
Traducción del idioma inglés publicado por el señor Daniel Stenberg, título original «The Art Of Scripting HTTP Requests Using Curl» en:
https://curl.se/docs/httpscripting.html
En esta traducción se conserva tal cual el dominio example.com (ejemplo punto com) y example.org (ejemplo punto o-ere-ge) ya que las traducciones al castellano allanan el camino a dominios comprados por terceros para aprovecharse de este tipo de situaciones didácticas. Las notas del traductor está abreviadas como (n. del t.) y se utiliza (sic) para denotar en latín que así tal cual fue escrito en su idioma original (y luego traducido tal cual).
Este artículo en específico se rige por la licencia CC-BY que fue asignada por su correspondiente(s) autor(es) o autora(s). Dicha licencia permite así la propagación de este material y su traducción a cualquier idioma. Usted podrá encontrar un resumen de tal licencia en este enlace (en idioma castellano) y la licencia en sí misma de forma completa y totalmente traducida al español en este otro enlace.

This article is under License Creative Commons Attribution 4.0 International.
Tabla de contenido:
Antesala
Este documento asume que está familiarizado con HTML y redes en general.
La creciente cantidad de aplicaciones que se trasladan a la web ha hecho que «HTTP Scripting» (guiones para HTML) sea ahora más solicitado y buscado. Poder extraer automáticamente información de la web, falsificar usuarios (sic n. del t.), publicar o cargar datos en servidores web son tareas importantes hoy en día.
Curl es una herramienta de línea de comandos para realizar todo tipo de manipulaciones y transferencias de URL, pero este documento en particular se centrará en cómo usarlo cuando se realizan solicitudes HTTP por diversión y ganancias. Asumiré que sabe cómo invocar curl –help o curl –manual para obtener información básica al respecto.
Curl no está escrito para hacer todo por usted. Hace las solicitudes, obtiene los datos, envía datos y recupera la información. Probablemente necesite unir todo utilizando algún tipo de lenguaje de script o o realizando invocaciones manuales repetidas.
El protocolo HTT (HTTP)
HTT es el protocolo utilizado para obtener datos de los servidores web. Es un protocolo simple que se basa en TCP/IP. El protocolo también permite enviar información al servidor desde el cliente utilizando algunos métodos diferentes, como se mostrará aquí.
HTTP son líneas de texto ASCII sin formato (HTTP anteriores a HTTP 2, n. del t.) que el cliente envía a un servidor para solicitar una acción en particular, y luego el servidor responde algunas líneas de texto antes de que el contenido real solicitado se envíe al cliente.
El cliente, curl, envía una solicitud HTTP. La solicitud contiene un método (como GET, POST, HEAD, etc.), varios encabezados de solicitud y, a veces, un cuerpo de solicitud. El servidor HTTP responde con una línea de estado (que indica si todo salió bien), encabezados de respuesta y, en la mayoría de los casos, también un cuerpo de respuesta. La parte del «cuerpo» son los datos sin formato que solicitó, como el HTML real o la imagen, etc.
Vea el protocolo en acción
El uso de la opción de curl --verbose (-v como opción abreviada) mostrará qué tipo de comandos envía curl al servidor, así como algunos otros textos informativos.
--verbose es la opción más útil cuando se trata de depurar o incluso comprender la interacción del servidor curl<->.
A veces incluso --verbose no es suficiente. Entonces, para eso, –trace y --trace-ascii ofrecen aún más detalles, ya que muestran todo lo que curl envía y recibe. Úselo así:
curl --trace-ascii debugdump.txt http://www.example.com/
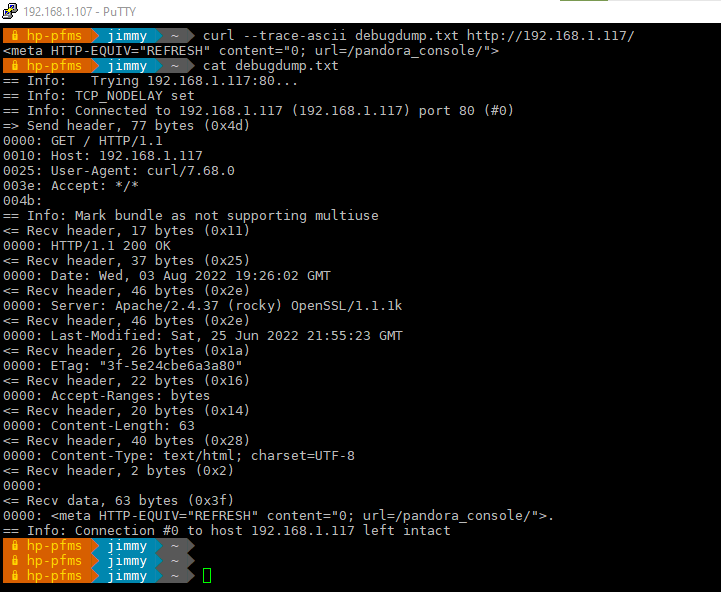
Cronometre la consulta
Muchas veces se preguntará cuánto tiempo exactamente toma la consulta, o simplemente quiere saber la cantidad de milisegundos entre dos puntos en una transferencia. Para esas y otras situaciones similares, la opción --trace-time es lo que necesita. Antepondrá la hora a cada línea de salida de seguimiento:
curl --trace-ascii d.txt --trace-time http://example.com/
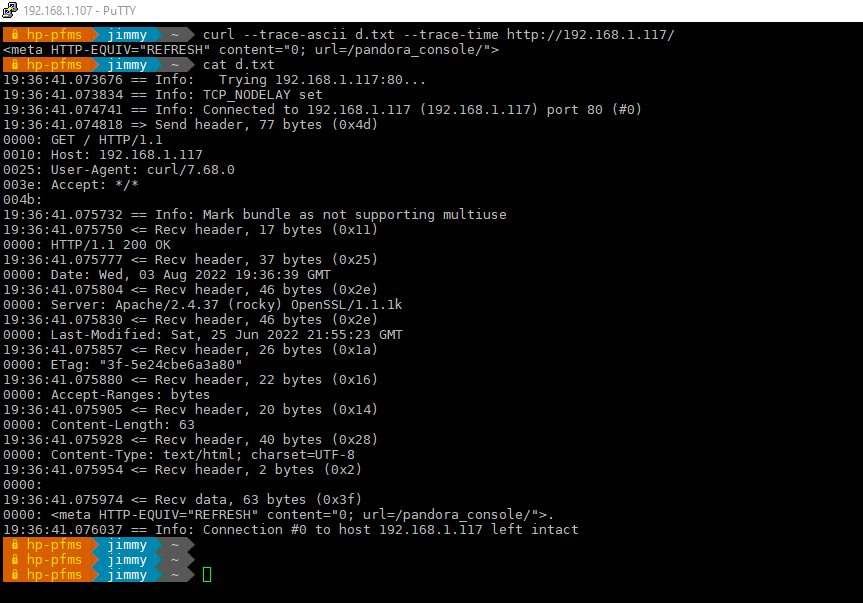
Observe la consulta
Por defecto, curl envía la respuesta a stdout. Debe redirigirlo a algún lugar para evitar eso, la mayoría de las veces se hace con -o o -O.
URL
Especificaciones
El formato del localizador uniforme de recursos (formato URL) es la forma en que especifica la dirección de un recurso en particular en Internet. Usted los conoce, usted los ha visto URL como, por ejemplo, https://curl.se o https://subanco.com.ve un millón de veces. RFC 3986 es la especificación canónica. Y sí, el nombre formal no es URL, es URI.
Anfitrión
El nombre del anfitrión (host) generalmente se resuelve usando DNS o su archivo /etc/hosts a una dirección IP y eso es con lo que curl se comunicará. Alternativamente, especifique la dirección IP directamente en la URL en lugar de un nombre.
Para el desarrollo y otras situaciones de prueba, puede señalar una dirección IP diferente para un nombre de host que la que se usaría de otro modo, utilizando la opción --resolve de curl:
curl --resolve www.example.org:80:127.0.0.1 http://www.example.org/
Número de puerto
Cada protocolo que admite curl opera en un número de puerto predeterminado, ya sea a través de TCP o, en algunos casos, UDP. Normalmente no tiene que tener eso en cuenta, pero a veces puede necesitar ejecutar en servidores de prueba con otros puertos o similares. Luego puede especificar el número de puerto en la URL con dos puntos y un número inmediatamente después del nombre de host. Como cuando se hace HTTP al puerto 1234:
curl http://www.example.org:1234/
El número de puerto que especifique en la URL es el número que utiliza el servidor para ofrecer sus servicios. A veces puede usar un proxy, y luego puede necesitar especificar el número de puerto de ese proxy por separado de lo que curl necesita para conectarse al servidor. Como cuando se usa un proxy HTTP en el puerto 4321:
curl --proxy http://proxy.example.com:4321 http://remoto.example.org/
Nombre de usuario y contraseña
Algunos servicios están configurados para requerir autenticación HTTP y luego debe proporcionar un nombre y una contraseña que luego se transfieren al sitio remoto de varias maneras, según el protocolo de autenticación exacto utilizado.
Puede optar por insertar el usuario y la contraseña en la URL o puede proporcionarlos por separado:
curl http://usuario:contraseña@example.org/
o
curl -u usuario:contraseña http://example.org/
Debe prestar atención a que este tipo de autenticación HTTP no es lo que suelen hacer y solicitar los sitios web orientados al usuario en estos días. Tienden a utilizar formularios y cookies en su lugar.
La ruta
La parte de la ruta simplemente se envía al servidor para solicitar que envíe la respuesta asociada. La ruta es lo que está a la derecha de la barra inclinada que sigue al nombre de host y posiblemente al número de puerto.
Obtener una página
Comando GET
La solicitud u operación más simple y común que se realiza mediante HTTP es obtener (GET) una URL. La URL en sí podría referirse a una página web, una imagen o un archivo. El cliente emite una solicitud GET al servidor y recibe el documento que solicitó. Si escribe en la línea de comando
curl https://curl.se
usted obtiene una página web de regreso en la ventana de su terminal. O sea, todo el documento HTML que contiene esa URL.
Todas las respuestas HTTP contienen un conjunto de encabezados de respuesta que normalmente están ocultos, para ello use la opción --include (abreviado como -i) de curl para mostrarlos, así como el resto del documento.
Comando HEAD
Puede solicitar al servidor remoto solamente los encabezados usando la opción --head (abreviado como -I) que hará que curl emita una solicitud HEAD. En algunos casos especiales, los servidores niegan el método HEAD mientras que otros aún funcionan, lo cual es un tipo particular de molestia.
El método HEAD está definido y creado para que el servidor devuelva los encabezados exactamente como lo haría con un GET, pero sin cuerpo. Significa que puede ver Content-Length: en los encabezados de respuesta, pero no debe haber un cuerpo real en la respuesta HEAD.
Múltiples URL en una sola línea de comando
Una sola línea de comando curl puede incluir una o varias URL. El caso más común es probablemente usar solo uno, pero puede especificar cualquier cantidad de URL. Sí, cualquier cantidad. Sin límites. Luego obtendrá solicitudes repetidas una y otra vez para todas las URL dadas.
Por ejemplo, envíe dos GET:
curl http://url1.example.com http://url2.example.com
Es de notar que si usa --data para POST a la URL, usar varias URL significa que envía ese mismo POST a todas las URL dadas.
Por ejemplo, envíe dos POST:
curl --data name=curl http://url1.example.com http://url2.example.com
Múltiples métodos HTTP en una sola línea de comando
Algunas veces necesita operar en varias URL en una sola línea de comando y hacer diferentes métodos HTTP en cada una. Para ello, disfrutará de la opción --next. Básicamente es un separador que separa un montón de opciones de las siguientes. Todas las URL anteriores a --next obtendrán el mismo método y fusionarán todos los datos POST en uno.
Cuando curl llegue a --next en la línea de comando, restablecerá el método y los datos POST y permitirá un nuevo conjunto.
Tal vez esto se muestre mejor con algunos ejemplos. Para enviar primero un HEAD y luego un GET:
curl -I http://example.com --next http://example.com
Para enviar primero un POST y luego un GET:
curl -d score=10 http://example.com/post.cgi --next http://example.com/results.html
Formularios HTML
Explicación de los formularios
Los formularios son la forma general en que un sitio web puede presentar una página HTML con campos para que el usuario ingrese datos y luego presione algún tipo de botón Aceptar o Enviar para hacer llegar esos datos al servidor. Luego, el servidor generalmente usa los datos publicados para decidir cómo actuar. Ejemplos de uso: utilizar las palabras ingresadas para buscar en una base de datos, o agregar la información en un sistema de seguimiento de errores, o mostrar la dirección ingresada en un mapa o usar la información como un indicador de inicio de sesión para verificar qué puede ver o no el usuario.
Por supuesto, tiene que haber algún tipo de programa en el extremo del servidor para recibir los datos que envía. No se puede simplemente inventar algo del aire.
Método GET
Un formulario tipo GET utiliza el método GET, como se especifica en HTML como por ejemplo:
<form method="GET" action="junk.cgi">
<input type=text name="birthyear">
<input type=submit name=press value="OK">
</form>
En su navegador web favorito (navegador), este formulario aparecerá con un cuadro de texto para completar y un botón de presión con la etiqueta Aceptar. Si introduce 1905 y presiona el botón Aceptar, su navegador creará una nueva URL para usted. Se agregará a la URL:
junk.cgi?birthyear=1905&press=OK
a la parte de la ruta de la URL anterior.
Si el formulario original se vio en la página :
www.example.com/when/birth.html
la segunda página que obtendrá se convertirá en
www.example.com/when/junk.cgi?birthyear=1905&press=OK.
La mayoría de los motores de búsqueda funcionan de esta manera.
Para hacer que curl haga la publicación del formulario GET por usted, simplemente ingrese la URL creada esperada (fíjese en el entrecomillado, n. del t.):
curl "http://www.example.com/when/junk.cgi?birthyear=1905&press=OK"
Método POST
El método GET hace que todos los nombres de los campos de entrada se muestren en el campo URL de su navegador. Por lo general, eso es algo bueno cuando desea poder marcar esa página con sus datos dados, pero es una desventaja obvia si ingresó información secreta en uno de los campos o si hay una gran cantidad de campos creando una larga y URL ilegible.
El protocolo HTTP luego ofrece el método POST. De esta manera, el cliente envía los datos separados de la URL y, por lo tanto, no verá nada en el campo de dirección URL.
El formulario sería similar al anterior:
<form method="POST" action="junk.cgi">
<input type=text name="birthyear">
<input type=submit name=press value=" OK ">
</form>
Y para usar curl para publicar este formulario con los mismos datos que antes, podría hacerlo así:
curl --data "birthyear=1905&press=%20OK%20" http://www.example.com/when/junk.cgi
Este tipo de POST utilizará:
Content-Type application/x-www-form-urlencoded
y es el tipo de POST más utilizado.
Los datos que envíe al servidor ya DEBEN estar codificados correctamente, curl no lo hará por usted. Por ejemplo, si desea que los datos contengan un espacio, debe reemplazar ese espacio con %20, etc. Si no cumple con esto, lo más probable es que sus datos se reciban incorrectamente y se estropeen.
Las versiones recientes de curl pueden, de hecho, codificar en URL los datos POST para usted, así:
curl --data-urlencode "name=I am Daniel" http://www.example.com
Si repite --data varias veces en la línea de comando, curl concatenará todas las piezas de datos dadas y colocará un símbolo & entre cada segmento de datos.
Método POST para «subir» archivos
A finales de 1995, definieron una forma adicional de publicar datos a través de HTTP. Está documentado en el RFC 1867, por lo que este método a veces se denomina publicación RFC1867.
Este método está diseñado principalmente para admitir mejor la carga de archivos. Un formulario que permite a un usuario cargar un archivo podría escribirse así en HTML:
<form method="POST" enctype='multipart/form-data' action="upload.cgi">
<input type=file name=upload>
<input type=submit name=press value="OK">
</form>
Esto muestra claramente que el tipo de contenido que se va a enviar es:
multipart/form-data
Para publicar en un formulario como este con curl, ingrese una línea de comando como:
curl --form upload=@localfilename --form press=OK [URL]
Campos ocultos
Una forma común en que las aplicaciones basadas en HTML pasan información de estado entre páginas es agregar campos ocultos a los formularios. Los campos ocultos ya están rellenos previamente por la aplicación, no se muestran al usuario y se transmiten al igual que todos los demás campos.
Un formulario de ejemplo similar con un campo visible, un campo oculto y un botón de envío podría verse así:
<form method="POST" action="foobar.cgi">
<input type=text name="birthyear">
<input type=hidden name="person" value="daniel">
<input type=submit name="press" value="OK">
</form>
Para emplear el método POST con curl, no tendrá que pensar si los campos están ocultos o no. Para curl todos son iguales, siguiendo el ejemplo anterior:
curl --data "birthyear=1905&press=OK&person=daniel" [URL]
Averiguar cómo se ve el método POST
Cuando está a punto de completar un formulario y enviarlo a un servidor utilizando curl en lugar de un navegador, por supuesto, usted está interesado en enviar una consulta POST exactamente como lo hace su navegador.
Una manera fácil de ver esto es guardar la página HTML con el formulario en su disco local, modificar el ‘método’ a GET y presionar el botón Enviar (también puede cambiar la URL de la acción si lo desea) .
Luego verá claramente que los datos se agregan a la URL, separados con una letra ?, como se supone que deben hacer los formularios GET.
Subiendo ficheros con HTTP
PUT
Quizás la mejor manera de cargar datos en un servidor HTTP es usar PUT. Por otra parte, esto por supuesto requiere que alguien coloque un programa o secuencia de comandos en el extremo del servidor que sepa cómo recibir una transmisión HTTP PUT.
Coloque un archivo en un servidor HTTP con curl:
curl --upload-file uploadfile http://www.example.com/receive.cgi
Autenticación HTTP
Autenticación básica
La autenticación HTTP es la capacidad de decirle al servidor su nombre de usuario y contraseña para que pueda verificar que tiene permiso para realizar la solicitud que está realizando. La autenticación básica que se usa en HTTP (que es el tipo que curl usa de forma predeterminada) se basa en texto sin formato, lo que significa que envía el nombre de usuario y la contraseña solo ligeramente ofuscados, pero que cualquiera que husmee en la red entre usted y el servidor remoto todavía puede leerlos por completo.
Para decirle a curl que use un usuario y una contraseña para la autenticación:
curl --user name:password http://www.example.com
Otra autenticación
El sitio puede requerir un método de autenticación diferente (verifique los encabezados devueltos por el servidor), y luego --ntlm, --digest, --negotiate o incluso --anyauth pueden ser opciones adecuadas para usted.
Autenticación proxy
A veces, su acceso HTTP solo está disponible mediante el uso de un proxy HTTP. Esto parece ser especialmente común en varias empresas. Un proxy HTTP puede requerir su propio usuario y contraseña para permitir que el cliente acceda a Internet. Para especificar aquellos con curl, ejecute algo como:
curl --proxy-user proxyuser:proxypassword curl.se
Si su proxy requiere que la autenticación se realice mediante el método NTLM, use --proxy-ntlm, si requiere Digest, use --proxy-digest.
Si usa cualquiera de estas opciones de usuario y contraseña, pero omite la parte de la contraseña, curl le solicitará la contraseña de forma interactiva.
Ocultamiento de credenciales
Tenga en cuenta que cuando se ejecuta un programa, sus parámetros pueden verse cuando se enumeran los procesos en ejecución del sistema. Por lo tanto, otros usuarios pueden ver sus contraseñas si las pasa como opciones de línea de comandos simples. Hay maneras de eludir esto.
Vale la pena señalar que, si bien así es como funciona la autenticación HTTP, muchos sitios web no utilizarán este concepto cuando proporcionen inicios de sesión, etc. Consulte el capítulo Inicio de sesión web más adelante para obtener más detalles al respecto.
Más encabezados HTTP
Parámetro referer
Una solicitud HTTP puede incluir un campo referer (sí, está mal escrito en inglés), que se puede usar para saber desde cuál URL llegó el cliente a este recurso en particular. Algunos programas/scripts verifican el campo de referencia de las solicitudes para verificar que no provengan de un sitio externo o una página desconocida. Si bien esta es una forma estúpida de verificar algo falsificado tan fácilmente, muchos scripts todavía lo hacen. Usando curl, puede poner cualquier cosa que desee en el campo de referencia y, por lo tanto, podrá engañar más fácilmente al servidor para que atienda su solicitud.
Use curl para establecer el campo de referencia con:
curl --referer http://www.example.come http://www.example.com
Parámetro user agent
Al igual que el campo de referencia, todas las solicitudes HTTP pueden establecer el campo User-Agent (Agente de Usuario). De esta manera se nombra cuál agente de usuario (software cliente) se está utilizando. Muchas aplicaciones utilizan esta información para decidir cómo mostrar las páginas. Los programadores web tontos intentan crear diferentes páginas para los usuarios de diferentes navegadores para que se vean lo mejor posible para sus navegadores particulares. Por lo general, también hacen diferentes tipos de JavaScript, VBScript, etc.
A veces, verá que obtener una página con curl no devolverá la misma página que ve cuando obtiene la página con su navegador. Entonces sabrá que es hora de configurar el campo Agente de usuario para engañar al servidor haciéndole creer que es uno de esos navegadores.
Para hacer que curl se vea como Internet Explorer 5® en una caja de Windows 2000® (navegador y sistema operativo obsoletos actualmente, n. del t.):
curl --user-agent "Mozilla/4.0 (compatible; MSIE 5.01; Windows NT 5.0)" [URL]
O por qué no parecer que está usando Netscape 4.73 en una vieja caja de GNU/Linux® (navegador obsoleto actualmente, n. del t.):
curl –user-agent «Mozilla/4.73 [en] (X11; U; Linux 2.2.15 i686)» [URL]
Redirecciones
Encabezado location
Cuando se solicita un recurso de un servidor, la respuesta del servidor puede incluir una sugerencia sobre dónde debe ir el navegador a continuación para encontrar esta página, o una nueva página que mantiene la salida recién generada. El encabezado que le dice al navegador que redirija es Location:.
Curl no sigue y redirige los encabezados Location: de forma predeterminada, sino que simplemente mostrará dichas páginas de la misma manera que muestra todas las respuestas HTTP. Sin embargo, presenta una opción que hará que intente seguir la ubicación: los punteros Location:.
Para decirle a curl que siga una ubicación:
curl --location http://www.example.com
Si usa curl para enviar por método POST a un sitio que lo redirige inmediatamente a otra página, puede usar con seguridad --location (-L de manera abreviada) y/o --data y/o --form juntos. Curl solo usará POST en la primera solicitud y luego volverá a GET en las siguientes operaciones.
Otras redirecciones
Los navegadores suelen admitir al menos otras dos formas de redireccionamiento que curl no admite: en primer lugar, el código HTML puede contener una etiqueta de actualización meta que le pide al navegador que cargue una URL específica después de un número determinado de segundos, o puede usar JavaScript para hacerlo.
La forma en que los navegadores web realizan el «control de estado del lado del cliente» es mediante el uso de cookies. Las cookies son solo nombres con contenidos asociados. Las cookies son enviadas al cliente por el servidor. El servidor le dice al cliente para qué ruta y nombre de anfitrión quiere que se le devuelva la cookie, y también le envía una fecha de caducidad y algunas propiedades más.
Cuando un cliente se comunica con un servidor con un nombre y una ruta como se especificó previamente en una cookie recibida, el cliente envía las cookies y su contenido al servidor, a menos, por supuesto, que hayan caducado.
Muchas aplicaciones y servidores utilizan este método para conectar una serie de solicitudes en una única sesión lógica. Para poder usar curl en tales ocasiones, debemos poder registrar y enviar cookies de la forma en que la aplicación web las espera. De la misma manera que los navegadores los tratan.
La forma más sencilla de enviar algunas cookies al servidor al obtener una página con curl es agregarlas en la línea de comando como:
curl --cookie "name=Daniel" http://www.example.com
Las cookies se envían como encabezados HTTP comunes. Esto es práctico ya que permite que curl registre cookies simplemente registrando encabezados. Registre cookies con curl usando la opción --dump-header (o con su versión corta -D) como por ejemplo:
curl --dump-header headers_and_cookies http://www.example.com
Tenga en cuenta que la opción
--cookie-jarque se describe a continuación es una mejor manera de almacenar cookies.
Curl tiene incorporado un motor de análisis de cookies completo que se usa si desea volver a conectarse a un servidor y usar cookies que se almacenaron de una conexión anterior (o creadas manualmente para engañar al servidor haciéndole creer que tenía una conexión anterior ). Para usar cookies previamente almacenadas, ejecute curl como:
curl --cookie stored_cookies_in_file http://www.example.com
El «motor de cookies» de curl se habilita cuando usa la opción --cookie. Si solo desea que curl comprenda las cookies recibidas, use --cookie con un archivo que no existe. Por ejemplo, si desea permitir que curl comprenda las cookies de una página y siga una ubicación (y, por lo tanto, posiblemente envíe las cookies que recibió), puede invocarlo como:
curl --cookie nada --location http://www.example.com
Curl tiene la capacidad de leer y escribir archivos de cookies que usan el mismo formato de archivo que alguna vez usaron Netscape y Mozilla. Es una forma conveniente de compartir cookies entre guiones o llamadas. El interruptor --cookie (-b) detecta automáticamente si un archivo determinado es un archivo de cookies y lo analiza, y al usar la opción --cookie-jar (-c) hará que curl escriba un nuevo archivo de cookies al final de una operación:
curl –cookie cookies.txt –cookie-jar newcookies.txt http://www.example.com
Véase también: https://curl.se/docs/http-cookies.html