar.",
)
argumento = analizador.parse_args()
if argumento.archivo="archivo":
print("Argumento OBLIGATORIO solicitado: archivo")
print("Nombre del archivo:"+argumento.archivo)
Si corremos sin parámetro alguno nos indicará que DEBEMOS indicar un nombre de fichero; si lo agregamos veremos esto:
$ python3 tutorial_argparser.py lista.txt
Argumento OBLIGATORIO solicitado: archivo
Nombre del archivo:lista.txt
Argumento obligatorio repetido n veces («nargs=n«).
Muchas veces una aplicación necesita un archivo origen de donde sacar datos, procesarlos y verter la respuestra en otro archivo: para ello podemos utilizar el siguiente código:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nom_arch",
nargs=2,
help="Indica el nombre de los ficheros origen y destino a trabajar.",
)
argumento = analizador.parse_args()
if argumento.nom_arch:
print("Argumento OBLIGATORIO solicitado: nom_arch")
print("Nombres de los archivos:")
print(argumento.nom_arch[0])
print(argumento.nom_arch[1])
Observad la línea nargs=2: le estamos indicando que necesita dos argumentos (o los que necesitemos) , la desventaja de este método es que al usuario colocar un solo argumento argparse emite un mensaje que puede ser confuso, no es un mensaje explícito (recordad las reglas de oro de Python: explícito es mejor que implícito), es decir:
$ python3 tutorial_argparser.py arch1
usage: tutorial_argparser.py [-h] nom_arch nom_arch
tutorial_argparser.py: error: the following arguments are required: nom_arch
Como véis repite lo mismo n veces cuando la cantidad de argumentos NO coincide con nargs. La ventaja acá es que codificamos menos porque no tenemos que incluir dos parámetros con diferentes nombres pero dejemos aparte la flojera, seamos explícitos:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nom_arch_orig",
help="Indica el nombre del archivo origen.",
)
analizador.add_argument(
"nom_arch_dest",
help="Indica el nombre del archivo destino.",
)
argumento = analizador.parse_args()
if argumento.nom_arch_orig:
print("Argumentos OBLIGATORIOS solicitados: nom_arch_orig y nom_arch_dest")
print("Nombres de los archivos:")
print(argumento.nom_arch_orig)
print(argumento.nom_arch_dest)
Así es menos confuso para nuestros usuarios y usuarias:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] nom_arch_orig nom_arch_dest
tutorial_argparser.py: error: the following arguments are required: nom_arch_orig, nom_arch_dest
$ python3 tutorial_argparser.py arch_orig.txt arch_dest.txt
Argumentos OBLIGATORIOS solicitados: nom_arch_orig y nom_arch_dest
Nombres de los archivos:
arch_orig.txt
arch_dest.txt
¿En cuales condiciones nos es útil nargs en modo múltiple? Ahora no viene nada a la cabeza pero alguna utilidad de seguro tendrá.
Ningún argumento, uno o más argumentos (» nargs=‘*’ «).
Por otro lado, así como nargs especifica un número exacto de argumentos, también permite el caracter asterisco que funciona a modo de comodín: puede aceptar uno, dos o más argumentos –o ninguno–. Escribamos este código:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nombres",
nargs="*",
help="Recibe una lista de nombres de personas.",
)
argumento = analizador.parse_args()
if argumento.nombres:
print("Argumento(s) OBLIGATORIO(S) solicitado(s): nombres")
print("Nombres de las personas:")
print(argumento.nombres)
Y probemos su salida:
$ python3 tutorial_argparser.py
$ python3 tutorial_argparser.py José
Argumento(s) solicitado(s): nombres
Nombres de las personas:
['José']
$ python3 tutorial_argparser.py José María Pedro Carmen
Argumento(s) solicitado(s): nombres
Nombres de las personas:
['José', 'María', 'Pedro', 'Carmen']
En la primera línea del terminal notamos que no necesita argumento alguno para funcionar, eso sería «cero o más». Avizorad que si necesitamos por lo menos una persona en la lista podemos utilizar el signo de suma «+» en vez del asterisco («uno o más»), y al sustituirlo y ejecutar el programa veremos lo siguiente:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] nombres [nombres ...]
tutorial_argparser.py: error: the following arguments are required: nombres
Así nos dice que «nombres» necesita al menos uno (no está entre corchetes, es obligatorio) y que podemos agregar otros nombres de personas, esto lo indica entre corchetes y con tres puntos suspensivos.
Un argumento no obligatorio ya que utiliza un valor por defecto (» nargs=‘?’ «).
En este caso se utiliza nargs=»?» en combinación de un valor por defecto default=’cadena_de_texto’ por lo que esta opción es un tanto extraña no es obligatoria ya que si no se le pasa un valor toma el que por defecto le pongamos, este ejemplo ilustra muy bien lo que decimos:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"nombre",
nargs="?",
default='Jesús',
help="Recibe un nombre de persona y si no es suministrado utiliza 'Jesús'.",
)
argumento = analizador.parse_args()
if argumento.nombre:
print("Argumento: solicita un nombre (por defecto utiliza 'Jesús')")
print("Nombre:")
print(argumento.nombre)
Ahora bien, al ejecutarlo fijáos bien en lo que hace:
$ python3 tutorial_argparser.py
Argumento: solicita un nombre (por defecto utiliza 'Jesús')
Nombre:
Jesús
$ python3 tutorial_argparser.py Pedro
Argumento: solicita un nombre (por defecto utiliza 'Jesús')
Nombre:
Pedro
Esta opción es tremendamente útil si le pedimos a la usuaria que indique un archivo de origen y, si lo desea, un archivo destino. De no colocar un archivo destino entonces utilizará el nombre de archivo que nosotros mismo escojamos (y si ese archivo existe bien le podemos agregar datos al final o creamos un archivo nuevo con el nombre por defecto acompañado de un número que esté libre: arch1, arch2, … arch_n). Colocamos el código necesario para enseñaros claramente la opción nargs=»?»:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"arch_orig",
help="Solicita un nombre de archivo de origen.",
)
analizador.add_argument(
"arch_dest",
nargs="?",
default='arch_dest.txt',
help="Solicita un nombre de archivo destino, si se omite utiliza 'arch_dest.txt'.",
)
argumento = analizador.parse_args()
print("Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)")
print("Nombres de archivos:")
print(argumento.arch_orig)
print(argumento.arch_dest)
Y esta sería la salida:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] arch_orig [arch_dest]
tutorial_argparser.py: error: the following arguments are required: arch_orig
$ python3 tutorial_argparser.py lista.txt
Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)
Nombres de archivos:
lista.txt
arch_dest.txt
$ python3 tutorial_argparser.py lista.txt lista_ordenada.txt
Argumentos: archivo de origen y destino ('arch_det.txt' si se omite destino)
Nombres de archivos:
lista.txt
lista_ordenada.txt
Como abreboca al estudio avanzado de argparse colocamos el siguiente ejemplo, muy sencillo pero que ilustra hasta donde podemos llegar combinando opciones:
import argparse
import os
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"arch_orig",
help="Solicita un nombre de archivo de origen.",
)
analizador.add_argument(
"arch_dest",
nargs="?",
default= os.getcwd()+'/arch_dest.txt',
help="Solicita un nombre de archivo destino, si se omite utiliza 'arch_dest.txt'.",
)
En color verde resaltamos la añadidura: primero tenemos que importar la librería os. Uno de los métodos es os.getcwd() la cual devuelve la ruta donde está almacenado nuestro guion, ¡probad vosotros! Es la manera de aprender.
Argumento opcional convertido en obligatorio.
Volviendo a nuestro ejemplo del argumento «-a» o»–aviso» (¿recordáis arriba?) lo podemos convertir en obligatorio adicionando un parámetro a la declaración del argumento, lo resaltamos en color verde:
analizador.add_argument(
"-a",
"--aviso",
required=True,
help="Detecta y confirma nuestro primer argumento."
)
Atención: el parámetro required NO es compatible con nargs=»*» ni con nargs=»?».
A medida que avanzamos se torna compleja nuestra aplicación, nuestra recomendación es transcribir y ejecutar, experimentar cada una de las diferentes combinaciones y una vez las tengamos comprendidas y bajo control avanzamos al siguiente nivel más complejo aún.
Argumento opcional con valor por defecto.
Ahora veremos que un argumento opcional le podemos dar un valor por defecto y así lo invoquemos sin ningún tipo de argumento utilice dicho valor prefijado. Además, si el usuario desea introducir algún valor deberá colocar la palabra clave acompañada de un tipo de valor por nosotros especificado (texto, entero, etc.). En este punto nos vamos acercando a la manera de como normalmente se comportan las aplicaciones más comunes, es decir, un comportamiento bastante común; acá la codificación de ejemplo:
import argparse
analizador = argparse.ArgumentParser(".:|Tutorial sobre argparser|:.")
analizador.add_argument(
'--limite',
default=3,
type=int,
help="Especifique el número máximo de elementos, (por defecto 3).")
argumento = analizador.parse_args()
print("Límite: {}".format(argumento.limite))
Si
$ python3 tutorial_argparser.py
Límite: 3
$ python3 tutorial_argparser.py --help
usage: .:|Tutorial sobre argparser|:. [-h] [--limite LIMITE]
optional arguments:
-h, --help show this help message and exit
--limite LIMITE Especifique el número máximo de elementos, (por defecto 3). 3.
$ python3 tutorial_argparser.py --limite 17
Límite: 17
Argumento obligatorio y que exige escoger de una lista de opciones.
Muchas veces necesitamos que un usuario escoja un solo valor de una lista de opciones. Por ejemplo, solicitamos qyue escoja un mes de inicio de trimestre, el código sería el siguiente:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
analizador.add_argument(
"mes",
choices=['Enero','Abril','Julio','Octubre'],
help="Permite escoger un mes de comienzo de trimestre.",
)
argumento = analizador.parse_args()
print("Argumento: solicita un mes de una lista predeterminada.")
print("Mes escogido:")
print(argumento.mes)
Y cuando lo ejecutamos:
$ python3 tutorial_argparser.py
usage: tutorial_argparser.py [-h] {Enero,Abril,Julio,Octubre}
tutorial_argparser.py: error: the following arguments are required: mes
$ python3 tutorial_argparser.py Junio
usage: tutorial_argparser.py [-h] {Enero,Abril,Julio,Octubre}
tutorial_argparser.py: error: argument mes: invalid choice: 'Junio' (choose from 'Enero', 'Abril', 'Julio', 'Octubre')
$ python3 tutorial_argparser.py Julio
Argumento: solicita un mes de una lista predeterminada.
Mes escogido:
Julio
Como ven, ¡tremendamente útil!
Un breve receso antes de continuar con…
Get comfortable with abstraction. If you try to understand how everything works, you'll get nothing done. pic.twitter.com/jfsXtdIySk
Como ya estamos prácticos con argparse (o deberíamos, sino retroceded y repasad) vamos a abstraernos un poco. Imaginemos que poseemos una impresora 3D, es decir, una ‘impresora’ capaz de producir objetos físicos tangibles. Nuestro programa será capaz de ‘imprimir’ bien sea un cubo, bien sea una esfera pero no ambos al mismo tiempo. Para ello codificamos de la siguiente forma y manera:
import argparse
analizador = argparse.ArgumentParser(description='Tutorial sobre argparse.')
grupo = analizador.add_mutually_exclusive_group()
grupo.add_argument(
"-c",
"--cubo",
action = "store_true",
help="Imprime un cubo en tercera dimensión.",
)
grupo.add_argument(
"-e",
"--esfera",
action = "store_true",
help="Imprime una esfera en tercera dimensión.",
)
argumento = analizador.parse_args()
if argumento.cubo:
print("'Imprime' un cubo")
if argumento.esfera:
print("'Imprime' una esfera")
En este caso, como los parámetros son opcionales si no «pasamos» nada pues nada hace. Pero si empleamos –cubo o –esfera dará como resutlado lo correspondiente, pero si usamos las dos al mismo tiempo nos indicará que escojamos solo una de ellas.
Si sois avezados notando los detalles, veréis lo coloreado en verde: un parámetro nuevo llamado action. Por increíble que les parezca, en realidad ya lo estuvimos usando desde hace rato: lo empleamos para saber si un parámetro opcional ha sido «pasado» a la aplicación, nuestro primer ejemplo hace uso de ello. La diferencia estriba que en aquel ejemplo debíamos acompañar de una cadena de texto y en este caso solo nos interesa el parámetro en si. Es decir, lo que nos interesa es si especificaron cubo o esfera y que lo represente como una variable booleana. Para que almacene un valor verdadero le asignamos store_true y si es un valor falso pues store_false. Esto último es un poco liado ¿para qué diantres necesitamos un valor falso?
En el siglo IX los chinos inventaron la brújula (aguja imantada suspendida que siempre apunta al polo norte) y desde entonces le destinaron en cada barco un habitaculum (en latín, habitáculo en castellano) al cual los franceses le nombraron habitacle y que luego abreviaron como bitacle y que pasó a ser traducido al castellano como bitácora (a pesar de que ya teníamos la palabra traducida directamente del latín, habitáculo). Pues bien, se necesitaba llevar un registro de la posición del barco en los largos viajes por nuestro globo terráqueo (y junto al sextante para registrar los astros) todo se anotaba en un cuaderno de bitácora, o simplemente bitácora.
¿A donde nos lleva esta introducción que aparentemente no tiene nada que ver con computación? ¡Ya veremos!
Introducción.
Así como los gobiernos en tierra necesitaban conocer qué sucedió en un navío en altamar a su regreso, nosotros necesitamos saber qué sucedió en los programas que para bien desarrollemos para nuestros usuarios. Lo más básico es mostrar mensajes por pantalla a los usuarios y confiar en que ellos y ellas nos retribuyan debidamente la información… pero con muy contadas excepciones, podemos esperar sentados para no cansarnos porque eso será difícil que se haga realidad.
Es por ello que debemos guardar un registro metódico para que posteriormente podamos evaluar qué funcionó mal (por extraño que parezca, si funciona bien pues felices de la vida aunque no recibamos las felicitaciones de nuestros usuarios y usuarias de software). Otra razón de llevar un registro sería la de análisis de desempeño o incluso ejecutar un programa en modo de depuración.
La razón y la lógica indica que dichos registros que pensamos llevar deberían ser guardados en una base de datos pero en proyectos pequeños tal vez no necesitemos tal nivel de complejidad. Pongamos por caso el programa Filezilla que tiene ambas versiones tanto como servidor como cliente: por defecto no se registra mensaje alguno a menos que así lo deseemos y si decidimos guardarlo podemos especificar un archivo llevando la fecha de cada evento (opcional) e incluso podemos limitar a un tamaño específico tras lo cual al alcanzar dicho valor se procede a crear un archivo nuevo pero sin la extensión «.log» la cual es sustituida por una numeración consecutiva.
Por esta y muchas otras razones el lenguaje Python 3 tiene disponible una librería destinada para tal efecto, estudiemos pues.
Creando una aplicación modelo.
Antes de crear siquiera registro alguno debemos tener, claro está, un software al cual llevarle un registro. Para ello proponemos un programa que llamaremos calculadora1.py cuyo código es el siguiente (si queréis repasar vuestro conocimientos básicos sobre Python, revisad nuestro tutorial al respecto):
El código es bastante sencillo, solo las cuatro operaciones aritméticas básicas: suma, resta, multiplicación y división; reconocemos que el código es un tanto extraño pero recordad que tiene propósitos didácticos solamente. Creamos una clase con funciones que no emplean return sino que muestran por pantalla los resultados excepto en la inicialización que muestra un mensaje puramente informativo, emulando el «on» de una calculadora electrónica y anunciando el modelo virtual. Abstraigámonos entonces en el ejemplo para comenzar a modificarlo con el registro de eventos.
Agregando la utilería «logging».
Para comenzar a utilizar la librería logging debemos incorporarla a nuestro archivo con el siguiente código:
La primera línea enlaza la librería y la segunda línea configuramos con una constante logging.DEBUG (que tiene un valor decimal de diez), osea, el nivel («level«) que vamos a usar: modo de depuración.
Notad todos y todas que en GNU/Linux son distintas las mayúsculas de las minúsculas, por lo tanto logging.DEBUG es una constante y logging.debug es un método, diferenciad bien esto en el siguiente código que modificamos a partir de la aplicación modelo.
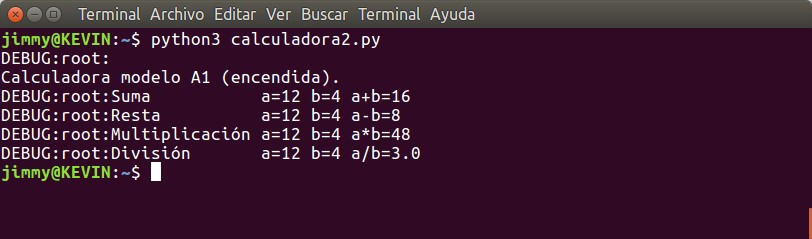
Como vemos en la siguiente imagen la salida por pantalla ha sido modificada ya que le agrega «DEBUG:root» a todos los mensajes de resultado.
python3 calculadora2.py
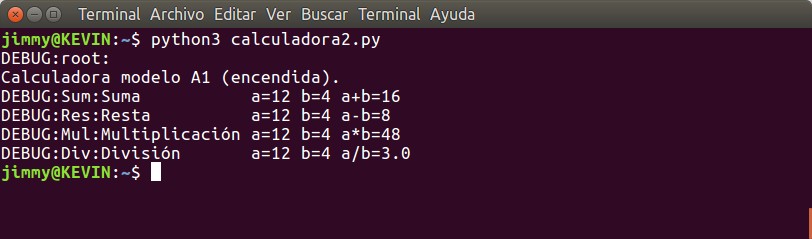
La primera palabra indica que estamos en modo de registro a nivel de depuración «DEBUG» y la segunda palabra indica que estamos depurando el módulo principal aunque esto no es realmente cierto. Lo mejor sería indicar desde dónde estamos imprimiendo el mensaje de depuración, en nuestro caso cualquiera de las cuatro funciones. Para ello vamos a volver a modificar el programa -que ya hemos renombrado como calculadora2.py– especificando cada función por separado:
Bien, pues ya estamos listos para comenzar a grabar en un archivo de texto plano nuestros eventos. Esto se logra configurando de nuevo el encabezado logging.basicConfig el cual ahora lo ocuparemos en varias líneas para buscar una mayor claridad para cada uno de sus parámetros:
Por supuesto el archivo será guardado en la misma carpeta donde se ejecuta la aplicación y para nuestra sorpresa al ejecutarla ya no muestra nada por pantalla… lo cual no es lo que realmente queremos hacer pero paciencia, primero analizemos el archivo resultante.
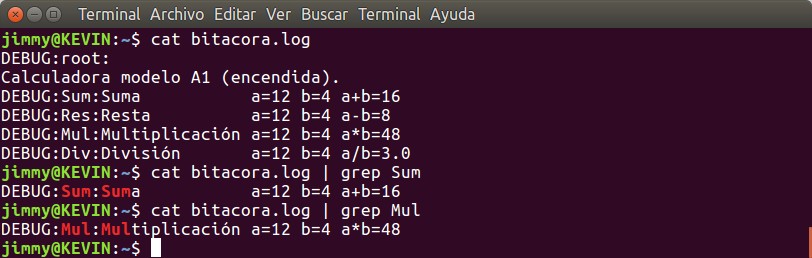
cat bitacora.log y combinado con el comando grep
Al usar el comando cat podremos, entre otras cosas, listar el contenido de un archivo por pantalla y como probablemente la cantidad de mensajes generará gran cantidad de líneas podremos filtrar los resultados por palabra clave. ¿Recordáis que dimos nombres diferentes para la muestra de resultados a nivel de cada función? Pues con el comando grep que recibe el resultado del comando cat por medio del comando «tubería» «|» y la palabra clave «Sum» o «Mul» podremos ver lo que nos interese. Ya nuestra aplicación está entrando en modo pragmático, ¡lo realmente útil para nosotros!
Agregando más pragmatismo aún: claridad al registro.
Nosotros los seres humanos en nuestro cerebro siempre buscamos darle «orden» a nuestro mundo, así está torcido lo tratamos de ver derecho y esto en el registro de eventos no ha de ser la excepción. Ya le colocamos para saber cual función produce tal registro pero le agregaremos mayor claridad en el apartado de configuración al inicio de la aplicación:
Recordad siempre al final de cada línea colocar una coma para separar los parámetros, que como es multilínea tendemos a pensar que cada retorno de carro automáticamente separa cada parámeto pero no es así.En el tercer parámetro mandamos a separar con par de espacios y un guion las diferentes secciones de cada evento en cada línea:
Fecha y hora exacta hasta en milisegundos cuando ocurrió el evento.
Nombre del módulo donde se origina cada evento, en nuestro caso cada función.
Nivel del mensaje, clasificación (hasta ahora estamos en modo de depuración solamente DEBUG).
El mensaje en sí mismo.
cat bitacora.log
Formato de tiempo mejorado.
Al formato de estampado de fecha y hora lo podremos mejorar agregando otra línea más al encabezado de configuración con una máscara que también es utlizada por el comando time.strftime():
Dejamos para vosotros os ejercitéis y veáis cómo es distinto los nuevos registros que se siguen adicionando de manera automática al final de nuestro archivo destinado a tal efecto, bitacora.log
Nivel de registro de eventos.
Como hemos repetido varias veces, del modo de depuración DEBUG no nos hemos movido hasta ahora. Por ello debemos estudiar los diferentes niveles -y constantes- que utiliza la librería logging: ya sabemos que logging.DEBUG vale diez -y se van incrementando de diez en diez- pero he aquí la tabla completa de valores:
Nivel
Valor
numérico
Función
Uso
NOSET
0
no aplica
no aplica
DEBUG
10
logging.debug()
Diganóstico de problemas, muestra información bien detallada.
INFO
20
logging.info()
Confirma que todo está funcionando correctamente.
WARNING
30
logging.warning()
Indica que algo inesperado ha sucedido, o pudiera suceder.
ERROR
40
logging.error()
Indica un problema más serio.
CRITICAL
50
logging.critical()
Muestra un error muy serio, el programa tal vez no pueda continuar.
Agregando mensajes de error y su registro.
A nuestra aplicación vamos a agregarle un mensaje de error en la función de división, bien sabemos que cualquier número dividido entre cero tiende al infinito el cual es un concepto que entedemos los seres humanos pero los ordenadores no. La modificación es la siguiente (notad que b valdría uno si el valor no es pasado a la función para tratar de evitar este error):
def dividir(self, a=0, b=1):
if (b==0):
bita_div.error("Alerta: el divisor debe ser distinto a cero.")
else:
bita_div.debug("División a={} b={} a/b={}".format(a,b,a/b))
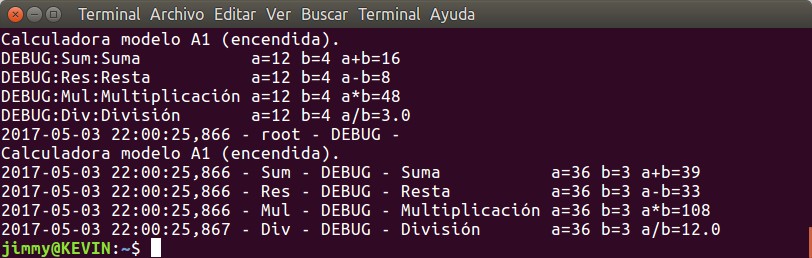
También modificamos el divisor en la función de división a calc.dividir(36,0) y el resultado en el registro de errores mostraría algo aprecido a esto:
Calculadora modelo A1 (encendida).
03/05/2017 11:03:07 PM - Sum - DEBUG - Suma a=36 b=3 a+b=39
03/05/2017 11:03:07 PM - Res - DEBUG - Resta a=36 b=3 a-b=33
03/05/2017 11:03:07 PM - Mul - DEBUG - Multiplicación a=36 b=3 a*b=108
03/05/2017 11:03:07 PM - Div - ERROR - Alerta: el divisor debe ser distinto a cero.
Lo próximo que haremos es modificar de manera completa nuestra aplicación con los diferentes «niveles» de mensajes.
Empleando diferentes niveles de registro.
Volvamos nuestros pasos sobre la sección logging.basicConfig donde contiene el nivel de registro de eventos para nuestra aplicación. Recordemos que la establecimos a nivel DEBUG y ahora la estableceremos a nivel INFO, guardaremos y ejecutaremos de nuevo la aplicación. Luego revisaremos el fichero bitacora.log y notaremos que no se registró el mensaje de inicialización pero si quedaron registrados los mensaje de información (y por supuesto el mensaje de error).
El siguiente paso es elevar al nivel de WARNING para obtener solamente el mensaje de error por la división entre cero y se repite el resultado si lo elevamos a nivel ERROR. No obtenderemos mensaje alguno si lo establecemos a nivel CRITICALya que la divisón entre cero no solamente ha sido debidamente advertida sino que también ha sido debidamente desviada.
Pro último, y más difícil de obtener (según la aplicación de modeo didáctico que de exprofeso escogimos) es el mensaje a nivel CRITICAL. Volvemos a repetir, este comportamiento es circunstrito estrictamente a nuestra aplicación modelo: la división está en el mensaje mismo a mostrar en bita_div.CRITICAL y nunca lograremos que se muestre ya que está debidamente desviado además, si no lo desviaramos al ejecutar el compilador Python3 inmediatamente nos mostraría el error si intentamos dividir entre cero y por ende no se ejecuta el programa.
Nosotros somos de experimentar al máximo, nos hacemos muchas, muchísimas preguntas: ¿Y si compilamos la aplicación, es decir la convertimos a lenguaje binario para ejecutar y lograr el mensaje a nivel CRITICAL?
Para ello -brevemente- podemos instalar PyInstaller:
sudo pip3 pyinstaller
Luego simplemente vamos a la carpeta con nuestro fichero calculadora2.py (habiendo eliminado la desviación del error de división entre cero):
pyinstaller calculadora2.py
Y luego de cierto tiempo (¡oh, sorpresa, también utiliza logging para mostrar el progreso de la compilación pero con unos códigos no recomendables de niveles de registro -valores personalizados-) y en una carpeta dist encontraremos nuestro ejecutable listo para ser experimentado. Nosotros obtuvimos esto, si queréis practicad que algo parecido obtendréis:
pyinstaller calculadora.py
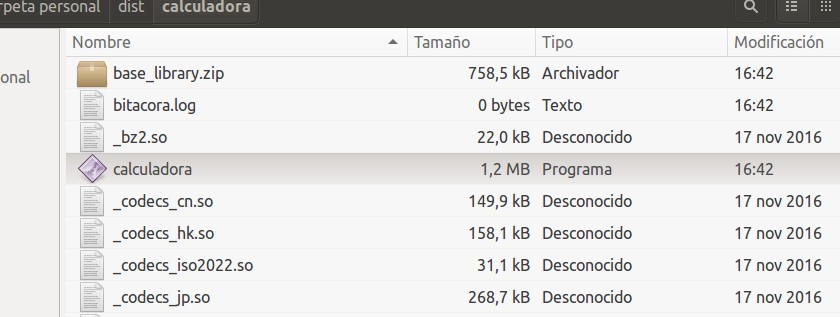
Entonces estaremos listo para ejecutar nuestro flamante binario, nos vamos con el explorador de ficheros Nautilus de Ubuntu a la carpeta dist le damos click derecho, ejecutar y ¡oh, sorpresa! el fichero bitacora.log se genera y aparece… pero con cero bytes, sin nada dentro, ¿qué ha sucedido aquí?
bitacora.log vacio cero bytes
Pues que simplemente la librería de registro abre el archivo bitacora.log (crea el archivo) pero la división entre cero no le permite llegar a ejecutar el grabado del mensaje, ya que las instrucciones son anidadas y primero trata de dividir y luego mostrar el mensaje, pero como se «cuelga» pues no registra nada de nada.
En este punto ya es bueno concluir algo muy cierto: el registro de errores incluso nos beneficiará al obligarnos a pensar dónde colocar los mensajes necesarios para futuras mejoras y en el caso del software libre donde TODOS podemos ser parte de un equipo de programadores esta ayuda es tremendamente bienvenida.
Otra pregunta que nos hacemos, ¿qué sucede si no establecemos un nivel de registro específico en logging.basicConfig? De manera predeterminada la utilería está en nivel WARNING y los mensajes que sean iguales o superiores a este nivel serán registrados (WARNING, ERROR y CRITICAL). No obstante vamos a dar un paso más allá en nuestros estudios y vamos a configurar para que sean nuestros propios usuarios quienes establezcan un nivel de registro lo cual consideramos útil para ellos que NO son programadores y que tal vez necesiten cierta orientación sin necesidad que ellos y/o ellas lleguen a tener que descargar el código fuente de la aplicación -que siempre estará al alcance por ser software libre-.
Que los usuarios y usuarias establezcan su nivel de registro.
Pasando parámetros a una aplicación desde la línea de comando.
En el mundo de Python hay varias librerías que nos permiten «pasar» parámetros hacia «lo interno» de nuestras aplicaciones, algunas de ellas son -pero no son todas-:
getoptes una librería la cual se deriva de una del lenguaje C llamada, claro, getopt().
optparseescrita para Python pero que actualemente está «descontinuada».
argparse la cual curiosamente deriva de optaprse pero ofrece total compatibilidad a la versión 3 -y a futuro-.
Por esa razón escogemos esta última para evitarnos dolores de cabeza a futuro.
argparse.
Introducción a argparse.
Debemos hacer una breve introducción al concepto de parámetros tanto opcionales como obligatorios. De manera general las aplicaciones corren sin ninguna isntrucción especial: escribimos el nombre del fichero, el sistema operativo revisa si es un ejecutable, o carga en memoria y ejecuta las instrucciones contenidas.
Un ejemplo sencillo es el comando para listar ficheros y directorios en una ventana terminal: ls. Sin más dicho comando nos muestra por pantalla los ficheros y directorios contenidos en la carpeta desde donde la ejecutamos. Si hubiera alguna carpeta y queremos saber su contenido debemos escribir ls nombre-de-la-carpeta y allí tenemos un parámetro opcional que le estamos pasando a la aplicación: le estamos ordenando listar el contenido de un directorio. Decimos que es opcional porque, como vimos, el comando no necesita nada para funcionar pero somos nosotros los que tenemos la necesidad de pedirle algo muy específico. Pero adicionalmente a la petición específica queremos que nos lo muestre de una manera específica y para poder diferenciar los nombres de las carpetas -o archivos- que pidamos de la forma como la va a presentar pues nació la idea de colocar palabras claves para diferenciar (recalcamos que estamos con el comando ls como ejemplo útil ya que es un comando extremadamente básico). Así podemos teclear ls nombre-de-carpeta -l para listar en modo columna o el también llmado modo largo (nombres de ficheros o directorios uno encima del otro con detalles de tamaños, fecha, atributos, etc.).
Es por esta razón que se estableció ciertas normas para pasar parámetros, en general podemos decir que:
Se utiliza un guion «-» como prefijo para indicar un parámetro y se acompaña generalmente con una sola letra que más que suficiente porque tenemos 54 opciones distintas (27 caracteres mayúsculas y minúsculas).
Como estrategia nemotécnica se utilizan dos guiones juntos «–» junto con palabras o incluso frases para que sea de manera explícita su recordación.
También se da el caso que a las dos opciones anteriores se le agregue sin dejar espacios un signo de igualdad y a continuación algún valor condicionante (que puede ser imprescindible o no).
Como para algunos el punto anterior no les parece elegante, también se estila colocar un espacio y a continuación algún valor condicionante.
Siguiendo con el ejemplo del comando ls:
Ejemplo del punto 1: comando «ls -r» (lista los archivos y carpetas en orden alfabético inverso, de la letra zeta hacia la letra a).
Ejemplo del punto 2: comando «ls –reverse» ídem al punto anterior pero más fácil de recordar y explícito para mostrar.
Ejemplo del punto 3: comando «ls –sort» ordena las lista de ficheros por orden de tamaño, del más grande hacia el más pequeño, pero sucede que hay muchas maneras de ordenar ese listado y si lo ejecutamos así sin más nos solicita un parámetro necesario. Podemos pedirlo por tamaño así que escribimos «ls –sort=size» y veremos el resultado con primero los más grandes yendo luego progresivamente hasta los más pequeños. Por cierto, este comando «largo» tiene un equivalente «corto»: ls -s.
Ejemplo del punto 4: comando «ls patron-a-buscar» como por ejemplo si queremos ver solamente los archivos que comienzen con la letra «a»: «ls a*«.
Primeros pasos con argparse.
Para comenzar a utilizar argparse en nuestro programa, simplemente hagamos un fichero nuevo y le colocamos los siguiente:
import argparse
analizador = argparse.ArgumentParser(description="Programa demostrativo de argparse")
analizador.parse_args()
Al salir lo nombramos como mi_programa.py y lo ejecutamos con python3 mi_programa.py y, por supuesto, no hace nada de nada ya que no le escribimos ningún código adicional. Pero ahora vamos a ejectuarlo acompañado de un parámetro como lo es el siguiente:python3 mi_programa.py -h y obtendremos la siguiente salida:
usage: mi_programa.py [-h]
Programa demostrativo de argparse.
optional arguments:
-h, --help show this help message and exit
Como vemos todo viene preconfigurado para utilizar el idioma inglés por defecto, pero pronto podremos darle un uso mejor para orientarlo hacia el idioma castellano en un tutorial dedicado al tema. Notad que especifica que el «parámetro largo» para ayuda es –help. Adicionalmente, cualquier otro parámetro que le pasemos manifestará desconocerlo -no hemos programado nada áun, por ahora-. Por lo pronto ya cumplimos con iniciar el uso práctico de argparser, continuemos aprendiendo.
Agregando otro argumento opcional.
Como vemos argparse tiene al menos un argumento establecido por defecto, el de ayuda [el cual es opcional, está mostrado entre corchetes], y ahora nosotros vamos a agregarle nuestro propio argumento para establecer el nivel de registro de eventos. Para ello especificaremos la palabra clave -log_lev acompañado del nivel que deseemos establecer, a continuación lo pasamos por una serie de tamices con la instrucción condicional if~elif~else y si coincide mostramos por pantalla la opción elegida:
import argparse
analizador = argparse.ArgumentParser("Programa demostrativo de argparse")
analizador.add_argument("-log_lev", help="Utilice DEBUG, INFO, WARNING, ERROR o$
analizador.parse_args()
argumentos = analizador.parse_args()
if argumentos.log_lev == 'DEBUG':
print("DEBUG")
elif argumentos.log_lev == 'INFO':
print("INFO")
elif argumentos.log_lev == 'WARNING':
print("WARNING")
elif argumentos.log_lev == 'ERROR':
print("ERROR")
elif argumentos.log_lev == 'CRITICAL':
print("CRITICAL")
else:
print("Opcion no válida de nivel de registro de eventos.")
Como vemos esto simplemente es el armazón para el manejo del pase de parámetros a nuestro programa didáctico para el registro de eventos con la utilería logging.
En este punto corred vuestro programa varias veces, experimentad con el pase de parámetros para que luego continuemos con el último paso de este tutorial: la fusión de logging con argparse.
Uniendo «logging» con «argparse».
Ya para finalizar unimos el código de ambos ejemplos y la idea es la siguiente: al utilizarse sin parámetros se establece el nivel de registro en WARNING que es el nivel predeterminado. Si se utiliza el parámetro -log_lev sin acompañarlo de valor alguno, la librería argparse se encargará debidamente de orientar al usuario sobre las opciones disponibles. Si el usuario usa alguna opción disponible válido pues se establece debidamente el nivel de registro correspondiente.
Queda para vuestra práctica el permitir que los usuarios especifiquen un nombre de archivo para el registro de eventos.
Acá tenemos el código final, espero os haya servido para aprender algo nuevo sobre el lenguaje Python.
Publicación en Gaceta Oficial y entrega del decreto ante el CNE.
Con fecha 1° de mayo de 2017 y en Gaceta Oficial Extraordinario N° 6.295 se publicó el decreto presidencial N° 2.830 donde se llama a Asamblea Nacional Constituyente y se entrega al Consejo Nacional Electoral para que proceda a planificar las elecciones de los 500 constituyentes a nivela nacional y sectorial para reformar nuestra Constitución Bolivariana de manera progresiva para los próximos 20 años de vida republicana.
(VIDEO) Presidente Maduro entrega en el CNE el decreto convocando a Asamblea Nacional Constituyente https://t.co/Gz1PBwvw73
Transcripción del Decreto N° 2.830: Convocatoria a Asamblea Constituyente.
Decreto N° 2.830, mediante el cual se establece que en ejercicio de las atribuciones que me otorga la Constitución de la República Bolivariana de Venezuela, en los artículos 348, 347, 70, y 236 numeral 1 ejusdem Convoco una Asamblea Nacional Constituyente, ciudadana y de profunda participacion popular, para que nuestro Pueblo, como depositario del Poder Constituyente Originario, con su voz suprema, pueda decidir el futuro de la Patria, reafirmando los principios de independencia, soberanía, igualdad, paz, de democracia participativa y protagónica, multiétnica y pluricultural.
NICOLÁS MADURO MOROS
Presidente de la República
En uso de la facultad que me confiere el artículo 348 de la Constitución de la República Bolivariana de Venezuela, en concordancia con los artículos 70, 236 numeral 1 y 347 ejusdem; con la bendición de Dios Todopoderoso, e inspirado en la grandiosa herencia historica de nuestros antepasados aborígenes, héroes y heroínas independentistas, en cuya cúspide está el Padre de la Patria, El Libertador Simón Bolívar, y con la finalidad primordial de garantizar la preservación de la paz del país ante las circunstancias sociales, políticas y económicas actuales, en las que severas amenazas internas y externas de factores antidemocráticos y de marcada postura antipatria se ciernen sobre su orden constitucional, considero un deber historico ineludible convocar una ASAMBLEA NACIONAL CONSTITUYENTE, tomando como fundamento el proceso popular constituyente, Legado del Comandante Hugo Chávez, y la Constitución pionera y fundacional de 1999, para que nuestro pueblo, como Poder Constituyente Originario, exprese su férrea voluntad y máxima garantia de defensa de los sagrados derechos y logros sociales conquistados, y que durante mi mandato he luchado por sostener y profundizar. Por lo que propongo como objetivos programaticos de la Asamblea Nacional Constituyente:
La paz como necesidad, derecho y anhelo de la nación, el proceso constituyente es una gran convocatoria a un diálogo nacional para contener la escalada de violencia política, mediante el reconocimiento político mutuo y de una reorganización del Estado, que recupere el principio constitucional de cooperación entre los poderes públicos, como garantía del pleno funcionamiento del Estado democrático, social, de derecho y de justicia, superando el actual clima de impunidad.
El perfeccionamiento del sistema económico nacional hacia la Venezuela Potencia, concibiendo el nuevo modelo de la economía post petrolera, mixta, productiva, diversificada, integradora, a partir de la creación de nuevos instrumentos que dinamicen el desarrollo de las fuerzas productivas, así como la instauración de un nuevo modelo de distribución transparente que satisfaga plenamente las necesidades de abastecimiento de la población.
Constitucionalizar las Misiones y Grandes Misiones Socialistas, desarrollando el Estado democrático, social, de derecho y de justicia, hacia un Estado de la Suprema Felicidad Social, con el fin de presentar y ampliar el legado del Comandante Hugo Chávez, en materia del pleno goce y ejercicio de los derechos sociales para nuestro pueblo.
La ampliación de las competencias del Sistema de Justicia, para erradicar la impunidad de los delitos, especialmente aquellos que se cometen contra las personas (homicidios, secuestro, extorsión, violaciones, violencia de género y contra niños y niñas); así como de los delitos contra la Patria y la sociedad tales como la corrupción; el contrabando de extracción; la especulación; el terrorismo; el narcotrafico; la promoción del odio social y la injerencia extranjera.
Constitucionalizacion de las nuevas formas de la democracia participativa y protagónica, a partir del reconocimiento de los nuevos sujetos del Poder Popular, tales como las Comunas y Consejos Comunales, Consejos de Trabajadores y Trabajadoras, entre otras formas de organización de base territorial y social de la población.
La defensa de la soberanía y la integridad de la nación y protección contra el intervencionismo extranjero, ampliando las competencias del Estado democrático, social, de derecho y de justicia para la preservación de la seguridad ciudadana, la garantía del ejercicio integral de los derechos humanos, la defensa de la independencia, la paz, la inmunidad, y la soberanía política, económica y territorial de Venezuela. Así como la promoción de la consolidación de un mundo pluripolar y multicéntrico que garantice el respeto al derecho y a la seguridad internacional.
Reivindicación del carácter pluricultural de la Patria, mediante el desarrollo constitucional de los valores espirituales que nos permitan reconocernos como venezolanos y venezolanas, en nuestra diversidad étnica y cultural como garantía de convivencia pacífica en el presente y hacia el porvenir, vacunándonos contra el odio social y racial incubado en una minoría de la sociedad.
La garantía del futuro, nuestra juventud, mediante la inclusión de un capítulo constitucional para consagrar los derechos de la juventud, tales como el uso libre y consciente de las tecnologías de información; el derecho a un trabajo digno y liberador de sus creatividades, la protección a las madres jóvenes; el acceso a una primera vivienda; y el reconocimiento a la diversidad de sus gustos, estilos y pensamientos, entre otros.
La preservación de la vida en el planeta, desarrollando constitucionalmente, con mayor especificidad los derechos soberanos sobre la protección de nuestra biodiversidad y el desarrollo de una cultura ecológica en nuestra sociedad.
Invoco al Poder Constituyente Originario, para que con su profundo espíritu patriótico, conforme una Asamblea Nacional Constituyente que sea tribuna participativa y protagónica de toda de nuestra sociedad, donde se exprese la voz de los más diversos sectores sociales. Una Asamblea Nacional Constituyente, cuya conformación obedezca a la estructura geopolítica del Estado Federal y Descentralizado, con base en la unidad política primaria de la organización territorial que nuestra Carta Magna consagra.
Es deber de la Asamblea Nacional Constituyente Originaria, garantizar el Estado Social de Derecho y de Justicia, así como canalizar el clamor popular de quienes hoy exigen que sus derechos, logros y conquistas gocen del rango constitucional, a cuyo nivel, sin duda alguna, deben ser elevados, perfeccionando el modelo de desarrollo humanista, político, jurídico y económico que esta contenido y consagrado en nuestra Carta Magna, por todas estas razones históricas y con el más sagrado compromiso moral y amoroso que le guardo al pueblo venezolano, tomo la iniciativa constitucional y exclusiva de convocar, en Consejo de Ministros:
DECRETO
Artículo 1°.
En ejercicio de las atribuciones que me otorga la Constitución de la República Bolivariana de Venezuela, en los artículos 348, 347, 70, y 236 numeral 1 ejusdem CONVOCO UNA ASAMBLEA NACIONAL. CONSTITUYENTE, ciudadana y de profunda participación popular, para que nuestro Pueblo, como depositario del Poder Constituyente Originario, con su voz suprema, pueda decidir el futuro de la Patria, reafirmando los principios de independencia, soberanía, igualdad, paz, de democracia participativa y protagonica, multiétnica y pluricultural.
Artículo 2°.
Los y las integrantes de la Asamblea Nacional Constituyente Originaria serán elegidos o elegidas en los ámbitos sectoriales y territoriales, bajo la rectoría del Consejo Nacional Electoral, mediante el voto universal, directo y secreto; con el interés supremo de presen/ar y profundizar los valores constitucionales de libertad, igualdad, justicia e inmunidad de la República y autodeterminación del pueblo.
Dado en Caracas, al primer día del mes de mayo de dos mil diecisiete. Años 207° de la Independencia, 158° de la Federación y 18° de la Revolución Bolivariana.
Transcripción del Decreto N° 2.831: Creación de la Comisión Presidencial para la conformación y funcionamiento de la Asamblea Constituyente.
Decreto N° 2.831, mediante el cual se crea una Comisión Presidencial que tendrá a su cargo la elaboración de una propuesta para las base comiciales territoriales y sectoriales, así como para los principales aspectos que servirán de fundamento a la conformación y funcionamiento de la Asamblea Nacional Constituyente, previa consulta a los más amplios sectores del país, garantizando el principio de participación directa establecido en la Constitución de la República Bolivariana de Venezuela, integrada por las ciudadanas y ciudadanos que en el se mencionan.
NICOLÁS MADURO MOROS
Presidente de la República
En uso de la facultad que me confiere el artículo 348 de la Constitución de la República Bolivariana de Venezuela, en concordancia con los artículos 70 y 347 ejusdem; con el propósito de preservar la paz, la independencia, la integridad, y la soberanía de la República, para que sea el pueblo venezolano, con su poder originario, quien con su voz suprema dirima el destino que como Patria soberana e independiente marque la ruta de nuestra historia en el camino heredado por nuestros Libertadores y Libertadoras; en Consejo de Ministros,
CONSIDERANDO
Por cuanto el Presidente la República Bolivariana de Venezuela, realizó la convocatoria a una Asamblea Nacional Constituyente, para que se lleve a cabo la propuesta a consulta de las bases populares y esclarecer todas las dudas sobre el poder constituyente originario,
CONSIDERANDO
Que en defensa del bien más preciado que hemos logrado: La Independencia política y la reafirmacién de nuestra identidad, en aras del encuentro con la nueva realidad nacional, para seguir cimentando Las bases del Socialismo Bolivariano del Siglo XXI.
DECRETO
Artículo 1°.
Creo una Comisión Presidencial que tendrá a su cargo la elaboración de una propuesta para las bases comiciales territoriales y sectoriales, así como para los principales aspectos que servirán de fundamento a la conformación y funcionamiento de la Asamblea Nacional Constituyente, previa consulta a los mas amplios sectores del país, garantizando el principio de participación directa establecido en la Constitución de la República Bolivariana de Venezuela.
Artículo 2°.
La Comisión Presidencial creada en el artículo precedente estará integrada por los ciudadanos y las ciudadanas que se mencionan a continuación:
ELÍAS JOSE JAUA MILANO, titular de la cédula de identidad N° V-10.096.662, quien la presidirá.
ADÁN COROMOTO CHÁVEZ FRIAS, titular de la cédula de identidad N° V-3.915.103, quien ejercerá la Secretaria de esta Comisión.
CILIA FLORES, titular de la cédula de identidad N° V-5.315.632.
ARISTÓBULO ISTÚRIZ ALMEIDA, titular de la cédula de identidad N° V-630.328.
DELCY ELOINA RODRiGUEZ GÓMEZ, titular de la cédula de identidad N° V-10.353.667.
MARÍA IRIS VARELA RANGEL, titular de la cédula de identidad N° V-9.242.760.
JULIÁN ISAIAS RODRÍGUEZ DIAZ, titular de la cédula de identidad N° V-2.218.534.
FRANCISCO JOSE AMELIACH ORTA, titular de la cédula de identidad N° V-7.062.172.
REINALDO ENRIQUE MUNOZ PEDROZA, titular de la cédula de identidad N° V-10.869.426.
ELVIS AMOROSO, titular de la cédula de identidad N° V-7.659.695.
HERMANN EDUARDO ESCARRA MALAVE, titular de la cédula de identidad N° V-3.820.195.
NOELI POCATERRA DE OBERTO, titular de la cédula de identidad N° V-1.651.000.
EARLE JOSE HERRERA SILVA, titular de la cédula de identidad N° V-2.744.362.
REMIGIO CEBALLOS ICHASO, titular de la Cédula de identidad N° V-6.557.495.
Artículo 3°.
La Comisión Presidencial, dentro de un plazo perentorio, contado a partir de la entrada en vigencia de este Decreto, presentará al Presidente de la República un informe con los fundamentos, resultados y recomendaciones obtenidos en el ejercicio de la atribución que le fuere encomendada de conformidad con el articulo 2° de este Decreto.
Artículo 4°.
Los gastos de la Comisión Presidencial serán sufragados con cargo al presupuesto del Ministerio del Poder Popular del Despacho de la Presidencia y Seguimiento de la Gestión de Gobierno.
Artículo 5°.
La Comisión Presidencial podrá constituir las subcomisiones o grupos de trabajos necesarios, con participación amplia y colegiada de asesores nacionales e internacionales de las disciplinas relacionadas a cada tema, así como representantes de la comunidad organizada que puedan coadyuvar en el cumplimiento de sus fines.
Artículo 6°.
La ejecución de este Decreto corresponde al Ministerio del Poder Popular del Despacho de la Presidencia y Seguimiento de la Gestión de Gobierno.
Artículo 7°.
Este Decreto entrara en vigencia a partir de la fecha de su publicación en la Gaceta Oficial de la República Bolivariana de Venezuela.
Dado en Caracas, a| primer día del mes de mayo de dos mil diecisiete. Afios 207° de la Independencia, 158° de la Federación y 18° de la Revolución Bolivariana.
El presidente Nicolás Maduro, en cadena de radio y televisión, anunció un aumento de salario mínimo en 60 por ciento, incluyendo pensiones y tablas de trabajadores de la administración pública. También anunció un aumento del cestaticket, que sube de 12 a 15 puntos de la unidad tributaria. “Esto quiere decir que el salario mínimo integral aumenta a Bs. 200.021 a partir del mes de mayor”. Igualmente, aprobó que el cestaticket pueda ser depositado y pagado en bolívares.
Aumento salarial 1° mayo 2017
El anuncio se realizó en el programa Los Domingos con Maduro, realizado desde el Teatro Bolívar en Caracas. Es el tercer aumento de este año, el aumento número 15 del gobierno de Nicolás Maduro, y el aumento número 37 de la revolución bolivariana.
Aumento salarial de 60% anuncia Presidente @NicolasMaduro via @VTVcanal8 en transmisión conjunta de radio, televisión e internet???.
Indicó que el nivel de desempleo es de 6,6 por ciento, “un récord para un país sometido a una guerra económica”. También señaló que el 62 por ciento de los trabajadores del país tienen empleo formal; recordó además de los programas sociales que asisten tanto a quienes tienen empleo formal como informal.
Aumento cestaticket a 15 U.T. anuncia Presidente @NicolasMaduro via @VTVcanal8 en transmisión conjunta de radio, televisión e internet???.
Señaló Maduro que se han creado 1,2 millones de empleos durante su gestión, y 5 millones de empleos durante la revolución bolivariana. “La revolución ha dado 36 aumentos salariales integrales”, señaló, de los cuales 14 aumentos se han dado en los 4 años de su gestión.
Maduro anuncia aumento salarial de 60 por ciento y aumento del cestaticket: sueldo integral sube a Bs. 200.021 https://t.co/AZ4EW18cLe
Decreto N° 2.832: aumento de 60% a salario mínimo mensual.
Con fecha martes 02 de mayo de 2017 en Gaceta Oficial Extraordinario N° 6.296 está publicado el Decreto Presidencial N° 2.832 el cual establece un aumento de 60% en el salario mínimo mensual para trabajadores y trabajadoras tanto del sector público como el sector privado, a continuación hacemos la transcripción del documento oficial.
Enlaces para descargar la Gaceta Oficial N° 6.296.
Extrajimos las primeras 4 hojas en 1,5 Megabytes que contienen solamente 2 decretos: el decreto de aumento de sueldo y el decreto de aumento de Cestaticket.
PRESIDENCIA DE LA REPÚBLICA
Decreto N° 2.832
01 de mayo de 2017
NICOLÁS MADURO MOROS
Presidente de la República
Con el supremo compromiso y voluntad de lograr la mayor eficacia política y calidad revolucionaria en la construcción del Socialismo, la refundación de la patria venezolana, basado en principios humanistas, sustentado en condiciones morales y éticas que persiguen el vivir bien del país y del colectivo, por mandato del pueblo de conformidad con lo establecido en los artículos 80 y 91 de la Constitución de la República Bolivariana de Venezuela, concatenado con el artículo 226 ibídem, y en ejercicio de la atribución que me confiere el numeral 11 del artículo 236 eiusdem, en concordancia con el artículo 46 del Decreto con Rango, Valor y Fuerza de Ley Orgánica de la Administración Publica, y de acuerdo a lo preceptuado en los artículos 10, 98, 111 y 129 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, en Consejo de Ministros,
CONSIDERANDO
Que es una función fundamental del gobierno revolucionario la protección social, de la economía del Pueblo y de la guerra económica desarrollada por el imperialismo y sectores apátridas nacionales, que impulsan procesos inflacionarios y desestabilizacion económica como instrumentos de acumulación de capital y perturbación económica, política y social,
CONSIDERANDO
Que el Estado democrático y social, de derecho y de justicia garantiza a los trabajadores y las trabajadoras, la participación en la justa distribución de la riqueza generada mediante el proceso social de trabajo, como condición básica para avanzar hacia la mayor suma de felicidad posible, como objetivo esencial de la Nación que nos legó El Libertador,
CONSIDERANDO
Que es función constitucional del Estado defender principios democráticos de equidad, así como una política de recuperación sostenida del poder adquisitivo de la población venezolana, así como la dignificación de la remuneración del trabajo y el desarrollo de un modelo productivo soberano, basado en la justa distribución de la riqueza, capaz de generar trabajo estable y de calidad, garantizando que las y los trabajadores disfruten de un salario mínimo igual para todas y todos,
DECRETO N° 26 EN EL MARCO DEL ESTADO DE EXCEPCIÓN Y EMERGENCIA ECONÓMICA, MEDIANTE EL CUAL SE AUMENTA EL SALARIO MÍNIMO MENSUAL OBLIGATORIO Y SE CREA UN BONO ESPECIAL COMPENSATORIO PARA LOS PENSIONADOS Y PENSIONADAS.
Artículo 1°.
Se aumenta en un sesenta por ciento (60%) el salario mínimo nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela, para los trabajadores y las trabajadoras que presten servicios en los sectores públicos y privados, sin perjuicio de lo dispuesto en el artículo 2° de este Decreto, a partir del 1° de mayo de 2017, estableciéndose la cantidad de SESENTA Y CINCO MIL VEINTIUNO BOLÍVARES CON CUATRO CÉNTIMOS (Bs. 65.021,04) mensuales.
El monto de salario diurno por jornada, será cancelado con base al salario mínimo mensual a que se refiere este artículo, dividido entre treinta (30) días.
Artículo 2°.
Se fija un aumento del salario mínimo nacional mensual obligatorio en todo el territorio de la República Bolivariana de Venezuela para los y las adolescentes aprendices, de conformidad con lo previsto en el Capítulo II del Titulo V del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, a partir del 1° de mayo de 2017, por la cantidad CUARENTA Y OCHO MIL TRESCIENTOS CINCUENTA Y CUATRO BOLÍVARES CON NOVENTA Y SEIS CÉNTIMOS (Bs. 48.354,96) mensuales.
El monto del salario por jornada diurna, aplicable a los y las adolescentes aprendices, será cancelado con base al salario mínimo mensual a que se refiere este artículo, dividido entre treinta (30) días.
Cuando la labor realizada por los y las adolescentes aprendices, sea efectuada en condiciones iguales a la de los demás trabajadores y trabajadoras, su salario mínimo será el establecido en el artículo 1° de este Decreto, de conformidad con el artículo 303 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras.
Artículo 3°.
Los salarios mínimos establecidos en este Decreto, deberán ser pagados en dinero en efectivo y no comprenderán, como parte de los mismos, ningún tipo de salario en especie.
Artículo 4°.
Se fija como monto de las pensiones de los jubilados y las jubiladas, los pensionados y las pensionadas de la Administración Pública, el salario mínimo nacional obligatorio establecido en el Artículo 1° de este Decreto.
Artículo 5°.
Se fija como monto de las pensiones otorgadas a los pensionados y las pensionadas, por el Instituto Venezolano de los Seguros Sociales (I.V.S.S.), el salario mínimo nacional obligatorio establecido en el Artículo 1° de este Decreto.
Artículo 6°.
Adicionalmente, a lo establecido en el artículo 1 de este Decreto, se otorga a los pensionados y pensionadas por el Instituto Venezolano de los Seguros Sociales (I.V.S.S.), que perciban el equivalente a un salario mínimo, un Bono Especial de Guerra Económica del treinta por ciento (30%), equivalente a la cantidad de DIECINUEVE MIL QUINIENTOS SEIS BOLÍVARES CON TREINTA Y ÚN CÉNTIMOS (Bs.19.506,31) mensuales.
Quienes fueren beneficiarios de más de una pensión, en el marco del ordenamiento jurídico aplicable, recibirán el beneficio solo con respecto a una de ellas.
Artículo 7°.
Cuando la participación en el proceso social de trabajo se hubiere convenido a tiempo pardal, el salario estipulado como mínimo, podrá someterse a lo dispuesto en el artículo 172 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras, en cuanto fuere pertinente.
Artículo 8°.
El pago de un salario inferior a los estipulados como mínimos en este Decreto, obligará al patrono o patrona a su pago de conformidad con el Artículo 130 del Decreto con Rango, Valor y Fuerza de Ley Orgánica del Trabajo, los Trabajadores y las Trabajadoras y dará lugar a la sanción indicada en su artículo 533.
Artículo 9°.
Se mantendrán inalterables las condiciones de trabajo no modificadas en este Decreto, salvo las que se adopten o acuerden en beneficio del trabajador y la trabajadora.
Artículo 10°.
Queda encargado de la ejecución de este Decreto, el Ministro del Poder Popular para el Proceso Social de Trabajo.
Artículo 11.
Este Decreto entrará en vigencia a partir del 1° de mayo de 2017.
Dado en Caracas, al primer día del mes de mayo de dos mil diecisiete. Años 207° de la Independencia, 158° de la Federación y 18° de la Revolución Bolivariana.
Decreto N° 2.833: aumento a 15 U.T. diarias el cestaticket socialista.
Decreto N° 2.833
01 de mayo de 2017
NICOLÁS MADURO MOROS
Presidente de la República
Con el supremo compromiso y voluntad de lograr la mayor eficacia polltica y calidad revolucionaria en la construcción del socialismo, y en el engrandecimiento del país, basado en los principios humanistas, y en condiciones morales y éticas bolivarianas, por mandato del pueblo, en ejercicio de la atribución que me confiere el numeral 11 del artículo 236 de la Constitución de la República Bolivariana de Venezuela, en concordancia con lo dispuesto en el artículo 46 del Decreto con
Rango, Valor y Fuerza de Ley Orgánica de la Administración Pública, y de conformidad con el artículo 7° del Decreto con
Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras, en Consejo de Ministros,
CONSIDERANDO
Que el Estado debe promover el desarrollo económico, con el generar fuentes de trabajo, con alto valor agregado nacional y elevar el nivel de vida de la población para garantizar la seguridad jurídica y la equidad en el crecimiento de la economía, a objeto de lograr una justa distribución de la riqueza, mediante una planificación estratégica, democrática y participativa,
CONSIDERANDO
Que es obligación del Estado, proteger al pueblo venezolano de los embates de la guerra económica propiciada por factores internos como externos; razón por la cual, considera necesario equilibrar los diferentes eslabones del proceso productivo y garantizar el acceso de la población a los productos de primera necesidad ante las circunstancias que vive la economía venezolana,
CONSIDERANDO
Que es interés del Ejecutivo Nacional, asegurar los niveles de bienestar y prosperidad de los trabajadores y las trabajadoras y de su núcleo familiar.
DICTO
El siguiente,
DECRETO N° 27 EN EL MARCO DEL ESTADO DE EXCEPCIÓN Y EMERGENCIA ECONÓMICA, MEDIANTE EL CUAL SE INCREMENTA LA BASE DE CÁLCULO Y SE MODIFICA LA MODALIDAD PARA EL PAGO DEL BENEFICIO DEL CESTATICKET SOCIALISTA.
Artículo 1°.
Se ajusta la base de calculo para el pago del Cestaticket Socialista para los trabajadores y las trabajadoras que presten servicios en Los sectores público y privado, a quince Unidades Tributarias (15 U.T.) por día, a razón de treinta (30) días por mes, pudiendo percibir hasta un máximo del equivalente a cuatrocientas cincuenta Unidades Tributarias (450 U.T.) al mes, sin perjuicio de lo dispuesto en el articulo 7° del Decreto con Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras.
Artículo 2°.
Las entidades de trabajo de los sectores público y privado, ajustaran de conformidad con lo establecido en el artículo 1° de este Decreto, el beneficio de alimentación denominado “Cestaticket Socialista” a todos los trabajadores y las trabajadoras a su servicio.
Artículo 3°.
Los empleadores y empleadoras tanto del sector público como del sector privado, pagarán a cada trabajador y trabajadora en efectivo o mediante abono en su cuenta nómina el monto por concepto de Cestaticket Socialista a que se refiere el artículo 1° de este Decreto, expresando en recibo de pago separado el monto que resulte por los días laborados, así como indicando que el mismo no genera incidencia salarial alguna, y en consecuencia no podrán efectuarse deducciones sobre este, salvo las que expresamente autorice el trabajador para la adquisición de bienes y servicios en el marco de Los programas y misiones sociales para la satisfacción de sus necesidades.
Artículo 4°.
El ajuste mencionado en el artículo 1° de este Decreto, es de obligatorio cumplimiento por parte de los empleadores y las empleadoras en todo el territorio de la República Bolivariana de Venezuela.
Artículo 5°.
Las entidades de trabajo de los sectores público y privado, que mantienen en funcionamiento el beneficio establecido en el artículo 4°, numerales 1 al 4 del Decreto con Rango, Valor y Fuerza de Ley del Cestaticket Socialista para los Trabajadores y Trabajadoras, adicionalmente y en forma temporal, deberán otorgar dicho beneficio en efectivo o mediante depósito en la cuenta nómina, de acuerdo con lo establecido en el artículo 3° de este Decreto.
Artículo 6°.
Se otorga un plazo de treinta (30) días, contado a partir de la publicación de este Decreto en la Gaceta Oficial de la República Bolivariana de Venezuela, para que las entidades de trabajo pública y privada, adecúen los sistemas de nóminas para proceder al pago del Cestaticket Socialista a los trabajadores y trabajadoras, en dinero efectivo en sus cuentas.
Artículo 7°.
Los cupones, tickets y tarjetas electrónicas de alimentación que ya hubieren sido emitidas mantendrán su validez y vigencia, para su uso ante Los establecimientos especializados en la administración y gestión de beneficios
sociales, hasta el 31 de diciembre de 2017.
Las empresas proveedoras o administradoras de Los cupones, tickets y tarjetas electrónicas de alimentación deberán garantizar el uso de los referidos instrumentos en Los establecimientos destinados a tal fin.
Artículo 8°.
Queda encargado de la ejecución de este Decreto, el Ministro del Poder Popular para el Proceso Social de Trabajo.
Artículo 9°.
Este Decreto entrara en vigencia a partir del 1° de mayo de 2017.
Dado en Caracas, al primer día del mes de mayo de dos mil diecisiete. Años 207° de la Independencia, 158° de la Federación y 18° de la Revolución Bolivariana.
Hoy tuvimos el regocijo de leer un artículo publicado por los colegas de LinuxAdictos donde hablan sobre comandos pocos conocidos para la terminal GNU/Linux. Es por ello que decidimos publicar nuestra propia entrada pero dandole valor agregado: vamos a enfocarlo desde nuestra distribución preferida, Ubuntu Desktop (actualmente usamos las 16.04 LTS) y también como suplemento a nuestra otra entrada sobre la introducción a la cónsola de comandos; ¡venid y acompañadnos en la búsqueda del conocimiento!
Pues eso, comandos poco conocidos que ya vienen por defecto ya instalados en Ubuntu, nada más teclearlos los podemos utilizar. Lo que haremos acá es teclear el comando «man» seguido de un espacio y el nombre del comando a conocer, leeremos su descripción en inglés y las traduciremos y le buscaremos propósitos prácticos, comencemos pues.
Comando «calendar»:
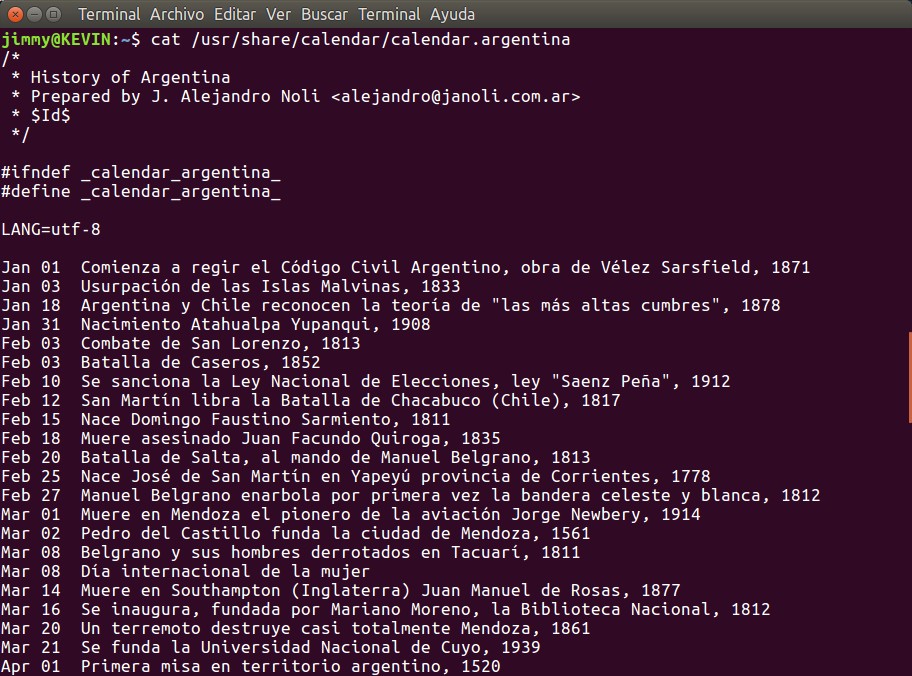
El comando «calendar» pertenece al paquete de bsdmainutils que viene por defecto en la distro GNU/Linux que utilizamos para esta entrada, Ubuntu 16.04 Xenial. Dado el caso extraño que no lo tengáis instalado podéis hacerlo con el comando «sudo apt-get install bsdmainutils» y sin ir a mucha profundidad en la materia, podréis ver los archivos que componen ese paquete de software en este enlace.
Este paquete proviene del muy antiguo sistema Unix (el comando «man calendar» especifica que un comando calendar apareció en la «Version 7 AT&T UNIX» en 1979) y ciertamente que nos fue difícil encontrar a quien o quienes actualmente mantienen dicho repositorio, ya que el mero hecho de ser un calendario implica lo más dinámico de este mundo: el transcurrir del tiempo es siempre cambiante. En un «fork» al que tuvimos acceso hecho por Andrey Ulanov < drey @ rt.mipt.ru > en el año 2002 comenta que proviene de OpenBSD e incluye una licencia que se hereda de cada uno de sus componentes, por ejemplo el módulo pathnames.h nos da la siguiente información:
/* $OpenBSD: pathnames.h,v 1.3 1996/12/05 06:04:41 millert Exp $ */
/* $Id: pathnames.h,v 1.1.1.1 2002/11/26 23:37:38 drey Exp $ */
/*
* Copyright (c) 1989, 1993
* The Regents of the University of California. All rights reserved.
*
* Redistribution and use in source and binary forms, with or without
* modification, are permitted provided that the following conditions
* are met:
* 1. Redistributions of source code must retain the above copyright
* notice, this list of conditions and the following disclaimer.
* 2. Redistributions in binary form must reproduce the above copyright
* notice, this list of conditions and the following disclaimer in the
* documentation and/or other materials provided with the distribution.
* 3. All advertising materials mentioning features or use of this software
* must display the following acknowledgement:
* This product includes software developed by the University of
* California, Berkeley and its contributors.
* 4. Neither the name of the University nor the names of its contributors
* may be used to endorse or promote products derived from this software
* without specific prior written permission.
*
* THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
* ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
* IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
* ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
* FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
* DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
* OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
* HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
* LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
* OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
* SUCH DAMAGE.
*
* @(#)pathnames.h 8.1 (Berkeley) 6/6/93
*/
Como véis se remota hasta el año de 1989, época en la cual apenas nosotros entrábamos a estudiar en la universidad, ¡fascinante como pasa el tiempo! Otra cosa es la fuente de bsdmainutils en la distribución Debian donde el propio Ian Murdock introdujo código fuente según se puede leer en esta página (no obstante acá la reproducimos de igual manera):
This is a collection of programs from 4.4BSD-Lite that have not (yet)
been re-written by FSF as GNU. It was constructed for inclusion in
Debian Linux. As programs found here become available from GNU sources,
they will be replaced.
This package was originally put together by Austin Donnelly
<and1000@debian.org>, but is heavily based on bsdutils, originally put
together by Ian Murdock <imurdock@gnu.ai.mit.edu>. Please report any
problems or suggested additions or changes to Austin Donnelly.
Then the package has been maintained by Charles Briscoe-Smith
<cpbs@debian.org>. I gathered data for the 1999-2001 calendar files
from various sources on the Internet, and I'd also like to thank Oliver
Elphick, Julian Gilbey, Daniel Martin and Jaldhar H. Vyas for providing
much useful data on the various religous calendars. I have edited the
files they provided to fit calendar's requirements, so any errors should
be attributed to me.
After cpbs@debian.org, Marco d'Itri <md@linux.it> maintained it for
almost two years, before Tollef Fog Heen <tfheen@debian.org> took over.
The package is now maintained by Graham Wilson <bob@decoy.wox.org>.
This package may be redistributed under the terms of the UCB BSD
license:
Copyright (C) 1980 -1998 The Regents of the University of California.
All rights reserved.
Redistribution and use in source and binary forms, with or without
modification, are permitted provided that the following conditions
are met:
1. Redistributions of source code must retain the above copyright
notice, this list of conditions and the following disclaimer.
2. Redistributions in binary form must reproduce the above copyright
notice, this list of conditions and the following disclaimer in the
documentation and/or other materials provided with the distribution.
4. Neither the name of the University nor the names of its contributors
may be used to endorse or promote products derived from this software
without specific prior written permission.
THIS SOFTWARE IS PROVIDED BY THE REGENTS AND CONTRIBUTORS ``AS IS'' AND
ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE
IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE
ARE DISCLAIMED. IN NO EVENT SHALL THE REGENTS OR CONTRIBUTORS BE LIABLE
FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL
DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS
OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION)
HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT
LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY
OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF
SUCH DAMAGE.
Usando el comando «calendar».
Nada más en la terminal al introducir el comando sin ningún parámetro veremos algo similar esto, os indicamos que la salida por pantall dependerá de la fecha de vuestro ordenador y os dará resultados similares o diferentes:
Figura 1:
bsdmainutils calendar 22 y 23 de abril
Notad la última línea en castellano, ya os explicaremos luego. Como bien podéis observar la cosa va en idioma inglés lo cual no representa problema, tal cual el latín en el mundo antiguo fue la lengua franca así lo es hoy este idioma. Lo que os advertimos es que hay varios idiomas más, tales como el francés y el ruso [justo arriba del Día de San Jorge esta en ruso el «Красная горка (праздник)» -aparición de Jesucristo a sus discípulos y la conversión del Apóstol Tomás-] y aunque no tiene calendarios del planeta entero, la intención del programa es bueno y tiene dos utilidades extras que estudiaremos pronto.
¿De dónde saca este programa calendar los datos a mostrar por pantalla? En la carpeta /usr/share/calendar/ de nuestros ordenadores se almacenan una serie de ficheros con el nombre, cómo no, calendar pero con diferentes extensiones cada uno, por ejemplo .russian, .christian o .computer.
Figura 2
ls usr/share/calendar
Como bien imaginamos por los metadatos, cada extensión describe lo que contiene el archivo y cuando llamamos al programa calendar simplemente lee y extrae los datos correspondientes a la fecha actual de cada fichero, pero hay más: también hay unos directorios con nombres claves que describen las dos primera letras el idioma separados de un guión bajo y dos letras más en mayúsculas que describen el país. Así tenemos que el directorio de_AT contiene en idioma alemán («deuschtland» en inglés) del país Austria (AT) donde se habla el alto alemán, más inclinado hacia el latín; de segundo en el listado está de_DE que corresponde al idioma Alemán de Alemania (ea, eso sonó feo en nuestro bello idioma castellano, nuestro idioma no es amistoso con esto de las redundancias).
Como somos unos «hackers» -o estamos en camino de ‘graduarnos’- podemos hacer uso del comando grep y la ‘tubería’ «|» para filtrar resultados por una palabra clave específica, por ejemplo «Bonne fête» o «Feliz cumpleaños» en francés, para ello teclearemos lo siguiente: calendar | grep «Bonne fête» y solo tendremos dos líneas –o ninguna o varias, repetimos que eso depende de la fecha de nuestro ordenador-.
Esto es para búsquedas puntuales y exactas (claro que con el uso de expresiones regulares podremos ampliar la búsqueda -mayúsculas/minúsculas, caracteres comodín, etc), pero ¿qué tal si queremos ver temas específicos? Veamos alguno de estos ficheros de datos con fechas y busquemos uno que está en nuestro idioma, por ejemplo «calendar.argentina». Si le damos el comando cat en la ubicación /usr/share/calendar al fichero calendar.argentina:
Figura 3
cat usr/share/calendar/calendar.argentina
Evidentemente escrito en lenguaje C notamos un encabezado describiendo el autor, unas variables de enlace para ser compiladas, el conjunto de caracteres a emplear y el conjunto de datos, uno por cada línea. Comienza con el mes abreviado en tres letras del idioma inglés, espacio, dos dígitos -cero a la izquierda de ser necesario-, caracter tabulador y luego la descripción del evento del correspondiente día.
Sumamente importante a destacar es que debemos separar la fecha de la descripción por medio del caracter tabulador( Tab↹ ), de lo contrario la línea no será mostrada en el calendario (nuevo en esta versión y que se diferencia de versiones anteriore según «man calendar«).
Hasta acá lo único especial son los comandos en lenguaje C ya que los eventos están muy bien «formateados» en texto plano pero son precisamente esas referencias en C las que nos indican que hay algo más. Esto quiere decir que «calendar» tiene una estructura rígida y que deben tener esos encabezados pero la cosa no termina allí. Si detalláis en la «Figura 2» nosotros agregamos un fichero calendar.venezuela con encabezado en toda regla y unos pocos acontecimientos históricos de nuestro país pero nada de nada, no lo muestra para nada. Eso quiere decir que solamente se atiene a los archivos que vengan con el paquete para probar esto último modificamos el fichero calendar.unitedkingdom:
Y modificamos la línea del 23 de abril, Día de San Jorge, le colocamos la descripción en castellano y la muestra por pantalla sin problema alguno (figura 1). Lo bueno del software libre es que tenemos acceso directo al código fuente y podemos modificar y compilar, ya sea de manera estática o dinámica, a gusto con nuestras modificaciónes. Pero antes de hacer esto sigamos estudiando las opciones ya establecidas en el comando «calendar» y luego veremos que más podemos hacer.
Parámetros del comando «calendar»:
Primero podemos consultar los eventos de cualquier otra fecha simplemente acompañando de un espacio, el comando del parámetro «-t«, otro espacio, y la fecha en formato AAAAMMDD, por ejemplo el 30 de diciembre de 2017 lo solicitamos de la siguiente manera:
calendar -t 20171230
Desglosamos la respuesta y no vemos por ningún lado la nota con el fallecimiento del gran Ian Murdock, padre de la distribución Debian (madre a su vez de Ubuntu) y que tiene su propio fichero calendar.debian. Por si acaso es que estamos cegatones volvemos a aplicar el comando grep de la siguiente manera:
calendar -t 20171230 | grep "urdock"
El cual no devuelve nada, aunque si usamos
calendar -t 20171230 | grep "KPD"
Sí que obtenemos respuesta: «Gründung der KPD, 1918», «Kommunistische Partei Deutschlands» o establecimiento del Partido Comunista Alemán, el 30 de diciembre de 1918. Es por ello que tecleamos el comando
sudo nano /usr/share/calendar/calendar.debian
y agregamos la siguiente línea (recordad de insertar pulsar la tecla Tabulador entre la fecha y la descripción):
Dec 30↹Ian Murdock, stalwart proponent of Free Open Source Software, Father, Son, and the 'ian' in Debian.
Guardamos y listo, guardamos el recordatorio de tan lamentable fallecimiento para futuras generaciones ??.
Por defecto el comando calendar muestra dos días de acontecimientos (el nombre correcto son recordatorios) pero podemos especificar el número de días con el parámetro -l acompañado del número de días hacia adelante que queremos visualizar (nota: el otro parámetro que hace exactamente el mismo trabajo es -A pero como se presta a confusión con el otro parámetro –a usaremos siempre -l). Así si queremos ver exactamente los recordatorios del 30 de diciembre debemos teclear lo siguiente:
calendar -l 0 -t 20151230
Figura 4
calendar -l 0 -t 20151230
Con el parámetro -B podemos especificar hacia atrás en el tiempo, desde la fecha señalada por el parámetro -t, el número de días que queramos ver. Por cierto que si se obvia el parámetro -t se toma la fecha del ordenador y si es viernes mostrará hasta el próximo lunes siguiente (si hay recordatorios); el parámetro -w se basa en eso para especificar el número de días hacia el futuro, pero no hayamos especialmente útil esa opción.
¿Recuerdan que comentamos haber realizado un calendario para Venezuela? Pues bueno llegó la hora de poder visualizarlo con el parámetro -f acompañado de la ruta de ubicación del archivo de marras, para ello metemos:
¿Qué tal nos ha quedado? Para subir este archivo y contribuir con el software libre publicaremos dicho archivo en GitHub con licencia «Creative Commons» e instrucciones sobre como instalarlo y utilizarlo.
Instalando «calendar.venezuela» en nuestro ordenador.
Según las instrucciones en el archivo calendar.alldeberíamos copiar dicho archivo a nuestra carpeta personal «~/.calendar/» si queremos editar dicho archivo. Esto es así ya que si compartimos un ordenador con varias personas lo lógico es que cada quien tenga su calendario particular, es decir, en el fichero «calendar.all» podemos especificar cuales ficheros queremos ver y/o utilizar. Si lo copiamos a nuestro perfil personal podemos editarlo sin molestar a los otros usuarios del sistema.
En nuestro caso decidimos modificar el archivo calendar.all para todos los usuarios para que tengan acceso al fichero de recordatorio de Venezuela (ambos en la carpeta /usr/share/calendar/). Para ello agregamos al archivo la siguiente línea, justo al final, por orden alfabético:
#include <calendar.venezuela>
Luego guardamos y podemos inmediatamente comprobar si funciona. De igual manera así como agregamos, podemos «quitar» ficheros de recordatorios que no pensamos usar. En realidad quitamos es la referencia o referencias, no el o los archivos en sí mismos.
Comandos «cal» y «ncal»:
Si necesitamos ver por pantalla el mes actual simplemente tecleamos cal y lo veremos por pantalla y el día actual estará resaltado. De manera similar funciona ncal pero en vez de tener los días de la semana en el eje de las abscisas los coloca en el eje de las ordenadas. Los parámetros son comunes a ambos comandos, pero tienen sus excepciones (os queda como tarea averiguar cuáles):
Si no queremos ver resaltado el día actual usaremos el parámetro -h.
Si queremos ver un mes específico del año actual usaremos -m n donde n es el número del mes. También podemos colocar las tres primeras letras del mes (inglés o castellano, sin embargo no reconoce francés ni ruso).
Si queremos ver el año completo -en curso- colocamos -y. Si necesitamos un año específico lo colocamos al lado (calendario gregoriano). Por ejemplo podremos saber que el 26 de diciembre del año 7017 será un día viernes. ?
Podremos combinar mes y año en la misma orden, ejemplo: cal -m 12 2117 mostrará el mes de diciembre del año 2117.
Algo muy útil es visualizar el mes anterior, el actual y el venidero: para ellos usamos el parámetro -3.
Para ver varios meses hacia adelante, -A seguido del número de meses; -B especifica los meses hacia atrás. Ejemplo: «cal -B 1 -A 3″.
Como sabemos el día cero en informática es el domingo, día del Señor, quien al séptimo día tomó descanso (sábado para los judíos). Para nosotros los católicos el domingo es día de adorar a Dios así que comenzamos a trabajar los lunes, por ello podemos especificar que las semanas comienzen los días lunes con -M y con -S comienzan los domingos (opción por defecto). Esta opción no funciona con cal no obstante ncal tiene un parámetro -b que tiene el mismo estilo de cal, ¡probad!
Comando «yes»:
Brevemente diremos que es un comando para nosotros los «nerds»: el comando yes repite indefinidamente por pantalla el texto que lo acompañe. Para detenerlo debemos usar la combinación de teclas CTRL+C (esto es válido para todos los comandos de terminal). Viene con el conjunto de utilerías básicas GNU.
Comando «col»:
El comando col también es poco conocido pero tiene el aliciente de trabajar con los comandos nroff,tbl y colcrt; sin embargo le hallamos cierta utilidad didáctica si lo combinamos con los caracteres especiales utilizados para el shell y el lenguaje C. Es por ello que comenzaremos de atrás para adelante: presentamos los caracteres especiales y terminamos con el comando col.
Pues bien, en el juego de caracteres ASCII (ahora sustituidos por los caracteres UNICODE y representados de manera práctica con UTF-8 –revisad nuestro tutorial sonbre HTML5- ) los primeros 31 caracteres son especiales, llamados «de sistema» y tienen diversos usos especiales. Como abreboca tenemos el ACK (acknowledgement) o reconocimiento: si recibimos un datagrama por TCP (o un paquete por puerto serial) y el contenido es recibido de conformidad a reglas preexistentes simplemente contestamos enviando dicho caracter, el número 6 en sistema de numeración decimal (en sistema binario es 000 0110 e igual es 6 en octal y hexadecimal). Además de esta numeración en el lenguaje C (así como Java, Perl e incluso Visual Basic) se le representa con caracteres de escape (esto se presta a confusión a la hora de traducir al castellano, ojito como lo interpretáis). Estos caracteres de escape tienen la función de salir, escaparse de la representación tal como son y se interpretan por pantalla e impresoras de matriz de punto (y algunas de inyección de tinta) de manera diferente. ¿Qué diantres tiene esto que ver con la terminal GNU/Linux o «shell»? ?
Vamos a la práctica directamente con solamente un caracter: el número 11 que corresponde al tabulador vertical (no confundir con el tabulador horizontal) al cual podemos almacenar en una variable con ayuda del operador $ el cual interpreta los códigos «escapados» por medio de «\0» -si es octal- o «\x» si es hexadecimal. En este caso sería «\013» en octal o «\xob» en hexadecimal. Corred los siguientes ejemplos en vuestra terminal:
Como notaréis aparentemente no vemos nada por pantalla y para notar como trabaja el tabulador vertical podemos acompañarlo de texto descriptivo de la siguiente manera, mirad la animación:
comando col
Allí veís el famoso comando col en acción. Otra forma de representar al tabulador vertical en lenguaje C es con «\v«:
jimmy@KEVIN:~$ linea=$'\vLinea 1.\vLinea 2.\vLinea 3.'
jimmy@KEVIN:~$ echo "$linea"
Linea 1.
Linea 2.
Linea 3.
jimmy@KEVIN:~$
Comando «colrm»:
El comando colrm nos permite remover la primera n columnas ya sea de un archivo de texto o lo que ingresemos por cónsola de comandos. Hacemos notar que la numeración comienza en uno y no en cero como la mayoría de las matrices en computación. El ejemplo aclara dudas:
comando colrm n+1 columnas
Otro uso es suministrarle dos parámetros: la columna de inicio y el largo que removerá:
comando colrm n m columnas
Comando «column»:
El comando column viene a ser de utilidad si queremos mostrar en columnas una lista que tengamos ya sea en un archivo o en una entrada de texto de terminal con el conector tubería «|«.
comando column
Comando «from»:
Este comando permite visualizar lo que hallan enviado los usuarios por el sistema de correo en un ordenador GNU/Linux. Sirve como sistema de comunicación enre los usuarios registrados en un ordenador.
Comando «hexdump»:
Permite desglosar los códigos ASCII en su representación decimal, octal o hexadecimal e incluso aplicandole un formato específico (aparte de los que trae de manera predeterminada) ya sea de un archivo o por entrada de terminal. Acá vemos el formato más útil para dicho comando, pero las posibilidades son infinitas:
jimmy@KEVIN:~$ echo "ABCD" | hexdump -v -e '/1 "%_ad# "' -e '/1 "%02X hex"' -e '/1 " = %03i dec"' -e '/1 " = %03o oct"' -e '/1 " = _%c\_\n"'
0# 41 hex = 065 dec = 101 oct = _A_
1# 42 hex = 066 dec = 102 oct = _B_
2# 43 hex = 067 dec = 103 oct = _C_
3# 44 hex = 068 dec = 104 oct = _D_
4# 0A hex = 010 dec = 012 oct = _
Esencialmente usamos el comando echo para enviar las cuatro primeras letras del abecedario por medio del comando «tubería» «|» y entregarselo a hexdump el cual lo desglosa caracter a caracter y muestra su código ASCII en diferentes sistemas de numeración para luego insertar un retorno de carro al final de cada línea «\n«.
Comando «look»:
Si por ejemplo necesitamos buscar palabras que tengan un prefijo común, por ejemplo «oft», introducimos «look oft» lo cual devuelve unas cuantas palabras… en inglés (often: a menudo, frecuentemente). Si bien indica que depende de la configuración que tengamos en ENVIRON (por ejemplo podemos ver cual lenguaje tenemos configurado si tecleamos echo $LANG) siempre utiliza el idioma inglés por defecto. Para buscar una lista de palabras en idioma castellano deberemos especificar que usaremos el diccionario ubicado en /usr/share/dict/spanish. ¿Utilidad? Tal vez querramos hacer un ataque de fuerza bruta a una contraseña usando palabras comunes, quien sabe.
Comandos «wall» y «write»:
Con wall podremos enviar un mensaje a todos los que estén conectados o conectadas por cónsola, quieran o no recibir el mensaje. Por el contrario, si queremos enviar a un usuario específico usamos el comando write acompañado del nombre de usuario y la erminal donde esté conectado. Para saber quiénes están en línea usaremos who.
Otros comandos poco conocidos:
lorder, ul.
Comandos que se deben instalar desde repositorios oficiales.
La verdad es que revisando los temas publicados por nuestros colegas de GNULinuxBlog (por ahora quien publica el tema, el sr. Elías Rodríguez Martín y el sr. José Miguel, creador del blog) encontramos uno en particular muy útil y que nosotros habíamos enfocado de una manera un tanto complicada en comparación con la facilidad de lo que allí proponen. Cuando conseguimos que alguien es más listo que nosotros inmediatamente lo reconocemos y aprendemos de dichas personas, no tenemos rubor en admitirlo, por eso os pedimos que nos acompañéis en nuestro artículo de hoy: compartir ficheros de una manera rápida y sencilla con Python.
El formato PDF es hoy en día ubicuo, sin embargo no nos detenemos a pensar mucho sobre cómo funcionan y qué podemos hacer con ellos. Anteriormente publicamos un problemilla que tuvimos para extraer los datos allí contenidos y los cuales ofuscaron de una manera muy intelegente, admirable en verdad, muy bien pensado. Pero eso no nos detiene y allí propusimos una solución que luego lo vamos a complementar con otro de nuestros artículos (todos nuestros tutoriales están interconectados o relacionados para configurar un todo). Empezemos, pues, ¡VAMOS!
Introducción.
Esta entrada no va a ir sobre la historia y normas de los documentos PDF («Portable Document Format» por sus siglas en idioma inglés) ya que sobre eso hay bastante material en la redy, además, que nosotros somos terriblementes pragmáticos. Ojo, no estamos diciendo que estudiar la teoría es mala, sino que en este caso la teoría es compleja, e incluso hay quienes piensan que las especificaciones establecidas son «maléficas» ya que permiten muchos fallos en la seguridad de nuestros ordenadores, pero ¿por qué a devenido esta situación? Veamos.
Brevísima historia del PDF.
Para todos los efectos, en vez de escribir a cada rato «Formato de Documento Portátil» os mostraremos el acrónimo de tres letras PDF por el cual es ampliamente conocido a nivel mundial por ser la norma de facto digital.
Aunque vosotros no lo creaís, el PDF comenzó siendo un formato privativo por parte del Doctor John Warnock, allá en 1991 (cuando nosotros en esa época montábamos redes de área local con Netware Novell con IPX/SPX y cable de red coaxial RG58 de 10 mbps -y estudiábamos ingeniería en la Universidad de Carabobo y aún Linus Torvalds estaba por comenzar a estudiar en la universidad-). Originalmente el proyecto se llamaba «Camelot» y para 1992 obtuvo su madurez técnica.
La idea era «sencilla»: poder abrir un fichero bajo diferentes sistemas operativos (y, por ende, en distintos hardwares) de la misma forma y manera, tanto por pantalla como por impresora. Debido a las limitaciones de los ordenadores y el costo de los mismos (y vaya que nosotros lo podemos atestiguar, lo sufrimos en carne propia) la ardua tarea era lo que hoy damos por sentado -recordad que el internet no estaba masificado aún-: que un documento se viera igual a como lo habían diseñado, «artísticamente», los autores respectivos. En aquel tiempo la idea era revolucionaria, apenas comenzábamos a usar sistemas operativos con entorno gráfico y dispositivos apuntadores -léase ratones-.
Para ello el Dr. John Warnock y su socio Charles Geschke basaron las especificaciones en un archivo autocontenido que contuviera las fuentes (tipos de letras) e imágenes -tan simple como eso- y en base a esas especificaciones programar diferentes ejecutables que pudieran abrir y mostrar dichos documentos en diferentes ambientes. Pero ellos no estaban solos en su trabajo, ambos (Warnock y Geschke) trabajaban en «Xerox’s Palo Alto Research Center (Xerox PARC)» y estaban tratando de convencer a dicha empresa acerca de un nuevo lenguaje gráfico que ellos denominaban Interpress pero no le prestaron atención tras lo cual decidieron renunciar y fundar la empresa Adobe (¿la conoceís acaso?) y rebautizaron dicho lenguaje como PostScript. Como véis, era software privativo e hicieron dinero a raudales por aquello de que «en tierra de ciegos, el tuerto es el rey».
Fallas en la seguridad del PDF.
Como podremos imaginar, lo único constante es el cambio, y para PDF ésto no es la excepción. Con el devenir de los años y el aumento de la potencia de los equipos aunado a la masificación de la internet, se hizo necesario -por ejemplo- que en los archivos PDF pudiera insertarse enlaces web para ampliar la información que uno leía. Pero las aplicaciones que leen y muestran documentos PDF no fueron hechas para navegar por internet, eso ya es un mundo completamente aparte y diferente, sumamente difícil de incrustar (ya veremos después que al final sucedió lo contrario: los modernos navegadores web pueden mostrar documentos PDF sin ningún tipo de problema debido a las bien conocidas especificaciones de formato de archivo).
La solución para la época fue que las aplicaciones lectoras de documentos PDF (lo abreviaremos de ahora en adelante como visor PDF) se les dió la «facultad» de lanzar aplicaciones no solo para los enlaces web contenidos en el documento sino también para todo el «multimedia» -audio y vídeo- e incluso la ejecución de ciertos lenguaje scomo JavaScript . Acá un ejemplo, en vídeo, de la situación en el año 2010:
El señor Neil J. Rubenking en el año 2010 se hizo la pregunta ¿acaso PDF significa Pretty Dangerous Format (Bonito y Peligroso Formato)? y a la conclusión que él llega es que en ese año, ahora en 2017 y allá por 1990 la solución a los problemas de seguridad en los archivos PDF es volver a sus raíces: mostrar correctamente un documento tal como fue concebido y eliminarle todos los agregados «multimedia» que pueden hacer daño a nuestros ordenadores.
PDF como «formato abierto».
Irónicamente el artículo que data del año 2010, y al cual hacemos referencia en la sección anterior, no nombra para nada el hecho que en el año 2005 la Asociación Internacional para la Normalización («International Organization for Standardization» o ISO por su abreviatura) emitió la norma ISO 19005-1 mejor conocida como PDF/A la cual está basada en la consabida norma PDFdictada por Adobe la cual recoge los sueños y anhelos de los más puristas defensores del documento de formato abierto.
Las características que hacen al PDF/A una joya a ser conservada son las siguientes:
Debe ser independiente del dispositivo donde se visualize.
Debe ser autocontenido, no necesita descargar ningún recurso fuera de los que contiene el archivo en sí.
Debe ser autodocumentado, lo cual garantiza a futuro su interpretación y correcta lectura.
Debido a estas tres características -cada fichero debe contener las instrucciones para abrirlo junto con el texto e imágenes también- resulta en que dichos archivos son ligeramente voluminosos. Pero es un costo que muchos estamos dispuestos «a pagar» e incluso existe una asociación formal que defienden a capa y espada dicho formato y desarrollan aplicaciones que garantizan mantener sus especificaciones.
El PDF/A garantiza su «pureza» al prohibir expresamente las siguientes características:
No deben contener ni audio ni vídeo.
No deben contener imágenes en formato JPG (deben ser imágenes de formato abierto, el JPG es privativo).
El lenguaje JavaScript y el llamado a ejecutar aplicaciones está prohibida.
Todas las fuentes o tipos de letras deben estar contenidas y se debe garantizar que no tienen restricción alguna para ser reproducidas y mostradas (entiéndase fuentes de dominio público).
La manera de definir y describir los colores debe ser independiente del dispositivo utilizado (entiendase especificaciones abiertas o normalizadas de color).
La encriptación está deshabilitada (lo cual es totalmente diferente a comprimir y/o encriptar un fichero PDF/A para enviarlo a otras personas o instituciones).
El uso de metadatos (datos que se describen a sí mismos) basados en normas internacionales reconocidas es obligatoria.
Subsiguientes normas PDF/A.
La norma ISO PDF/A en realidad es la norma PDF/A-1 y luego le sucedieron dos normas adicionales:
PDF/A-2 emitida en el año 2011 la cual extiende las capacidades del PDF/A-1.
PDF-/A-3 emitida en el año 2012 el cual permite la incrustación de diverson formatos de archivos tales como XML, CSV, CAD, hojas de cálculo, etc.
Desde luego, las especificaciones son más complejas, pero en aras de la simplicidad, así lo hemos explicado. Tal vez, y a futuro, publicaremos algo sobre formularios en PDF lo cual consideramos algo verdaderamente útil: recibes un fichero donde puedes llenar ciertos campos (tu nombres, apellidos, etc.) y mandarlo a la impresora. Lo que no consideramos para nada útil es devolver ese mismo fichero por correo electrónico ya que para eso mucho mejor es crear una página web segura (https) para recolectar dicha información en línea y guardarla en una base de datos.
Si habéis aguantado hasta acá nuestra resumida descripción del mundo PDF os felicito y ahora pasemos a la práctica. Como ya os dijimos el PDF fue creado para transmitir información y su contenido jamás ni nunca fue diseñado para ser editado ni transformado.
Es por ello que a veces suceden cosas como la acontecida a nuestro colega de «Linux GNU Blog«:
Lo que sucede es lo siguiente: es un fichero PDF que contiene las instrucciones para un electrodoméstico y con cualquier visor PDF abre perfectamente y de maravilla. Pero he aquí lo extraño: pesa 9 megabytes (exactamente 9.212.740 bytes) lo cual es MUY grande para la información que contiene, considerando que los gráficos son en escala de grises y no tienen mayor detalle que el estrictamente necesario para describir al aparato electrónico. Lo más extraño viene luego, si extraemos un rango de sus páginas, el fichero resultante tiene mayor tamaño incluso que el original, lo cual contraviene cualquier tipo de lógica.
Os explico:el pdf trae código q dibuja imágenes ¿aleatorias? al abrirlo con LibreOfficeDraw ESO RALENTIZA la edición.
De hecho arriba vemos que si lo abrimos con Libre Office Draw tardará muchísimo tiempo en ser abierto, e incluso tal vez no lo hará. Eso es debido a que tiene en capas transparentes que en modo normal no se visualizan pero que a la hora de «editar» el fichero aparece como polígonos aparentemente aleatorios que llenan y «engordan» todo el documento. De hecho Libre Office Draw NO ESTÁ EDITANDO EL ARCHIVO PDF, está simplemente extrayendo su información para que pueda ser editado en formato de dibujo «.odg», y el hecho que pueda ser exportado de nuevo a formato PDF pues es un extra añadido, ya que si queremos seguir editando dicho documento cada vez que queramos, debemos guardarlo en formato «.odg«.
Nosotros hicimos un análisis exportando el contenido PDF a formato XML y eso ocupó más de 50 megabytes debido a la técnica de ofuscamiento basado en dibujar incontables polígono que, en teoría, evitarían que sea «editado» o más bien transformado a otro documento PDF: ¡tanto misterio para un manual de usuario de un artefacto electrónico! Pues más bien nos causa risa tal comportamiento.
Usando aplicaciones para unir y cortar documentos PDF.
Cada quien tiene un estilo diferente de publicar sus conocimientos, en nuestro caso lo orientamos más bien hacia la programación (Python, PHP, lenguaje C, etc.) pero hay excelentes aplicaciones gráficas que suplen rápidamente nuestras necesidadas e incluso algunas como Ghoscript corren en una ventana terminal. Os recomendamos un excelente artículo escrito en castellano donde podréis ampliar vuestro conocimientos sobre el tema PDF.
Luego que haya descargado pues estamos prestos y listos a lanzar nuestras líneas de código. Acá os colocamos el ejemplo dado el caso vosotros utilicéis Python3, ya que debéis utilizar pip3(se sugiere utilizar el comando sudo con la opción «-H» para referirnos a nuestro propio directorio «home«):
pip3 install PyPDF2
Primero podéis descargar el manual de marras cuyo enlace está en uno de nuestros mensajes tipo «tuit»:
Sobre ese manual es que vamos a practicar los comandos -programa- en Python con PyPDF2 y para todos los efectos prácticos nosotros descargamos y renombramos dicho archivo a «manual.pdf» para escribir menos código y mayor legilbilidad didáctica. Comencemos , pues, a desgranar el fichero en una cónsola terminal con Python en modo interactivo:
>>> # agregamos la referencia a la libreria necesaria
...
>>> import PyPDF2
>>> # abrimos el archivo en si y lo almacenamos en 'archivoPDF'
...
>>> archivoPDF = open('manual.pdf', 'rb')
>>> # ese archivo abierto lo leemos con PyPDF2 y lo almacenamos en el objeto 'lectorPDF'
...
>>> lectorPDF = PyPDF2.PdfFileReader(archivoPDF)
>>> # ahora procedemos a obtener la pagina 61, instrucciones en castellano y almacenamos en objeto 'paginaPDF'
>>> paginaPDF = lectorPDF.getPage(61)
>>> # ya tenemos esa pagina en memoria y aplicamos el metodo de extraer solamente el texto
>>> paginaPDF.extractText()
u'2Instrucciones de seguridad\nLea detenidamente estas instrucciones de seguridad \nantes de utilizar el producto.\n ADVERTENCIA\nNo coloque la TV ni el mando a distancia en los siguientes entornos:\nUna ubicaci\xf3n expuesta a luz solar directa\nUn \xe1rea con mucha humedad, com
>>> # LA PAGINA ES LARGA hemos publicado apenas el inicio de ella
... # NOTAD que el texto esta 'formateado' para lenguaje Python para representar caracteres unicode
Cada línea está debidamente comentada y debemos agregar que para visualizar correctamente el texto de la página que está en formato unicode para Python3 se debe utilizar, simplemente, lo siguiente:
print(paginaPDF.extractText())
Para Python (2) debemos hacer una función como la siguiente:
Pero no nos desviemos de nuestro objetivo, desgranar un documento PDF.
Extrayendo un rango de páginas a un documento nuevo PDF.
Acá volvemos a reutilizar los conceptos del ejemplo anterior, de nuevo cada línea está comentada indicando claramente qué hace cada comando:
>>> # Referencia a la libreria necesaria
...
>>> import PyPDF2
>>> # Abrimos el manual al cual lo denominamos origen de datos
...
>>> origenPDF = open('manual.pdf', 'rb');
>>> # Leemos el origen abierto en un objeto lector;
...
>>> origenPDFlector= PyPDF2.PdfFileReader(origenPDF);
>>> # Creamos un objeto escritor de PDF
...
>>> destinoPDF = PyPDF2.PdfFileWriter()
>>> # Creamos un objeto escritor de PDF y adicionamos la pagina 60 (instruccioens en castellano)
...
>>> paginaOBJ = origenPDFlector.getPage(60);
>>> destinoPDF.addPage(paginaOBJ)
>>> # Un ciclo para leer de la pagina 61 a la 80
...
>>> for num_pag in range(61,80):
... paginaOBJ = origenPDFlector.getPage(num_pag)
... destinoPDF.addPage(paginaOBJ)
...
>>> # abrimos un fichero de destino
...
>>> destinoPDFarchivo = open('manual_en_castellano.pdf' , 'wb');
>>> # escribimos el objeto en el fichero de destino
...
>>> destinoPDF.write(destinoPDFarchivo);
>>> # cerramos los archivos debidamente
...
>>> destinoPDFarchivo.close()
>>> origenPDF.close()
>>>
Tendremos así, entonces, un fichero solamente con las instrucciones en castellano que podemos abrir con el visor de dcoumentos predeterminado en Ubuntu, en este caso Evince. En nuestro caso la salida pesa 1.240.731 bytes (para nosotros los viejitos eso es casi un diskette 3½ pulgadas) y, tercos nosotros como somos, lo intentamos abrir de nuevo con LibreOfficeDraw y cuando va más o menos por la tercera hoja «COLAPSA» la aplicación rellenando cada cuadrito «basura» que le colocaron para ofuscar el documento. Luego de 45 segundos es que se presta a mostrar por pantalla una copia del documento, tal como nosotros hicimos en lenguaje Python. Incluso después de abrir por completo la primera página, si nos ubicamos en la novena, por ejemplo, de nuevo LibreOfficeDraw colapsa de nuevo, así que el truco de cargar basura en un PDF vaya que funciona en realidad.
Por ahora vamos a recapitualr el método que aprendimos en esta sección, lo que llamamos pseudocódigo:
Inicio del proceso.
Colocamos la referencia a la librería necesaria.
Abrimos el documento PDF en modo lectura binario.
Creamos un objeto de lectura de la librería y leemos el archivo abierto.
Creamos un objeto de escritura de la librería.
Creamos un objeto de página de la librería que lee del documento origen y lo pasamos al documento destino (1 página a la vez con exactamente todo el contenido de cada página: texto, imágenes, basura…).
Una vez que tenemos el objeto de escritura listo con las páginas que nos interesa, abrimos un archivo destino en modo de escritura binario (lo nombramos como querramos).
LLamamos al método de escritura del objeto de escritura de la librería.
Cerramos el archivo destino.
Cerramos el archivo origen.
Fin del proceso.
Ofuscando nuestros propios documentos PDF.
Podemos «ofuscar» nuestros propios documentos PDF colocandole, por ejemplo, una licencia de Creative Commons como la que acompaña nuestra página web y dejando bien en claro que la información que compartimos es libre pero respetando, al menos, el nombrar la autoría. Para ello podemos crear un documento PDF de una sola hoja que tenga una marca de agua que simplemente es un texto en gris claro escrito a 45° sobre la diagonal de la hoja.
Para crear nuestro documento con la marca de agua podemos utilizar rapidamente a Gimp y exportamos a PDF colocandole el nombre, muy original eso sí, marca_de_agua.pdf y escribir el siguiente código:
# Solo las librerias necesarias
from PyPDF2 import PdfFileWriter, PdfFileReader
# Creamos un objeto de escritura
salida = PdfFileWriter()
# Abrimos el documento original
origenPDF = PdfFileReader(open('origen.pdf', 'rb'))
# Abrimos nuestro documento creado con marca de agua
marca_aguaPDF = PdfFileReader(open('marca_de_agua.pdf', 'rb'))
# Abrimos la primera hoja del documento marca de agua y lo guardamos en un objeto hoja PDF
hoja_marca_agua = marca_aguaPDF.getPage(0)
# Hacemos un ciclo para COMBINAR cada hoja del origen con la hoja con la marca de agua
for i in xrange(origenPDF.getNumPages()):
# Leemos la pagina en un objeto y luego lo combinamos con 'merge()'
pagina = origenPDF.getPage(i)pagina.mergePage(hoja_marca_agua)
# vamos agregando al documento destino
salida.addPage(pagina)
# escribimos en nuestro disco duro el resultado
with open('destino.pdf', 'wb') as f:salida.write(f)
¿En qué consiste la ofuscación? Podemos escribir con Python un programa que cree una hoja PDF con imágenes aleatorias para luego combinarla con el documento que queremos ofuscar (agregar por capas) y luego hacer la capa con dichas imágenes como invisible (la capa) que cualquier visor PDF no la msotrará pero que al extraer las hojas siempre nos llevaremos dichas imágenes y las podremos ver (y hasta colapsar) al programa que hayamos usado para extraerle páginas, ¿Qué tal os parece?
Eliminando las imágenes del archivo PDF destino.
De la sección «Extrayendo un rango de páginas a un documento PDF» retomamos exactamente todo el código allí escrito y le insertamos la siguiente línea justo antes de escribir en el disco duro el resultado (guiense por los comentarios):
# eliminamos las imágenes del archivo destinoPDF
destinoPDF.removeImages()
# abrimos un fichero de destino
destinoPDFarchivo = open('manual_en_castellano.pdf' , 'wb');
Con el comando «.removeImages()» logramos quedarnos solamente con el texto y el fichero resultante es de 780.895 bytes ¡una reducción de 37%! (pesaba 1.240.731 bytes). Otros dos comandos útiles de la librería PyPDF2 son los comandos para eliminar los enlaces web .removeLinks() y para eliminar el texto .removeText().
El punto interesante es que, de nuevo, abrimos el archivo resultante con LibreOfficeDraw y podemos hacer una copia del documento que puede ser editada pero por supuesto, sin las imágenes que son las que ocasionan que se «cuelgue» la aplicación.
Ya brevemente hemos descrito cómo instalar Shutter en Ubuntu cuando publicamos nuestro tutorial sobre Tesseract OCR y en esta oportunidad le vamos a dar todo el protagonismo que Shutter merece con su reportaje dedicado y, para variar, lo instalaremos bajo la distribución Fedora 25, ¡acompáñanos!
Actualizado el día martes 11 de diciembre de 2018
¡También explicamos como instalar las herramientas de edición (de imágenes, por supuesto)!
Repetimos que esta página no va de ciencias sociales, sin embargo somos fanáticos de la ortografía y en esta oportunidad os presentamos una herramienta para corregir nuestros escritos, que ya son bastantes, por demás. Ahora es el punto donde nos diréis «ea, tío, ¿de qué vais si eso está integrado en ‘todos’ los programas?» Pues bueno preparaos a sorprenderos con los que os vamos a contar, ¡vamos a aprender a programar para corregir nuestra ortografía!