Iniciamos operaciones en 1993 en el sur de Valencia con una maquina XT8088 con 2 unidades de floppy de 5 1/4 y un monitor monocromatico: ¡HEMOS LLEGADO LEJOS!
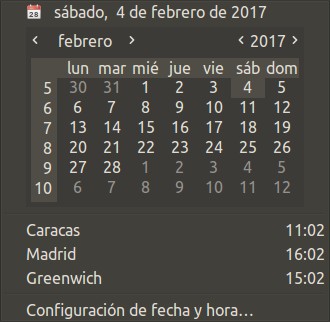
Recién me acabo de percatar que el Ubuntu que uso (14.04 LTS) NO está mostrando el reloj y la fecha, como siempre veo es mi móvil pues, ea, que había desaparecido de mi vista y yo tan tranquilo.
Investigando en este enlace (en inglés) recomiendan abrir una ventana terminal (que en Ubuntu es CTRL+ALT+T) y transcribir lo siguiente:
sudo killall unity-panel-service
colocan su respectiva contraseña ¡y listo!
En el enlace mencionado culpan a ciertas aplicaciones, en mi caso lo que hice fue una «gran» actualización y creo allí fue cuando desapareció de mi Escritorio.
Si desean personalizar aún más hagan click en el botón de apagado y del submenú seleccionan «Configuración del sistema» y al abrir la ventana selecciona «Fecha y Hora» para luego hacer click en la pestaña «Reloj» y cualquier cambio que hagan tomará efecto inmediatamente, prueben y vean.
Dado el caso que «Simple clock» por alguna razón no esté instalado, pues lo reisntalamos con:
para luego reniciarlo (el unity-panel-service ) con el comando que explicamos al principio.
<Eso es todo, por ahora>.
La resolución de monitor que «ha muerto» hoy.
Actualizado el día sábado 04 de febrero de 2017.
Un año y diez meses después de haber comenzado esta entrada -lo cual es muestra de la «estabilidad» de Ubuntu- volvimos a tener problemas con el reloj y la bandeja del sistema. Por supuesto que aplicamos nuestra consabida fórmula aquí explicada pero lamentablemente no funcionó.
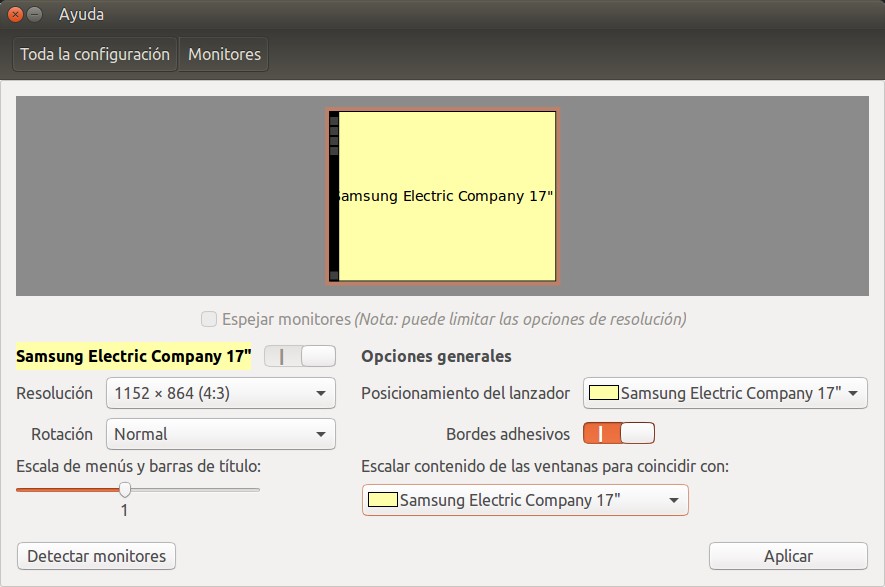
Una cosa que notamos al ejecutar el comando arriba descrito, una y otra vez, fue el «parpadeo» de las ventanas abiertas, que se redimensionaban para ocupar la pantalla completa. Como tenemos un solo monitor, un venerable Samsung de 17 pulgadas en diagonal, lo tenemos trabajando en su resolución nativa de 1024 por 768 píxeles. La resolución nativa indica el mejor tamaño sin perder legibilidad (y nosotros ahora por la edad que estamos más cegatones que nunca). Es por ello que no pocas veces, para ciertas tareas, cambiar la resolución al máximo 1280 por 1024 (esto es especialmente útil para cuando nos conectamos de manera remota a varios clientes con Remmina) y he aquí que apareció de nuevo la barra del reloj.
Monitores en Ubuntu ejemplo con Samsung 17 pulgadas.
Tal vez muchos se sorprenderán con lo que vamos a decir: los monitores de 17 pulgadas «han muerto», eso es parte de la vida, lo único constante es el cambio y lo hemos visto pasar con el transcurso de las décadas. Desde Windows 3.11 con 640 por 480 píxeles, a Windows 98 con 800 por 600, a Windows XP con 1024 por 768 y hoy en día con Ubuntu 16 a 1280 por 1024 píxeles (de hecho en las oficinas utilizamos monitores de 22 pulgadas y los celulares a pesar de tener el mismo tamaño la resolución ha aumentado siendo muy distintivo el caso de «Retina Display®», norma indicada por el genial Steve Jobs, fundador de la empresa Apple).
Esta situación se presenta tiempo después que descargamos «grandes» actualizaciones de nuestro sistema operativo libre favorito y que manifestamos públicamente por medio de nuestra cuenta Twitter:
Por ahora nuestra solución será basada en hardware y no en software ya que consideramos que los programadores de Ubuntu tienen razón: 1024 por 768 se nos ha quedado corto en este año 2017. Es por ello que trabajaremos muy duro para ganar dinero y comprar un monitor de 22 pulgadas que lo conectaremos como principal a la tarjeta de video Nvidia y el viejo monitor lo colocaremos en la tarjeta gráfica integrada Radeon de la tarjeta madre.
Lo único constante es el cambio (y el único cambio que le gusta al ser humano es el cambio de pañal).
Evolución de los monitores a lo largo del tiempo.
Actualizado el miércoles 1° de marzo de 2017.
Para complementar lo del punto anterior, el siguiente vídeo ilustra muy bien, por medio de la evolución de los videojuegos, la terminología y evolución de los monitores y sus resoluciones (aparte de tocar con menos importancia el tema del sonido -y muchísimo menos importante el tema de la memoria RAM-). Disfrutad, pues, el documental en idioma inglés con «The 8-Bites Guy»:
Registro de Información Fiscal ( RIF ): su historia en Venezuela.
Sobre el RIF me contaba una fallecida Contadora Pública (que en paz descanse+) con la cual tuve la feliz oportunidad de trabajar, que en los años 70 cuando ella estudiaba en la Universidad de Carabobo ya en clases calculaban el dígito verificador (que viene a ser similar a los códigos de barra), sólo que en aquella época las computadoras NO estaban al alcance del pueblo (ni siquiera las calculadoras electrónicas -oh cómo recuerdo mi querida Casio A1, ¡si A1! funcionaba con una sola pila doble A de pantalla verde-) y ellos/ellas lo hacían manualmente. En fin, que yo conocía lo del RIF desde los años 80 pero desconocía lo del cálculo del dígito verificador hasta que ella me lo dijo:
SIR RIF 07
Al principio de este siglo me dí a la tarea de buscar dicha fórmula y conseguí el siguiente algoritmo escrito en javascript, desconozco su autoría pero es el que he venido utilizando esta última década (más adelante explicaré cómo funciona):
function VerifRIF(RIF)
{
//
// Función JavaScript VerifRIF Versión 1, 18/Marzo/2002
// Recibe el Numero de RIF sin separadores y devuelve
// True si el RIF es correcto
//
var SumRIF;
var NumRif;
NumRif = RIF
var cadena = new Array();
if (NumRif.length == 10)
{
for (i = 0; i < 10; i++)
{
cadena[i] = NumRif.substr(i,1);
}
cadena[0] = 0;
if ((NumRif.substr(0,1) == "V")||(NumRif.substr(0,1) == "v")) cadena[0] = 1
if ((NumRif.substr(0,1) == "E")||(NumRif.substr(0,1) =="e")) cadena[0] = 2
if ((NumRif.substr(0,1) == "J")||(NumRif.substr(0,1) == "j")) cadena[0] = 3
if ((NumRif.substr(0,1) == "P")||(NumRif.substr(0,1) == "p")) cadena[0] = 4
if ((NumRif.substr(0,1) == "G")||(NumRif.substr(0,1) == "g")) cadena[0] = 5
cadena[0] = cadena[0] * 4
cadena[1] = cadena[1] * 3
cadena[2] = cadena[2] * 2
cadena[3] = cadena[3] * 7
cadena[4] = cadena[4] * 6
cadena[5] = cadena[5] * 5
cadena[6] = cadena[6] * 4
cadena[7] = cadena[7] * 3
cadena[8] = cadena[8] * 2
SumRIF = cadena[0] + cadena[1] + cadena[2] + cadena[3] +
cadena[4] + cadena[5] + cadena[6] + cadena[7] + cadena[8];
EntRIF = parseInt(SumRIF/11);
Residuo = SumRIF - (EntRIF * 11)
DigiVal = 11 - Residuo;
if (DigiVal > 9)
DigiVal = 0;
if (DigiVal == cadena[9])
return true;
else
return false;
}
else return false;
}
Es así ahora que recuerdo, con ayuda de mi envejecido y primer comprobante de RIF que fue el Decreto N° 193 del 2 de julio de 1979 (la cual pueden descargar desde la Procuraduría General de la República Bolivariana o desde nuestro sitio web -gracias a «pdfsam» son tres hojas de la Gaceta ) y bajo la Presidencia de Luis Herrera Campíns cuando se estableció de manera obligatoria dicho registro y era muy amplios los datos que debía contener:
n) Cualquier otra información que requiera la Administración del Impuesto Sobre la Renta.
¡hasta exigían apartado postal! (que para la época fungía como suerte de correo electrónico). Interesante es el artículo 10 el cual ya establecía exhibir el RIF y dejar constancia en las facturas que emitieran ¡no fue sino hasta 1994 que el Presidente Rafael Caldera mandó a crear al SENIAT y muchos años después que emitieron normas de facturación e incluyeron ese punto!
Al final del decreto se aclara que quedan derogados los decretos: N° 2.920 del 24 de octubre de 1978 (creación original del RIF) y el decreto N° 3.102 del 23 de febrero de 1979 (prorrogación de entrada en vigencia del mismo). La diferencia fundamental entre ambos decretos (N° 2.920 y N° 193 -diferentes presidentes de la República, Carlos Andrés Pérez y Luis Herrera Campíns-) estriba en que originalmente sólo se les exigía inscribirse a quienes o cuales hubieran obtenido enriquecimiento neto anual -a partir de 1977- mayor a Bs. 24 mil o «ingresoss» (sic) brutos mayor a Bs. 72 mil anual. En el Decreto de Luis Herrera se obliga a todo el mundo a inscribirse y dado el caso la persona o entidad manifestare que no está obligada a hacerlo (artículo 11, parágrafo único), le dieran igual curso a los trámites que a bien tuvieran que hacer ante el Gobierno pero debía ser reportado en paralelo al Ministerio de Hacienda. En ambos decretos (artículo 7) se establecen los famosos «operativos de RIF» que se ejecutan desde la Presidencia de Hugo Rafael Chávez Frías e indican que se extenderá un comprobante provisional y luego de 3 meses emitirán el comprobante definitivo (imagino que debido a la tecnología de la época: yo, por ejemplo, hacía mis trabajos del liceo en una viejísima máquina de escribir que mi tío desechó de una de sus oficinas la cual yo reparé y ajustaba constantemente). Al día de hoy uno mismo llena los datos por primera vez por internet (basado en el número de cédula en las personas naturales y el tomo y registro en las personas jurídicas) para luego ir en persona a la sede más cercana del SENIAT donde le emiten de una vez el RIF ELECTRÓNICO (en este blog explican de manera más detallada el proceso) luego las renovaciónes se hacen vía web sin necesidad de acudir a las oficinas del SENIAT. Dicho proceso ha logrado reducir en 60% las colas en esa institución .
El RIF DIGITAL tal como lo conocemos hoy en día fue creado en la Gaceta Oficial N° 40.214 del jueves 25 de julio de 2013 y entre otras novedades establece 3 códigos de seguridad para evitar su falsificación así como un servicio en línea por internet para comprobar su veracidad con ayuda de un código QR para ahorrar tiempo evitando escribir la dirección en la computadora o teléfono celular.
Es de hacer notar que en este último decreto se exceptúan de la obligatoriedad de inscripción a los menores de edad (siempre y cuando no posean bienes ni realicen actividades económicas) así como exhibir, reflejar y colocar en productos, publicidad, páginas web (internet), libros contables, facturas, etc. También anuncia la extinción definitiva de la forma «SIR RIF 07» con la cual yo obtuve mi primer comprobante de RIF en 1998.
Los puntos más resaltante del RIF DIGITAL es que se denomina ahora «REGISTRO ÚNICO DE INFORMACIÓN FISCAL» (artículo 4 providencia N° SNAT/2013/0048) y especifica que es «…único, exclusivo y excluyente…» y en el artículo 7 se establece la condición «activo o inactivo» (lo cual pienso yo es reflejo del uso de bases de datos por ordenadores) bajo ciertas condiciones (muerte de persona natural, por ejemplo).
Volviendo al artículo 4 podemos observar la necesidad de identificar con correspondencia unívoca las personas naturales o jurídicas a un código alfanumérico.
He aquí entonces que volvemos a la fórmula del «número de chequeo» (así lo llamaba el SENIAT en 1998) y procedo a explicar el código arriba mostrado:
Declaración de variables y una matriz para luego almacenar cada letra y dígito, lo que se le pasa a la función en la variable «RIF» se almacena en otra variable llamada «NumRif»:
var SumRIF;
var NumRif;
NumRif = RIF
var cadena = new Array();
Importante: el RIF a verificar debe tener exactamente 10 caracteres, si no la función devuelve FALSO:
if (NumRif.length == 10)
Cada uno de los caracteres se almacena en la matriz declarada al principo, importante asignar cero a «cadena[0]» ya que si el primer caracter NO es ninguno de los ya normalizados el cálculo mediante fórmula no coincidará con el dígito verificador:
for (i = 0; i < 10; i++)
{
cadena[i] = NumRif.substr(i,1);
}
cadena[0] = 0;
El primer caracter del RIF debe ser alguno de los siguientes:
«V»: Venezolano o venezolana.
«E»: extranjero o extranjera (número de cédula mayor a 80 millones).
«P»: Pasaporte, por ejemplo es útil para los cantantes que se presentan en nuestro país y que hay que retenerles Impuesto sobre la renta.
«J»: Persona jurídica, osea, compañías anónimas, sociedades anónimas, S.R.L., etc.
«G»: Gobierno, entes gubernamentales, de cualquier Poder, estado, municipio e incluso organismos «autónomos» (ejemplo Universidad de Carabobo RIF G-20000041-4).
A futuro es importante considerar lo siguiente:
ACTUALIZACIÓN AL 25 DE MARZO DE 2015: el Presidente de la República Nicolás Maduro Moros ordenó al SENIAT identificar a las Comunas y Consejos Comunales (imagino yo que será extensivo a las Cooperativas, pienso yo PERO el Presidente no las nombró, esto es idea mía) con la letra «C» las cuales antes se venían registrando con la letra «J».
Dependiendo del primer caracter se le asigna el valor a «cadena[0]» según lo siguiente:
if ((NumRif.substr(0,1) == "V")||(NumRif.substr(0,1) == "v")) cadena[0] = 1
if ((NumRif.substr(0,1) == "E")||(NumRif.substr(0,1) =="e")) cadena[0] = 2
if ((NumRif.substr(0,1) == "J")||(NumRif.substr(0,1) == "j")) cadena[0] = 3
if ((NumRif.substr(0,1) == "P")||(NumRif.substr(0,1) == "p")) cadena[0] = 4
if ((NumRif.substr(0,1) == "G")||(NumRif.substr(0,1) == "g")) cadena[0] = 5
IMAGINO YO que los RIF que comienze por la letra «C» se les asignará el siguiente valor disponible, el seis (ES UNA SUPOSICIÓN MÍA, SE DEBE ESPERAR EL PRONUNCIAMIENTO OFICIAL DEL SENIAT):
if ((NumRif.substr(0,1) == "C")||(NumRif.substr(0,1) == "c")) cadena[0] = 6
Luego ese valor asignado a «cadena[0]» se multiplica por 4, los demás caracteres que deben ser números se multiplican por los siguientes valores correspondientes (importante acotar que esta función le falta discriminar si en realidad son números lo que introduce el usuario en la variable «RIF» de lo contrario asigna cero y el cálculo no dará correctamente):
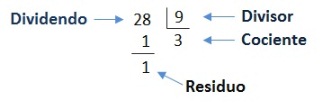
Lo siguiente es calcular el residuo resultante de dividir «SumRIF» entre 11 y para ello se utiliza la función de javascript «parseINT()» que devuelve la parte entera y al multiplicarla por 11 y restar de «SumRIF» devuelve dicho valor.
RECORDAR los miembros que componen una división inexacta (en nuestro ejemplo el divisor es una constante, 11, número primo):
Por último vamos a calcular la diferencia entre el residuo y la constante 11 teniendo en cuenta que si el residuo es 0 u 1 el dígito de verificación valdrá cero :
DigiVal = 11 - Residuo;
if (DigiVal > 9)
DigiVal = 0;
Y listo ya sólo queda comparar si coincide nuestro cálculo con el valor que introdujo el usuario a la función:
if (DigiVal == cadena[9])
return true;
else
return false;
Hagamos un cálculo de ejemplo, para ello tomaremos a la Corporación Socialista del Cemento S.A cuyo RIF es el siguiente: G-20009048-0, comenzemos por eliminar los guiones: G200090480.
«G» toma el valor de 5 multiplicado por 4 =20
2 multplicado por 3 = 6
0 multplicado por 2 = 0
0 multplicado por 7 = 0
0 multplicado por 6 = 0
9 multplicado por 5 = 45
0 multplicado por 4 = 0
4 multplicado por 3 = 12
8 multplicado por 2 = 16
Sumamos:20+6+0+0+0+45+0+12+16=99
Dividimos por 11 y tomamos el residuo que en este caso es cero: 99÷11=9
Dicho residuo lo restamos de once: 11-0=11 y como es mayor que 9 (tiene dos cifras) ENTONCES el dígito de verificación es cero lo cual corresponde con el RIF suministrado: «G-20009048-0»
Es de acotar que en términos de presentación al usuario mi representación favorita es la siguiente:
Dicha forma de interfaz al usuario NO PERMITE introducir letra diferentes a las normalizadas (a futuro incluiré la letra «C» en dicho objeto de programación) y sólo permite números en el resto del RIF haciendo el cálculo del dígito de verificación y es el usuario quien lo debe comparar con el que suministra el cliente a quien se le desea facturar, así se garantiza la correcta escritura del nombre o razón social.
En este último punto debemos tocar el tema de la consulta masiva de RIF cuyo servicio es ofrecido por el SENIAT por medio de su página web, esta consulta (aparte de devolver el nombre o razón social, eso nos ahorra el trabajo de escribir) también devuelve el porcentaje de IVA a retener (75% ó 100% actualmente), en el caso de que la farmacia donde trabajemos sea Agente de Retención; como dicho tema es un poco largo de explicar («Contribuyentes Especiales») he decidido dejarlo para una entrada posterior.
Actualizado el sábado 15 de agosto de 2015:
El día de hoy se tramitó el primer RIF con la letra «C», dicha noticia la recojo vía Twitter, he aquí que incluyo los mensajes:
También el SENIAT en su página web hace el anuncio oficial, más sin embargo aún no veo una Providencia como tal sobre dicho documento de información fiscal.
Son 3 hojitas en formato pdf (agradezco a “pdfsam” y lo recomiendo para dividir y combinar documentos en ese formato); con este aumento las facturas de compra con monto inferior a 20 U.T. (Bs. 3.000,00) podrán ser ingresadas en «caja chica» sin hacerle retención de IVA (Contribuyentes Especiales); también aumentan automáticamente el Bono Alimentación para los Trabajadores y Trabajadoras, el costo de emisión de los pasaportes, multas y un sinfín de cosas más.
Gaceta 0ficial 40.608 sumario.
Para descargar dicho ejemplar electrónico de la Gaceta Oficial desde nuestra página web haga click aquí.
Si desea descargarla desde el Tribunal Supremo de Justicia deberá luego introducir el número “40608” en el cuadro de búsqueda rápida.
Y seguimos aprovechando el receso de Carnaval para continuar nuestro estudio del poderoso motor de base de datos relacional PostgreSQL 9.1.
Nuestra miniserie comienza acá y en la última entrada tocamos el tema de las consultas con uniones las cuales utilizaremos aquí también pero con ayuda del programa psql y tal como lo prometimos vamos a trabajar en profundidad por línea de comandos.
Como recordarán ya habíamos utilizado anteriormente a psql para garantizarle al usuario adminsql acceso íntegro a todas las bases de datos en el servidor PostgreSQL que instalamos.
Breve pausa para hablar sobre seguridad básica.
Normalmente lo que hicimos en el párrafo anterior sólamente se hace si hay un solo usuario y una sola base de datos, un sistema pequeño, tal como era a finales del siglo pasado. Pero ahora con computadoras con procesadores multinúcleo (e incluso hasta computadoras con multiprocesador ) un servidor PostgreSQL puede, tranquilamente, atender muchos usuarios a la vez. Imaginemos que en nuestra Academia de Software Libre de ejemplo cada alumno debe acceder a este recurso único pero debemos de cuidar que cada quien trabaje en su propia base de datos y no toque las ajenas, ya sea por error o a propósito (que se ven casos así). Pues bien PostgreSQL soporta usuarios y grupos internamente, tal como si fuera una computadora con un sistema operativo moderno.
Un usuario pudiera ser cada alumno en clase con su base de datos propia para desarrollar su trabajo y aprobar el curso.
Un grupo, por ejemplo, pudiera ser un sección o curso en determinada aula de clase con derechos de sólo lectura sobre una base de datos perteneciente al instructor de clases y además independiente de otros instructores en otras seccionesde clase; eso nos facilita el trabajo al crear usuarios pues se le asigna al grupo y «hereda» la configuración.
Trabajando con psql.
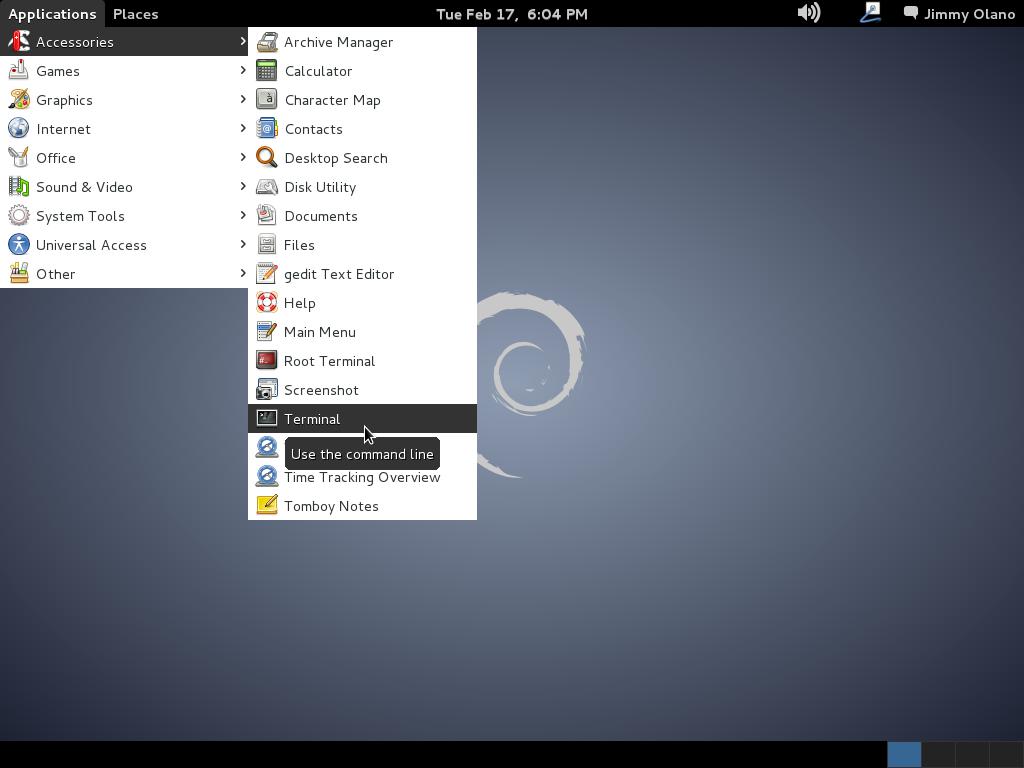
Lo comentado en la sección anterior lo veremos ahora de forma práctica y de la manera más sencilla posible. En la máquina Debian que corre nuestro PostgresSQL seleccionamos «Aplicaciones->Accesorios->Terminal»:
Abrimos así una ventana terminal donde procederemos a ingresar el comando psql pero en esta oportunidad lo haremos acompañado de opciones adicionales:
«–username=nombre_de_usuario» permite colocar a continuación el nombre del usuario que se va a conectar; la forma abreviada es «-Unombre_de_usuario» con un espacio entre ambos (y tened en cuenta las mayúsculas y minúsculas, tal cual se escriben).
«–password» para que nos pregunte la contraseña («–no-password» será útil en trabajos de procesos por lotes); la forma abreviada es «-W» (notad que las formas largas son con doble guión y las cortas con un solo guión).
«–dbname=nombre_de_la_base_de_datos» nos conecta de una vez a donde vamos a trabajar; la forma abreviada es «-d nombre_de_la_base_de_datos» con un espacio entre ambos.
Por ahora ésas son las opciones que utilizaremos por la terminal interactiva pero en realidad psql tiene gran cantidad de agregados los cuales en otras entradas le daremos uso, pero no a todos. Si queréis echar un ojo a la lista completa, pincha aquí.
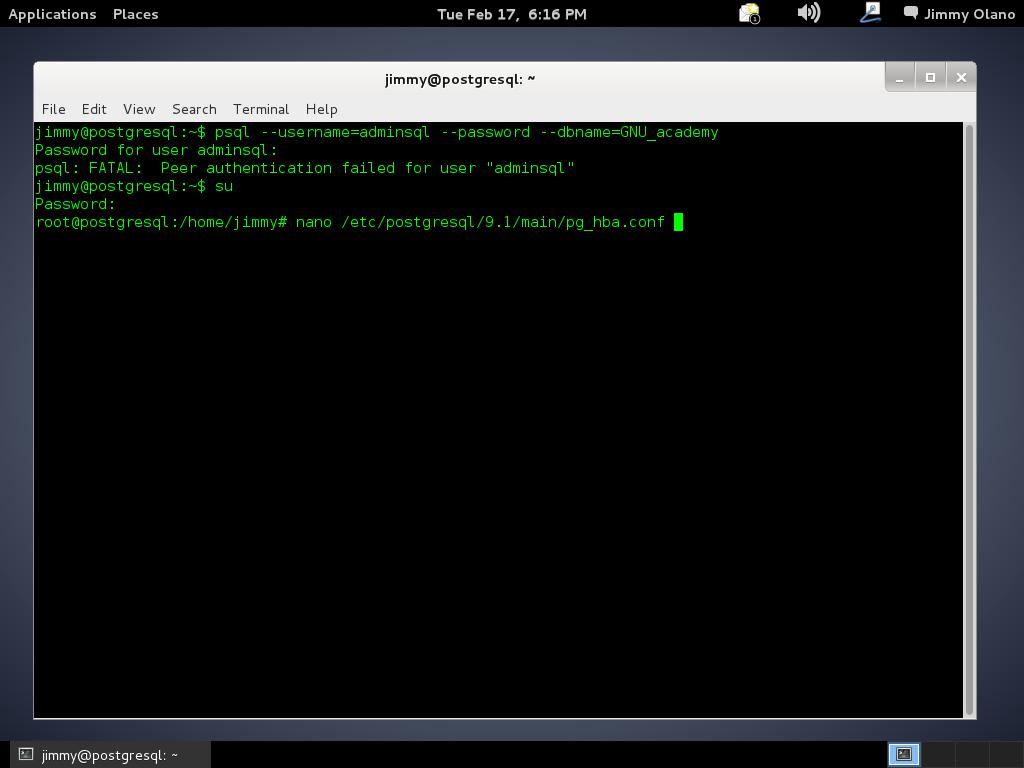
Una vez hayamos presionado intro y haber tecleado nuestra consabida contraseña al cabo de otro intro nos aparece el siguiente mensaje de error:
psql: FATAL: Peer authentication failed for user «adminsql»
Y no, no es porque hayamos ingresado mal la contraseña, que es harta sencilla sino por el asunto de seguridad que describí hace poco. Para que podamos conectarnos debemos crear un usuario llamado adminsql con su correspondiente contraseña en el sistema operativo Debian (o GNU/Linux que usemos). Esto no sería deseable, ya que los usuarios tendrían acceso al sistema operativo en sí, amén que también si son muchos usuarios recarga inncesariamente el sistema de archivos (que aunque tengamos poderosas computadoras siempre la frugalidad es bienvenida), y no, no necesitamos ése esquema de trabajo.
Es por ello que contamos con la opción peer por defecto, apoyada por el sistema operativo y contamos con la opción md5 que encripta la contraseña para mayor seguridad, así que sólo registraremos usuarios dentro de PostgreSQL. Para ello ganaremos acceso como superusuario y luego usaremos el programa editor de texto nano para editar la configuración. Por favor observen la imagen para que tengan el panorama completo:
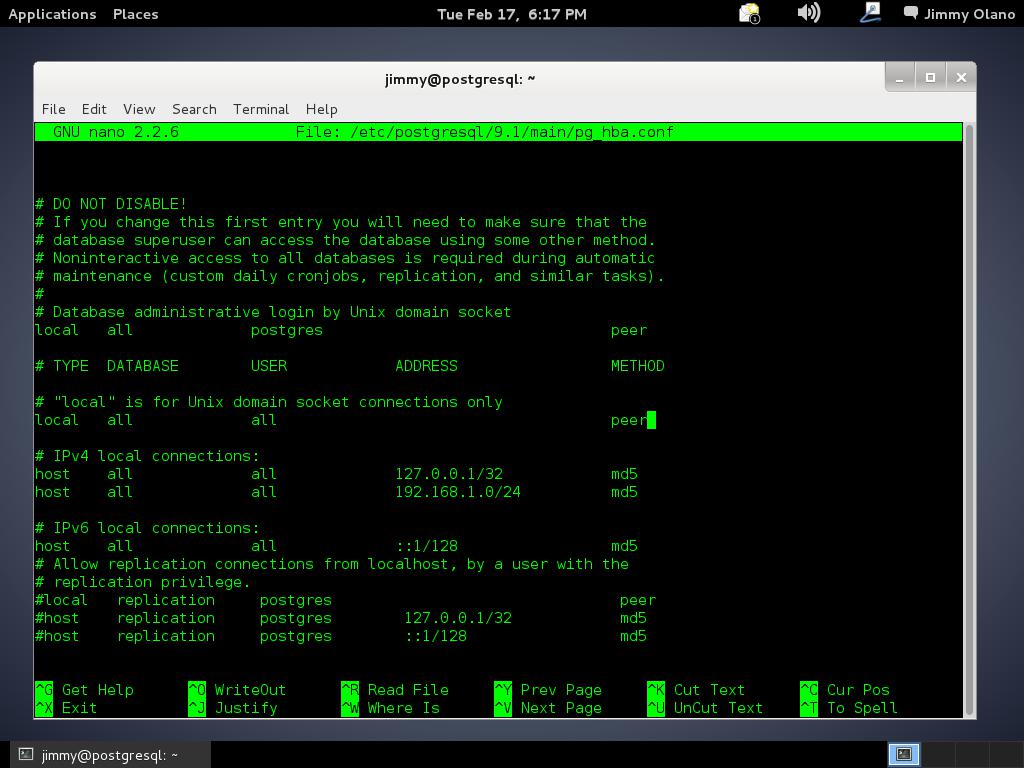
nano /etc/postgresql/9.1/main/pg_hba.conf
y buscaremos la sección «is for Unix domain sockets connections only» donde cambiaremos «peer» por «md5» tal como aparece en la siguiente figura:
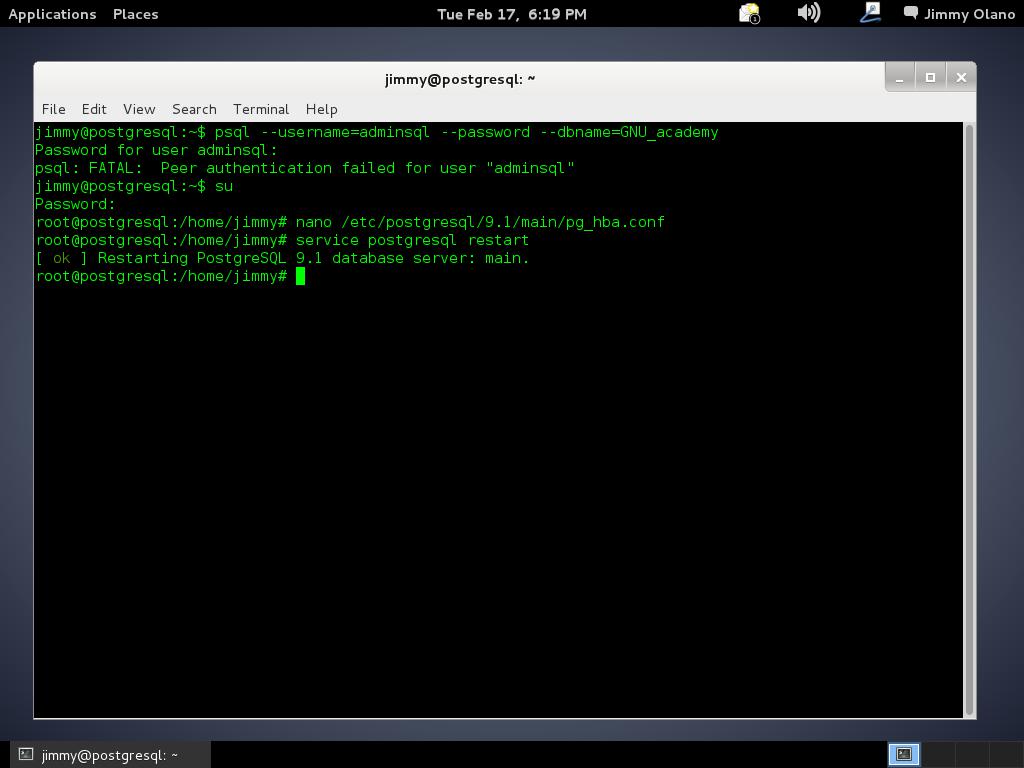
lo siguiente será (recuerden, estamos usando nano) CTRL+X -> «y» -> intro osea guardar y salir en el editor de textos que hayan utilizado ustedes. Una vez hecho esto, necesitamos que el servidor tome la nueva configuración, en realidad el servicio o demonio debemos reiniciarlo, no la máquina en si:
service postgresql restart
y si hicimos bien nuestro trabajo veremos más o menos lo siguiente:
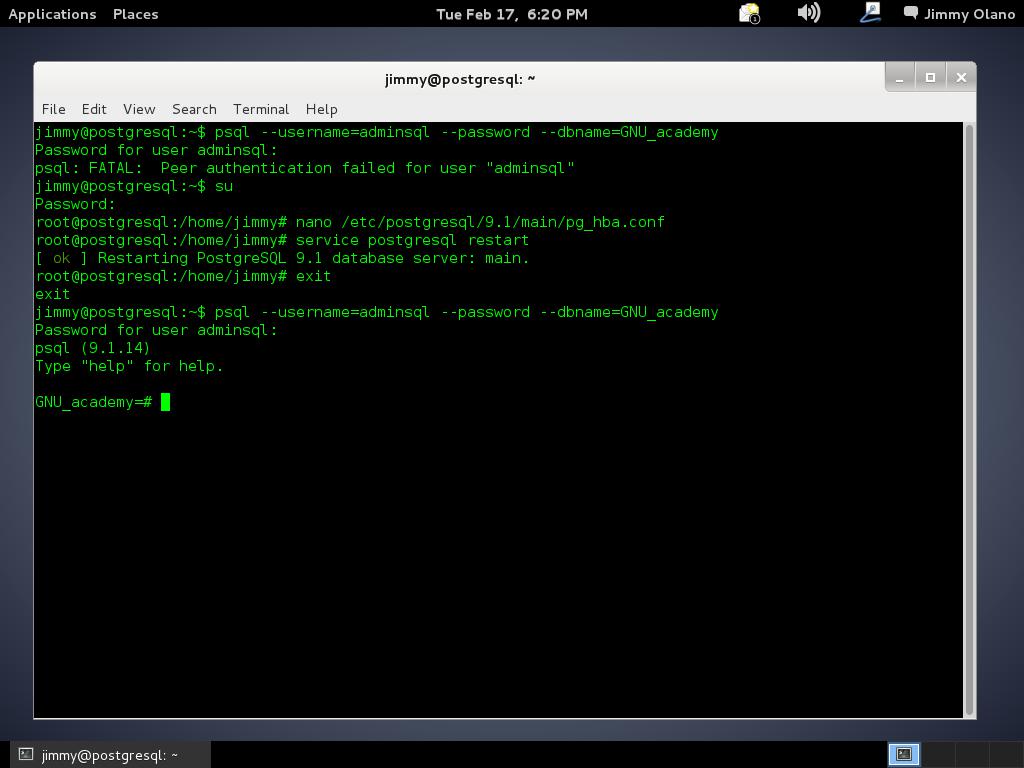
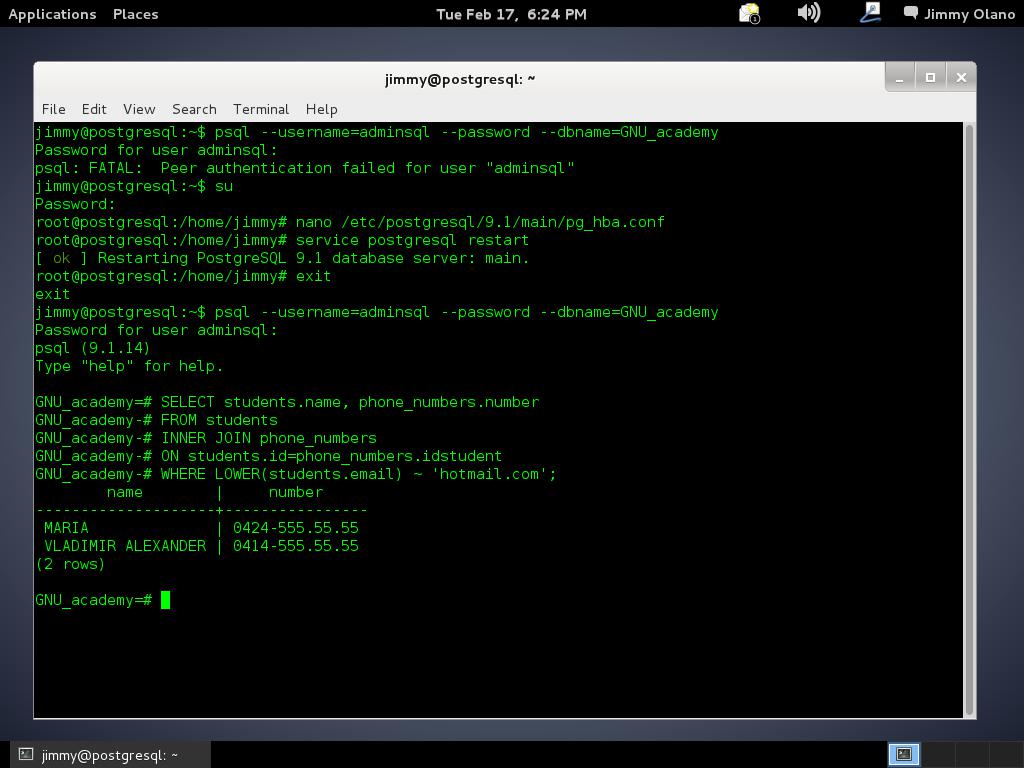
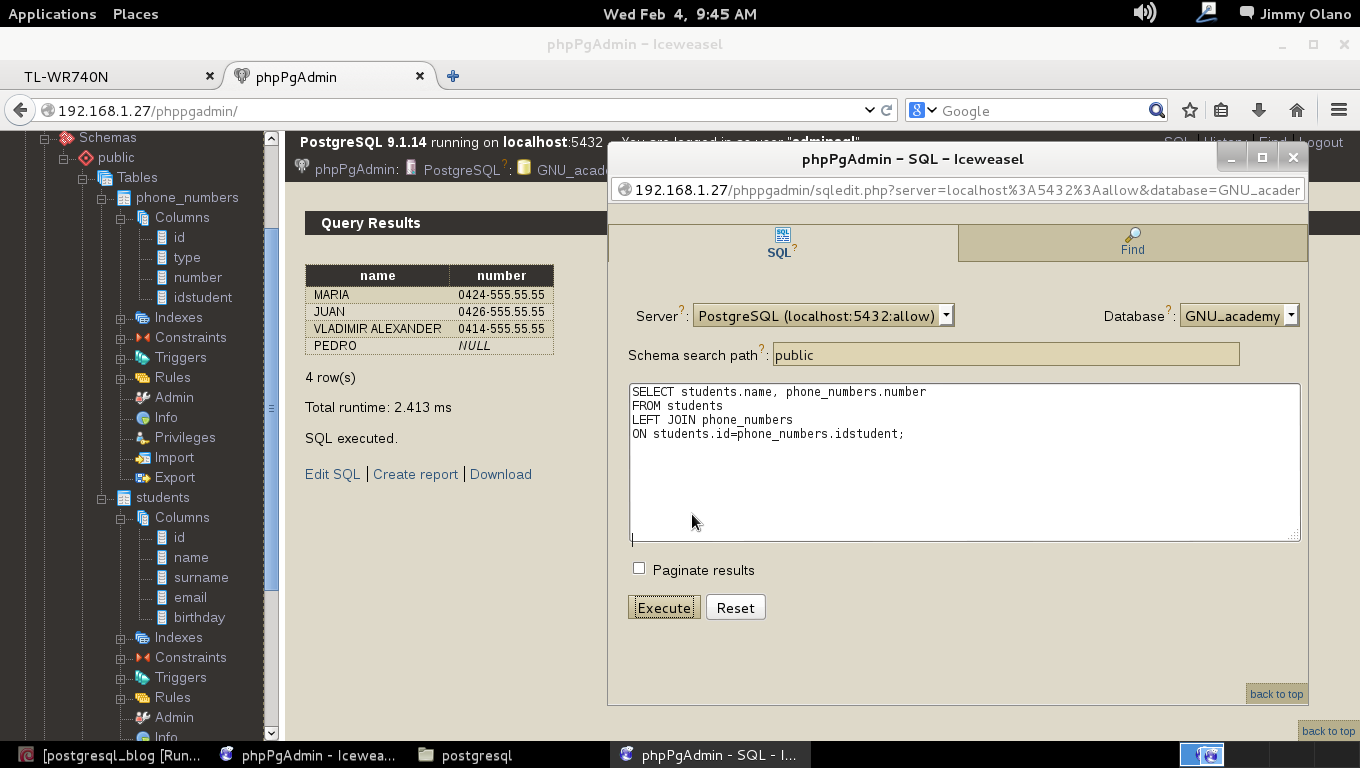
De nuevo introducimos el comando descrito para conectarnos a la base de datos pero esta vez si que tenemos éxito en nuestra tarea:
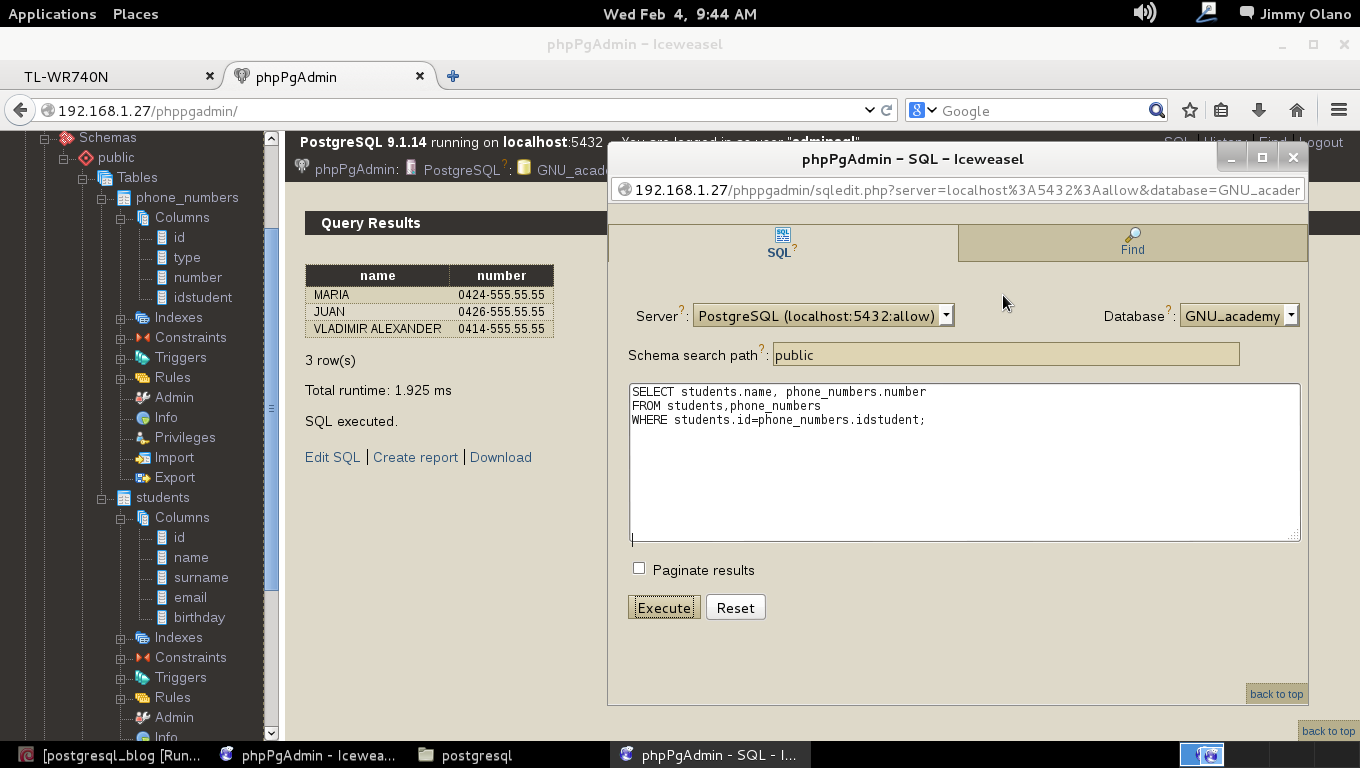
Y allí estamos, a la espera de la primera consulta, usaremos entonces la última de la entrada anterior:
SELECT students.name, phone_numbers.number
FROM students
INNER JOIN phone_numbers
ON students.id=phone_numbers.idstudent
WHERE LOWER(students.email) ~ ‘hotmail.com’;
¿Recuerdan la utilidad del punto y coma para indicar el final de la consulta? Acá nos viene como anillo al dedo pues estas terminales son un tanto incómodas al estar generalmente limitadas a 80 columnas, así que presionamos intro y notad que el prompt cambia de «=#» a «-=» para indicarnos que estamos en una sola sentencia a pesar que son varias lineas:
¡Y listo! hemos hecho nuestra primera consulta por terminal interactiva, ya sólo queda salir de psql y luego de nuestra terminal para ello bastará con teclear:
/quit
exit
En la próxima entrada seguiremos trabajando por línea de comandos para la creación de tablas e insertado de datos en las mismas y ampliaremos el estudio de consultas por uniones JOIN.
Esta vez realizaremos unas consultas por uniones no sin antes dar una breve explicación de la integridad referencial, una característica de las bases de datos relacionales, siempre de la manera más sencilla posible.
Para los que el orden es importante esta serie de artículos sobre PostgreSQL 9.1comienzan acá y la manera de conectarnos al servidor vía phpPgAdmin se describe aquí.
Pues bien, comenzemos ya: tenemos creadas dos tablas llamadas students y phone_numbers y como bien lo describe sus nombres en inglés, sirven para almacenar datos de estudiantes y sus números telefónicos. Como cada persona puede tener varios teléfonos (casa, trabajo, móvil, fax, etc.) y a su vez cada una de esas ubicaciones hoy en día pueden tener varios números diferentes (en mi caso tengo 2 en casa, 3 en el trabajo y uno celular) no tiene sentido crear campos para cada uno de ellos en la tabla students porque no sabemos cuántos va a tener cada inviduo. Cualquiera me puede rebatir diciendo que aunque sea debería suministrar un número de teléfono para alguna emergencia en clase (desde el punto de vista de este ejercicio donde somos una Academia de Software Libre) pero ni con eso contaría yo, es decir, puede darse el caso que no tenga ningún teléfono (hermosa es la película «Enemy of the State» ojalá la disfruten tanto como yo la disfruté en 1999). Es por tanto que en la tabla students no dejamos ningún campo para almacenar el o los que nos suministren y los guardaremos en la tabla phone_numbers teniendo cuidado de guardar de quién es cada cual.
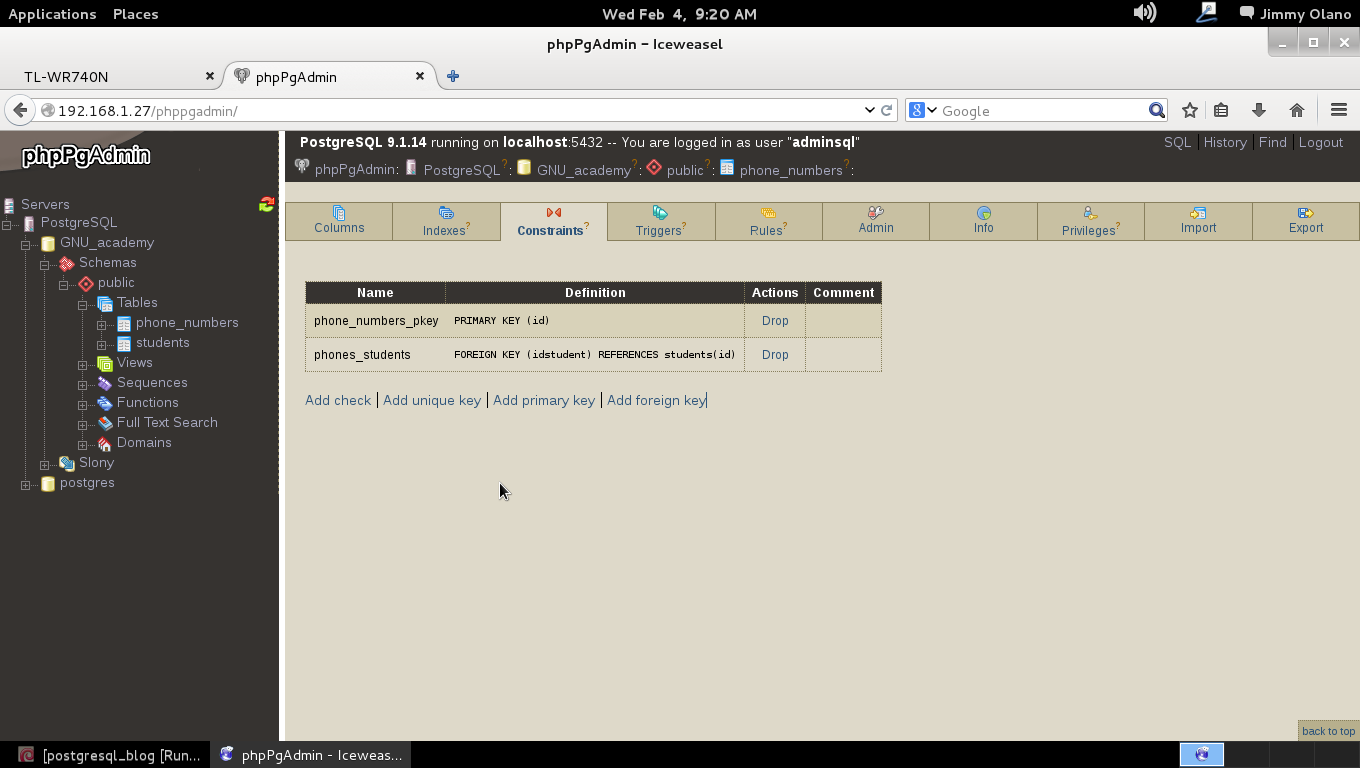
Observemos que al seleccionar la tabla phone_numbers desde phpPgAdmin haciendo click en «constraints» («restricciones») descubriremos el trabajo que hizoVisual Paradigm traduciendo nuestro organigrama a la base de datos:
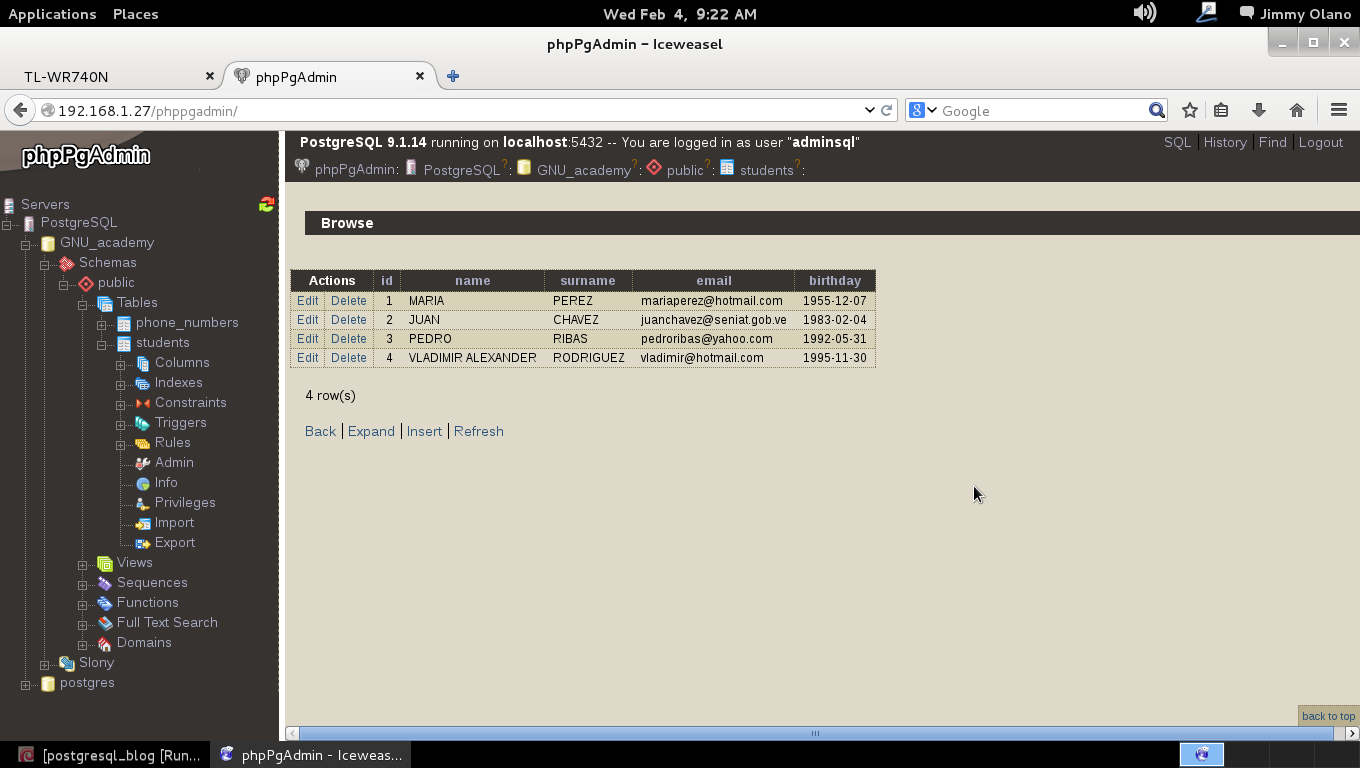
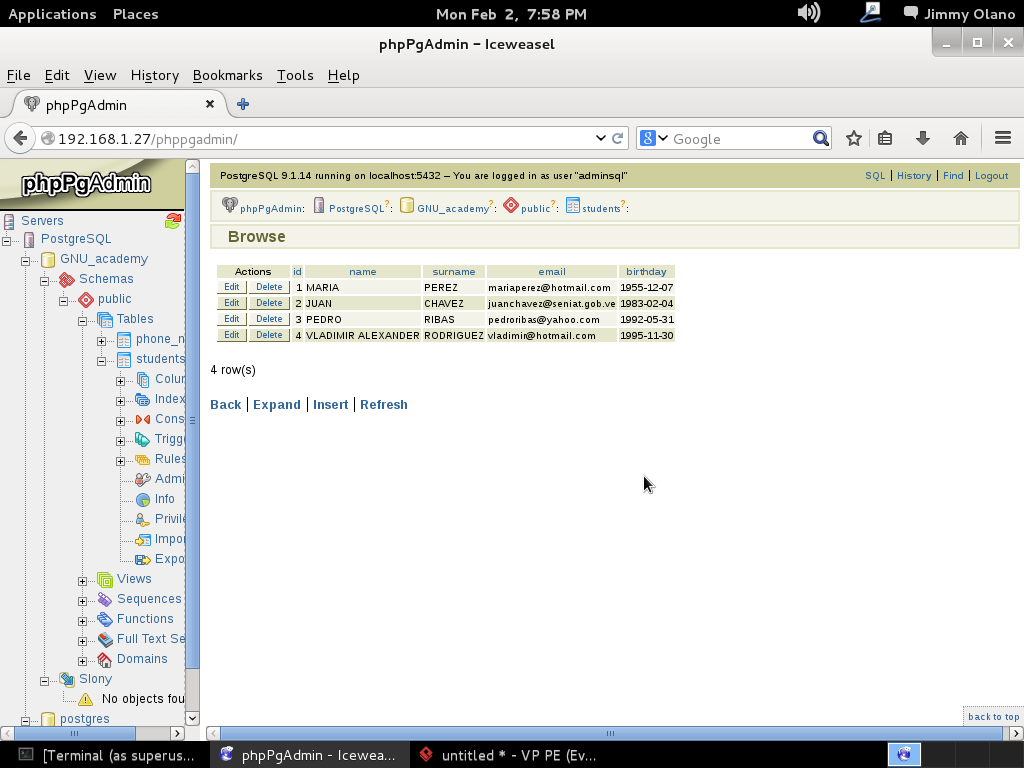
Como en la entrada anterior agregamos algunos datos de los estudiantes tenemos dicha tabla de ejemplos de la siguiente manera:
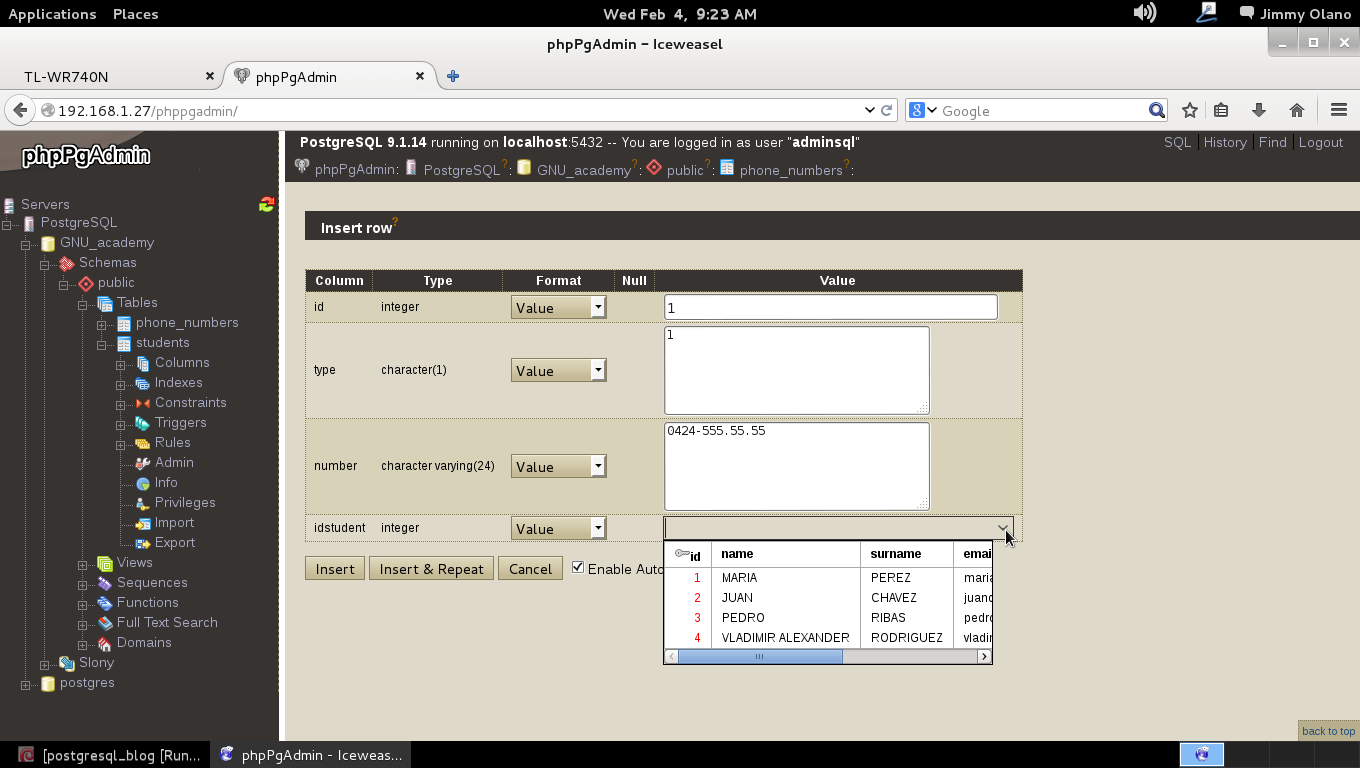
De nuevo hacemos click en la tabla phone_numbers e insertamos un registro tal como lo hicimos en la entrada anterior, sólo que en este caso y cuando lleguemos al campo idstudent automáticamente aparecerá una lista de los estudiantes que ya tenemos registrados, en este caso identificados del 1 al 4:
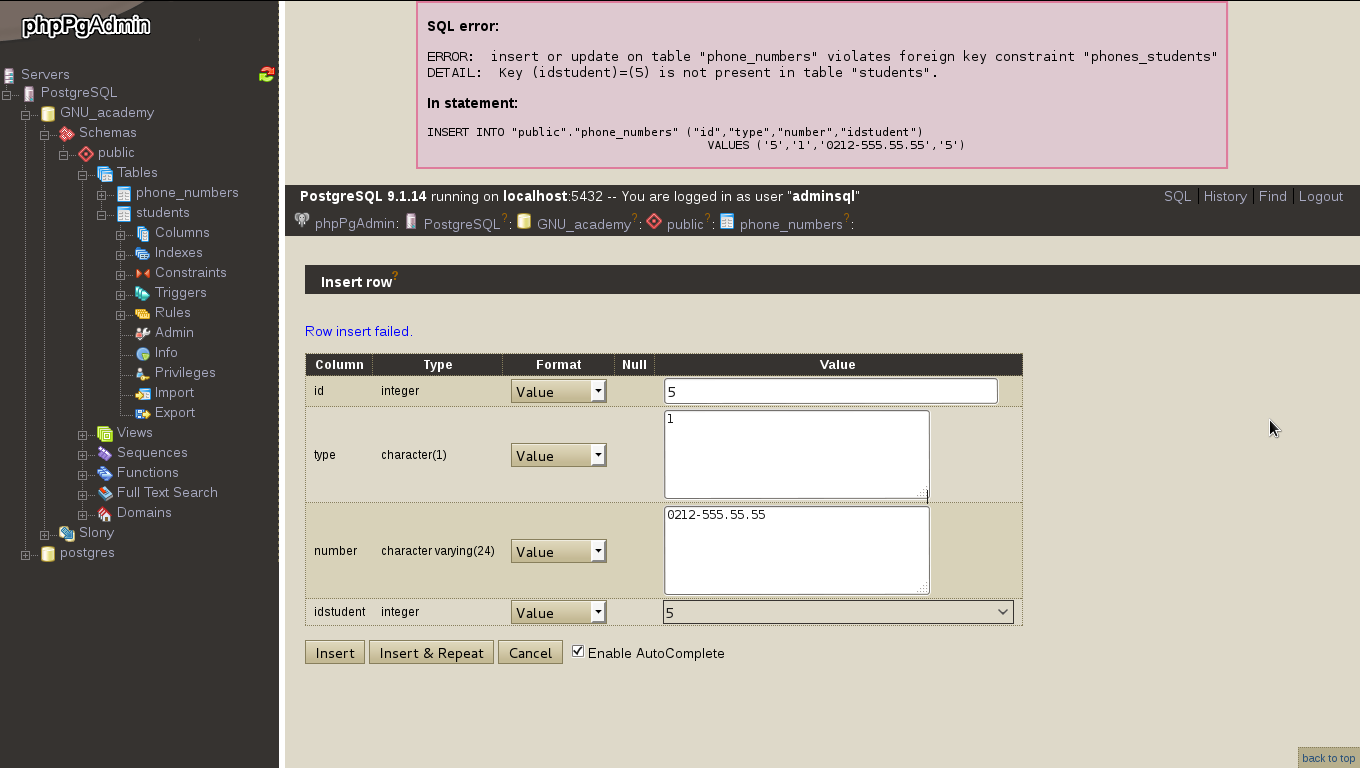
Para probar si la base de datos funciona correctamente en su integridad referencial colocaremos el idstudent = 5 (que aún no está registrado) y le damos click a «insert»:
¡Oh, sorpresa! nos devuelve un mensaje de error y no es para menos ¿para qué querríamos guardar un número de teléfono si no sabemos quién es su propietario? (a menos que trabajeís como detective, hay «caso de casos»).
Desistimos pues en nuestro intento de «embasurar» nuestra base de datos y procedemos a colocarles a los tres números telefónicos que insertemos un idstudent cualquiera entre 1 y 4 y al poco rato tenemos una bonita matrícula lista para clases (aunque falta agregar cursos, aulas, profesores, horarios… «Roma no se construyó en un solo día» reza el refrán, vamos poco a poco).
Una vez hecho esto ya estamos listos para hacer unas consultas entre ambas tablas y con propósitos didácticos ejecutamos la primera consulta (y de manera similar a nuestra entrada anterior):
SELECT students.name, phone_numbers.number
FROM students, phone_numbers
WHERE students.id = phone_numbers.idstudent;
La consulta está en escrita en tres líneas pero la base de datos «sabe» que la misma termina cuando alcanza el punto y coma «;» y dicha manera de escribirla nos proporciona legibilidad para desglosarla y explicarla, línea por línea:
La primera línea ordena que seleccione «SELECT» los campos «name» de la tabla «students» (de allí el punto como unión) e igual con «number» que pertenece a la tabla «phone_numbers». Esta sintaxis permite que, por ejemplo, dos campos con el mismo nombre en diferentes tablas sean identificados sin ambigüedad alguna.
La segunda línea «FROM» instruye de cuáles tablas sacarán los datos.
La tercera línea «WHERE» está el condicional: para cada estudiante que devuelva el o los números telefónico(s) registrado(s) relacionados entre sí por el identificador numérico.
Como sólo insertamos tres números telefónicos pues sólo tres estudiantes con teléfonos será lo que veremos (en este caso para cada estudiante un solo número telefónico que sería el caso más común). ¿Pero y si queremos visualizar TODOS los estudiantes, tengan o no número telefónico registrado?
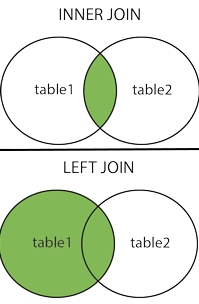
Uniones o «JOIN»:
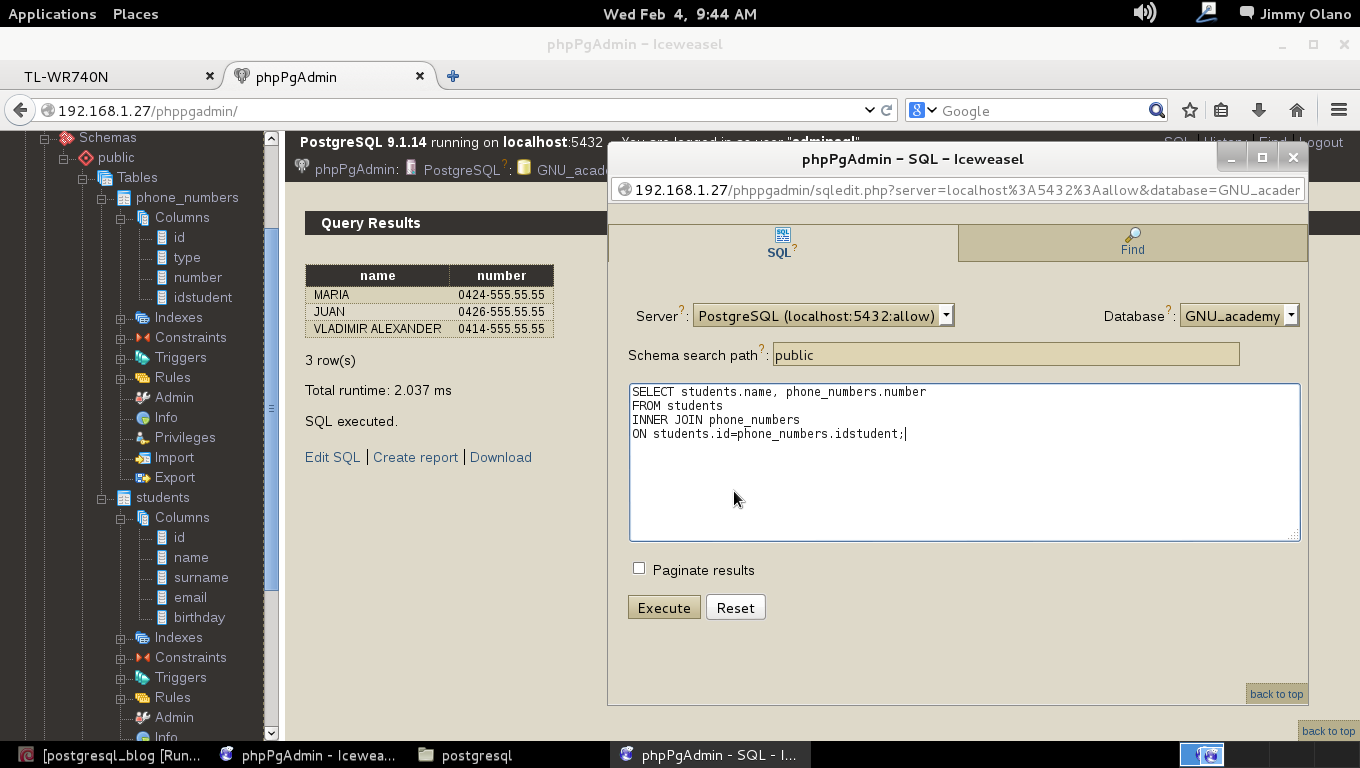
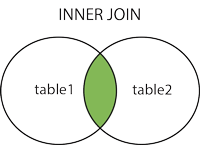
En el lenguaje SQL existe el comando JOIN con sus prefijos INNER, LEFT y RIGHT haciendo la salvedad que «JOIN» = «INNER JOIN» y será el primero que veremos para realizar la misma consulta que hicimos con el condicional WHERE:
SELECT students.name, phone_numbers.number
FROM students
INNER JOIN phone_numbers
ON students.id=phone_numbers.idstudent;
De nuevo desglosamos y analizamos línea por línea (recordad el para qué sirve el punto y coma al final de la consulta):
La primera línea solicitamos los campos que nos interesan de ambas tablas, cada uno con su espacio de nombres para evitar confusiones.
La segunda línea específicamos la tabla «principal» (esto tendrá sentido más adelante) es decir los estudiantes, ya que ellos son los propietarios de cada número de teléfono.
La tercera línea indica hacia cual tabla se hará la unión, osea con cual se combinará.
La última linea establece cómo relacionar los datos, en este caso una sola condición posible de relación entre ambas tablas (pudieran haber otras relaciones posibles pero por ahora no complicaremos las cosas).
INNER JOIN
Hasta aquí todo bien pero volvamos a la pregunta:
¿Pero y si queremos visualizar TODOS los estudiantes -y su(s) número(s) telefónico(s)-, tengan o no número telefónico registrado?
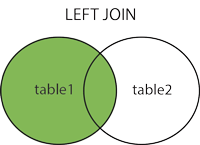
Es aquí que utilizaremos LEFT JOIN en vez de INNER JOIN, simplemente ese cambio, una sola palabra por otra:
SELECT students.name, phone_numbers.number
FROM students
LEFT JOIN phone_numbers
ON students.id=phone_numbers.idstudent;
Y AHORA SÍ que observamos que el estudiante Pedro aparece pero en donde va el número telefónico muestra NULL el cual es una palabra que encierra un concepto que en base de datos trae aún hoy en día candentes discusiones pero que en este caso práctico muestra su utilidad: «NO TIENE NÚMERO TELEFÓNICO REGISTRADO Y NO SABEMOS SI REALMENTE LO TIENE YA QUE SIMPLEMENTE O SE NEGÓ A SUMINISTRARLO O EL INSCRIPTOR OLVIDÓ REGISTRARLO». Todo eso encierra el concepto de NULL.
Actualizado el martes 12 de enero de 2016: me hacen la sugerencia que pudieramos colocar un campo lógico (verdadero o falso) para saber a ciencia cierta si la persona posee algún teléfono. No veo mala esa idea pero recomiendo que le coloquen NULL como valor predeterminado pero que sea obligatorio ese dato -y por ende no permitirá guardar con NULL-. A nivel de la interfaz del usuario, el formulario que introduce datos para agregar personas deberá utilizarse un RADIO BUTTON sin valor preseleccionado en ninguno de los dos. Ejemplo:
LEFT JOIN
Ya cerrando la entrada podemos acotar la consulta JOIN con un simple WHERE tal como ejercitamos en otra entrada:
SELECT students.name, phone_numbers.number
FROM students
LEFT JOIN phone_numbers
ON students.id=phone_numbers.idstudent
WHERE LOWER(students.email) ~ ‘hotmail.com’;
sólo que esta vez veremos sólamente los estudiantes que posean correo electrónico en «hotmail.com» (hoy día «outlook.com») y que tengan al menos un número telefónico registrado.
Aprovecho el breve receso de estas fechas carnestolendas de 2015 para continuar con esta miniserie de artículos sobre PostgreSQL 9.1. Para aquellos que quieran llevar la secuencia correcta del tema éste se inicia acá .
Lo que haremos hoy son unas consultas sencillas en SQL no sin antes haber agregado unos cuantos datos de prueba (cualquier semejanza con personas reales es pura y casual coincidencia).
Utilizando el navegador web predeterminado en Debian, el Iceweasel (que cada día aprecio más por su economía de recursos y por ende rapidez) nos vamos a la consabida dirección IP de nuestro servidor virtual:
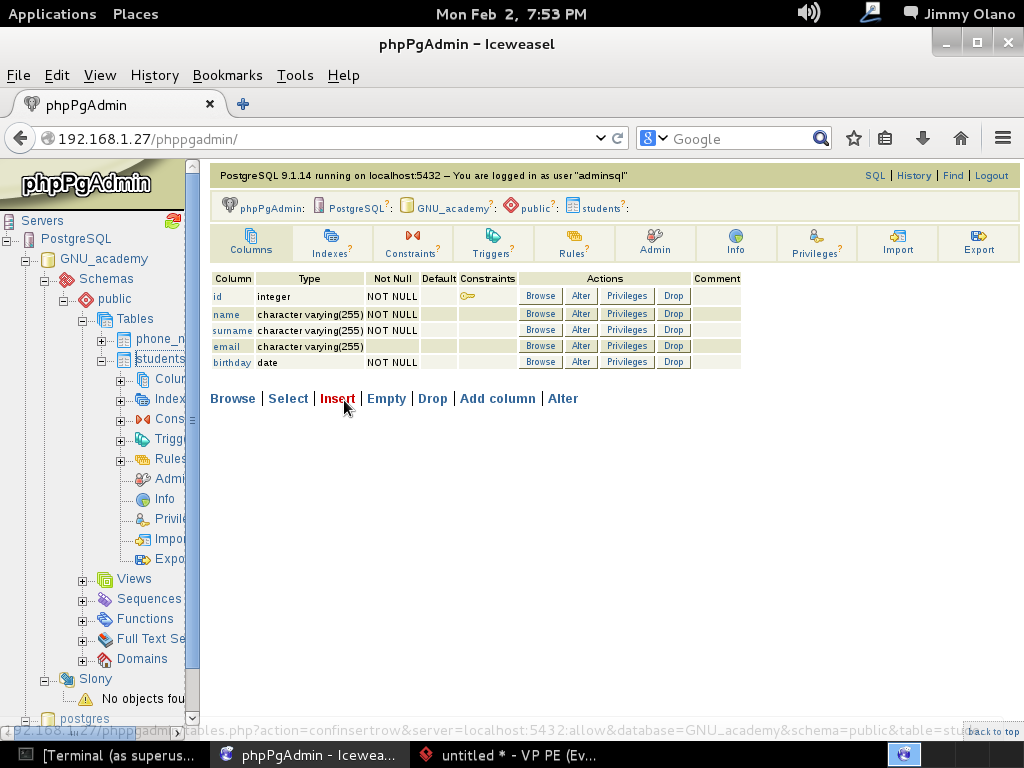
Introducimos el «login» y la contraseña (si no lo recuerdan ir a esta entrada ) y una vez hayamos logrado acceso hacemos click («o vamos») a la tabla students (aunque soy fanático del castellano, debo reconocer que el inglés es hoy en día lo que fue el latín en el mundo entero) y observamos su estructura de datos más sin embargo nos interesa, por ahora, el enlace «insert» para dar algunas altas en la tabla:
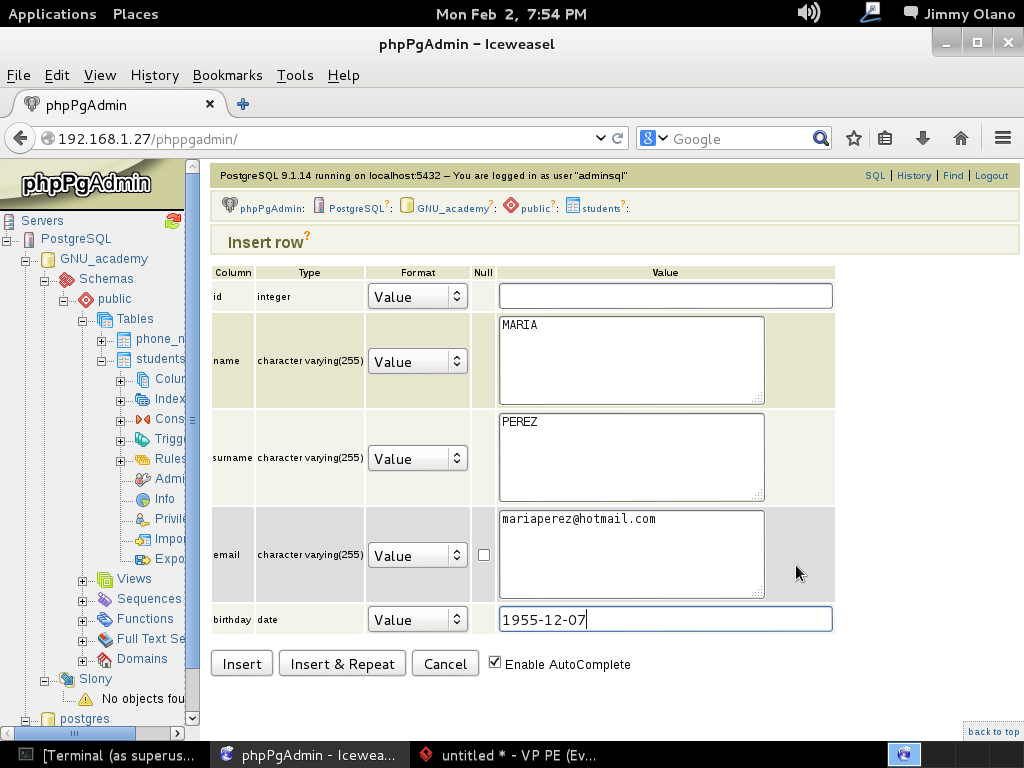
Tras lo cual se nos abre el siguiente cuadro de diálogo el cual procedemos a llenar sin cortapisa:
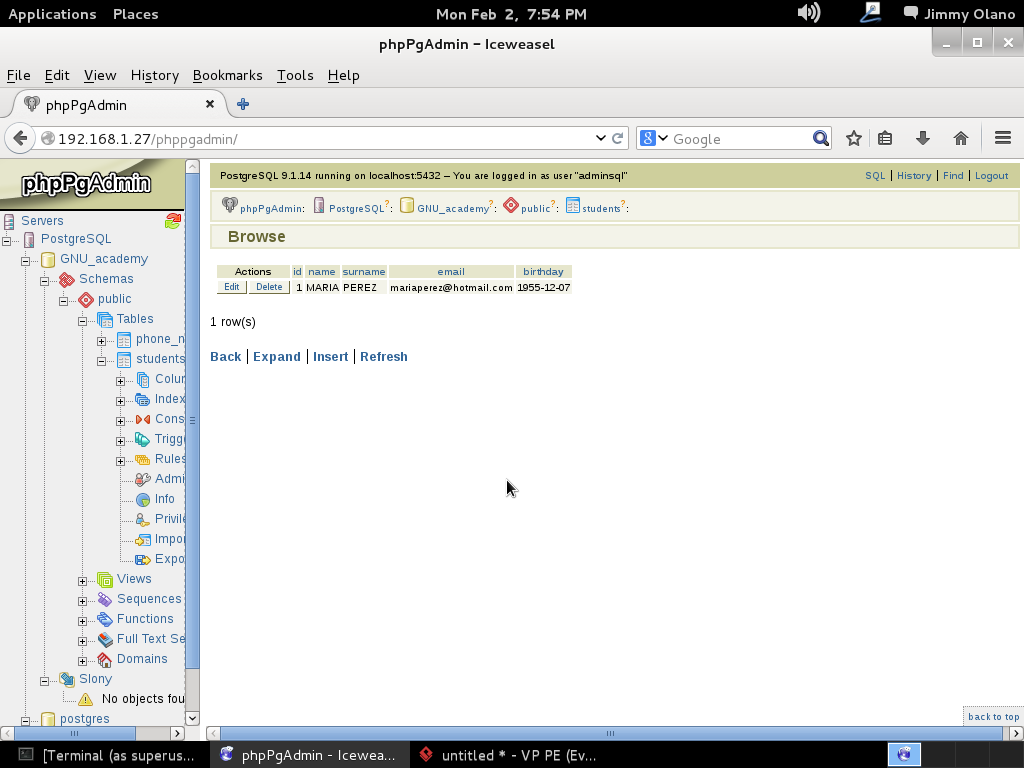
Observen que dejé el campo «id» intencionalmente en blanco: nuestro primer valor será, naturalmente, el 1 pero en los siguientes registros que insertemos intenten guardar ese valor de nuevo y observarán una de las restricciones de la tabla: los valores no pueden repetirse para ese campo en particular. A la final verán algo parecido a esto, ya con los registros insertados:
Vuelvo a repetir: cualquier parecido con los datos personales en la realidad es simple y feliz coincidencia. Ahora que tenemos unos cuantos registros insertados podemos hacer unas consultas sencillas, para ello bastará con hacer click en el enlace «SQL» que está en el borde superior derecho de la web, cerquita de
«SQL | History |Find | Logout»
¿lo vieron? en el cuadro de diálogo que se abre escribimos la siguiente sentencia para visualizar los correos electrónicos de los estudiantes:
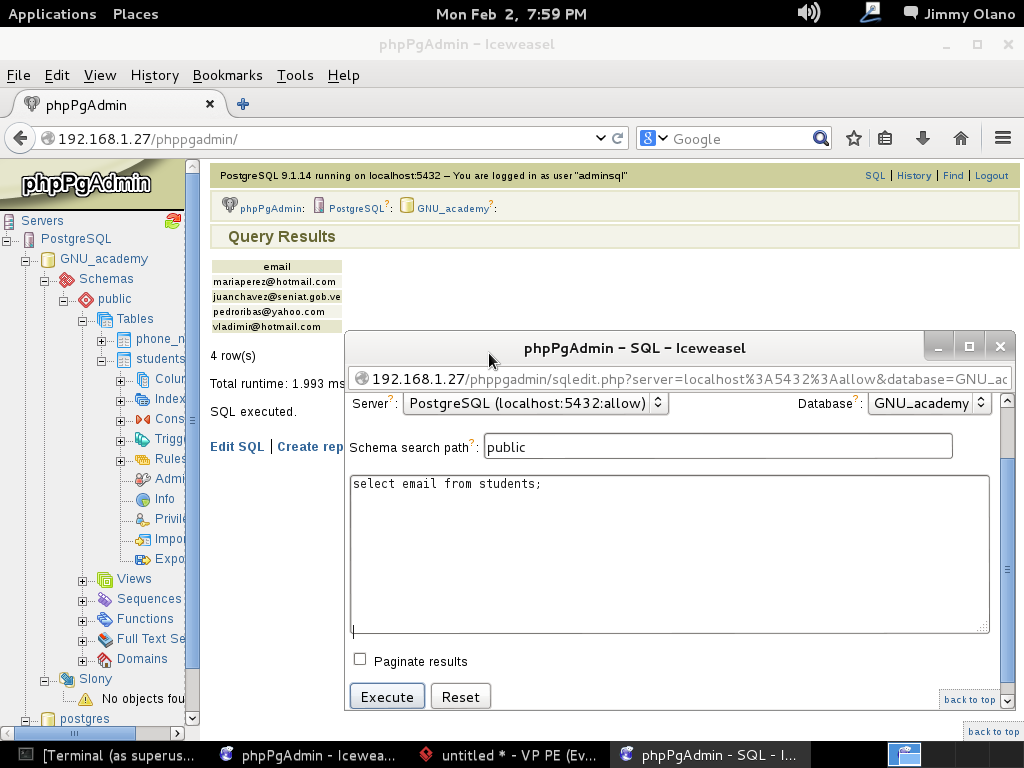
select email from students;
Antes que hagan click en «execute» («ejecutar -sentencia-«) observen atentamente que estamos trabajando con la base de datos «GNU_academy» y que nuestro vía de búsqueda de esquema está apuntada a «public» (ésto último permite que al ejecutar una sentencia SQL los nombres de tablas y campos sean buscados y verificados primero antes de comenzar a buscar datos, e incluso es útil para asuntos de seguridad y privilegios pero ese tema es más avanzado; si luego quieren aprender más sobre ello aquí el enlace introductorio al asunto ).
Así pues, sin más, ejecutamos la sentencia tras lo cual veremos algo parecido a esto:
La explicación breve de la sentencia SQL es traducirla del inglés:
«select»->»selecciona»
«from»->»desde (la tabla)»
«;»-> indica fin de la sentencia, no es obligatorio pero es útil si vamos a introducir varias sentencias que deben ir en un orden específico (por ejemplo insertar más datos de estudiantes y luego mostrarlos en un listado para asistencia -ya le vamos dando utilidad en la vida real a esto de las bases de datos-).
Como hay comandos específicos del lenguaje SQL yo opto (y hay varias personas que lo hacen) por escribir dichos comandos en mayúsculas y los nombres de tablas (y/o variables y/o constantes) en minúsculas y como pueden ver se ejecutan sin ningún problema, el asunto es de legibilidad para nosotros los humanos:
SELECT email FROM students;
Importante: los nombres de campos y tablas han escribirse tal cual fueron creados en la base de datos correspondiente, de no ser así nos devuelve error; es por ello que desde un principio en estos tutoriales los creamos todos en minúsculas -y en inglés, de paso-.
Volviendo al tema de la realidad, supongamos que por cualquier razón necesitamos saber cúales (y cuántos) estudiantes utilizan correo hotmail pues simplemente introducimos la siguiente sentencia SQL
SELECT email FROM students WHERE email ~ ‘hotmail.com’;
Observen el nuevo comando
«WHERE»->»donde (satisfazga la condición)»
y el uso de la virgulilla como comparador lógico indicando que dicha condición tenga la cadena de texto ‘hotmail.com’. Otros detalles a considerar es el uso de las comillas simples y el uso de mayúsculas: si usamos comillas dobles se interpreta como nombre de columna y si usamos mayúsculas NO devuelve los correos electrónicos ya que «hoTMail.com» NO ES IGUAL A «hotmail.com»:
«hoTMail.com» <> «hotmail.com»
Sobre nomenclatura del correo electrónico:
Esto nos plantea desde ya nuevos retos: si vamos a desarrollar una aplicación seria es deber que los usuarios ingresen direcciones de correo válidos (sintaxis usuario@dominio ):
El nombre del usuario NO debe llevar espacios a menos que estén precedidos por una barra inversa y entrecomillado.
El dominio NUNCA debe llevar espacios (ni arrobas, claro está).
No pueden haber espacios antes o después de una dirección válida.
No pueden llevar dobles puntos «..», así estén entrecomillados.
El nombre del usuario no pueden contener dobles arrobas a menos que estén debidamente entrecomillados.
Y son sólo algunas de las reglas que aplican a la sintaxis de una dirección de correo electrónico, para mayor información (en inglés, ¡cuando no!) en RFC 822 y dirección de correo electrónico . La buena noticia es que PosgreSQL admite varios lenguajes de programación que junto con triggers o «disparadores» nos permitirán capturar y revisar los correos electrónicos antes de agregarlos a la base de datos (serán tratados a futuro en una entrada aparte). Y aunque nos hemos salido un poco de las consultas sencillas era necesario ir abonando el terreno hacia temas más avanzados (oh idioma castellano, qué poético eres, nunca cambies 😉 ).
Os ruego hagan la prueba escribiendo las sentencias en sus múltiples variantes, como ayuda os dejo el comando LIKE cuyo uso tiene una sintaxis más elaborada:
SELECT email FROM students WHERE email LIKE ‘%hotmail.com%’;
Produciendo el mismo resultado que con la virgulilla; vale destacar que al colocar el símbolo de porcentaje como comodín le estamos ordenando que nos busque cualquier dirección de correo electrónico registrado en nuestra tabla students que contenga la cadena de caracteres «hotmail.com» (obsérvese que si algún bromista registrara la dirección de correo electrónico «hotmail.com@gmail.com» sería devuelta también en la consulta, os animo a probarla -aunque dudo que alguien en verdad tenga ésa dirección-) pero eso aún no resuelve nuestro problema de mayúsculas y minúsculas.
Una solución sería utilizar una función integrada por defecto en nuestra base de datos, es decir, una serie de programas ya registrados y de propósito general; dicha función para este caso es LOWER() aplicado al campo email (ojo que si es así lo que entrecomillamos como condición debe ir todo en minúsculas):
SELECT email FROM students WHERE LOWER(email) LIKE ‘%hotmail.com%’;
o también podemos usar, como al principio, la virgulilla que nos ahorra el uso de comodines:
SELECT email FROM students WHERE LOWER(email) ~ ‘hotmail.com’;
Si quereís ver el resto de funciones de cadena, haced click aquí.
Por último, si quiséramos el caso contrario, listar los estudiantes que no tienen correo «hotmail» registrado:
SELECT email FROM students WHERE LOWER(email) !~ ‘hotmail.com’;
y lo único que hicimos fue agregarle el operador lógico «!» que indica negación «NOT», el cual si que lo podemos usar con LIKE:
SELECT email FROM students WHERE LOWER(email) NOT LIKE ‘%hotmail.com%’;
Y entonces nos desconectamos de la base de datos como es debido:
Son 3 hojitas en formato pdf (agradezco a «pdfsam» y lo recomiendo para dividir y combinar documentos en ese formato); con este aumento el sueldo mínimo en Venezuela se ubica en Bs. 5.622,48 (si tomamos como referencia el SICAD II serían aproximadamente US$ 114 mensuales).
Para descargar dicho ejemplar electrónico de la Gaceta Oficial desde nuestra página web haga click aquí.
Si desea descargarla desde el Tribunal Supremo de Justicia deberá luego introducir el número «40597» en el cuadro de búsqueda rápida.
En la entrada anterior explicamos cómo instalar y configurar el phpPgAdmin y creamos nuestra primera base de datos (basados en el usuario «adminsql» de la primera entrada de esta mini serie de artículos), y esta entrada estará dedicada a la poderosa herramienta Visual Paradigm (que puede descargar para GNU/Linux en este enlace ) con la cual podremos crear tablas y sus relaciones de una manera gráfica y hasta amena (si se quiere) en comparación a los comandos por cónsola. Para mí es una novedad esta herramienta, y creo que es representativa del nivel de calidad de software que contamos hoy en día no obstante dedicaremos una entrada a las órdenes por cónsola, por aquello de la nostalgia. 😉
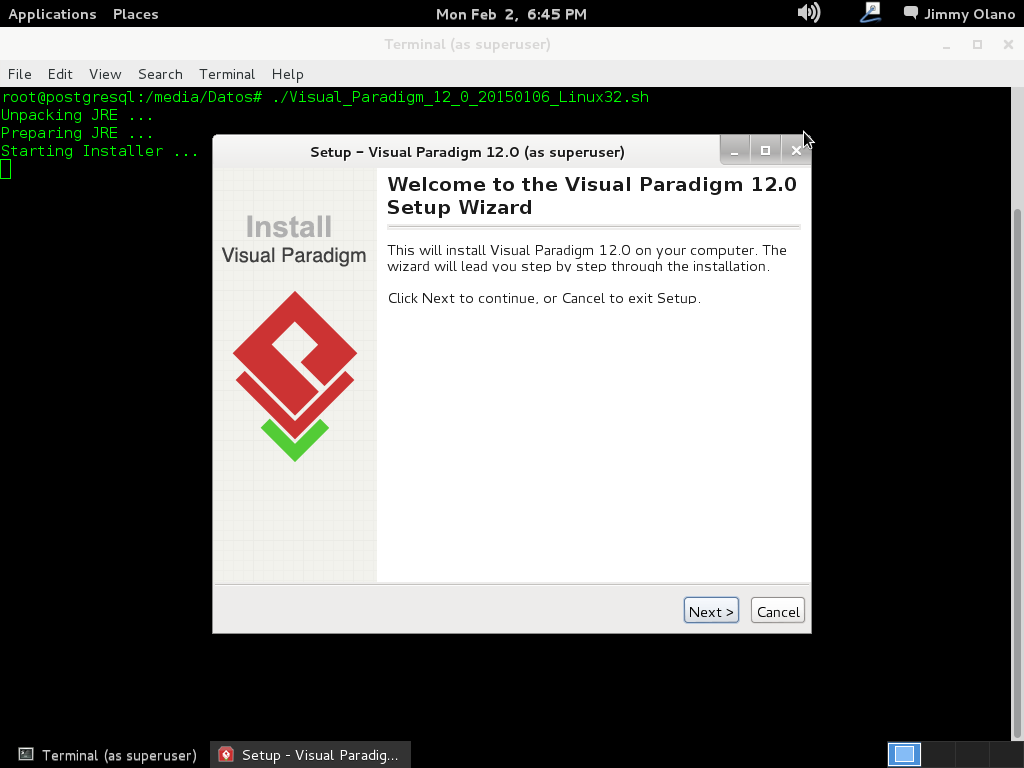
Pues bien, empecemos: de primero ya descargamos el archivo llamado Visual_Paradigm_12_0_20150106_Linux32.sh que no es más que un archivo de procesamiento por lotes (o shell script en idioma inglés) en este caso MUY GRANDE que ocupa 253,3 megabytes y al cual hay que dedicarle al menos mil megabytes de espacio en disco para ser instalado. Es grande.
Abrimos una terminal con derechos de usuario root y nos vamos a la carpeta de descargas de nuestro navegador web (o a la carpeta donde realmente los guardamos) y ejecutamos:
./Visual_Paradigm_12_0_20150106_Linux32.sh
Hacemos click en «next» y veremos lo siguiente:
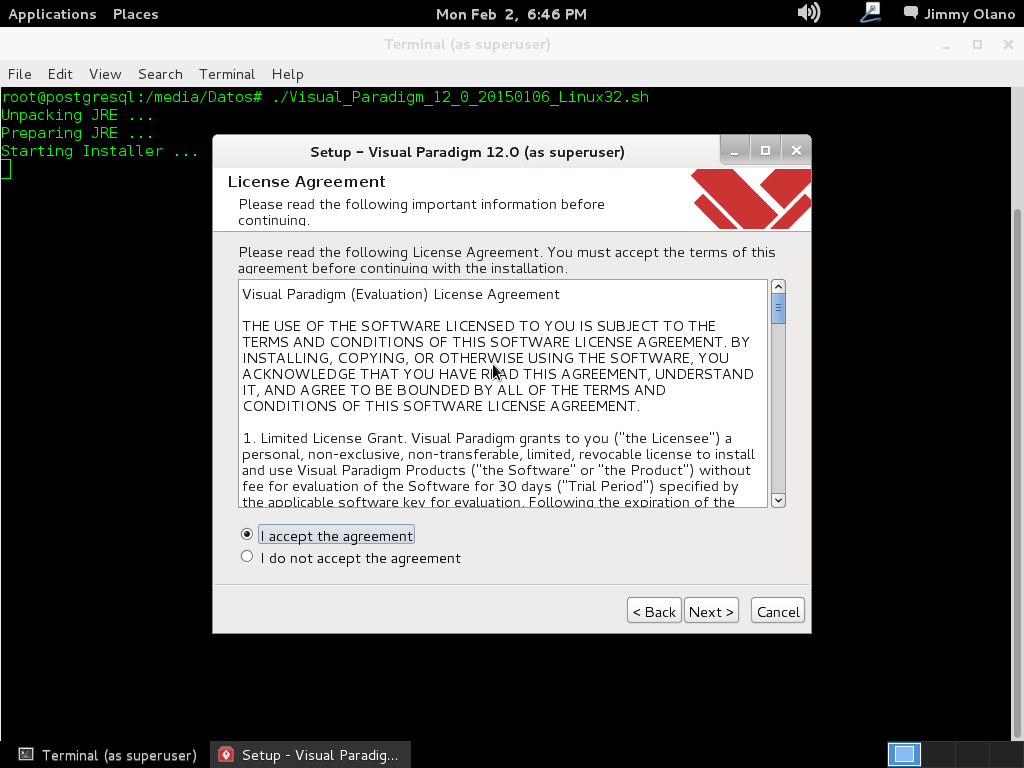
Pueden leer completo (en inglés) la el acuerdo de licencia completo haciendo click aquí. Seleccionamos «I accept the agreement» y hacemos click en «next»:
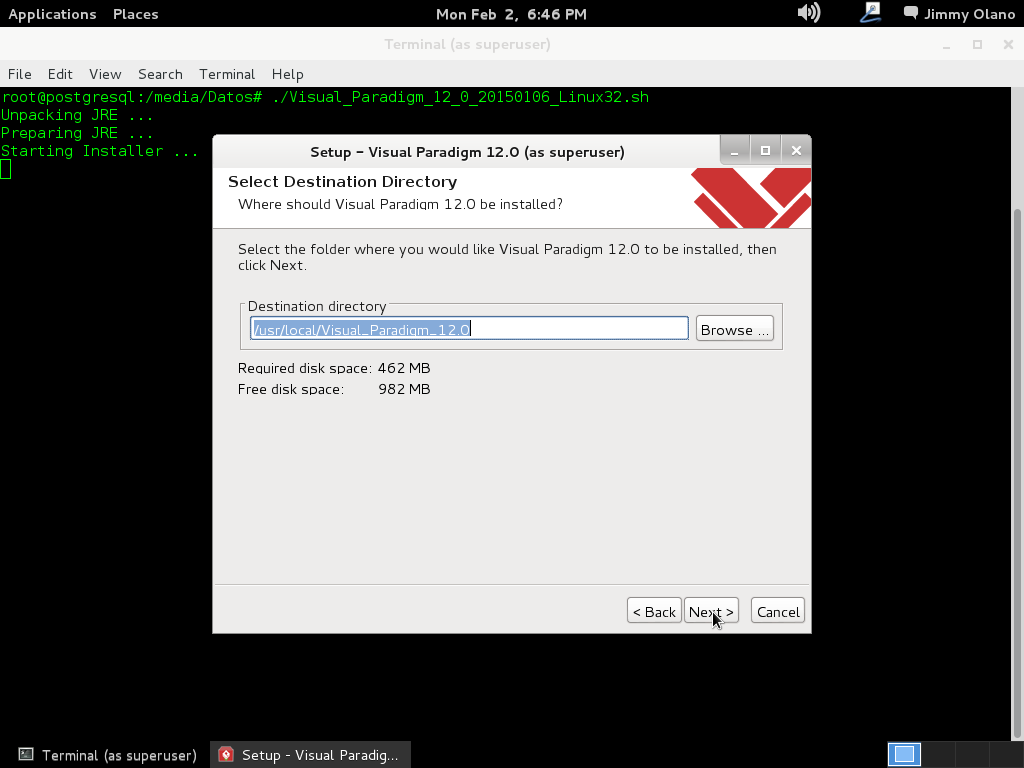
En nuestro caso dejamos el directorio por defecto (si hacen click en «browse» pueden seleccionar otra ubicación) y hacemos click en «next»:
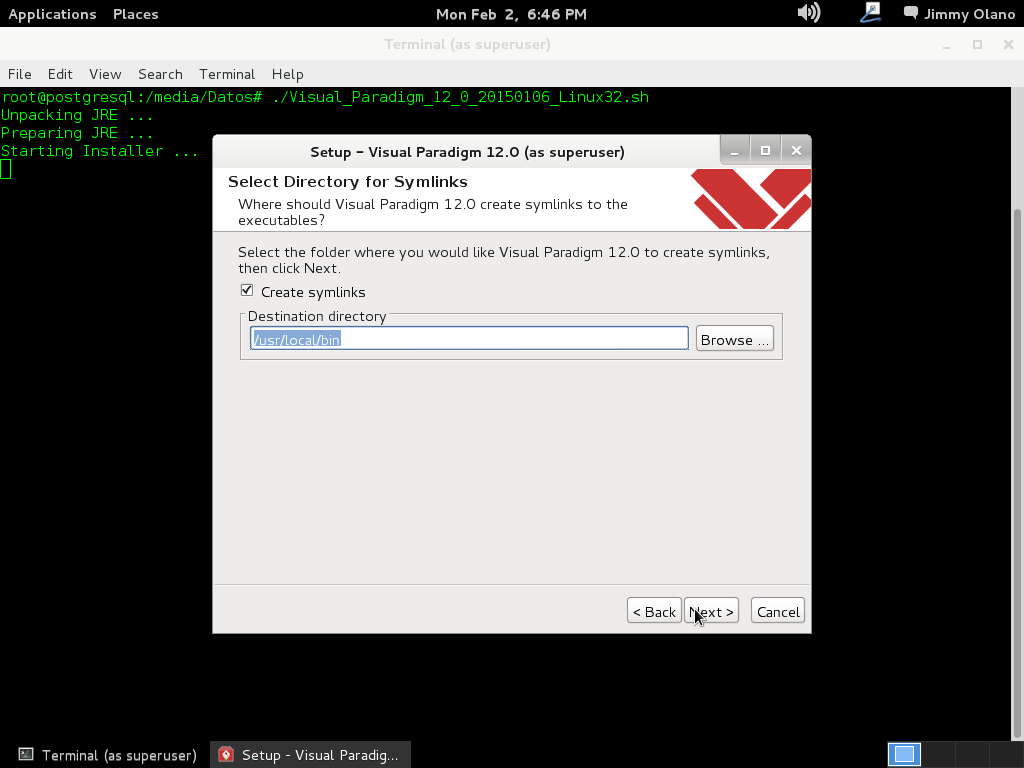
Dejamos los «symlinks» o «symbolic link» (o «enlace simbólico«) en su directorio por defecto (dichos enlaces simbólicos son archivos que apunta hacia la ubicación real de los archivos y ayudan, por ejemplo, dar nombres cortos a los programas que nos ahorran trabajo cuando escribimos por cónsola). Hacemos click en «next» y comienza realmente la instalación en sí:
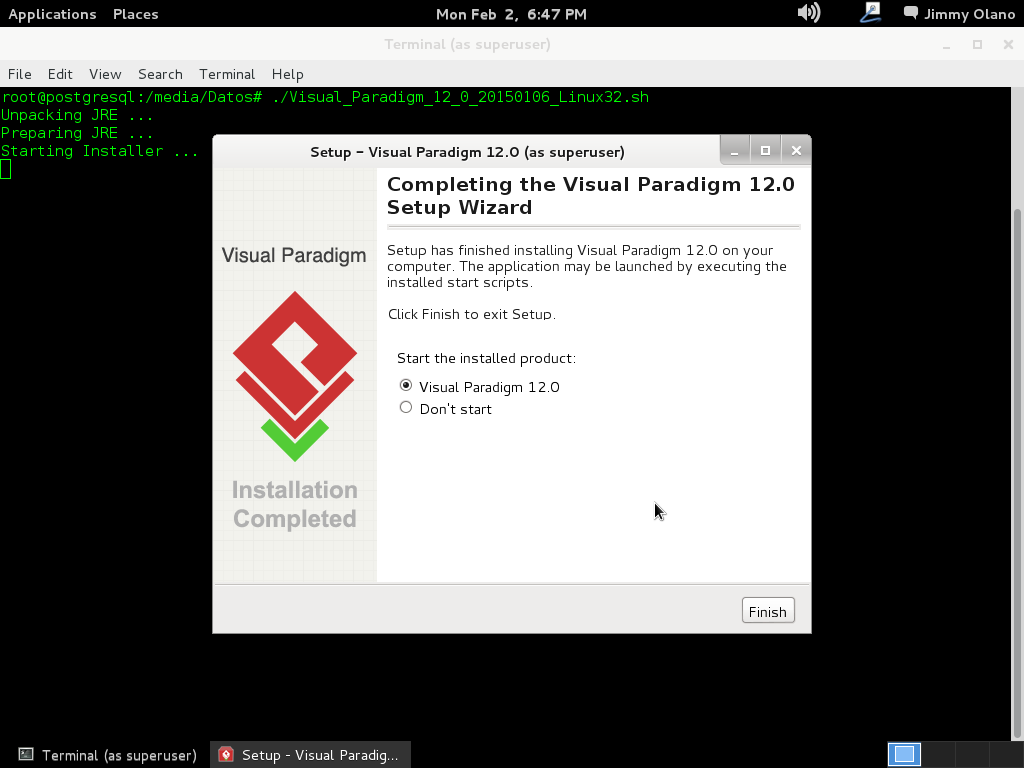
Como queda seleccionada por defecto la opción de ejecutar (o «correr») el programa hacemos click en «next» para seleccionar la opción de uso, en nuestro caso seleccionamos los 30 días de prueba:
Hasta acá queda instalado la herramienta de software, ahora a trabajar en la creación de las tablas y sus relaciones.
Creación de tablas y relaciones.
Nos proponemos crear dos tablas sencillas, una para contener los datos básicos de los estudiantes y otra con los números de teléfonos (teniendo en cuenta que cada persona puede tener un celular o móvil, el teléfono de casa, el de oficina u otro(s) números) relacionados por una «foreign key» que apunta a una «primary key» y en su debida oportunidad veremos las ventajas (y desventajas) de dicha forma de trabajar, todo bajo la «Normalización de base de datos«; por ahora basta con saber que ésos son los conceptos que nos basaremos para modelar.
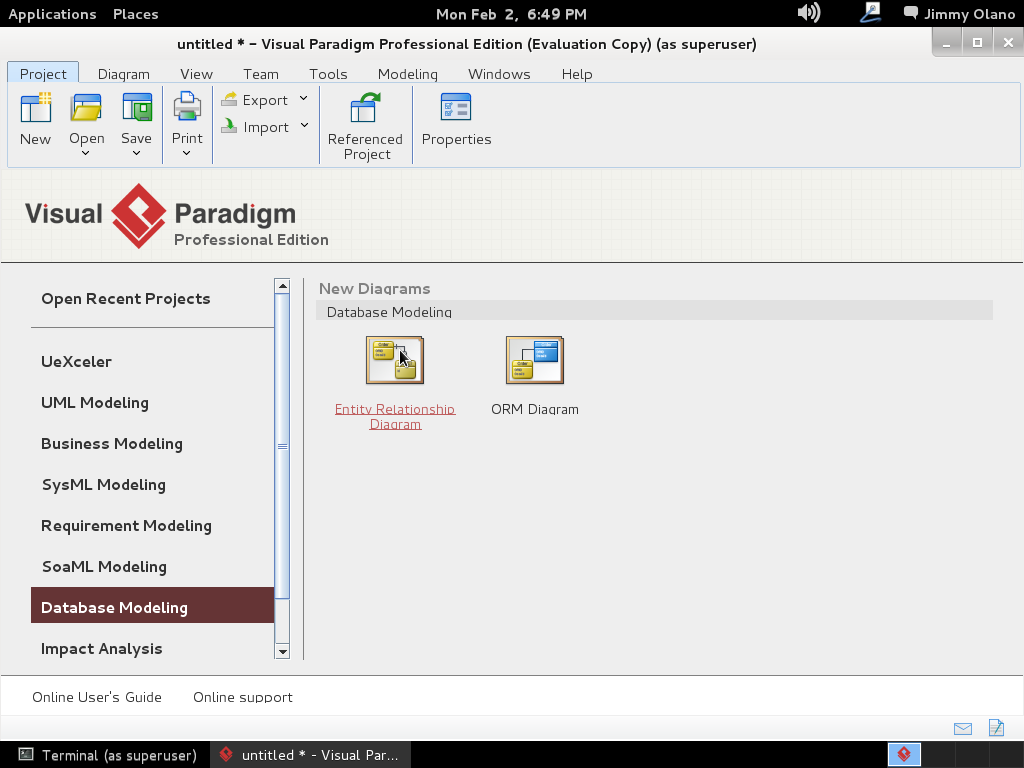
Una vez que arranca el programa seleccionamos «Database modeling»:
y luego hacemos click en «Entity Relationship Diagram» y le asignamos el nombre «pupils» al nuevo proyecto:
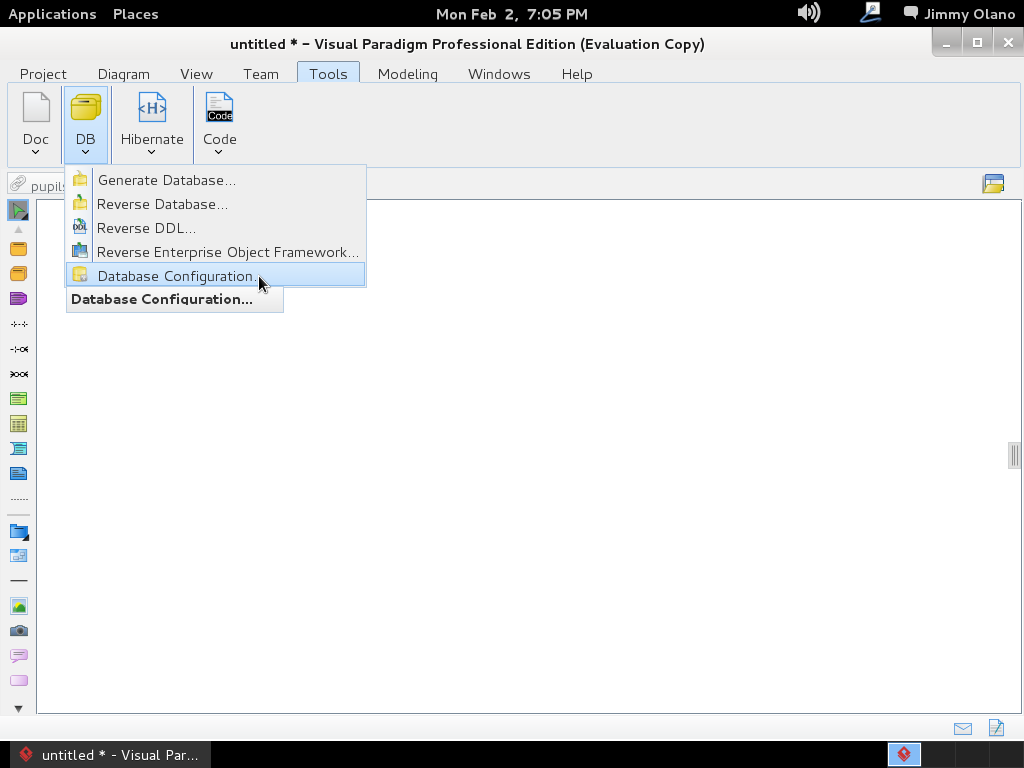
y procedemos primero que nada a configurar con cuál motor de base de datos vamos a trabajar, PostgreSQL para lo cual nos vamos a la pestaña «tools» y luego «Database Configuration«:
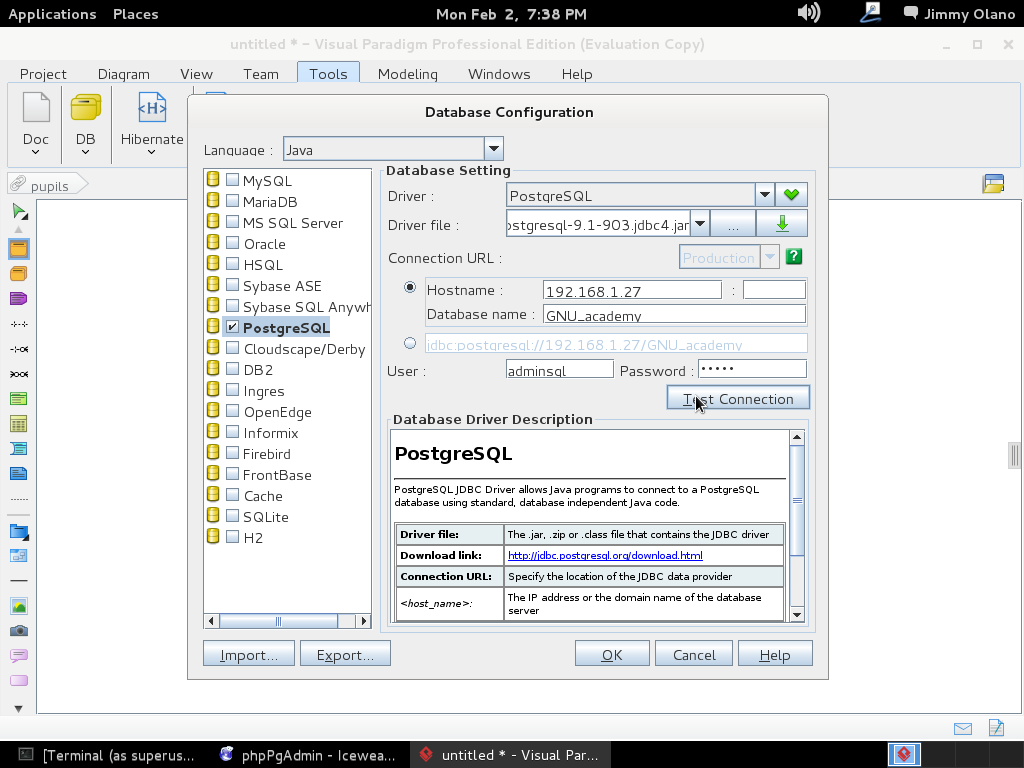
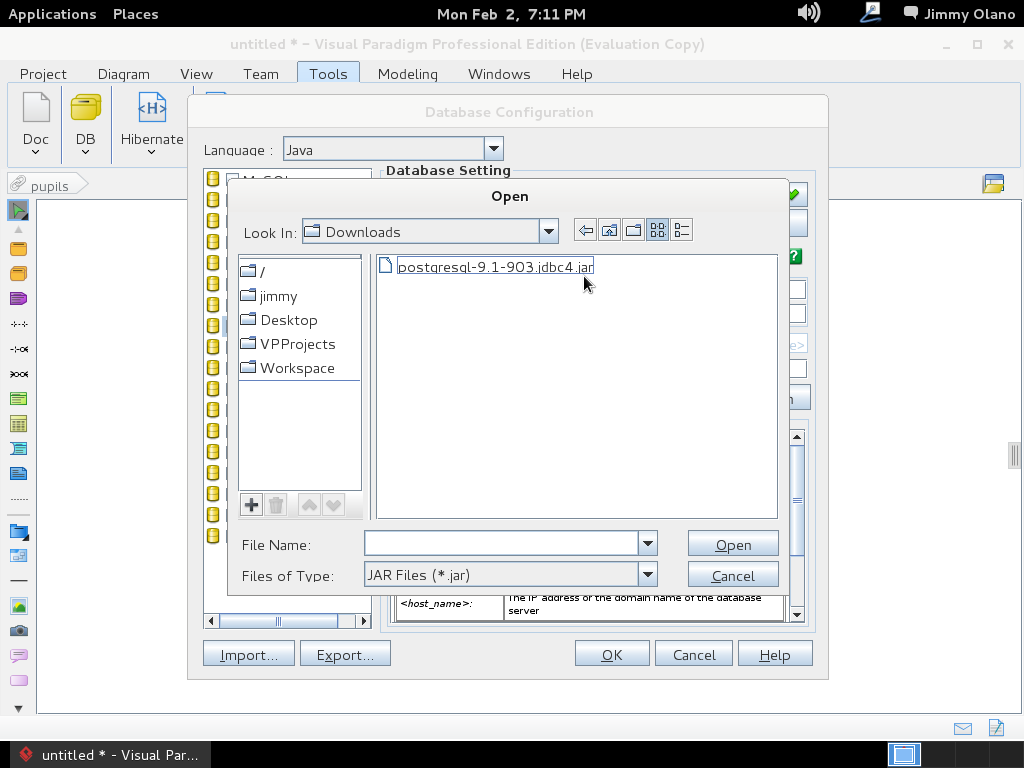
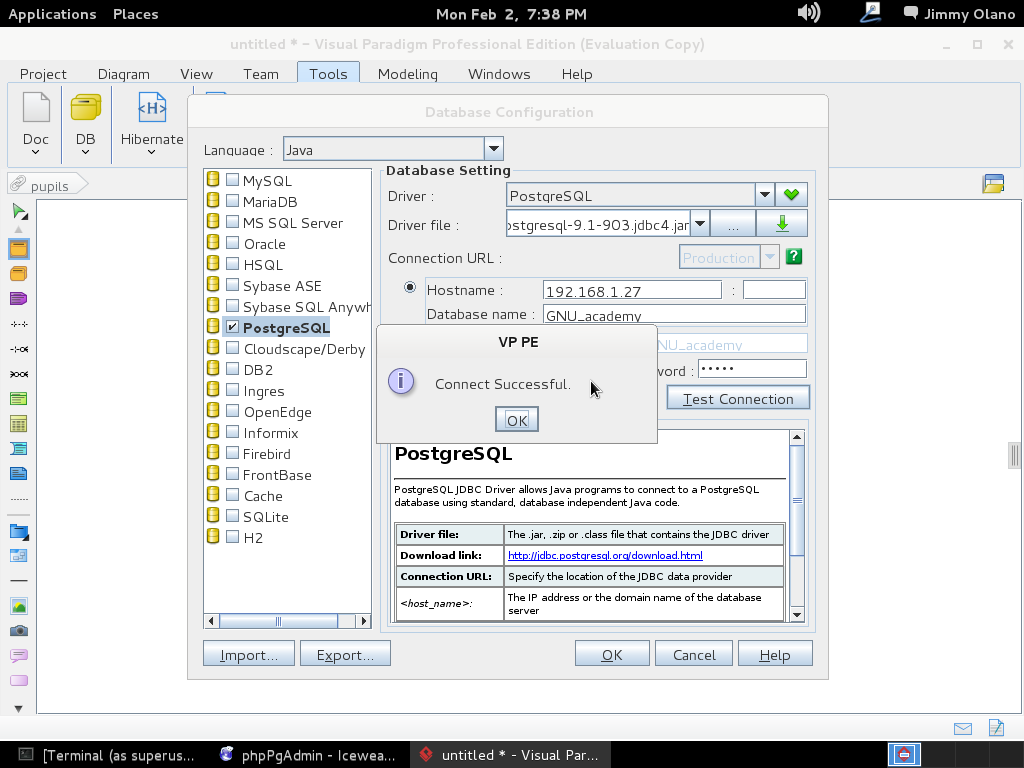
Hacemos click y se abre un cuadro de diálogo para que seleccionemos «PostgreSQL» no sin antes indicar dónde tenemos el «driver file» o «archivo controlador» que servirá para que Visual Paradigm pueda «hablar» con nuestro servidor recién instalado. Si nos fijamos bien en el mismo cuadro de diálogo nos indica de dónde podemos descargarlo:
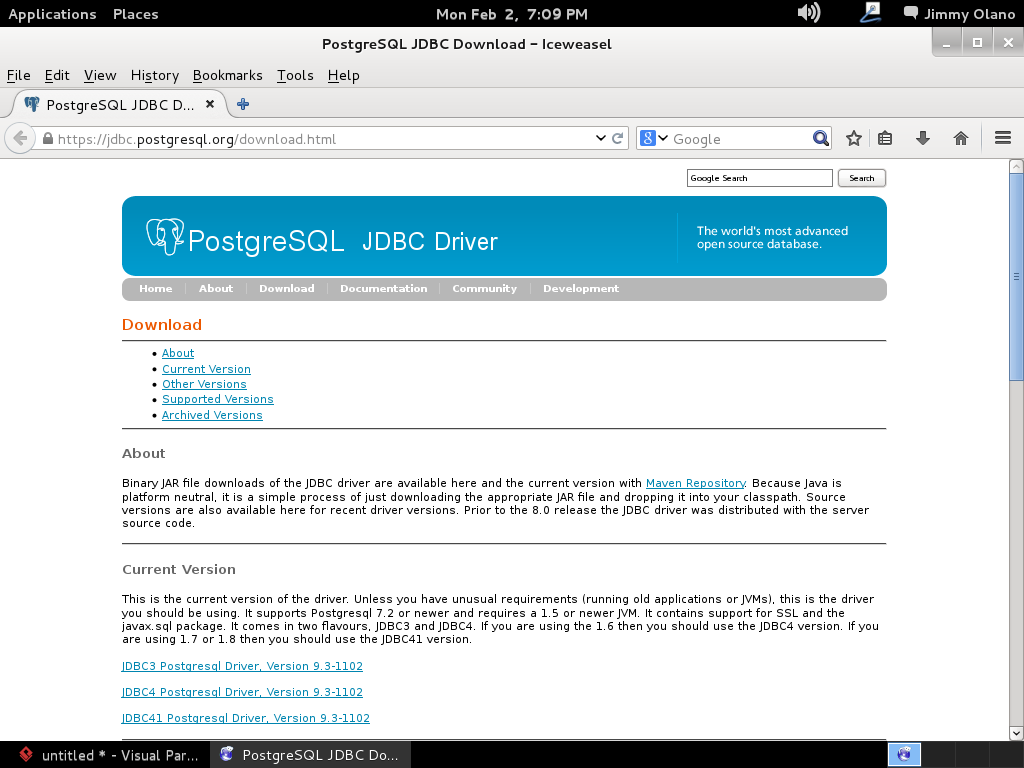
si hacemos click en «Download link» y tenemos paciencia se abre nuestro navegador web predeterminado con la siguiente página:
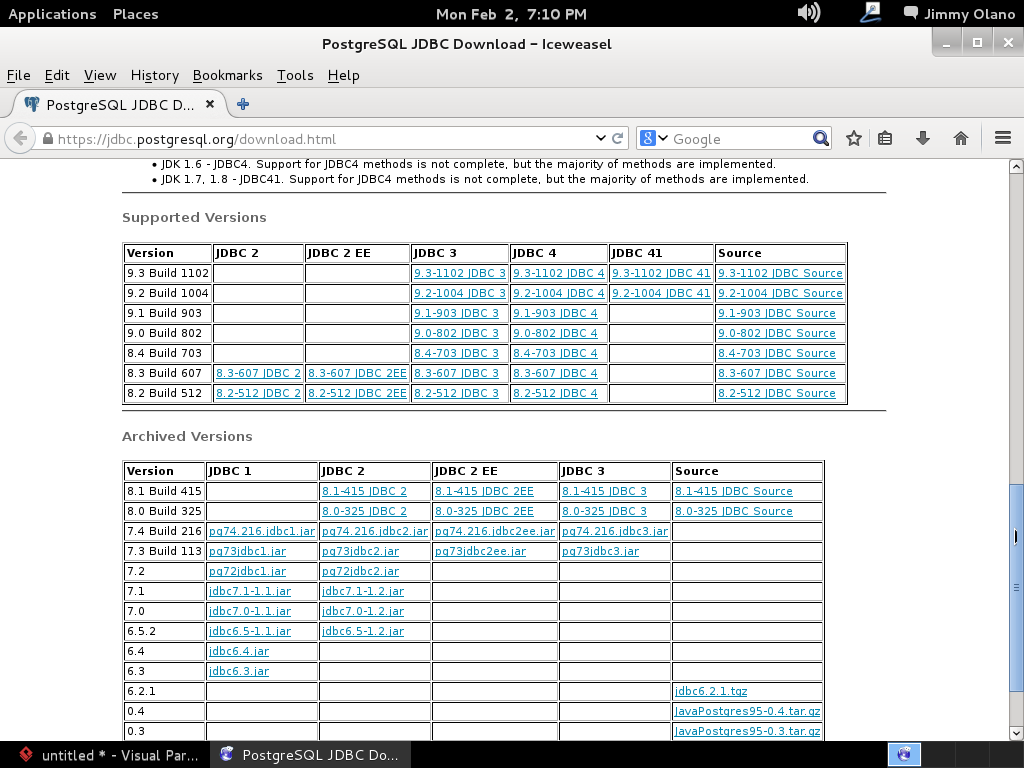
procedemos a descargar el identificado como «postgresql-9.1-903.jdbc4.jar» (observen que para cada versión de PostgreSQL hay su correspondiente controlador, sean cuidadosos al elegir por favor):
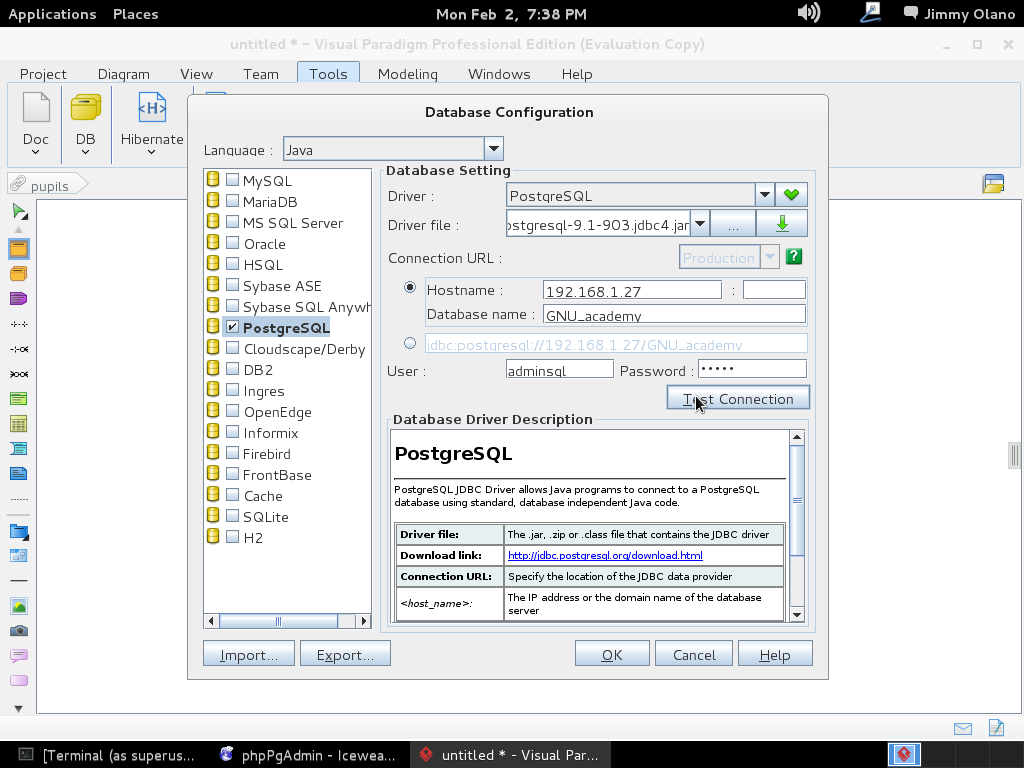
Este último cuadro de diálogo para elegir el controlador aparece al hacer click en el botón que muestra 3 puntitos en la misma línea de «Driver file». Al clickear en «Open» procedemos a llenar el resto de los valores que configuramos en las dos entradas anteriores, que en un papelito debemos haber anotado y puesto al alcance de la mano para ganar tiempo:
Luego hacemos click en «Test Connection» y si hemos realizado bien nuestro trabajo veremos algo como esto:
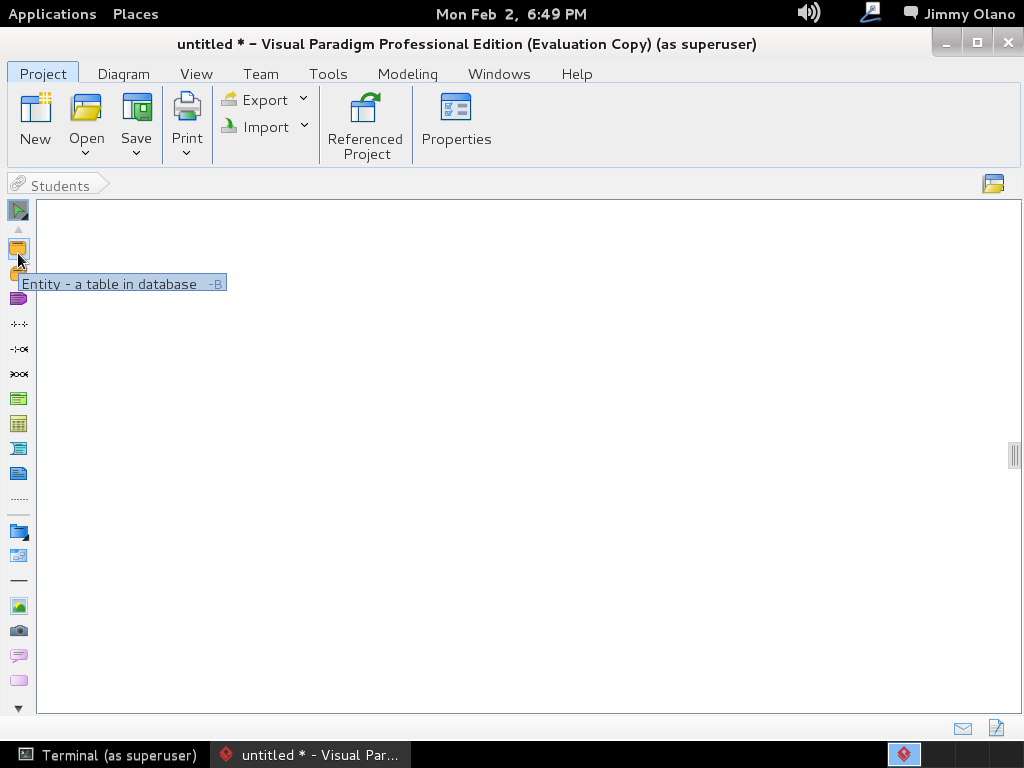
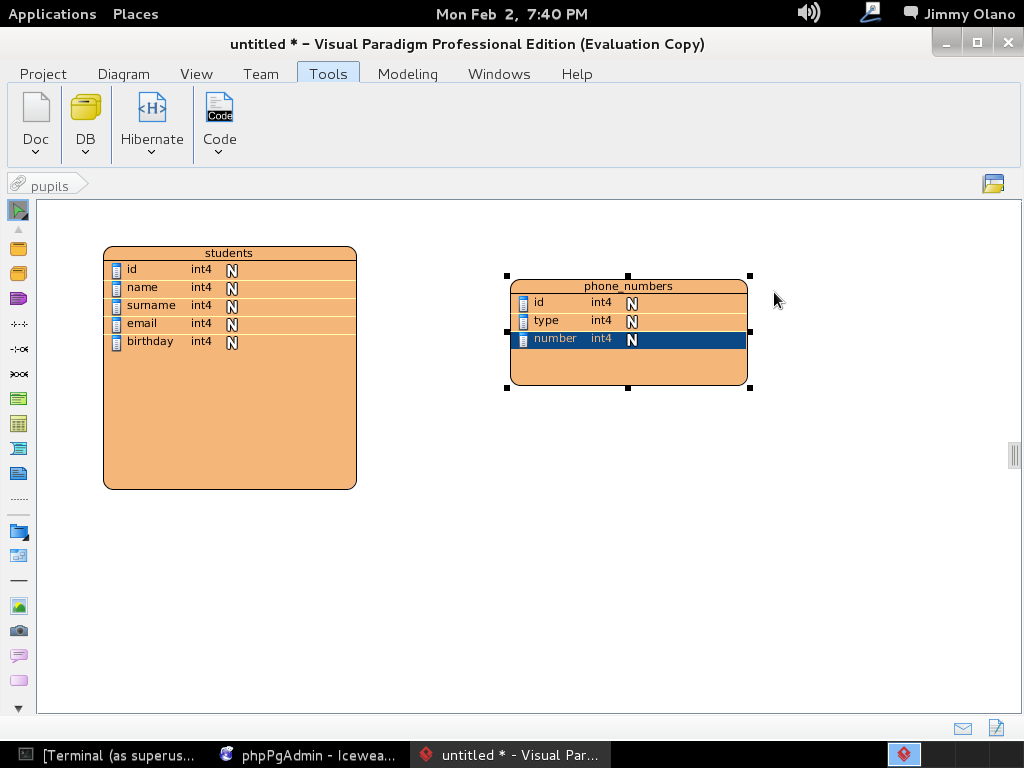
Le damos click a «OK» para entonces agregar la primera futura tabla al hacer click en «Entity -a table-» en el icono que se ve en la siguiente imagen (me disculpan el errorcito de nombre de proyecto, si se fijan) y acto seguido «dibujamos» un rectángulo con tamaño a nuestra apetencia en el área de trabajo:
Lo que viene a continuacón es largo de describir en palabras, pero como decimos en farmacia «hágase según arte» y siendo así manipulamos dicho objeto colocandole los nombres siguientes (no se preocupen, más adelante especificaremos los tipos de datos):
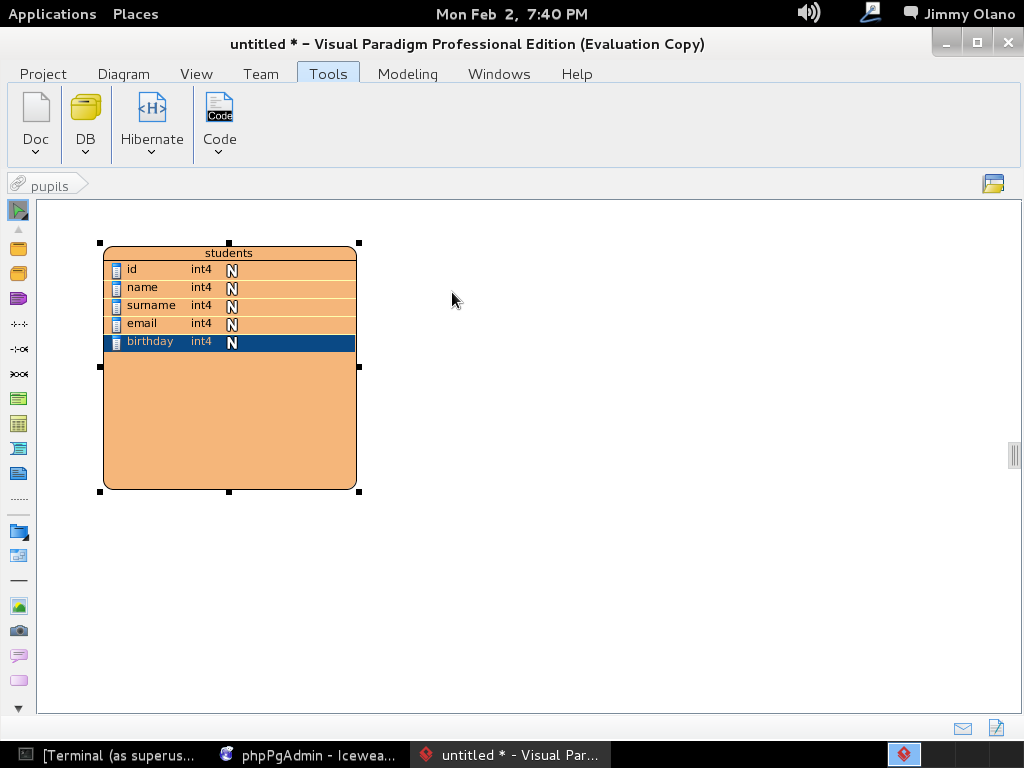
Tal como lo hicimos, de buenas a primera, los tipos de datos son «integer» de allí la letra «N» gorda rellena de blanco en cada renglón. Repetimos el procedimiento pero esta vez debe quedar de esta manera:
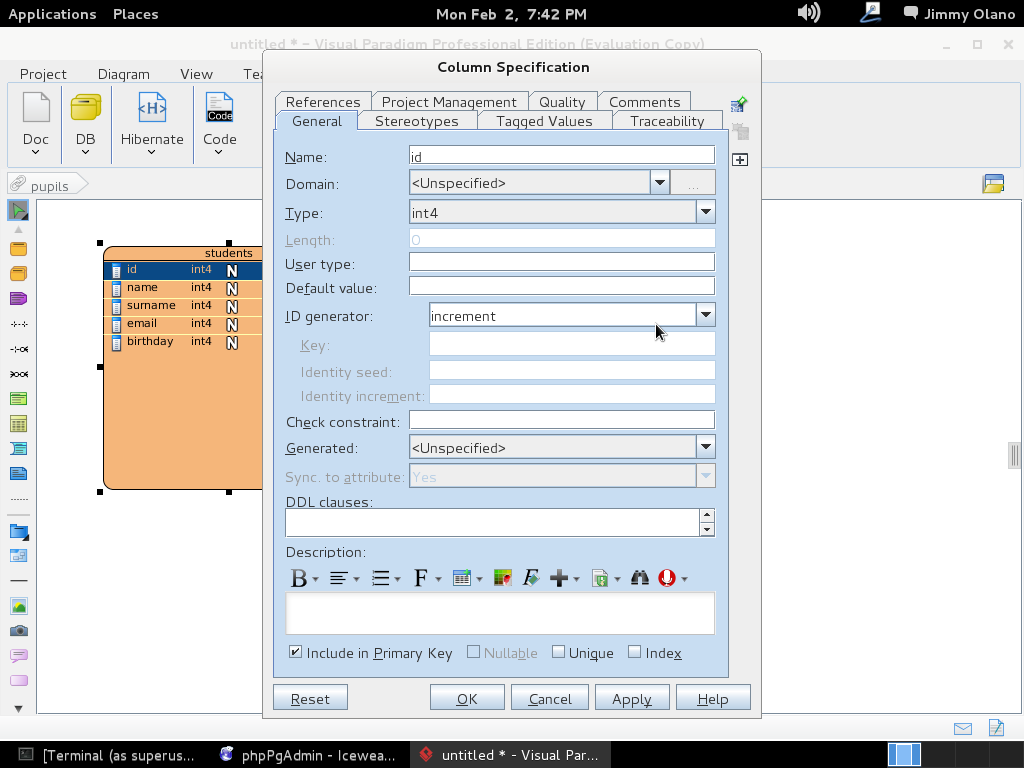
Ahora si hacemos «click derecho» – click con el botón secundario del ratón- para que en el cuadro de diálogo de cada linea (campo de la tabla) nos permita modificarlo; EJEMPLO seleccionamos el «id» de «students» y lo marcamos como «Primary Key» y un «Id Generator-> Increment»:
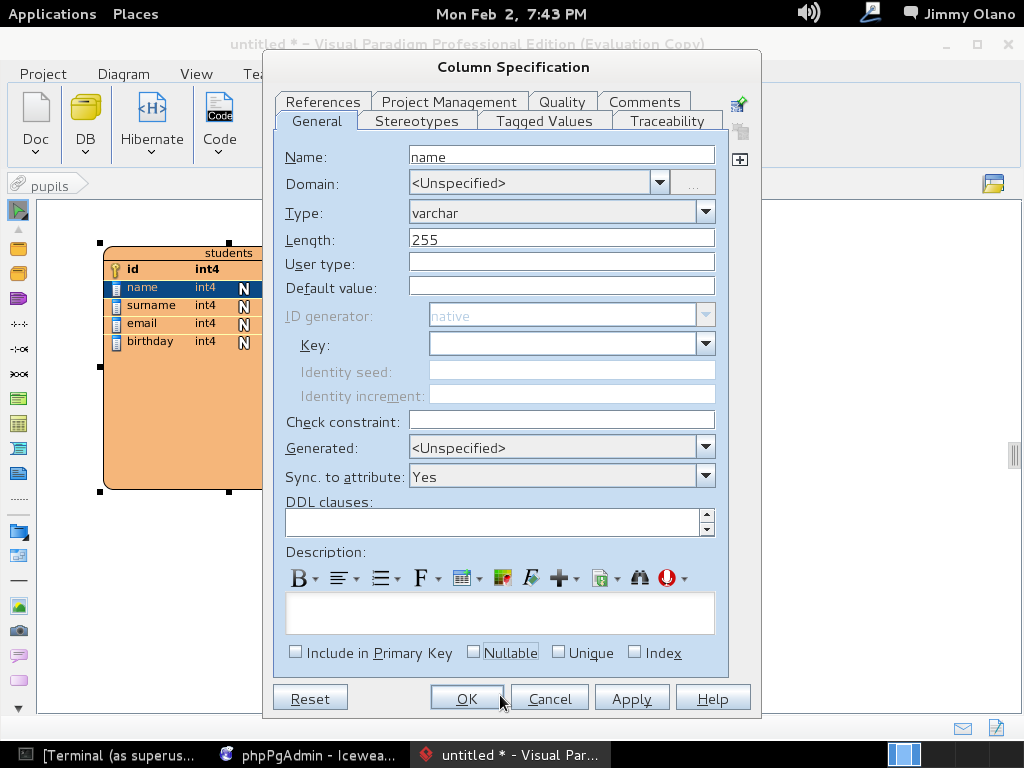
Hacemos click en «Ok» y repetimos el procedimiento para el campo «name» PERO lo colocamos para que sea tipo «varchar» (cadena de texto) y acepte hasta 255 letras -toda una exageración- pero vuelvo a repetir «con propósitos didácticos»:
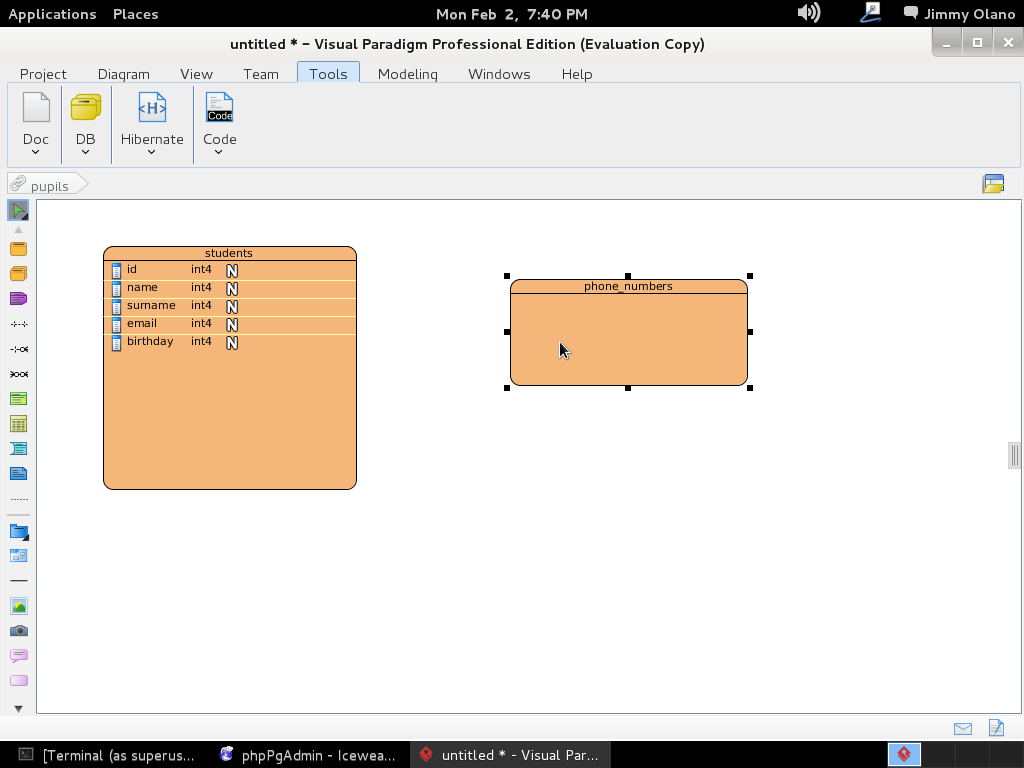
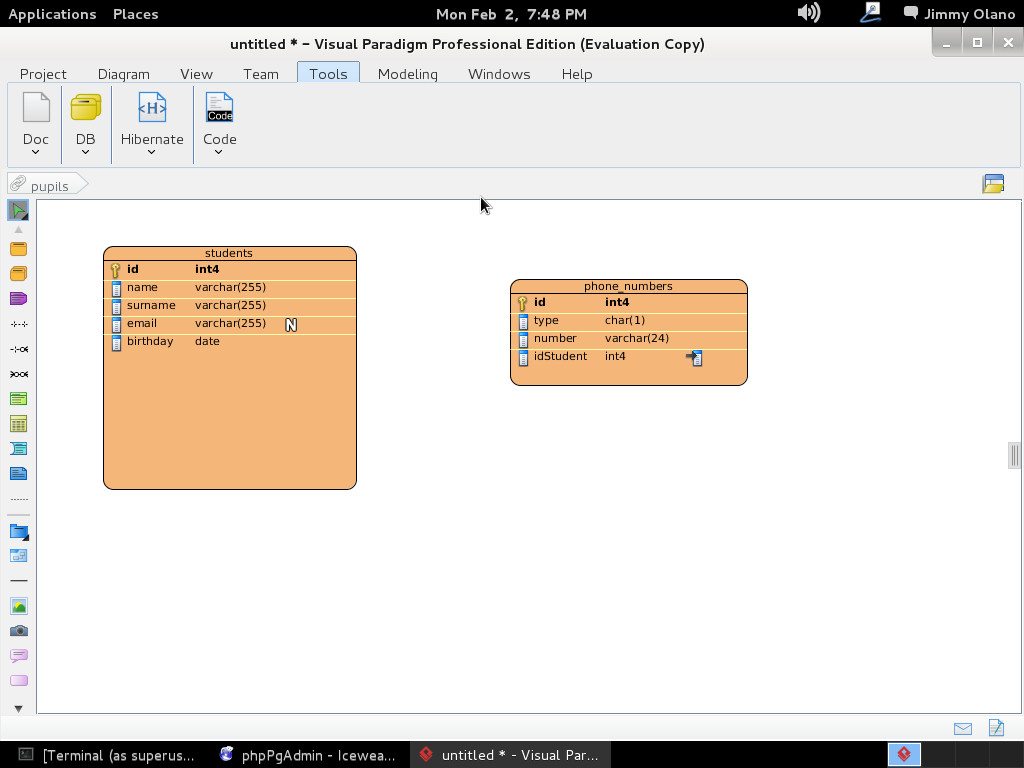
A la final (TÓMENSE SU TIEMPO) las dos tablas han de quedar de la siguiente manera:
Luego procedemos a simplemente hacer click sobre la tabla «students» y al mover el puntero del ratón hacia el borde superior aprecerá rápidamente unos iconos con descripción rápida de uso para cada uno de ellos:
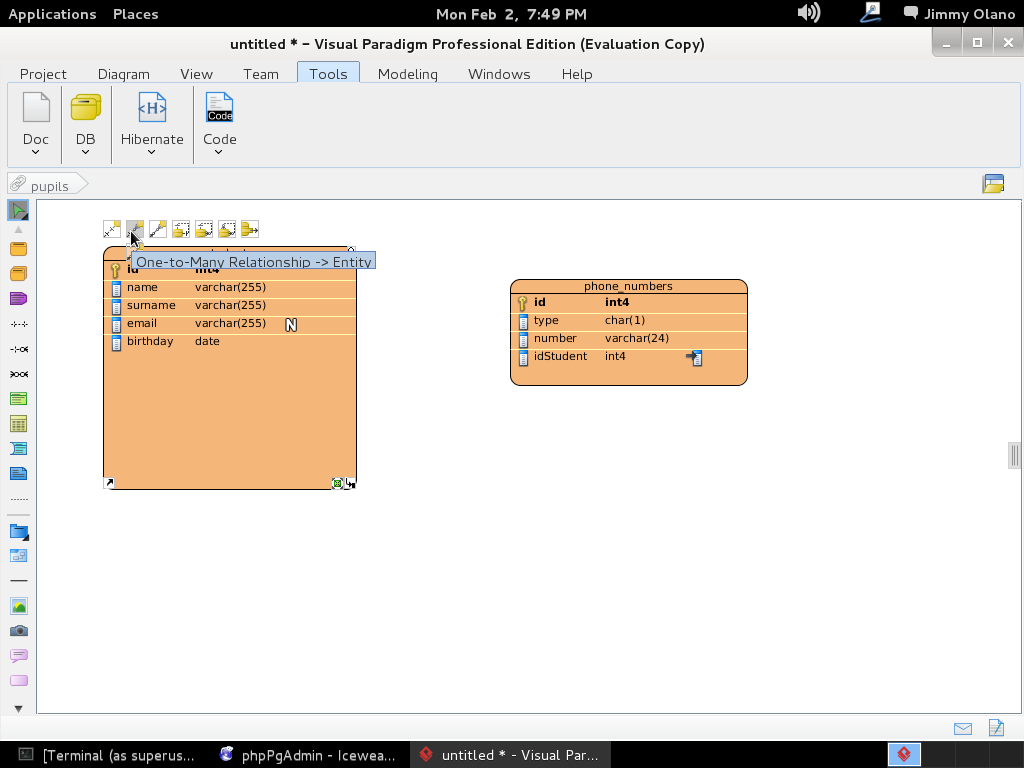
Escogemos «One-to-Many Relationship» (un estudiante puede tener varios números de telefonos distintos -o ninguno-) y arrastramos la línea hasta la tabla «phone_numbers» como aprecian en figura:
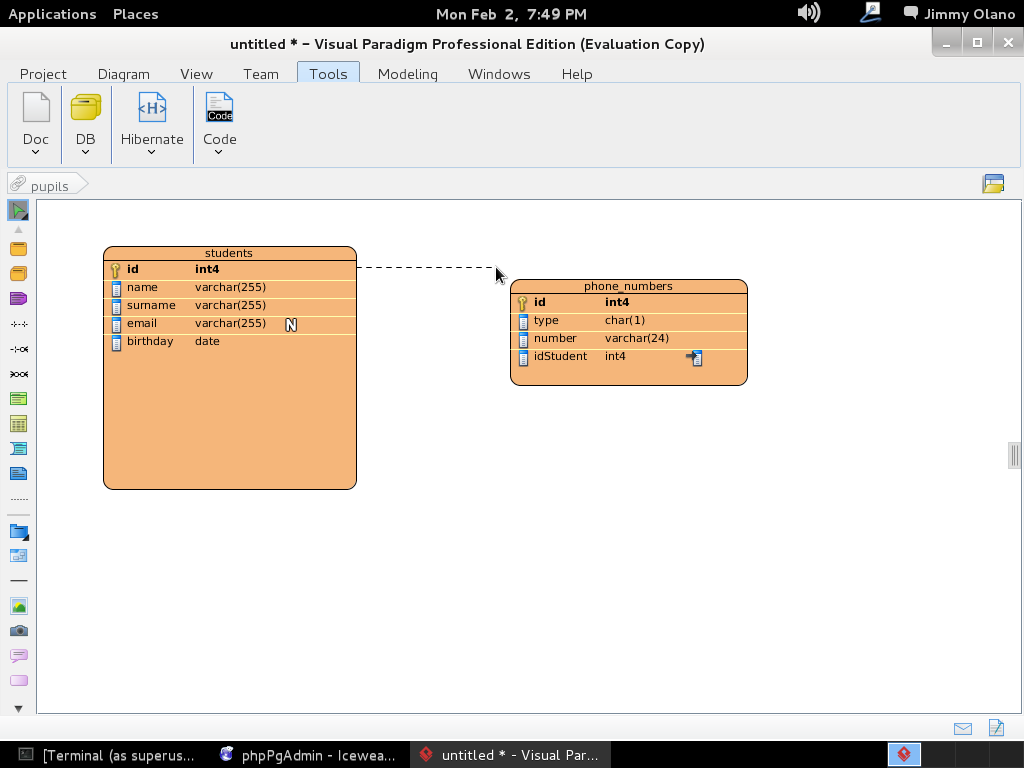
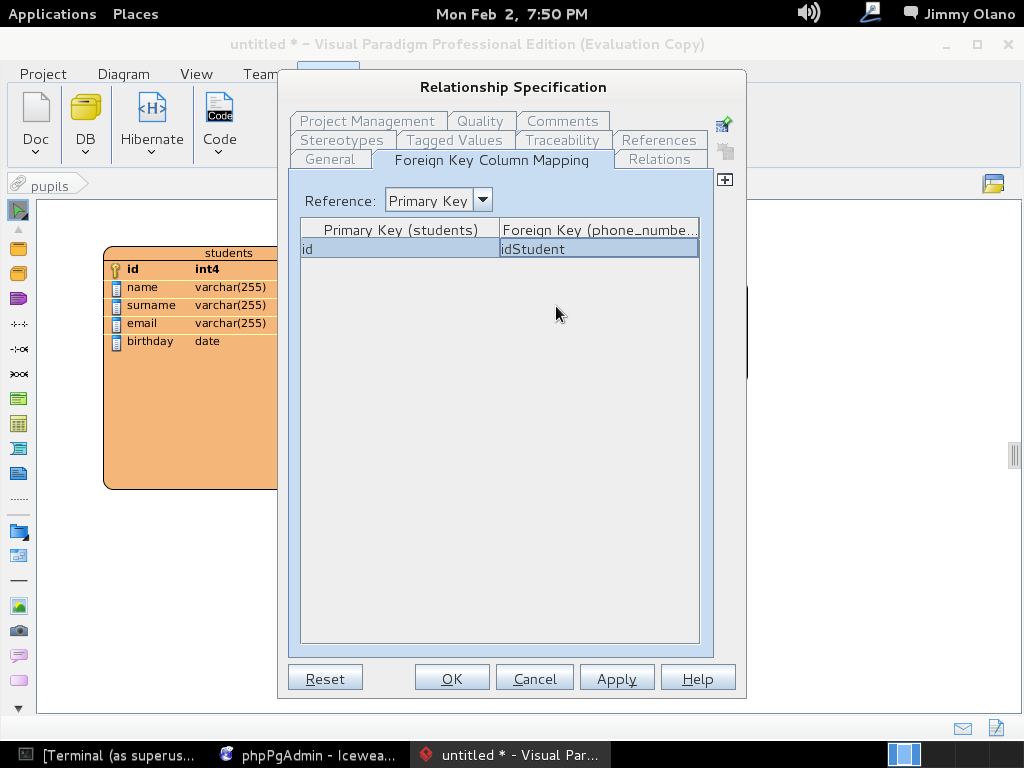
A continuación soltamos y se abre menú para escoger detalladamente la relación que queremos:
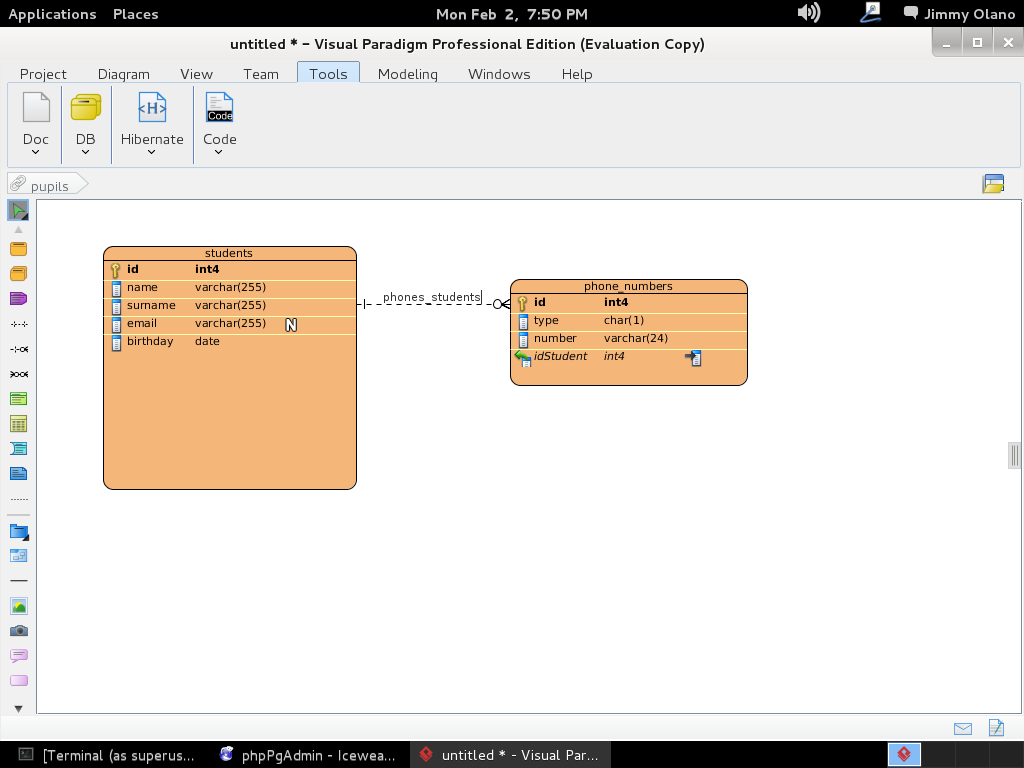
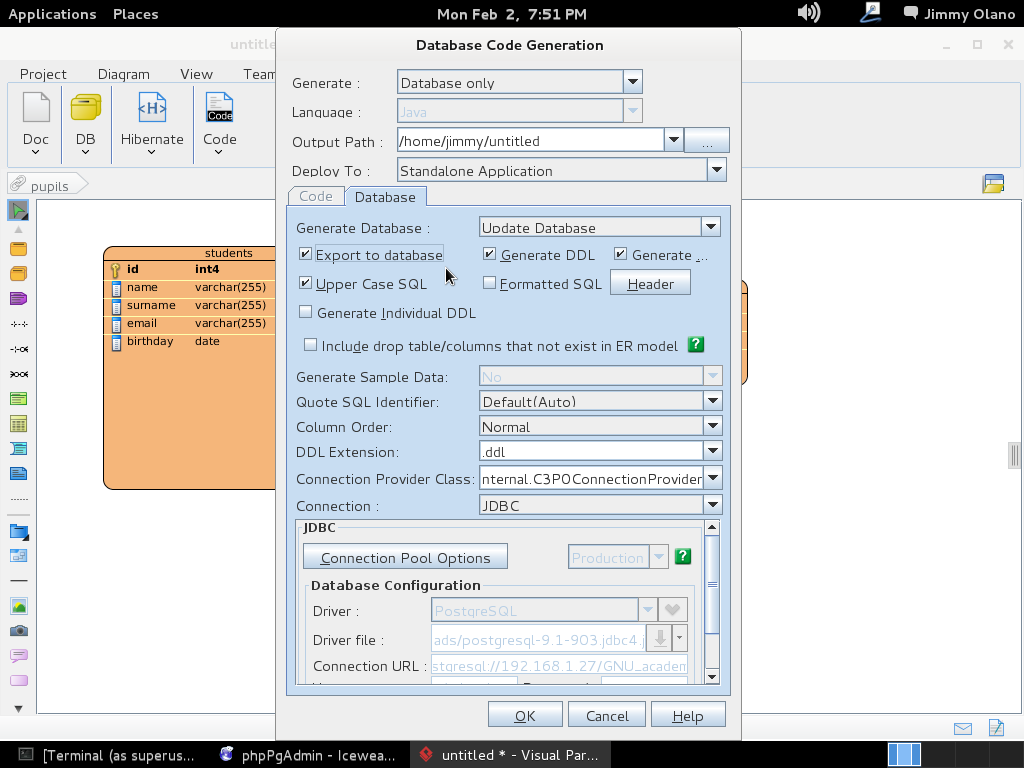
Y listo, ya tenemos definida la estructura de datos, sólo que falta el pequeño detalle de «enviarla» al servidor PostgreSQL, para ello de nuevo nos vamos la pestaña «Tools» y luego en «DB»->»Generate Database» (no se preocupen NO vamos a generar base de datos, aunque se puede hacer ya nosotros la creamos cuando instalamos phpPgAdmin ¿se recuerdan?) sólo es cuestión de seleccionar «Update Database» y marcar «Export to database», observen bien:
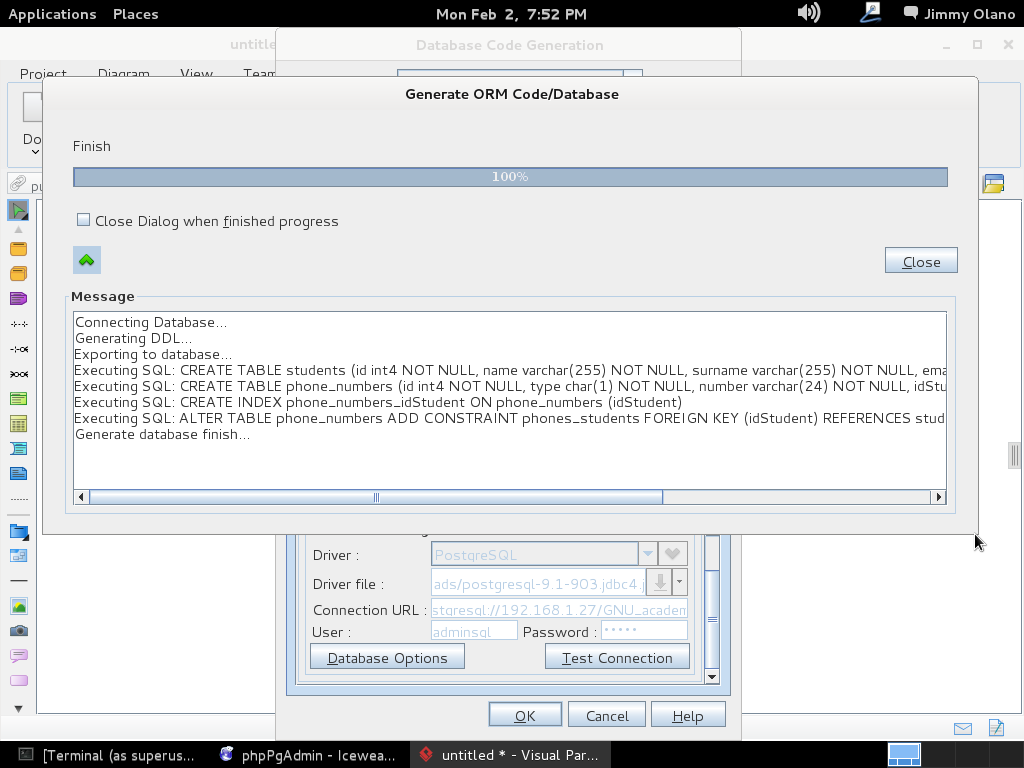
Recordemos que habíamos configurado previamente las propiedades de conexión, una vez pulsado «OK» (y sin seleccionar «Close dialog…») y si ampliamos y ajustamos el tamaño de ventana detallaremos el maravillos trabajo que nos ahorramos (sí, todas esas líneas de comandos que para este ejemplo son pocas pero imagínense que trabajamos en una empresa que manufactura clavos y nos piden hacer una aplicación que lleve el inventario de materia prima y productos terminados… ufff y eso sin meter las ventas, pedidos, despachos, comisiones de vendedores…):
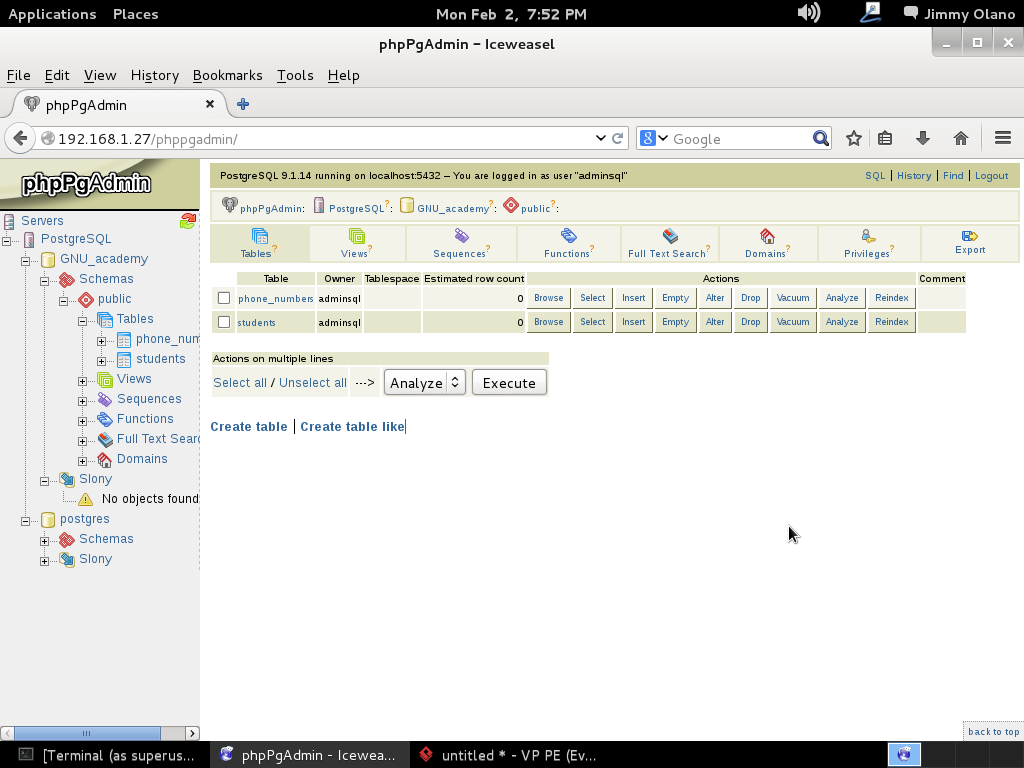
Ya para finalizar esta entrada, y sólo por desconfianza inherente a nuestra naturaleza humana, verificamos con phpPgAdmin cómo quedaron nuestras tablas (cómo navegar e ingresar están descritos en la entrada anterior) :
En nuestra próxima entrada veremos cómo añadir unos cuantos datos (registros) y los primeros comandos básicos de SQL.
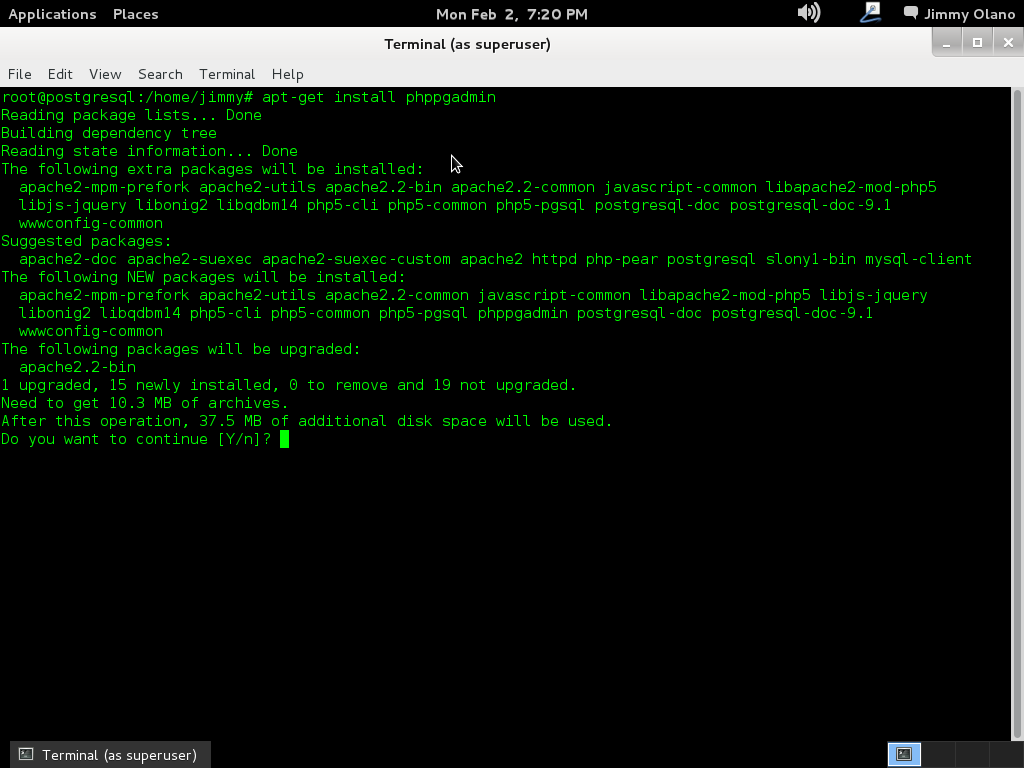
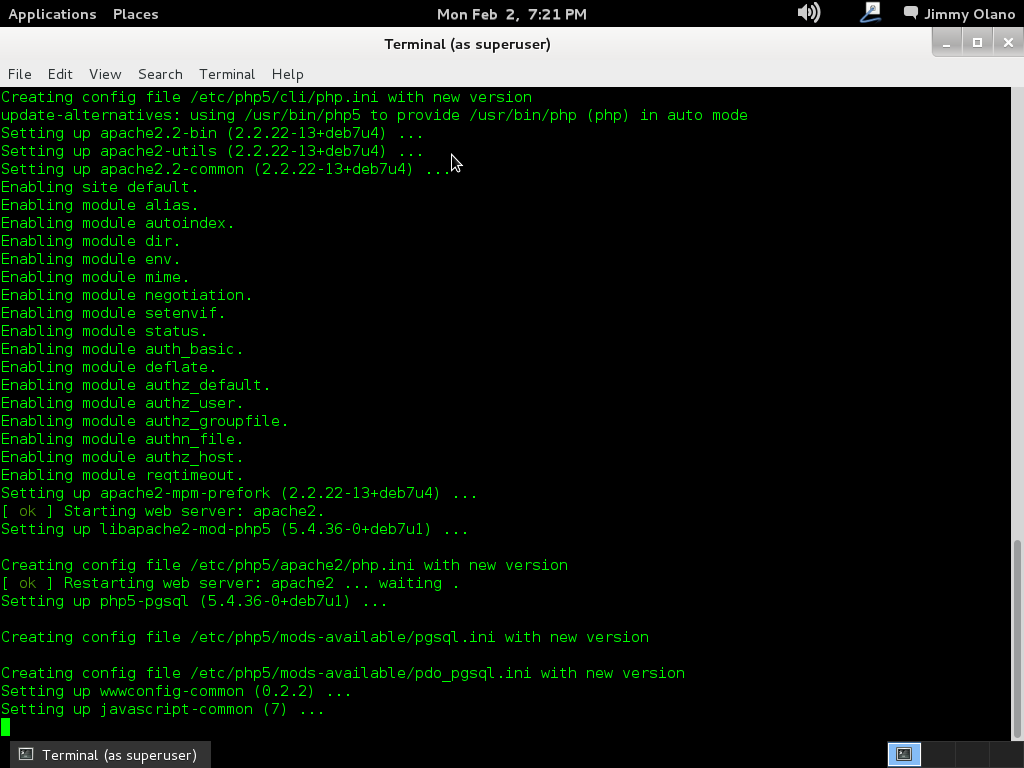
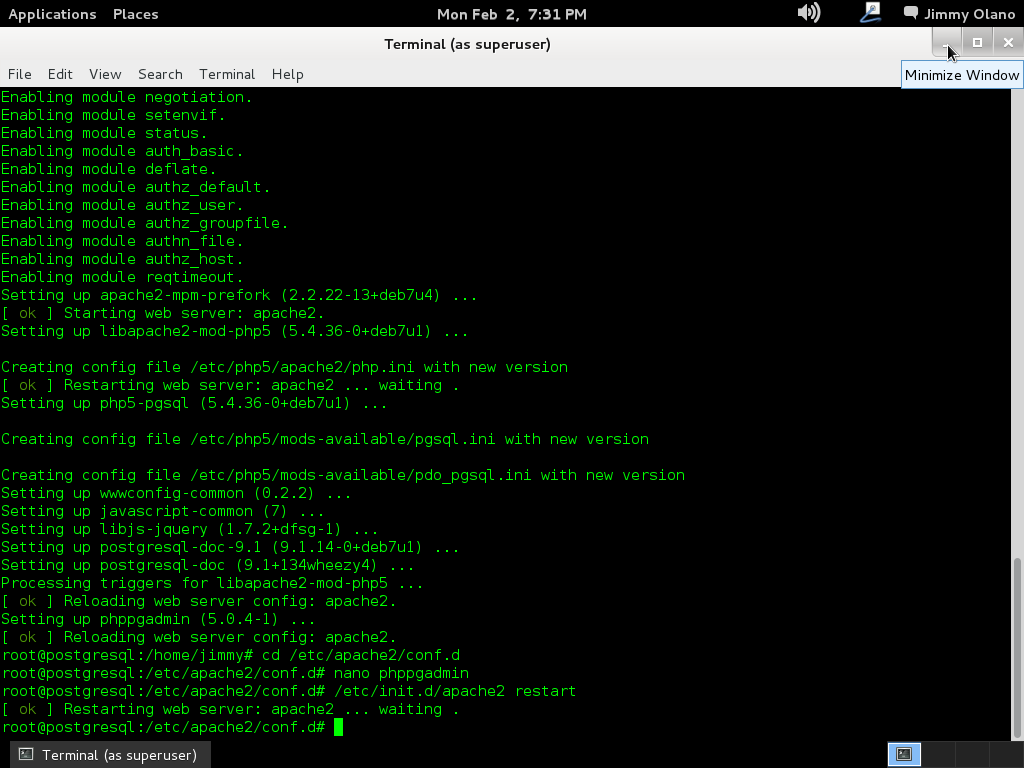
En la entrada anterior dejamos listo el servidor de base de datos PostgreSQL 9.1 y ahora vamos a utilizar software de administración basado en web phpPgAdmin para lo cual echamos mano de una cónsola con derechos (aquí utilizamos root de una buena vez) y luego usamos apt (también pueden utilizar aptitude-install si gustan y lo tienen configurado):
apt-get install phppgadmin
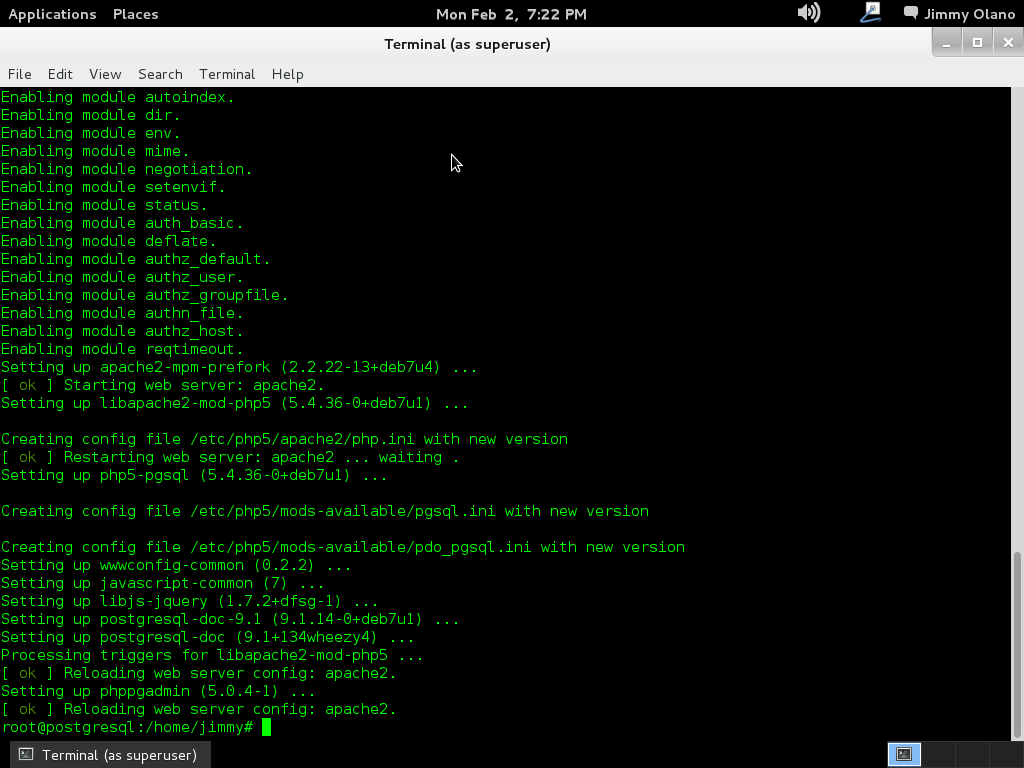
Recordad que aunque nos referimos como «phpPgAdmin» para el apt debemos escribirlo todo en letras minúsculas para que pueda haber coincidencia con los repositorios, ojito con eso que en GNU/Linux es motivo de frustración en muchas personas (eso y el NUMLOCK encendido). La buena noticia es que, si no lo tenemos instalado, la orden de manera tácita instala el servidor web Apache y el lenguaje de programación PHP a nuestra máquina (los módulos necesarios sólamente, ni más ni menos):
Una vez que pulsamos la letra «Y» y presionamos «Enter» («S» e «Intro» para los que hablamos castellano):
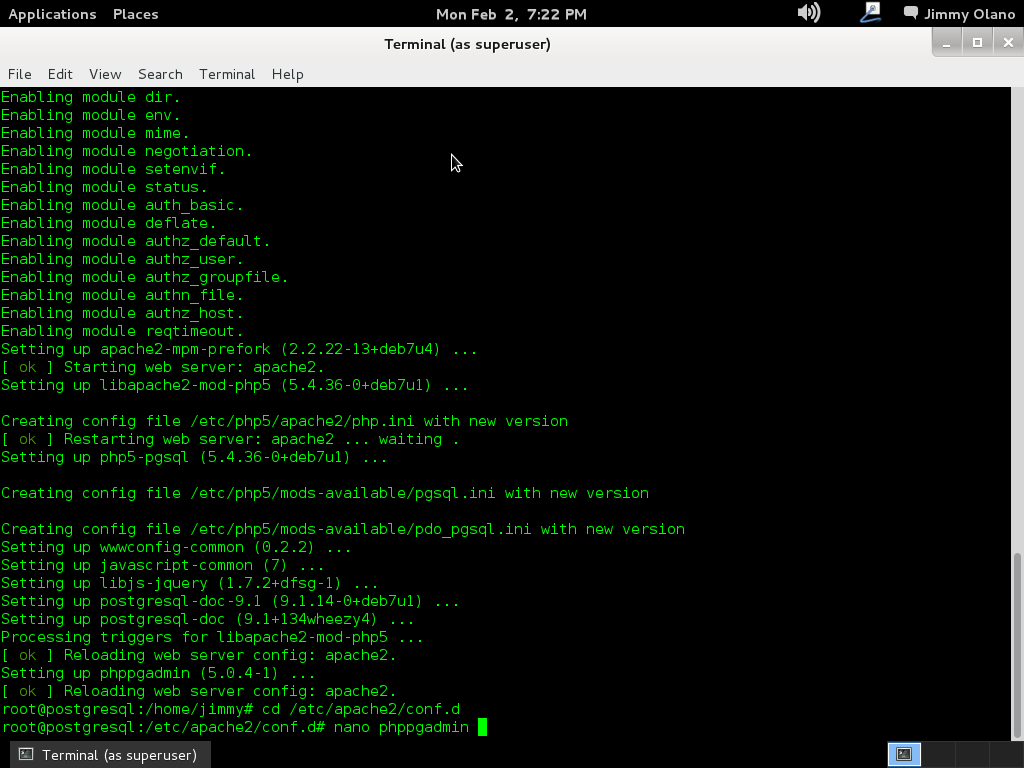
Al finalizar la instalación podemos configurar el phpPgAdmin para que admita conexiones desde cualquier computadora, por seguridad viene sólo para sea administrado directa y únicamente por cónsola de la máquina, así que:
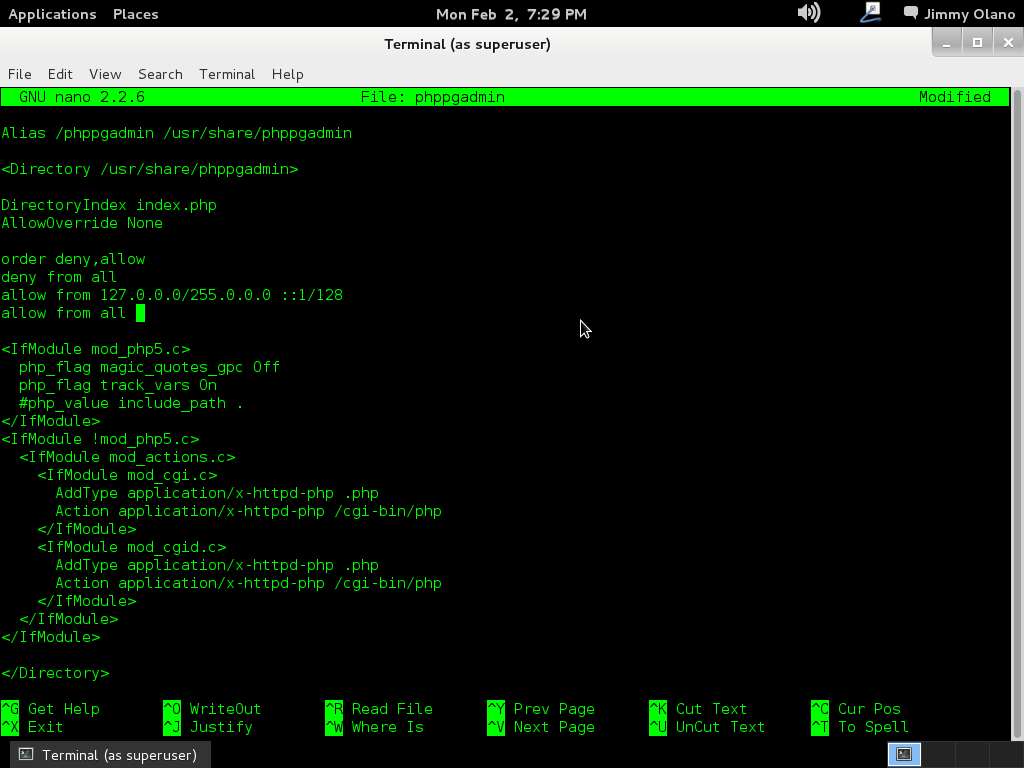
cd /etc/apache2.d
nano phppgadmin
Así descomentamos (eliminamos «# » del inicio de línea) justo la que está debajo de «allow from 127.0.0. (..)», veréis algo así como esto:
Guardamos y salimos para luego reiniciar el servidor Apache y que acepte así la nueva configuración que necesitamos:
/etc/init.d/apache2 restart
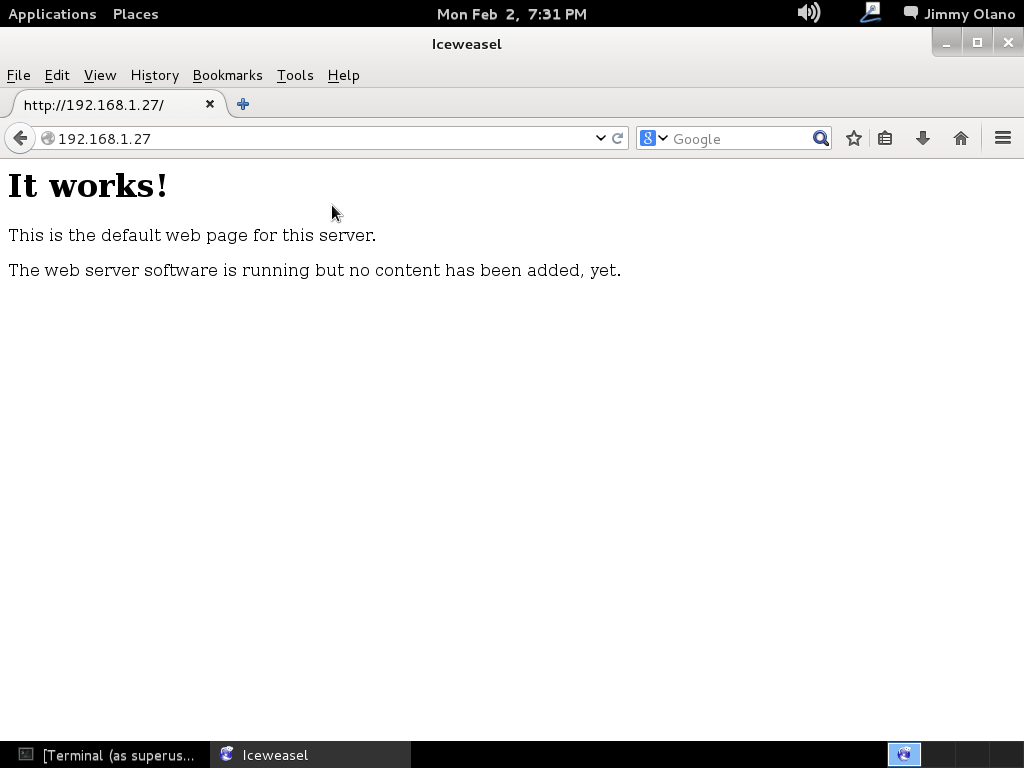
Ahora desde cualquier otra máquina en la misma red de área local (recordáis que les dije que anotaran ése valor) podemos proceder a verificar primero si el servidor web funciona:
Esta última captura de pantalla, tal y como se los describí en la entrada origen a este trabajo, es la máquina real que contiene a la máquina virtual en la cual está alojada la máquina virtual cuyo nuestro enrutador de red inalámbrico le asignó la dirección 192.168.1.27 y utilizamos Iceweasel que es el navegador web predeterminado en Debian. Luego procedemos a verificar si el phpPgAdmin está corriendo al introducir en la barra de direcciones el siguiente comando:
http://192.168.1.27/phppgadmin
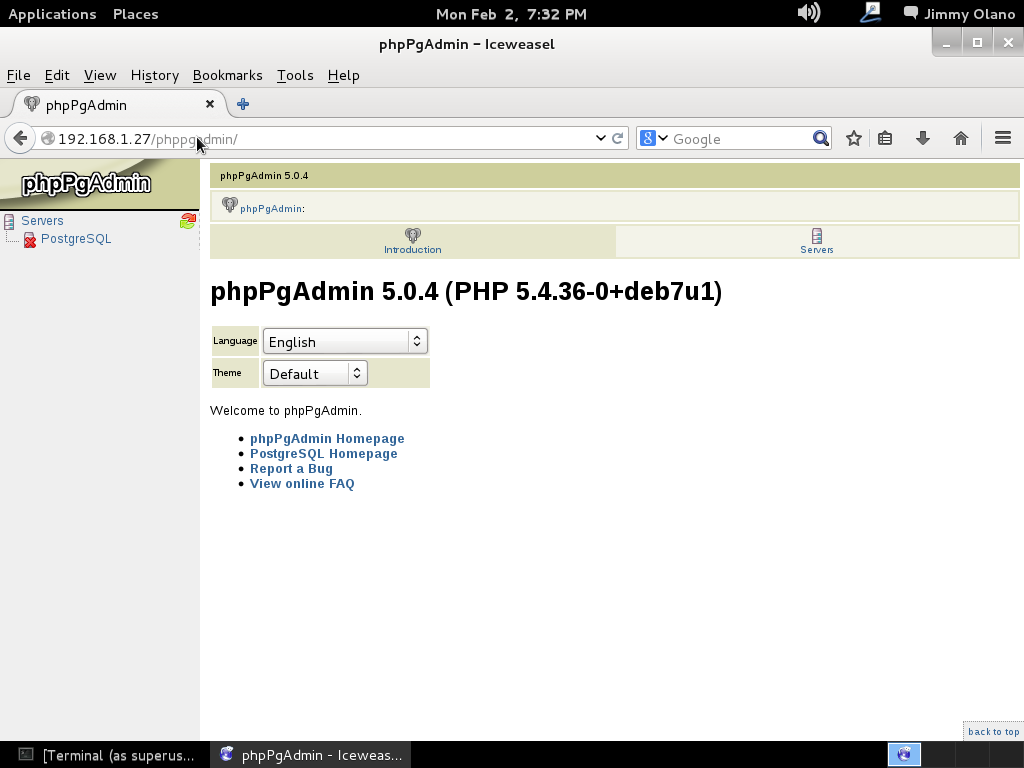
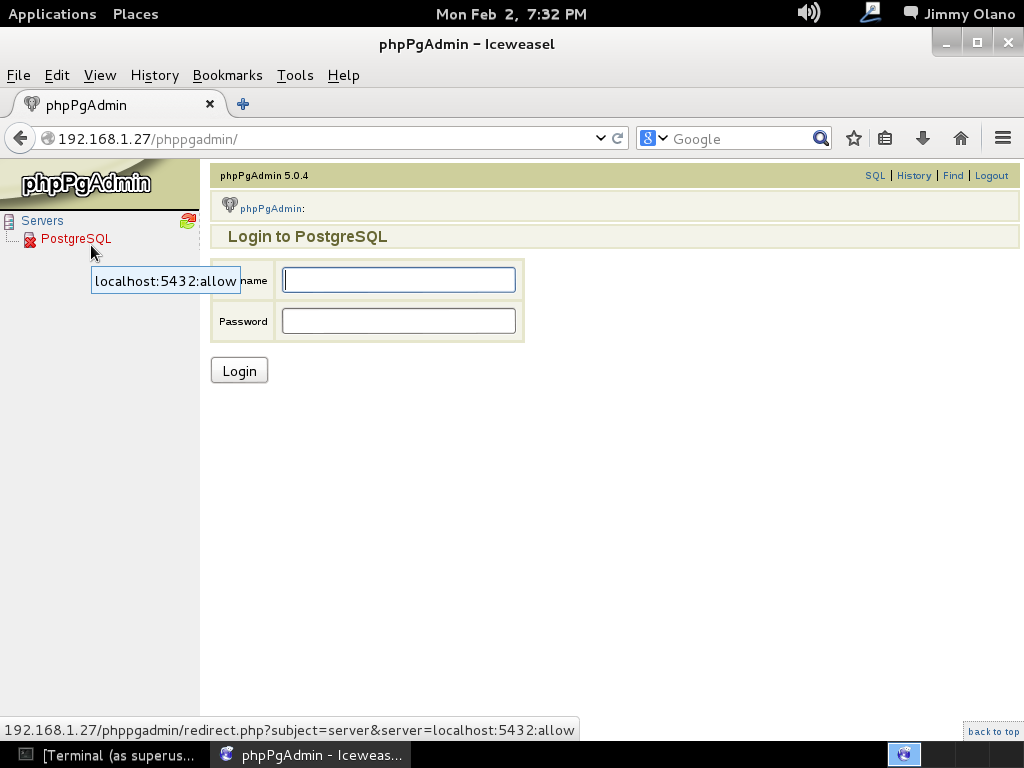
Hacemos click en el panel izquierdo en donde dice «Servers->PostgreSQL» y nos aparece la pantalla para iniciar sesión:
Para nuestro caso el usuario que le colocamos: «adminsql» y contraseña «12345», entramos y podemos observar que la única base de datos es postgres la cual es utilizada para almacenar valores del PostgreSQL y permitir su funcionamiento, la dejamos tranquilita, si queréis podeís ver sus valor sin modificar nada (por ahora):
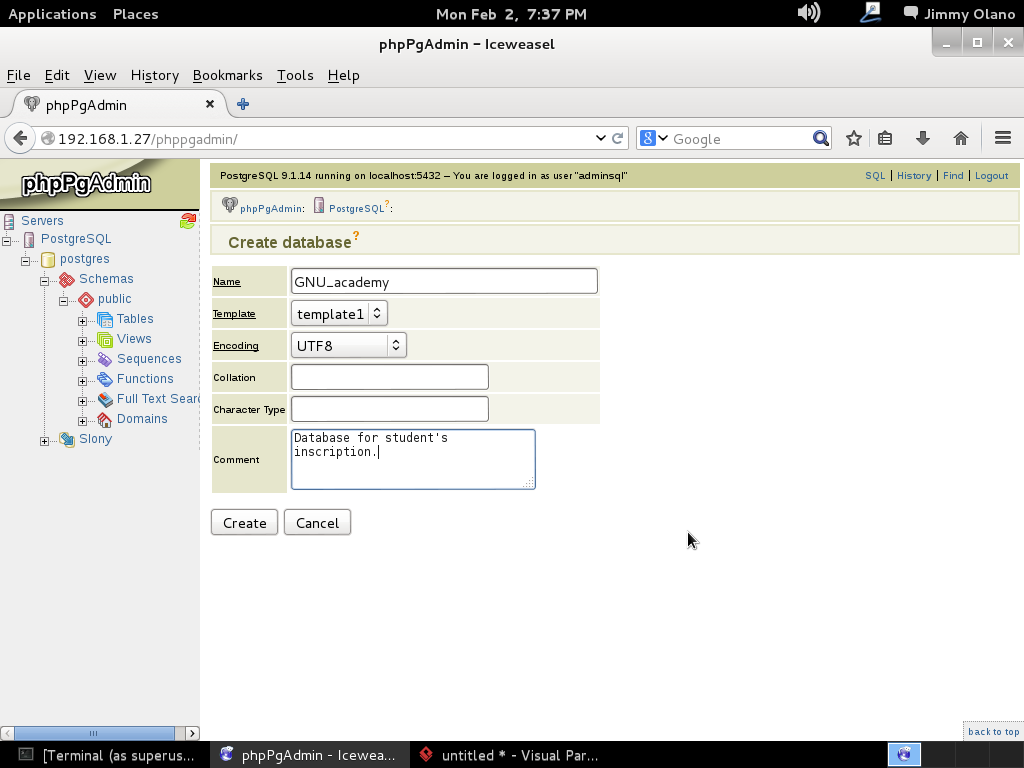
Fijad la mirada en el enlace «Create database» allí mismo hacemos click para comenzar a trabajar (¡por fin!) en el proyecto en sí:
Le colocamos el nombre «GNU_academy» en el «encoding» seleccionamos «UTF8» para que acepte nuestros caracteres castellanos («ñÑáÁéÉíÍóÓúUüÜ») y no se preocupen por «Collation» que automáticamente toma la configuración regional del sistema.
Hasta aquí finaliza el tema de phpPgAdminen la próxima entrada comenzaremos con la poderosa herramienta Visual Paradigm.
Por motivos de trabajo y estudio hemos descuidado un poco nuestro blog pero antes que termine el mes de enero de 2015 traemos a caso de análisis el potente motor para bases de datos PostgreSQL y aunque al momento de escribir esto ya van por la versión 9.4 (diciembre de 2014) utilizaremos para nuestro estudio la versión 9.1 (ojito con estos numeritos de la versión que lo usaremos bastante).
En esta entrada haremos un trabajo eminentemente práctico, las teorías y detalles serán tradadas en entradas posterios, dado el tamaño del tema en cuestión. Mi reconocimiento especial a @phenobarbital por su blog que sirve como preciada guía para este nuestro proceso de aprendizaje.
A manera de resumen enumeramos lo siguiente:
Con VirtualBox haremos una máquina virtual Debian 32 bits para hacer allí las pruebas necesarias sin comprometer nuestra máquina real (uso y creación de máquinas virtuales merece una entrada completa aparte a futuro).
Una vez instalada y configurada con sus repositorios instalaremos PostgreSQL y la configuraremos para aceptar conexiones de usuarios de la red de área local (no obstante los comandos los introduciremos directamente por cónsola, las sesiones ssh y Tmux merecen entrada aparte en el blog -a futuro-).
Una vez tengamos el terreno abonado usaremos Visual Paradigm para linux 32 bits en modo demostrativo ya que con esta herramienta definiremos las tablas de una base de datos sencilla, manejo de inscripción de personas en cursos, haciendo una abstracción generalizada de dicho proceso.
Instalaremos phpPgAdmin como herramienta para administrar la base de datos vía web, verificar las tablas e incluso agregar y/o modificar datos.
Con datos agregados (y esperamos agregar unos cuantos millones de usuarios) realizaremos algunas sentencias SQL, uniones y consultas.
Pues bien, manos a la obra.
Instalación de PostgreSQL.
Con la máquina virtual corriendo (512 megabytes RAM, 1 CPU y 1 NIC 100 mbps asignados virtualmente) abrimos una terminal y nos registramos como super usuario, recuerden que debemos tener configurados ya nuestros repositorios y una buena conexión a internet. Para nuestro caso es específico tenemos a la máquina virtual alojada en una red de área local cuyo enrutador asigna direcciones IP internas con DHCP basado en la dirección MAC de la tarjeta de red virtual que está en puente «bridge» con la máquina real así que al arrancar automáticamente ya la tenemos en la dirección 192.168.1.27 y con 5 mbps de velocidad al internet asignada a ella solita para no molestar a los demás usuarios, si no hacemos esto monopolizaremos al modem y no es la idea (de nuevo, todo esto merece una entrada aparte en nuestro blog, a futuro lo haremos).
Ejecutamos en la cónsola:
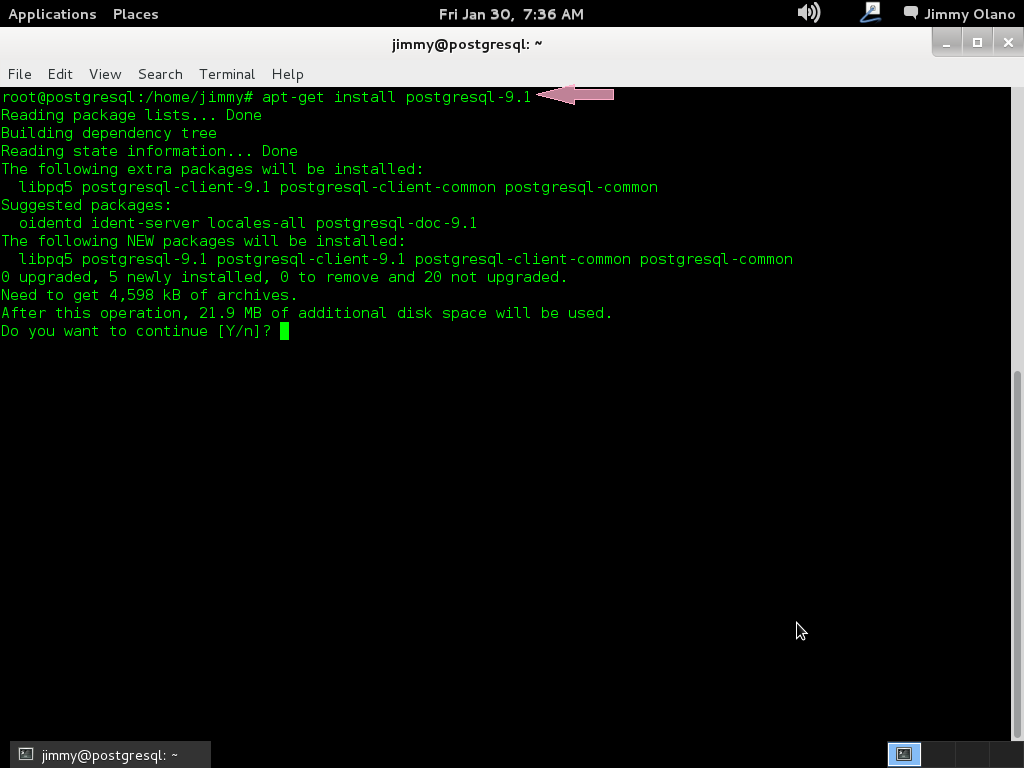
apt-get update (intro).
apt-get install postgresql-9.1
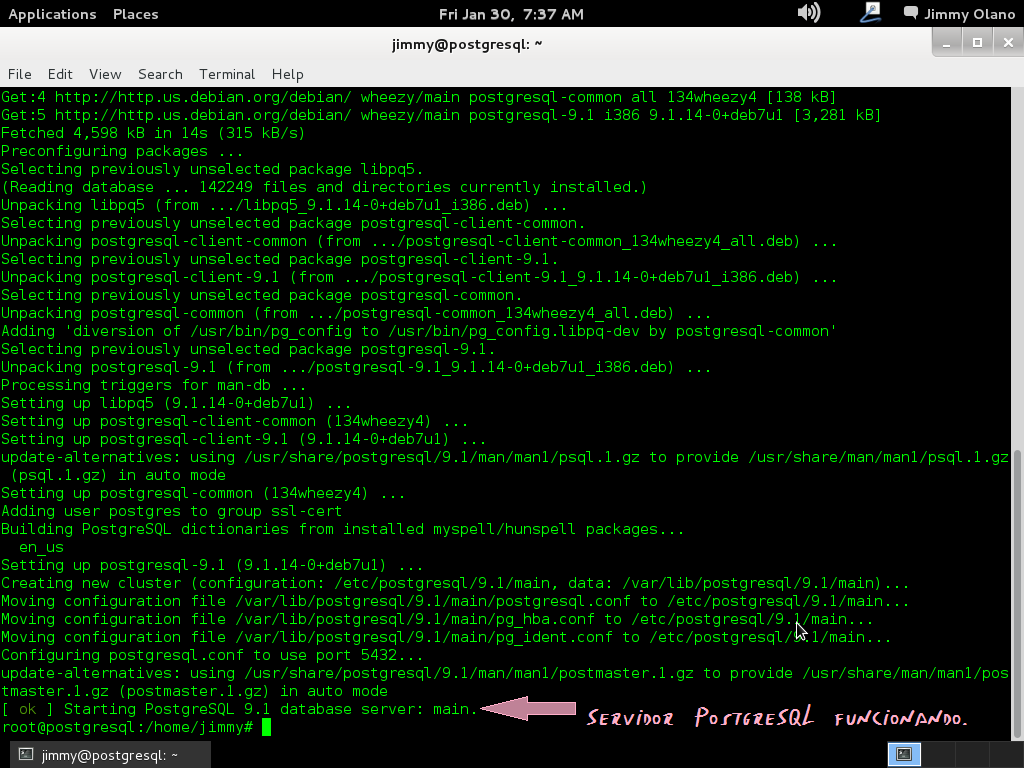
Recordando siempre que estamos como super usuario, aquí una captura de pantalla de los procesos que más o menos vereís sobre el proceso de instalación.
Configuración de PostgreSQL.
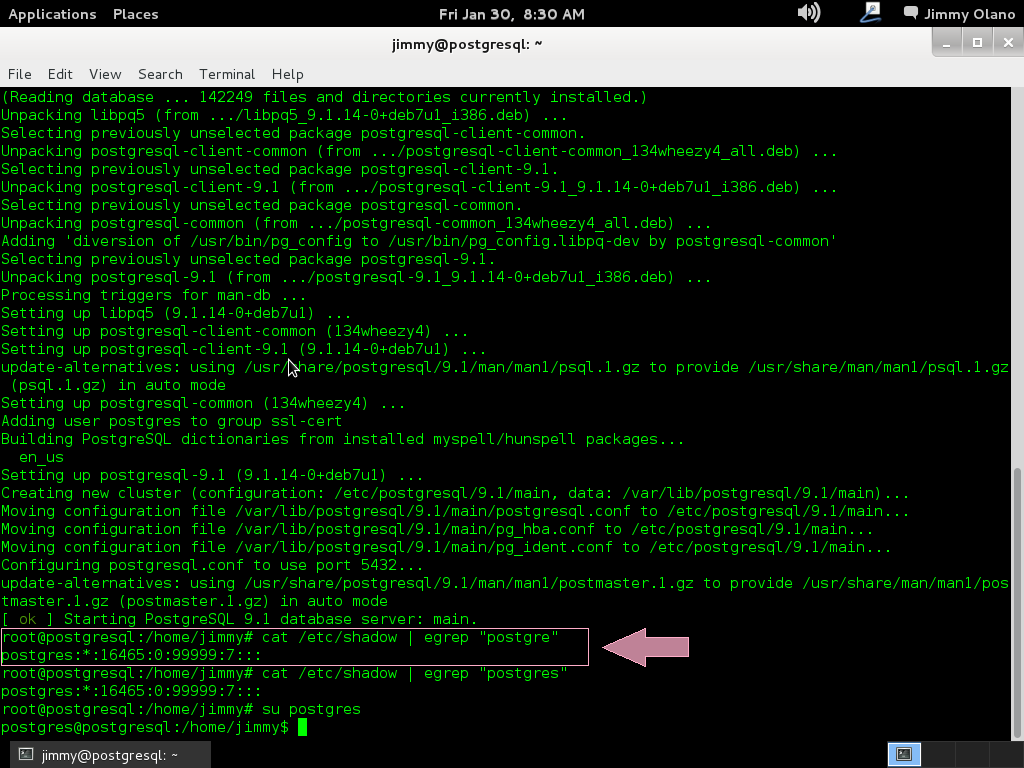
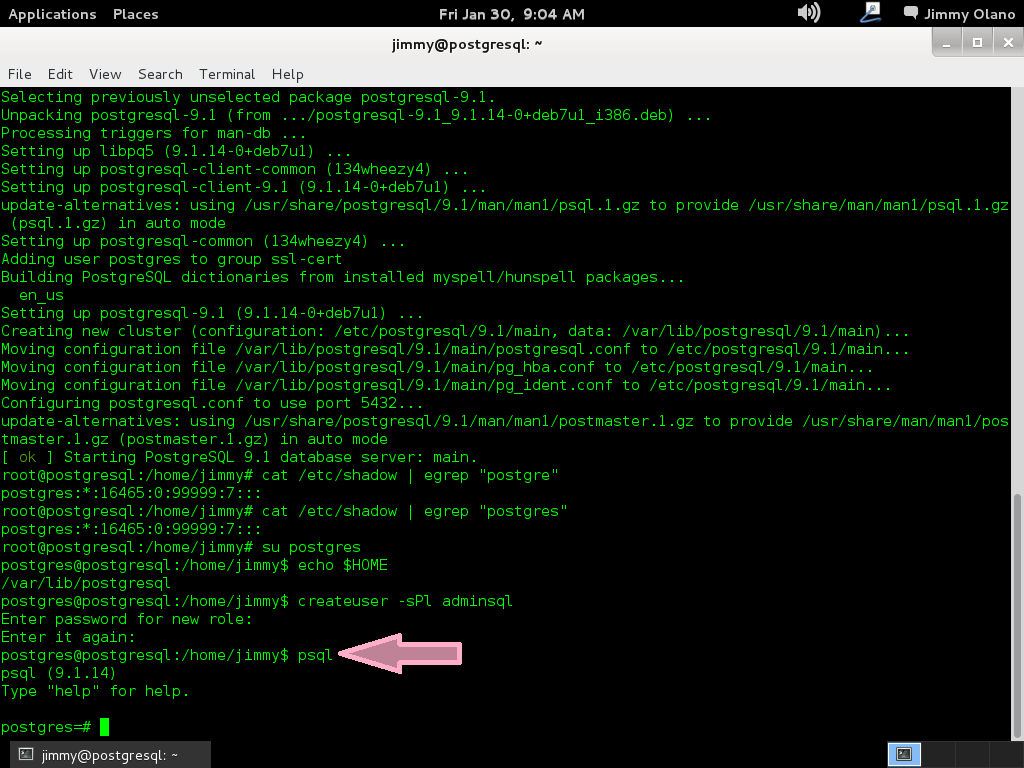
Una vez finalizada la instalación es que comienza en realidad nuestro trabajo, verificamos si la instalación agregó un usuario llamado «postgres» con el comando:
cat /etc/shadow | egrep «postgres»
a lo cual devuelve algo parecido a esto (si está está agregado el usuario):
postgres:*:16465:0:99999:7:::
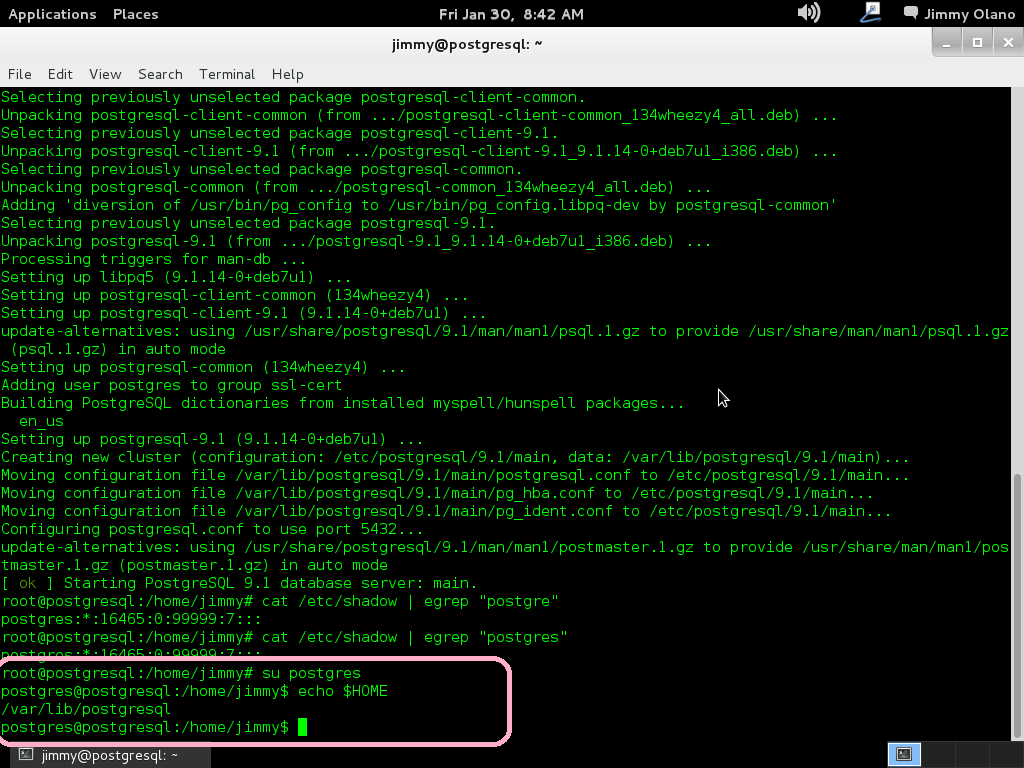
Si es positivo procedemos a conectarnos como usuario «postgres»:
su postgres
y el indicador se convierte en «postgres@postgresql:/home/jimmy$» y esto quiere decir que estamos conectados como usuario «postgres» en la máquina «postgresql» y ubicados en la carpeta «home» del usuario «jimmy». Si queremos ver cual es nuestra carpeta «home», osea el «home» del usuario «postgre» escribimos:
echo $HOME
lo cual devuelve «/var/lib/postgresql».
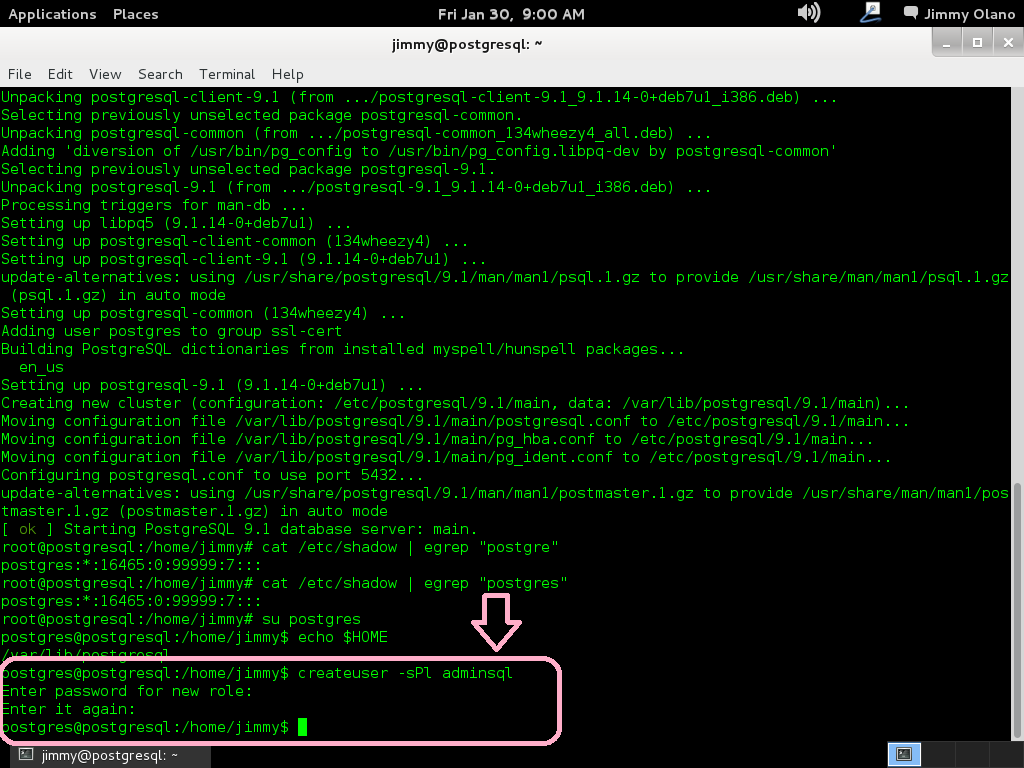
La idea es crear un nuevo usuario utilizando la sencilla nomenclatura para nombres y contraseñas (que para propósitos didácticos es excelente PERO para la vida real NO cuidadito con dejar un servidor PostgreSQL configurado así 😯 ).
createuser -sPl adminsql
y nos pregunta contraseña a lo cual introducimos «12345» y confirmamos nuestra elección.
Ahora si es que vamos a entrar al propio PostgreSQL, escribimos:
psql
lo cual nos devuelve algo parecido a esto (imagen):
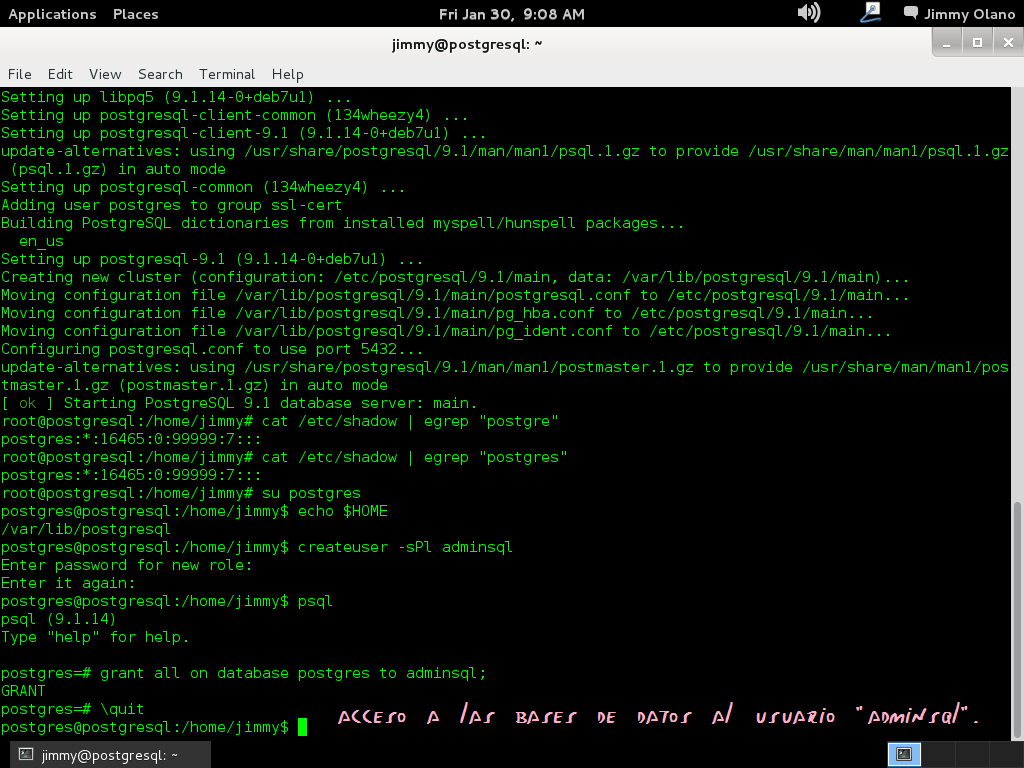
y acto seguido garantizamos que el usuario que acabamos de agregar tenga acceso libre a las bases de datos:
grant all on database postgres to adminsql;
y si nos acepta el comando nos devuelve «GRANT» y listo, salimos de la cónsola con
\quit
Acceso remoto a PostgreSQL.
No obstante que estamos trabajando en cónsola directamente a la máquina virtual lo más probable es que tengamos que acceder a ella remotamente así que agregamos el usuario que acabamos de agregar al archivo siguiente:
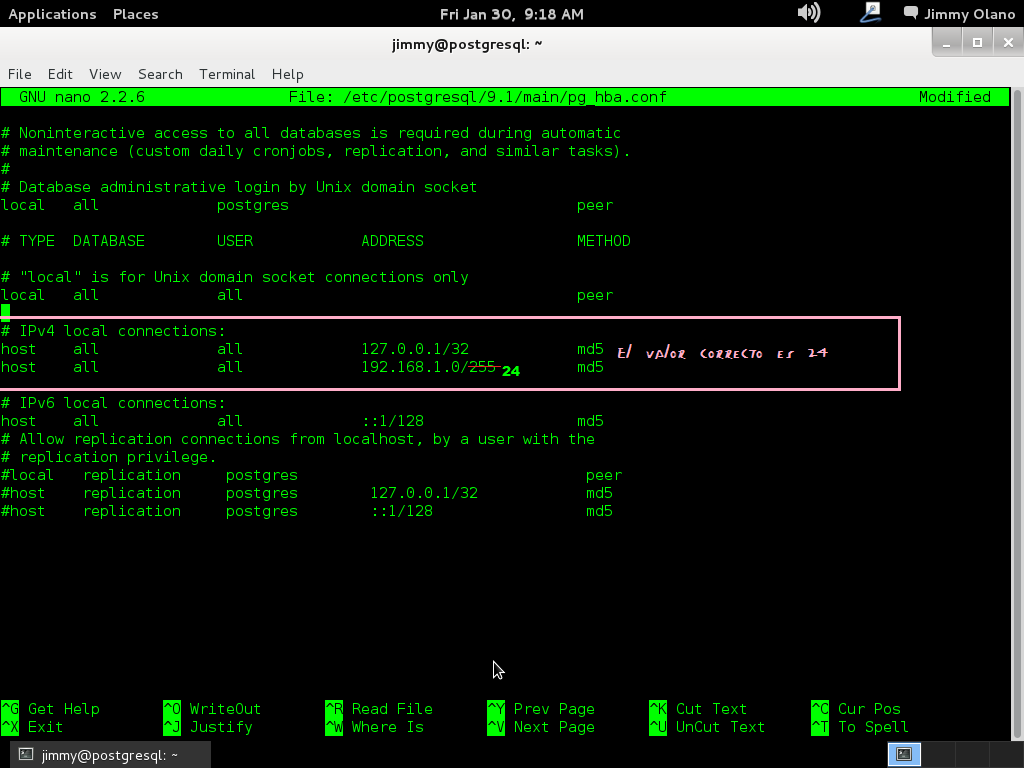
nano /etc/postgresql/9.1/main/pg_hba.conf
y quiere decir que utilizamos el editor de texto «nano» para editar el archivo pg_hba.conf (o utilicen su editor de texto favorito, muy populares son «vi» y pueden instalar «vim» o «gedit», el que gusten). Editamos el archivo donde especifican las direcciones IPv4:
#IPv4 local conections:
host all 127.0.0.1/32 md5
host all 192.168.1.0/24 md5
Teniendo cuidado de insertar sólo espacios en blanco entre las palabras (que si usaís la tecla TAB configurar para que la misma inserte espacios y no el caracter mismo tabulador) y recordemos hacer esto cada vez que agreguemos un usuario a la base de datos y así permitirle conectarse de manera remota en una red de área local con su respectiva submáscara de red (en notación CIDR: «192.168.1.0/24»), me disculpan el error al colocar 255:
Guardamos y salimos a la linea de comando para ejecutar:
nano /etc/postgresql/9.1/main/postgresql.conf
y modificamos y agregamos los siguientes datos (todo lo que esté escrito a la derecha del símbolo «#» son comentarios que no toma en cuenta el servidor PostgreSQL pero que para nosotros los humanos son importantes):
# – Connection settings –
listen_addresses = ‘*’ #valor por defecto ‘localhost’
max_connections = 50 # valor por defecto 100
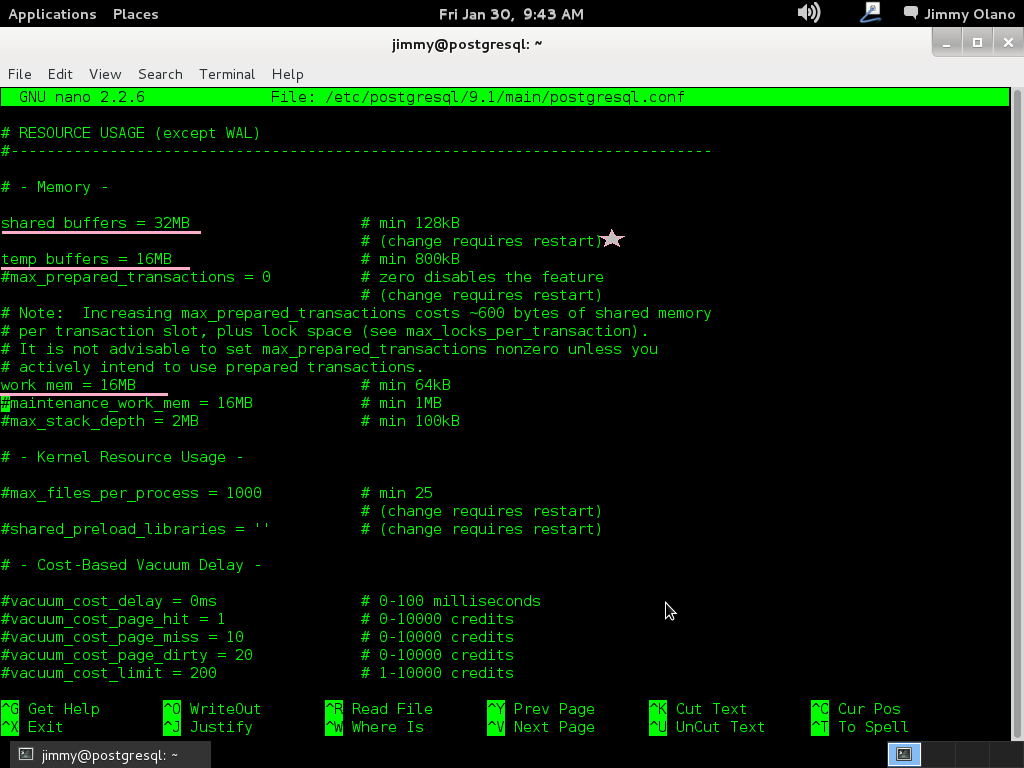
# – Memory –
shared_buffers = 16MB #valor por defecto 24 se requiere «fórmula» para hallar el mejor valor para nuestro servidor según nuestro hardware -nunca más del 40% de la memoria instalada o virtualizada-.
temp_buffers = 8MB #8 por defecto la subimos a 16 pero eso depende de las consultes que pensemos ejecutar, hay que tantear este valor.
work-men = 16MB #para las INSERT, DELETE para cada usuario por cada segundo
# – Background Writer –
bgwriter_delay = 500ms #cada medio segundo escribe al disco duro y así evitamos sobrecargar al hardware.
En las siguientes imágenes sólo falta el valor de acceso al disco duro descrito poco antes, observen que coloco una estrella para resaltar los valores que necesitan reiniciar al servidor PostgreSQL (dado el caso que tengamos usuarios conectados utilizamos reload en vez de restart):
Observen escribir cuidadosamente cada uno de los valores antes de guardar (si yo tengo algún error o sugerencia COMENTAR esta entrada) así que si todo está correcto guardamos y salimos a la cónsola de entrada y una vez hecho esto procedemos a reiniciar el servidor de base de datos con la orden:
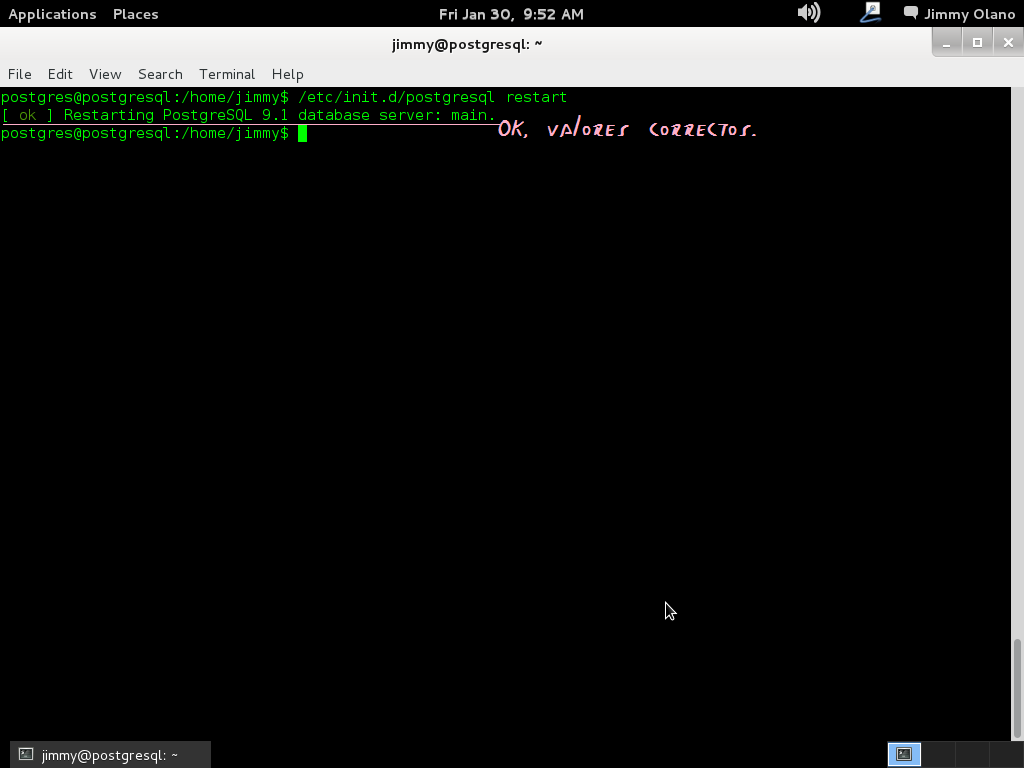
/etc/init.d/postgresql restart
y si hemos colocado bien las modificaciones devolverá lo siguiente (imagen):
De no ser así volvemos sobre nuestros pasos hasta que se reinicie el servidor postgresql y avanzar hacia la siguiente etapa de configuración.
En este punto debemos advertir que tocaremos variables de configuración del sistem Debian por lo tanto debemos ser cuidadosos con lo que escribimos, vericar 3 veces lo ingresado; ya que estamos como usuario «postgres» debemos teclear «exit» y presionar la tecla intro y ganar acceso como «root» para así poder ejecutar en cónsola:
nano /etc/sysctl.conf
y agregamos al final los siguientes valores (que por ahora no sabemos qué significan pero en una futura entrada le dedicaremos su correspondiente espacio bien explicado):
Revisamos bien los valores guardamos y salimos para ejecutar:
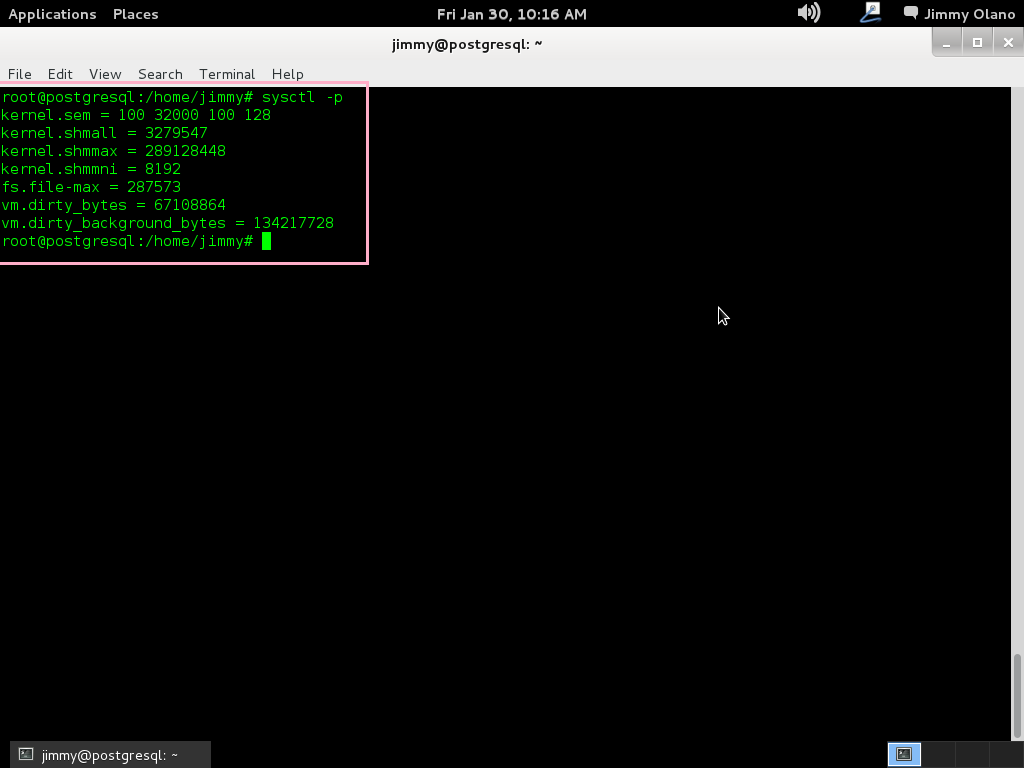
sysctl -p
a lo cual nos devuelve por pantalla precisamente los guarismos que introdujimos:
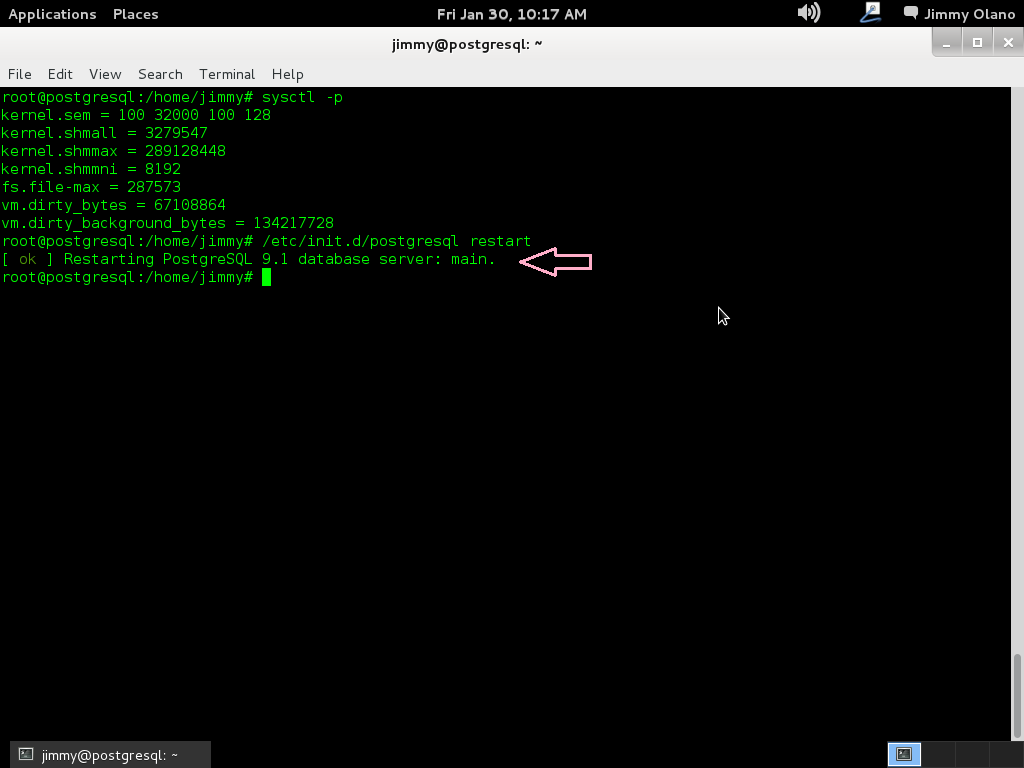
Acto seguido comprobamos que el servidor PostgreSQL acepte la nueva configuración pormedio de la orden que ya sabemos:
/etc/init.d/postgresql restart
y si todo va bien veremos lo siguiente:
Ahora vamos a instalar el Visual Paradigm 12 phpPgAdmin desde el enlace que colocamos al inicio de esta entrada y para no resultar tediosa y larga esta entrada continuaremos en otra en el siguente enlace.